Kubernetes 系列从整体架构的感性认识切入
Posted 范桂飓
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes 系列从整体架构的感性认识切入相关的知识,希望对你有一定的参考价值。
目录
文章目录
分层架构

系统架构

Kubernetes 是一个典型的中控分布式架构(Central control distributed architecture)。
Master
kube-apiserver
资源对象是 Kubernetes 的核心概念,在 Kubernetes 中,万物皆对象。路由(Ingress)、服务(Service)、部署(Deployment)、存储(Storage/PV/PVC)、Pod、角色(Role)、账户(Accoutn)、配置(ConfigMap)等等。通过管理这些对象来管理整个 Kubernetes 集群。
kube-apiserver(Kubernetes API Server)则负责将 Kubernetes 的 “资源、资源版本、资源组” 等逻辑概念以 RESTful 风格的形式对外暴露并提供服务。是唯一的 Kubernetes Cluster 控制入口,所有的指令请求都必须要经过 API Server。即:Kubernetes Cluster 中的所有组件都通过 kube-apiserver 继而操作 Kubernetes 的资源对象。
kube-apiserver 也是 Kubernetes Cluster 中唯一与 etcd cluster 进行交互的核心组件。例如,通过 kubectl 创建了一个 Pod 资源对象,请求通过 kube-apiserver 的 HTTP 接口将 Pod 资源对象存储至 etcd cluster 中。
小结,kube-apiserver 具有以下重要特性:
- 将 Kubernetes 系统中的所有资源对象都封装成 RESTful 风格的 API 接口进行管理。
- 提供了集群各组件的通信和交互功能。
- 可进行集群状态管理和数据管理,是唯一与 etcd cluster 交互的组件。
- 拥有丰富的集群安全访问机制,以及认证、授权及准入控制器。依靠 CA 认证体系提供身份认证、授权、鉴权等 Kubernetes Security Mechanism(安全机制)访问控制功能,统称 3A(Authentication、Authorization、Admission)。
kube-apiserver 是可以进行水平扩展的。
kube-controller-manager
kube-controller-manager(Kubernetes Controller Manager,管理控制器)负责管理 Kubernetes Cluster 中的 Node、Pod、Service、Endpoint、Namespace、ServiceAccount(服务账户)、ResourceQuota(资源定额)等资源对象。例如:当某个 Node 意外宕机时,Controller Manager 会及时发现并执行自动化修复流程,确保集群始终处于预期的工作状态。
Kubernetes Controller Manager 负责确保 Kubernetes 系统的实际状态收敛到所需状态,其默认提供了一些控制器(Controller),例如:Deployment Controller、StatefulSet Controller、Namespace Controller、PersistentVolume Controller 等。每个 Controller 在逻辑上是独立的进程,但是为了降低复杂性,它们被编译为一个二进制文件,以单个进程运行。
每个 Controller 通过 kube-apiserver 提供的接口实时监控整个 Kubernetes Cluster 中所有资源对象的当前状态,当因发生各种故障而导致系统状态出现变化时,会尝试将系统状态修复到 “期望状态”,即:声明式 API 的思想。
Kubernetes Controller Manager 具有热备型高可用性(只有一个 Actice),基于 etcd cluster 的分布式锁实现领导者选举机制,多实例同时运行,通过 kube-apiserver 提供的资源锁进行选举竞争。抢先获取锁的实例被称为 Leader(领导)节点,并运行 kube-controller-manager 组件的主逻辑;而未获取锁的实例被称为 Candidate(候选)节点,运行时处于阻塞状态。在 Leader 节点因某些原因退出后,Candidate 节点则通过领导者选举机制参与竞选,成为 Leader 节点后接替 kube-controller-manager 的工作。
kube-scheduler
kube-scheduler(Kubernetes Scheduler)作为 Pod 资源对象调度器,按照预设的策略(调度算法)将 Pod 调度到目的(最佳)Node 上启动。Kubernetes Scheduler 每次只调度一个 Pod 资源对象,为每一个 Pod 资源对象寻找合适节点的过程是一个调度周期。
Kubernetes Scheduler 监控整个 Kubernetes Cluster 的 Pod 资源对象和 Node 资源对象,当监控到新的 Pod 资源对象时,会通过调度算法为其选择最优节点。调度算法分为两种,分别为:预选调度算法和优选调度算法。除调度策略外,Kubernetes 还支持优先级调度、抢占机制及亲和性调度等功能。
Kubernetes Scheduler 调度策略中考虑的因素包括:个体和全部资源需求、硬件 / 软件 / 策略约束,亲和性和反亲和性(affinity and anti-affinity)规范、数据的本地性、工作负载间的干扰和最后期限等。
Kubernetes Scheduler 同样支持与 Kubernetes Controller Manager 一样的热备型高可用性。
etcd
etcd 提供高可用性、严格数据一致性的非关系型数据库,具有共享配置、服务发现、分布式等特点。常被用于构建服务发现系统。
etcd cluster 是分布式键值存(Key/Value)储集群,其提供了可靠的强一致性服务发现。etcd cluster 存储 Kubernetes Cluster 的状态和元数据,其中包括所有 Kubernetes 资源对象信息、集群节点信息等。Kubernetes 将所有数据存储至 etcd cluster 中前缀为 /registry 的目录下。
Node
kubelet
每个 Node 都会运行 kubelet,用来接收、处理、上报 kube-apiserver 下发的任务执行结果。是真正负责 Pod 运行的组件。
- kubelet 进程启动时会向 kube-apiserver 注册 Node 自身的信息。
- kubelet 负责对所在 Node 上的 Pod 资源对象的管理,例如:Pod 资源对象的创建、修改、监控、删除、驱逐及 Pod 生命周期管理等。
- kubelet 会读取 Pod 的清单(manifests),确保清单中定义的容器已启动并处于运行状态。
- kubelet 会定期监控所在 Node 的资源使用状态并上报给 kube-apiserver 组件,这些资源数据可以帮助 kube-scheduler 为 Pod 资源对象预选节点。
- kubelet 也会对所在 Node 的镜像和容器做清理工作,保证节点上的镜像不会占满磁盘空间、删除的容器释放相关资源。
在 OS 上去创建容器所需要运行的环境,最终把容器运行起来,也就需要对存储、网络进行管理。Kubernetes 并不会直接进行网络存储的操作,他们会靠 Storage Plugin 或者是 Network Plugin 来进行操作。用户自己或者云厂商都会去写相应的 Storage Plugin 或者 Network Plugin,去完成存储操作或网络操作。
kubelet 实现了 3 种开放接口:

-
CRI(Container Runtime Interface,容器运行时接口):提供容器运行时通用插件接口服务。CRI 定义了容器和镜像服务的接口。CRI 将 kubelet 与容器运行时进行解耦,将原来完全面向 Pod 级别的内部接口拆分成面向 Sandbox 和 Container 的 gRPC 接口,并将镜像管理和容器管理分离给不同的服务。
-
CNI(Container Network Interface,容器网络接口):提供网络通用插件接口服务。CNI 定义了 Kubernetes 网络插件的基础,容器创建时通过 CNI 插件配置网络。
-
CSI(Container Storage Interface,容器存储接口):提供存储通用插件接口服务。CSI 定义了容器存储卷标准规范,容器创建时通过 CSI 插件配置存储卷。
kube-proxy
在 Kubernetes Cluster 中,也会有其内部的网络元素,真正完成为 Kubernetes Service 进行组网的组件的是 kube-proxy,它利用了 iptable 的能力来进行组建 Kubernetes 内部的网络,也就是 Cluster Network。
kube-proxy 作为 Node 上的网络代理,它从 kube-apiserver 监控 Kubernetes Service 和 Endpoint 资源对象的变化,并通过 iptables、ipvs 等网络堆栈配置负载均衡器,为一组 Pod 提供统一的 TCP/UDP 流量转发和负载均衡功能。kube-proxy 是参与管理 Pod-to-Service 和 External-to-Service 网络的最重要的节点组件之一。
kube-proxy 的本质是一个代理模型,对某个 IP:Port 的请求,负责将其转发给专用网络上的相应服务或应用程序。kube-proxy 与其他负载均衡服务的区别在于:kube-proxy 代理只向 Kubernetes Service 及其后端的 Pods 发出请求。
containerd
containerd 是 Container Runtime,负责镜像管理以及 Pod 和 Container 的运行(CRI)。注重于容器的简单性、鲁棒性和可移植性。负责获取和存储容器映像、执行容器、提供网络访问等。
kubectl

提供与 Kubernetes API Server 交互的命令行工具,通信协议使用了 HTTP/JSON。用户可使用 kubectl 创建、更新和删除 Kubernetes 资源对象。
client-go
除了 CLI kubectl,Kubernetes 还提供了编程 SDK client-go 与 Kubernetes API Server 进行通信。
client-go 是从 Kubernetes 代码中抽象的一个包,作为官方提供的 Golang 编程客户端库。client-go 在 Kubernetes 系统上做了大量的优化,Kubernetes 核心组件,如:kube-scheduler、kube-controller-manager 等,都通过 client-go 与 Kubernetes API Server 进行交互。
协议架构

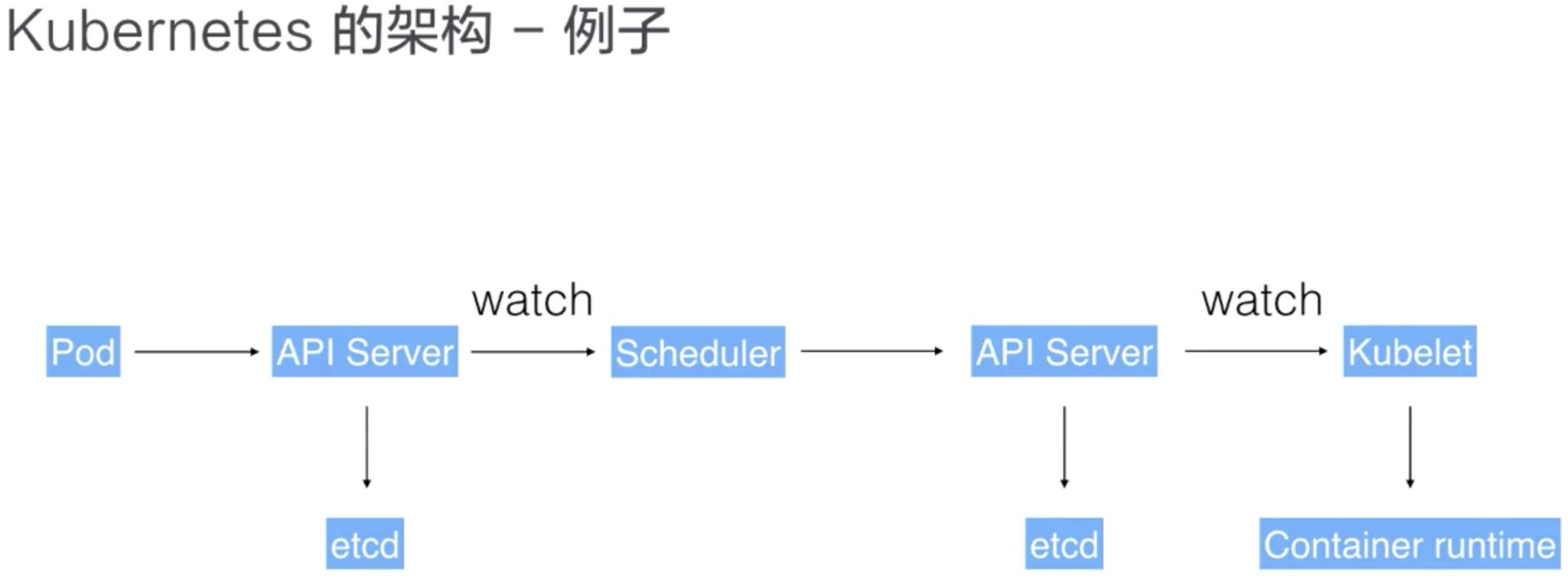
用户通过 UI 或者 CLI 提交一个 Pod 给 Kubernetes 进行部署,这个 Pod 请求首先会通过 CLI 或者 UI 提交给 Kubernetes API Server,下一步 API Server 会把这个信息写入到它的存储系统 etcd,之后 Scheduler 会通过 API Server 的 watch 或者叫做 notification 机制得到这个信息:有一个 Pod 需要被调度。
这个时候 Scheduler 会根据它的内存状态进行一次调度决策,在完成这次调度之后,它会向 API Server report 说:“OK!这个 Pod 需要被调度到某一个节点上。”
这个时候 API Server 接收到这次操作之后,会把这次的结果再次写到 etcd 中,然后 API Server 会通知相应的节点进行这次 Pod 真正的执行启动。相应节点的 kubelet 会得到这个通知,kubelet 就会去调度 CRI 的 Container Runtime 来真正去启动配置这个容器和这个容器的运行环境,去调度 Storage Plugin 来去配置存储,Network Plugin 去配置网络。
部署架构

-
Client 层:即外部用户、客户端等;
-
服务访问层:即由 Traefik Ingress 实现服务发现、负载均衡和路由规则定义等;
-
业务应用层:即基于 Kubernetes 之上构建和运行的企业业务应用,如:CI/CD、微服务项目、监控告警和日志管理、私有镜像仓库等;
-
基础设施层:即由 Kubernetes、Calico SDN、Ceph SDS 等系统组成的基础设施服务。
基础设施层
- Kubernetes
- Calico SDN
- Ceph SDS 或 NFS
业务应用层
- 镜像管理:使用 Harbor 私有镜像仓库服务;
- 日志管理:使用 ELK Stack。
- 监控告警管理:使用 Prometheus 和 Grafana;
- 微服务架构:使用 Istio 的 Service Mesh 方案,或者使用 APIGW;
- DevOps:使用 Gitlab、Jenkins 等 CI/CD 工具;
- 单体应用:无状态类服务使用 deployment,有状态类服务则使用 Statefulset,如果关联的服务较多且复杂则使用 Helm。
- 规划好 Namespace:应当做到每个 Namespace 专属用于某类型的应用,例如:monitor namespace 用于统一管理监控告警、日志管理方面的 pod、service、pvc、ingress 等资源对象。
服务访问层
外部客户端访问 Kubernetes Cluster 内部的 Service、LB 和路由规则定义使用 Ingress 实现。此外,应当实现 Ingress 的 HA。

以上是关于Kubernetes 系列从整体架构的感性认识切入的主要内容,如果未能解决你的问题,请参考以下文章
深入浅出etcd系列Part 1 – etcd架构和代码框架