Kafka生产者
Posted
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kafka生产者相关的知识,希望对你有一定的参考价值。
参考技术A 当我们使用Kafka作为异步消息队列之后,首当其冲的两个问题:消息的来源和消息的去除,映入我们的脑海。进而延伸出很多我们需要考虑的问题,这里引用《Kafka权威指南》的原文:这里就需要我们着手对Kafka生产者组件进行研究,学着怎么自己用生产者API构造一个Java Client类。
一次数据的生产大概要经历这么一个流程:
1.创建ProducerRecord对象,对象内指定目标主题和发送内容,同时还可以指定键和要发送到的分区。
2.创建定制的序列化器或使用现有的序列化器,Kafka支持的序列化协议有JSON、Protobuf、arvo等,其中arvo是Kafka本身支持的定制化协议格式。
3.对象通过序列化器序列化后,会被发往指定分区。如果ProducerRecord对象未指定分区,则交由分区器根据对象的键来选择一个分区。
4.接着数据会被传到一个记录批次里,这个批次的数据会被发往相同的topic和Partition
5.Kafka服务器处理上面的发送请求,同时抛出成功与否的响应消息,如果失败则重试。
1.1 bootstrap.servers:broker 的地址清单,地址的格式为host:port,至少提供两个broker信息
1.2 key.serializer 和 value.serializer:key和value的序列化方式,必须被设置为一个实现了org.apache.kafka.common.serialization.Serializer接口的类.Kafka 客户端默认提供了ByteArraySerializer(这个只做很少的事情)、StringSerializer和IntegerSerializer,因此,如果你只使用常见的几种Java 对象类型,那么就没必要实现自己的序列化器。
1.3 acks:acks=0,表示生产者在成功写入悄息之前不会等待任何来自服务器的响应。acks=1,表示只要集群的首领节点收到消息,生产者就会收到 一个来自服务器的成功响应。acks=all ,只有当所有参与复制的节点全部收到消息时,生产者才会收到一个来自服务器的成功响应。
延迟比较:acks=0<acks=1<acks=ALL
安全比较:acks=ALL>acks=1>acks=0
1.4 buffer.memory:生产者内存缓冲区的大小,生产者用它缓冲要发送到服务器的消息。
1.5 compresision.type:使用哪种压缩算法
1.6 retries:重试次数
1.7 batch.size:当有多个消息需要被发送到同一个分区时,生产者会把它们放在罔一个批次里。该参数指定了一个批次可以使用的内存大小。
1.8 max.in.flight.requests.per.connection:该参数指定了生产者在收到服务器晌应之前可以发送多少个批次的消息。一般设置为1,可以保证批次写入消息是有序的
2.1 同步发送:发送并等待服务端响应。
2.2 异步发送:这里还实现了一个回调函数,等待服务端响应时处理。
2.3 发送并忘记:最简单的同步发送方式。
第二段我们提到了如果使用Kafka默认的序列化器,比如JSON 、Avro 、Thrift或Protobuf,则没必要实现序列化器。但是默认的序列化器并不能满足大部分场景的需求,我们可以实现自定义的序列化器类。
此前我们提到,一个ProducerRecord除了包含目标主题和发送内容,还可以设置键值。这个键值既可以作为附加信息,又可以决定消息被发送到哪个分区。对于分区策略,Kafka默认的分区策略是轮询算法,当然也可以实现自定义分区策略。
参考资料:《Kafka权威指南》
Kafka02--Kafka生产者简要原理
前言
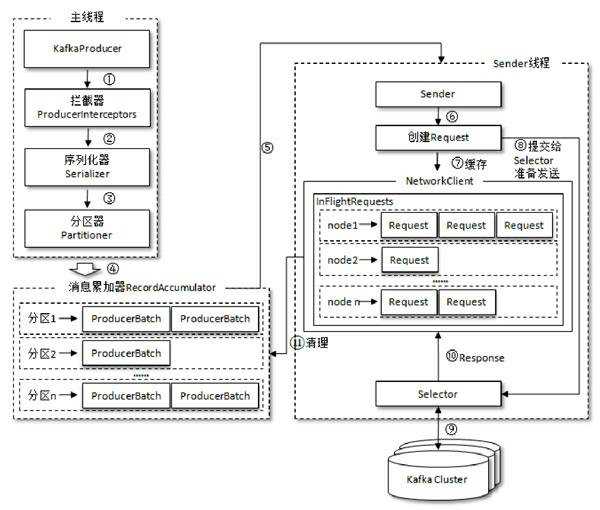
在Kafka01--Kafka生产者使用方式中对KafkaProducer的基本使用方式进行了了解。以上只是使用方面,一个好的开元框架必定是易于开发者使用的,但是对生产者的基本逻辑流程和数据流转并没有什么概念。
KafkaProducer原理分析
以上是关于Kafka生产者的主要内容,如果未能解决你的问题,请参考以下文章