unicode与utf-8的联系
Posted issue是fw
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了unicode与utf-8的联系相关的知识,希望对你有一定的参考价值。
参考
①. ASCII码
由美国最早指定的编码方式. 每个字符用 8 8 8个比特表示, 所以最多可以表示 256 256 256种字符
由于只需要表示一些字母和数字或简单符号(一共128种字符), 所以这样表示没有问题.
②. Unicode
对于使用英语的国家,ASCII码已经足够使用.
使用其他语言的国家就需要创建自己的编码方式了, 比如编码中文的GBK格式.
后来每个国家都创建一种编码方式, 交流极其不便, 需要有一种编码统一起来.
这就是Unicode编码, 目前它包含大概1114112个字符,使用数字0-0x10FFFF来映射这些字符。
比如U+4E25表示汉字严
③.Unicode的不足
虽然Unicode制定了二进制和字符间的映射, 但它没有规定这个二进制代码如何存储.
如果采用ASCII码就知道每 8 8 8个比特表示一个字符, 而Unicode码则没有这样规定。
当然我们也可以效仿ASCII码, 比如用四个字节来表示一个字符.
这样的问题是, 数字小的那些二进制高位都是0, 而这些二进制对应的字符恰好是常用的那些
极大的浪费了存储空间.
④.UTF-8
UTF-8是Unicode的一种实现方式.
UTF-8 最大的一个特点,就是它是一种变长的编码方式。它可以使用1~4个字节表示一个符号,根据不同的符号而变化字节长度, 这样极大的节省了空间.
UTF-8的编码规则如下
Ⅰ. 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 Unicode 码。因此对于英语字母,UTF-8编码和 ASCII码是相同的。
Ⅱ. 对于n字节的符号(n > 1),第一个字节的前n位都设为1,第n + 1位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的Unicode码。
具体如下图所示
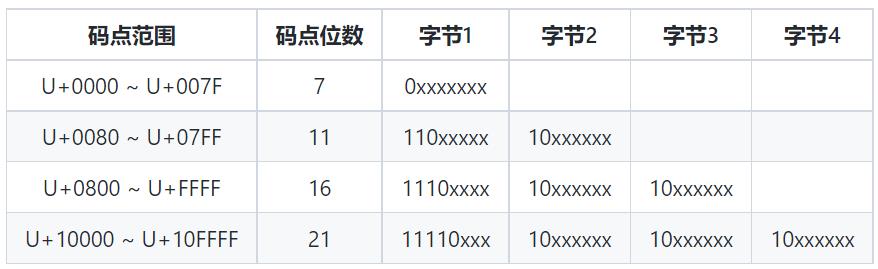
这样设置有一个好处. 当看到以0开头就知道接下来的字符是一个字节
看到以110开头就知道接下来的字符是两个字节…以此类推
以上是关于unicode与utf-8的联系的主要内容,如果未能解决你的问题,请参考以下文章