(数据分析三板斧)第二斧Pandas-第一节:Pandas了解
Posted 快乐江湖
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了(数据分析三板斧)第二斧Pandas-第一节:Pandas了解相关的知识,希望对你有一定的参考价值。
文章目录
一:Pandas了解
(1)什么是Pandas
Pandas是2008年WesMcKinney开发出的库,是一个专门用于数据挖掘的开源Python库,它以Numpy为基础,借力Numpy模块在计算方面性能高的优势,又基于Matplotlib,可以简便的画图,而且还拥有自己独特的数据结构
- Pandas=Panel+data+analysis
(2)Pandas优势
在学习完Numpy和Matplotlib后还要学习Pandas的原因在于:Pandas纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需要的工具,也提供了大量使我们能够快速处理数据的函数和方法。具体来说:
-
Pandas 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据。
-
Pandas 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征。
-
Pandas 广泛应用在学术、金融、统计学等各个数据分析领域
(3)Pandas安装
- 自行查阅,安装非常简单
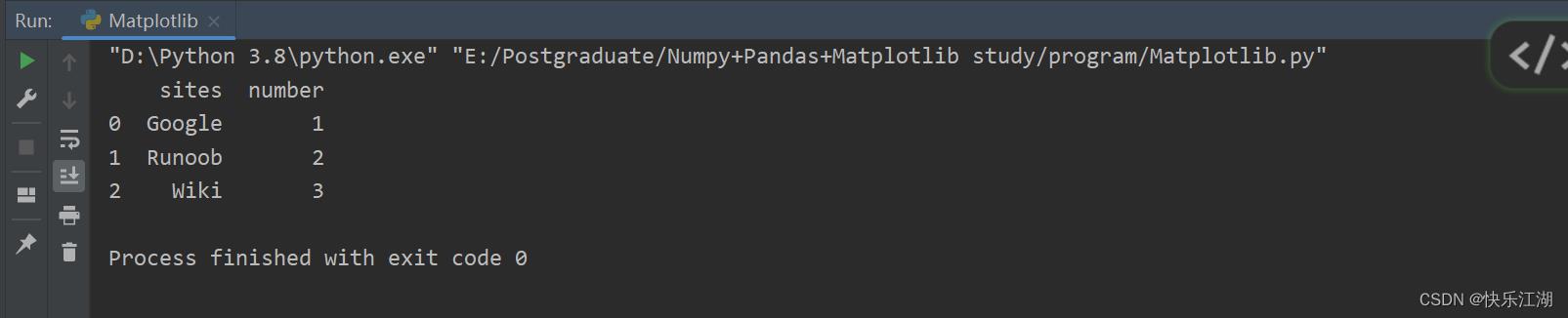
安装好之后,可以通过下面的语句导入Pandas库以及查看其是否能够正常运行
import pandas as pd
mydataset =
'sites': ["Google", "Runoob", "Wiki"],
'number': [1, 2, 3]
myvar = pd.DataFrame(mydataset)
print(myvar)
(4)Pandas核心数据结构
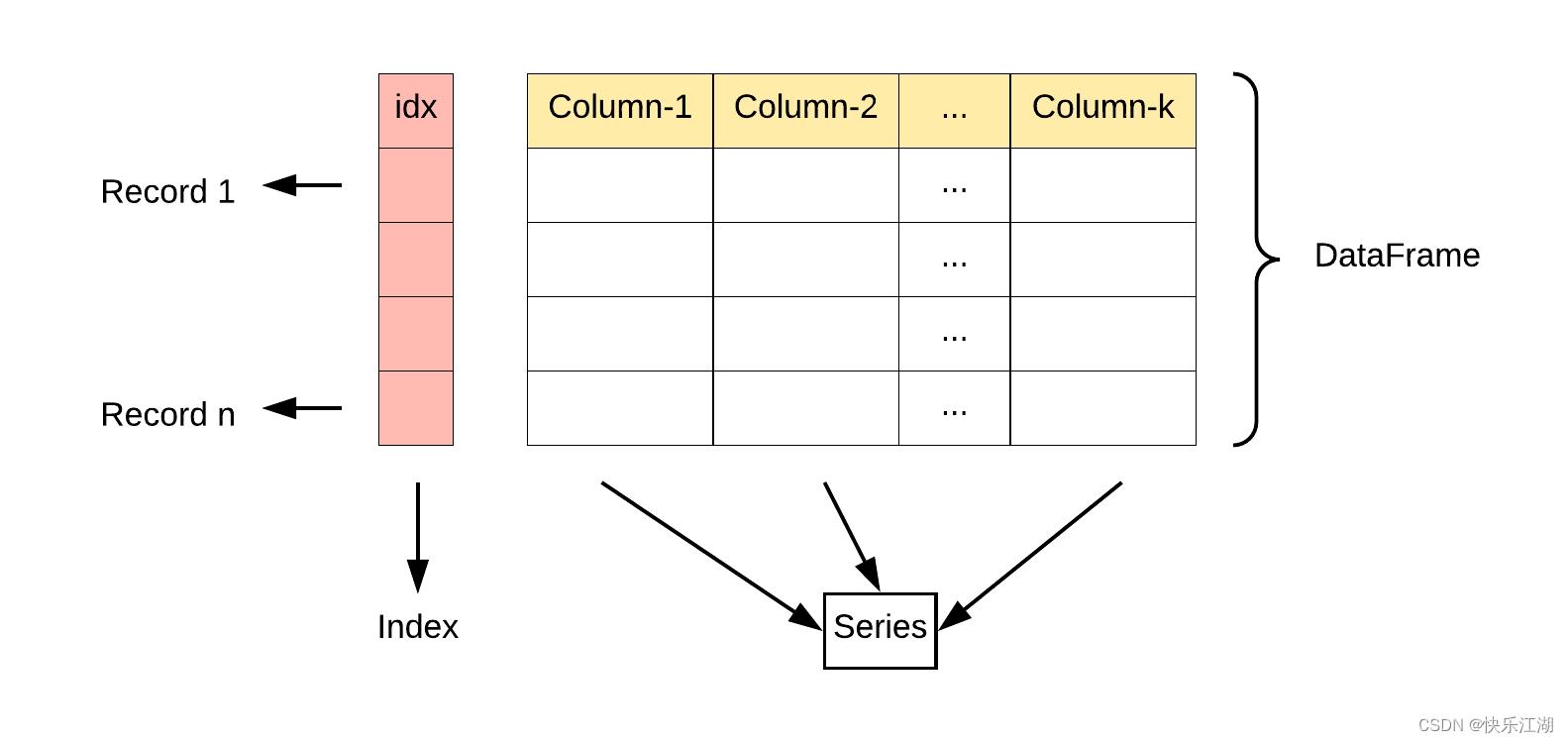
在Pandas中有三类数据结构
Series:是一种类似于一维数组的对象,它由一组数据(各种Numpy数据类型)以及一组与之相关的数据标签(即索引)组成;它可以保存不同种类的数据类型DataFrame:是一个表格型的数据结构(Excel、SQL等),它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)
二:DataFrame类型
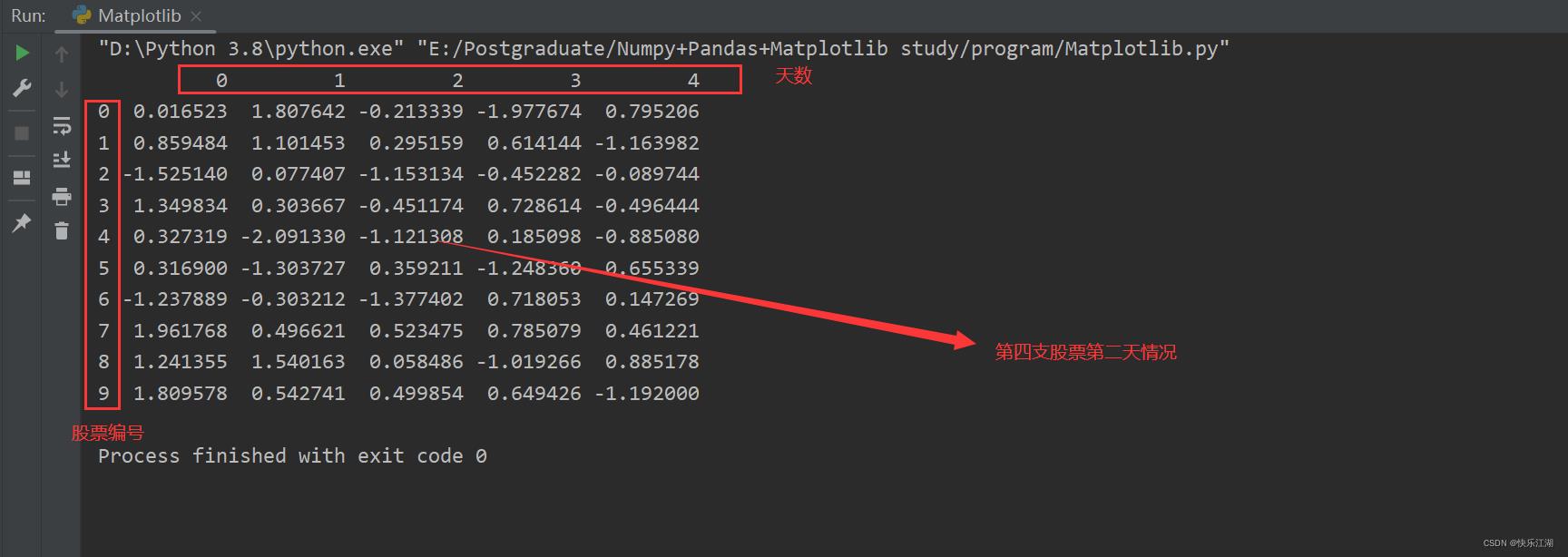
Numpy注重运算,所以对于数据意义的表达没有那么清楚,比如下面用Numpy生成了一个符号正态分布的10支股票5天的涨幅情况
- 这样的数据表现形式让人有点难受,因为完全不知道它在表达什么
stock_change = np.random.normal(0, 1, (10, 5))
print(stock_change)
[[ 0.22129238 1.72192263 0.49808165 -0.70501369 -0.57315298]
[-0.05685967 -1.59493883 0.20770355 2.03934052 -0.91647225]
[-0.64659703 -1.7586049 -0.53091496 -0.95453855 0.84446516]
[ 0.02877987 1.53110344 -0.90623823 1.41938924 -1.24248129]
[-0.36990152 -0.17153907 0.24179436 0.82450977 1.1865927 ]
[-0.14524005 -0.57297533 -0.08680693 0.07105316 -0.12050658]
[ 0.50399736 1.56385492 -0.38175291 0.52144963 0.51322901]
[ 0.71534998 -0.61644881 0.15437358 0.00324533 -0.830954 ]
[-0.65036464 -1.71639338 -1.18670887 0.34092581 -0.8870423 ]
[-0.89061683 -0.93671895 -0.19911303 0.49350255 2.02240886]]
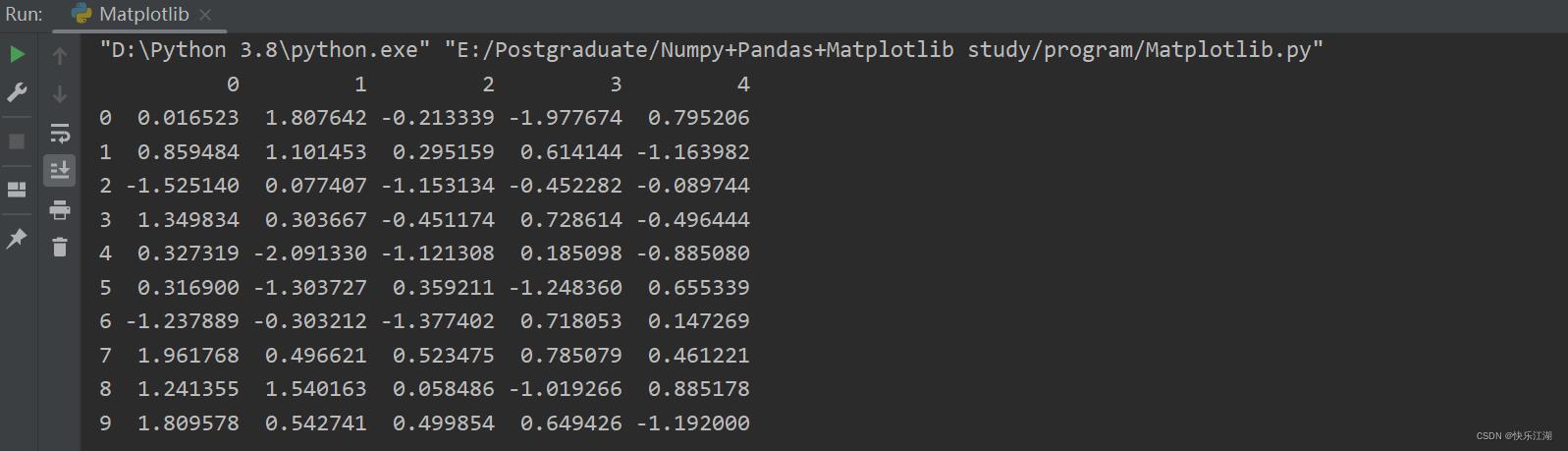
因此,我们的DataFrame就是为了让数据更有意义的显示。这里可以直接调用pd.DataFrame(),然后将numpy数组传入进去
stock_change = np.random.normal(0, 1, (10, 5))
a = pd.DataFrame(stock_change)
print(a)
你会发现,现在显示形式比之前就舒服多了
(1)DataFrame结构
DataFrame 是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值类型(数值、字符串、布尔型值)。DataFrame 既有行索引也有列索引,它可以被看做由 Series 组成的字典(共同用一个索引)
因此,上面的那个例子中行列索引表达的意思为
(2)DataFrame构造方法
DataFrame 构造格式下:
pandas.DataFrame( data, index, columns, dtype, copy)
-
data:一组数据(ndarray、series,map,lists,dict等类型)。 -
index:索引值,或者可以称为行标签。 -
columns:列标签,默认为 RangeIndex (0, 1, 2, …, n) 。 -
dtype:数据类型。 -
copy:拷贝数据,默认为 False
举例
a = pd.DataFrame(np.random.randn(4, 5)) # numpy二维随机数组
print(a)

从以上输出结果可以知道, DataFrame 数据类型一个表格,包含 rows(行) 和 columns(列)
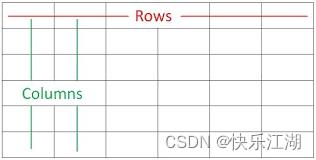
(3)DataFrame索引
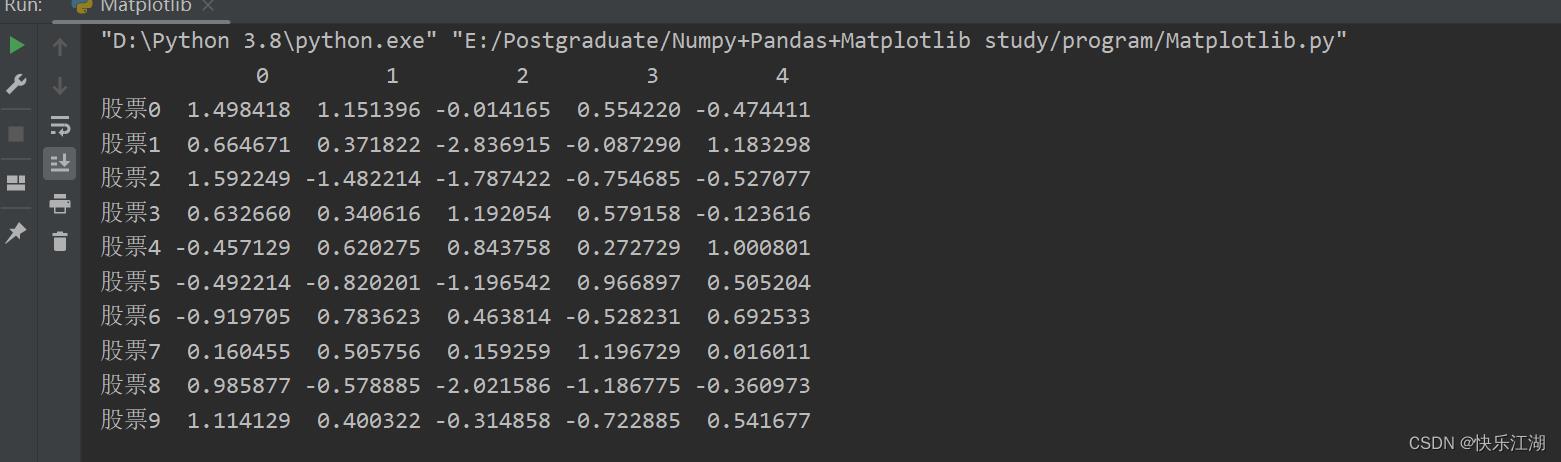
上例中默认显示的索引并不是很合适,没有起到见名知意的作用。我的目的是行索引显示股票支数,列索引显示天数,这里先用列表生成式生成行索引
stock_index = ["股票".format(i) for i in range(10)] # 行索引
然后在刚才的pd.DataFrame()中传入index=stock_index,即行索引
stock_change = np.random.normal(0, 1, (10, 5))
stock_index = ["股票".format(i) for i in range(10)] # 行索引
a = pd.DataFrame(stock_change, index=stock_index)
print(a)
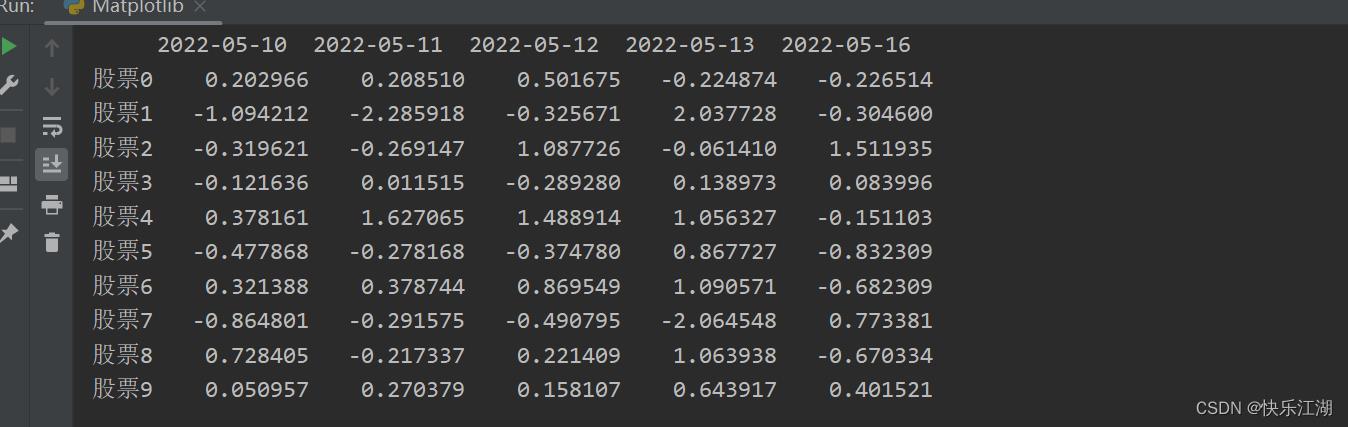
对于列索引,我们直接调用Pandas中现成的函数
- 关于date_range()更为详细的用法可以参照这篇文章点击跳转
date_index = pd.date_range(start='20220510', periods=5, freq='B') #列索引
然后在刚才的pd.DataFrame()中传入columns=date_index,即列索引
stock_change = np.random.normal(0, 1, (10, 5))
stock_index = ["股票".format(i) for i in range(10)] # 行索引
date_index = pd.date_range(start='20220510', periods=5, freq='B') # 列索引
a = pd.DataFrame(stock_change, index=stock_index, columns=date_index)
print(a)
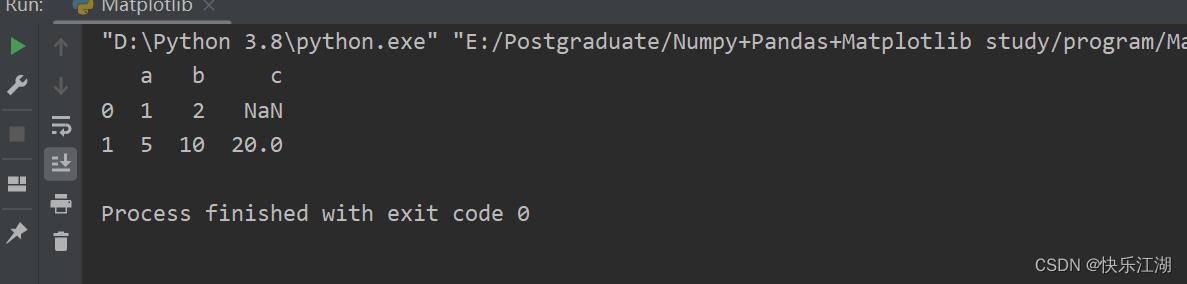
还可以通过字典传入
a = pd.DataFrame(
[
'a': 1, 'b': 2,
'a': 5, 'b': 10, 'c': 20
]
)
print(a)
(4)DateFrame常用属性和方法
A:属性
DateFrame说穿了其实就是Numpy二维数组加了行列索引,所以Numpy数组具有的属性,DateFrame基本也有,常用属性有
stock_change = np.random.normal(0, 1, (10, 5))
stock_index = ["股票".format(i) for i in range(10)] # 行索引
date_index = pd.date_range(start='20220510', periods=5, freq='B') # 列索引
a = pd.DataFrame(stock_change, index=stock_index, columns=date_index)
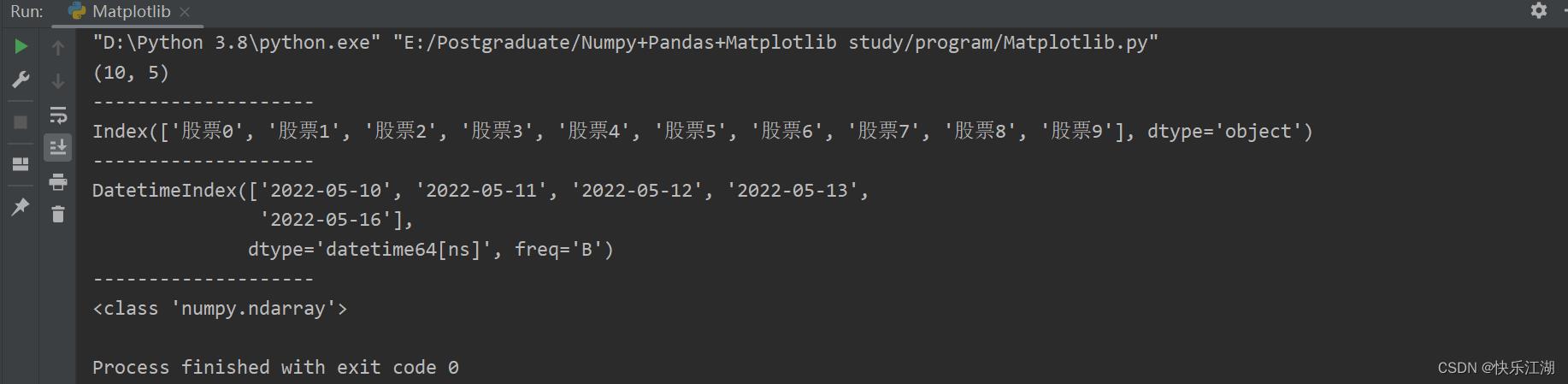
print(a.shape) # 形状
print("-"*20)
print(a.index) # 返回DateFrame行索引列表
print("-"*20)
print(a.columns) # 返回DateFrame列索引列表
print("-"*20)
print(type(a.values)) # 返回原生Numpy数组
print("-"*20)
B:方法
经常使用到的方法是head()和tail(),因为很多时候我们要频繁查看表的头部和尾部信息
stock_change = np.random.normal(0, 1, (10, 5))
stock_index = ["股票".format(i) for i in range(10)] # 行索引
date_index = pd.date_range(start='20220510', periods=5, freq='B') # 列索引
a = pd.DataFrame(stock_change, index=stock_index, columns=date_index)
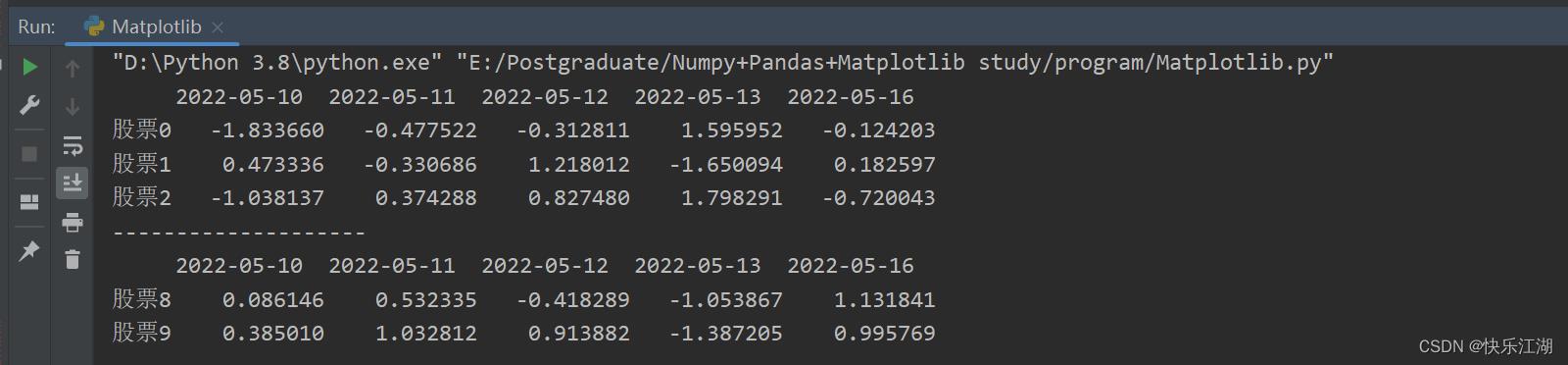
print(a.head(3)) # 查看前三只股表信息
print("-"*20)
print(a.tail(2)) # 查看后两只股票信息
四:Series类型
Pandas Series 类似表格中的一个列(column),类似于一维数组,可以保存任何数据类型;Series 由索引(index)和列组成,函数如下
pandas.Series( data, index, dtype, name, copy)
-
data:一组数据(ndarray 类型) -
index:数据索引标签,如果不指定,默认从 0 开始 -
dtype:数据类型,默认会自己判断 -
name:设置名称 -
copy:拷贝数据,默认为 False
举例
a = pd.Series([1, 3, 'str', np.nan, 7])
print(a)

其中的索引index是可以自己设定的
- 其实你也可以将字典传入,也能达到这样的效果
a = pd.Series([1, 3, 'str', np.nan, 7], index=['A', 'B', 'C', 'D', 'E'])
print(a)
print("-"*20)
print(a['C'])

还有一种写法我比较喜欢
a = pd.Series([1, 3, 'str', np.nan, 7])
print(a)
print("-"*20)
a.index = list('ABCDE')
print(a)

如果执行pandas.index,就会显示其索引情况
a = pd.Series([1, 3, 'str', np.nan, 7], index=['A', 'B', 'C', 'D', 'E'])
print(a)
print("-"*20)
print(a.index)

如果执行pandas.values(),就会显示其值
a = pd.Series([1, 3, 'str', np.nan, 7], index=['A', 'B', 'C', 'D', 'E'])
print(a)
print("-"*20)
print(a.values)

它的索引和切片也是一个道理
a = pd.Series([1, 3, 'str', np.nan, 7], index=['A', 'B', 'C', 'D', 'E'])
print(a)
print("-"*20)
print(a['C'])
print(a['A':'D'])

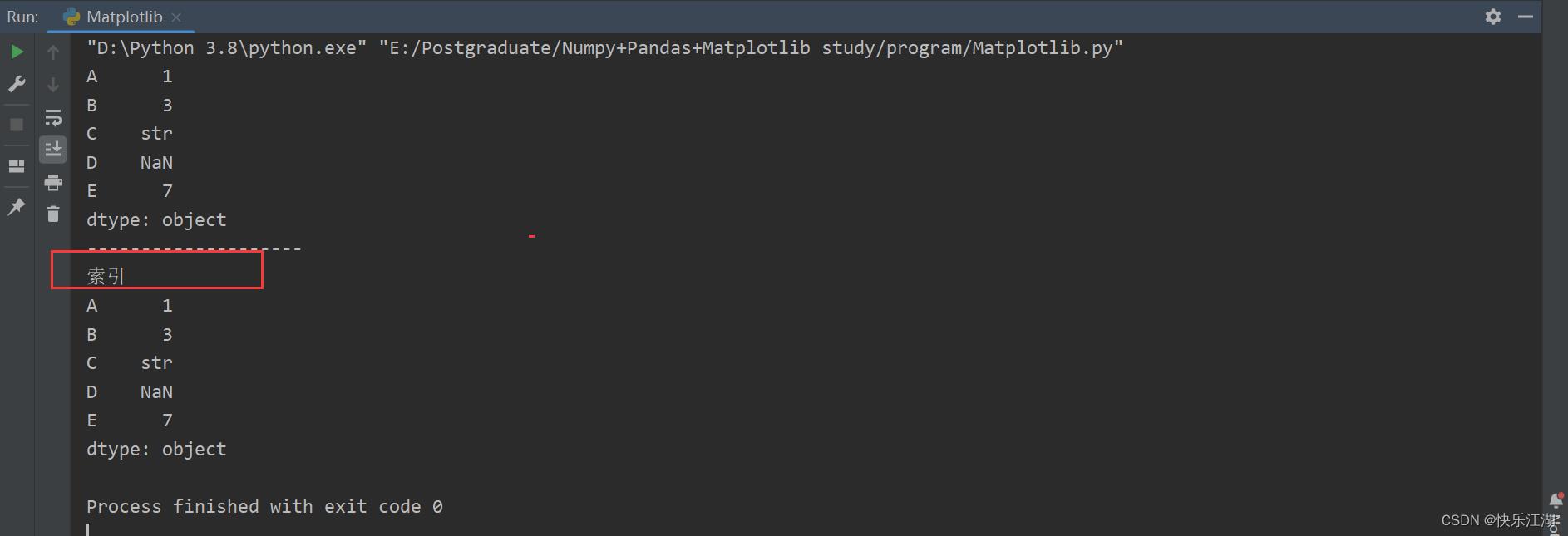
可以使用pandas.index.name来为索引列起一个名字
a = pd.Series([1, 3, 'str', np.nan, 7], index=['A', 'B', 'C', 'D', 'E'])
print(a)
print("-"*20)
a.index.name = '索引'
print(a)
以上是关于(数据分析三板斧)第二斧Pandas-第一节:Pandas了解的主要内容,如果未能解决你的问题,请参考以下文章
(数据分析三板斧)第一斧Numpy-第一节:Numpy基本了解
(数据分析三板斧)第三斧Matplotlib-第一节:Matplotlib及其三层结构