学fpga(hls之unroll的使用)
Posted 费晓行
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了学fpga(hls之unroll的使用)相关的知识,希望对你有一定的参考价值。
【 声明:版权所有,欢迎转载,请勿用于商业用途。 联系信箱:feixiaoxing @163.com】
hls里面除了提供了c、c++的编辑、综合功能之外,还提供了很多与之配套的功能,比如说testbench、co-sim、open wave viewer、compare report等等。这些都是分析fpga效果的利器。大家在学习hls的时候,要时刻记得是,我们编写的不是代码,其实是电路,和verilog一样的电路。言归正传,今天还是看一下hls里面unroll是怎么使用的。
1、简单多项式计算
void computer_matrix(uint32 src, uint32* dst, uint32 a, uint32 b, uint32 c)
#pragma HLS INTERFACE ap_ctrl_none port=return
#pragma HLS INTERFACE s_axilite port=src
#pragma HLS INTERFACE s_axilite port=a
#pragma HLS INTERFACE s_axilite port=b
#pragma HLS INTERFACE s_axilite port=c
*dst = src * a + b + c;
综合一下,看一下效果,

进一步分析计算的流程,从图中可以看出来,tmp1和tmp_2是可以一起完成的,
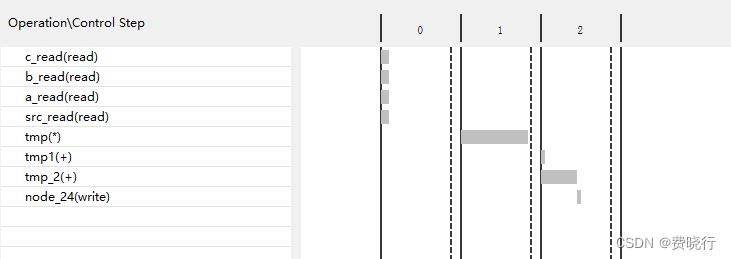
2、强制顺序执行的多项式计算
void computer_matrix(uint32 src, uint32* dst, uint32 a, uint32 b, uint32 c)
#pragma HLS INTERFACE ap_ctrl_none port=return
#pragma HLS INTERFACE s_axilite port=src
#pragma HLS INTERFACE s_axilite port=a
#pragma HLS INTERFACE s_axilite port=b
#pragma HLS INTERFACE s_axilite port=c
*dst = src * a ;
*dst += b;
*dst *= c;
分析方法和1是一样的,只不过这个时候latency和interval都变成了3。

进一步分析调度器视图,

3、加入循环的多项式计算
void computer_matrix(uint32 src[10], uint32 dst[10], uint32 a, uint32 b, uint32 c)
#pragma HLS INTERFACE ap_ctrl_none port=return
#pragma HLS INTERFACE s_axilite port=src
#pragma HLS INTERFACE s_axilite port=dst
#pragma HLS INTERFACE s_axilite port=a
#pragma HLS INTERFACE s_axilite port=b
#pragma HLS INTERFACE s_axilite port=c
for(int i = 0; i < 10; i++)
dst[i] = src[i] * a + b + c;
和2相比较,输入数据变成了src数组和dst数组,长度为10。与此同时,通过综合报告,我们发现interval和latency也发生了变化,

此外,可以再次确认下状态机效果,
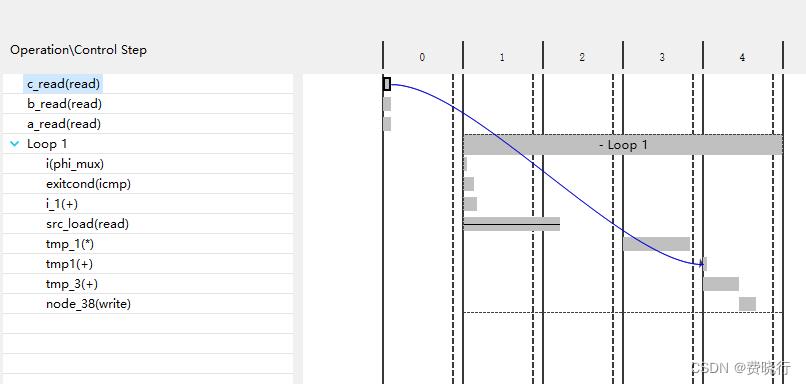
4、 添加unroll之后的多项式计算
void computer_matrix(uint32 src[10], uint32 dst[10], uint32 a, uint32 b, uint32 c)
#pragma HLS INTERFACE ap_ctrl_none port=return
#pragma HLS INTERFACE s_axilite port=src
#pragma HLS INTERFACE s_axilite port=dst
#pragma HLS INTERFACE s_axilite port=a
#pragma HLS INTERFACE s_axilite port=b
#pragma HLS INTERFACE s_axilite port=c
for(int i = 0; i < 10; i++)
#pragma HLS UNROLL
dst[i] = src[i] * a + b + c;
4和3的区别其实就是添加了#pragma HLS UNROLL这个语句。可以看一下效果如何,

从report可以看出,latency和interval大幅度降低到12,
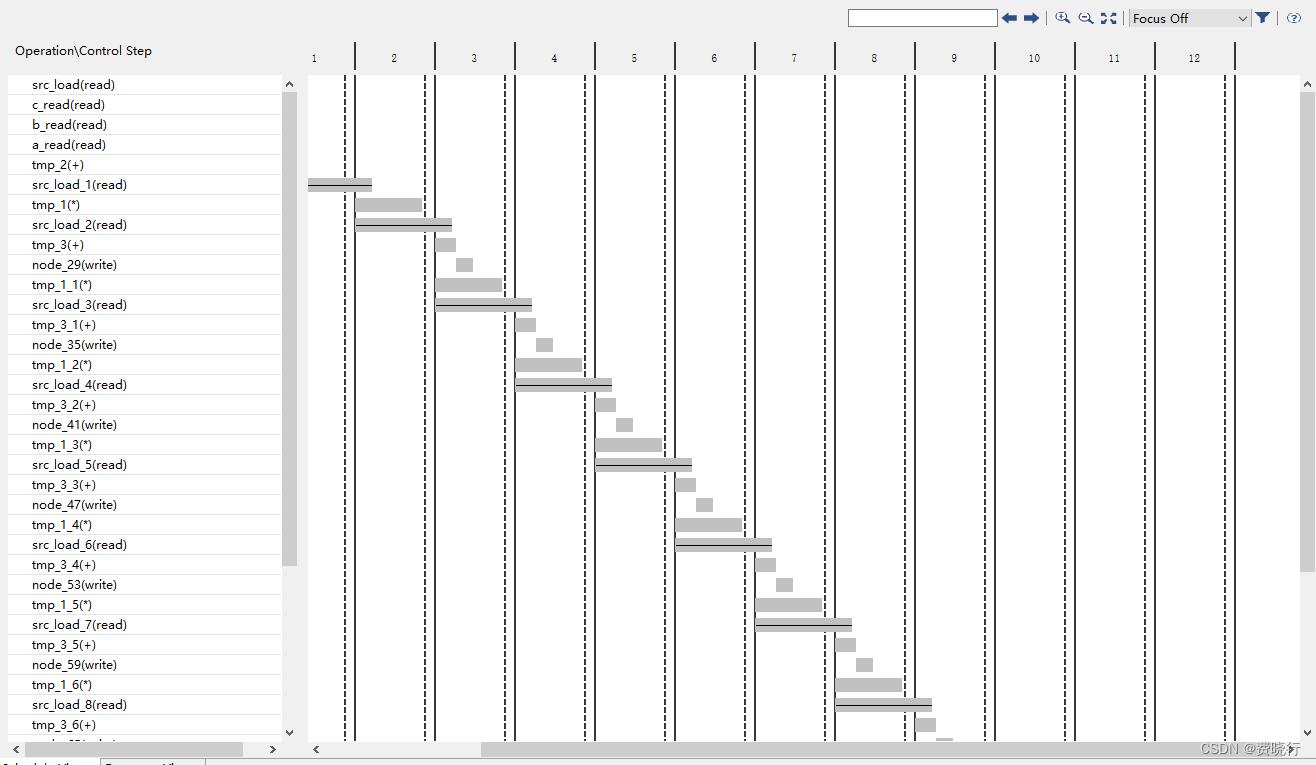
从状态图可以发现,整个循环其实被分解成了一个pipeline操作。似乎从图形上看,这也不是我们想要的结果。
5、去除interface定义后的unroll操作
void computer_matrix(uint32 src[10], uint32 dst[10], uint32 a, uint32 b, uint32 c)
for(int i = 0; i < 10; i+=1)
#pragma HLS UNROLL
dst[i] = src[i] * a + b + c;
还是这一段代码,可以通过interface的定义,直接用unroll来进行处理。
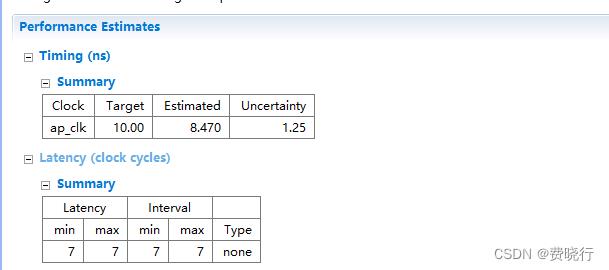
果不其然,latency的时间再次大幅度减小,可以打开状态图确认下,

6、当然latency和interval只是一方面,大家还可以自己编写testbench进行分析和计算,
#include <ap_cint.h>
extern void computer_matrix(uint32 src, uint32* dst, uint32 a, uint32 b, uint32 c);
int main()
uint32 src =1;
uint32 dst;
computer_matrix(src, &dst, 2, 3, 4);
if(dst == 20)
printf("ok");
else
printf("error");
return 0;
7、总结
优化是一个循序渐进的操作,更多的时候是一个妥协。一方面,需要调高运算的速度;另外一方面需要降低使用的资源。这中间寻找平衡点是非常重要的。
以上是关于学fpga(hls之unroll的使用)的主要内容,如果未能解决你的问题,请参考以下文章