Redis进阶学习05---Feed流,GEO地理坐标的应用,bitmap的应用,HyperLogLog实现UV统计
Posted 大忽悠爱忽悠
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis进阶学习05---Feed流,GEO地理坐标的应用,bitmap的应用,HyperLogLog实现UV统计相关的知识,希望对你有一定的参考价值。
Redis进阶学习05---Redis进阶学习05---Feed流和GEO地理坐标的应用
点赞功能
这部分内容比较简单,没啥难度,因此我不打算进行具体代码实践演示,只是给出完整的解决思路和其中的注意事项
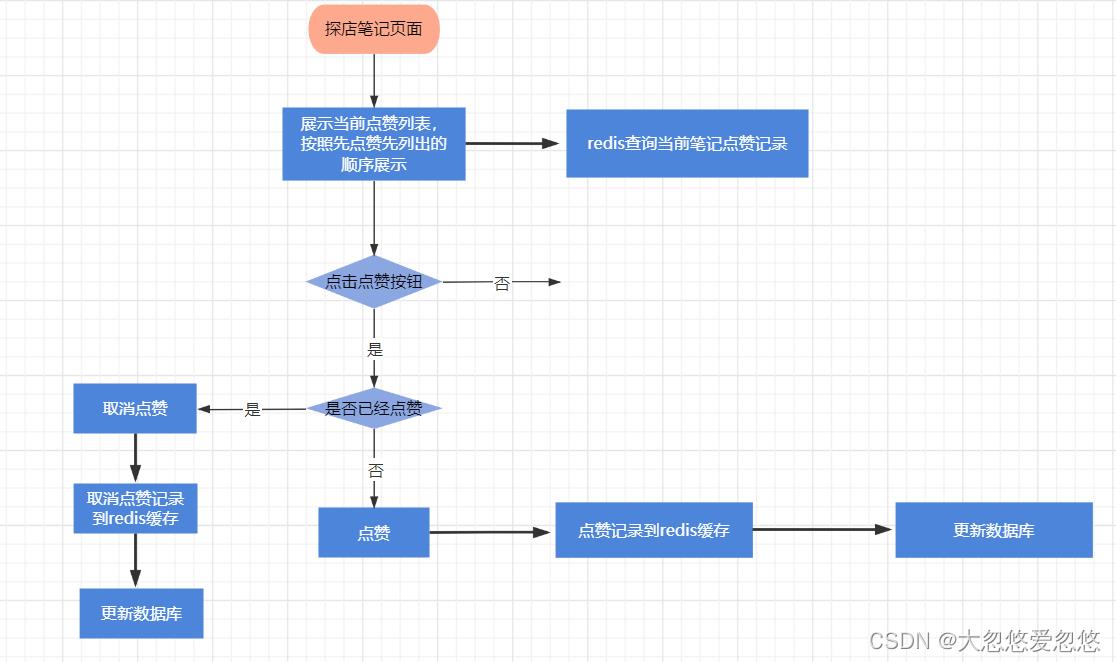
主要是将用户点赞的行为记录到redis进行缓存,然后查询的时候直接走redis缓存即可
下面我们考虑一下,该使用redis中什么样的数据结构来存放用户点赞这个行为,首先同一个用户不能重复对一篇笔记点赞,然后我们需要获取的信息是一篇笔记被哪些用户点赞过,并且返回的数据是按照时间顺序排序的

显然我们应该选取sortedSet集合来完成这个功能
具体实现就不多讲了,这里额外提一嘴mysql的in查询的小问题:
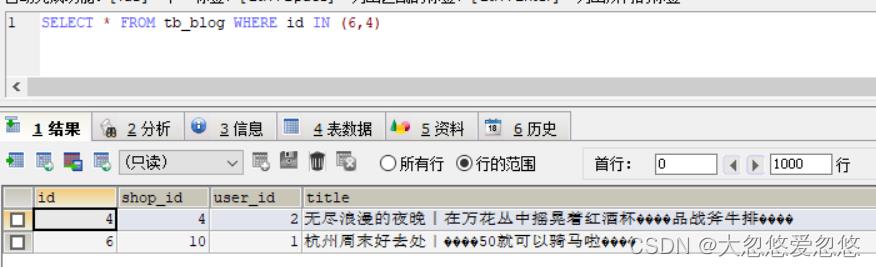
我们的想法是按照6,4的顺序返回,但是mysql查询结果返回的是按照4,6的顺序,因为这里是通过聚簇索引进行查询的,而聚簇索引是按照主键id进行降序排序的,因此这里id显示是先4,后6.
这个问题在各位想要处理点赞用户列表按照时间升序排列时,会出现这个问题,解决方法就是我们可以自定义mysql排序规则:
SELECT * FROM tb_blog WHERE id IN (6,4) ORDER BY FIELD(id,6,4)
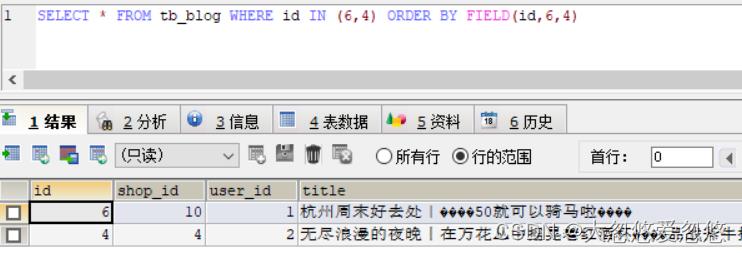
原理:
FIELD()函数是将参数1的字段对后续参数进行比较,并返回1、2、3等等,如果遇到null或者没有在结果集上存在的数据,则返回0,然后根据升序进行排序。
共同关注
如果我们要查看两个用户共同关注的用户,其实就是求交集,相信各位第一时间就想到了redis的set集合的interact求交集方法
所以,我们需要在关注这一步,使用redis的set集合,记录下当前用户关注的所有人,然后在取消关注的时候,再从set集合移除掉对应取关的用户id

具体代码实现这里就不提供了,因为逻辑很简单,各位可以自行实现
关注推送
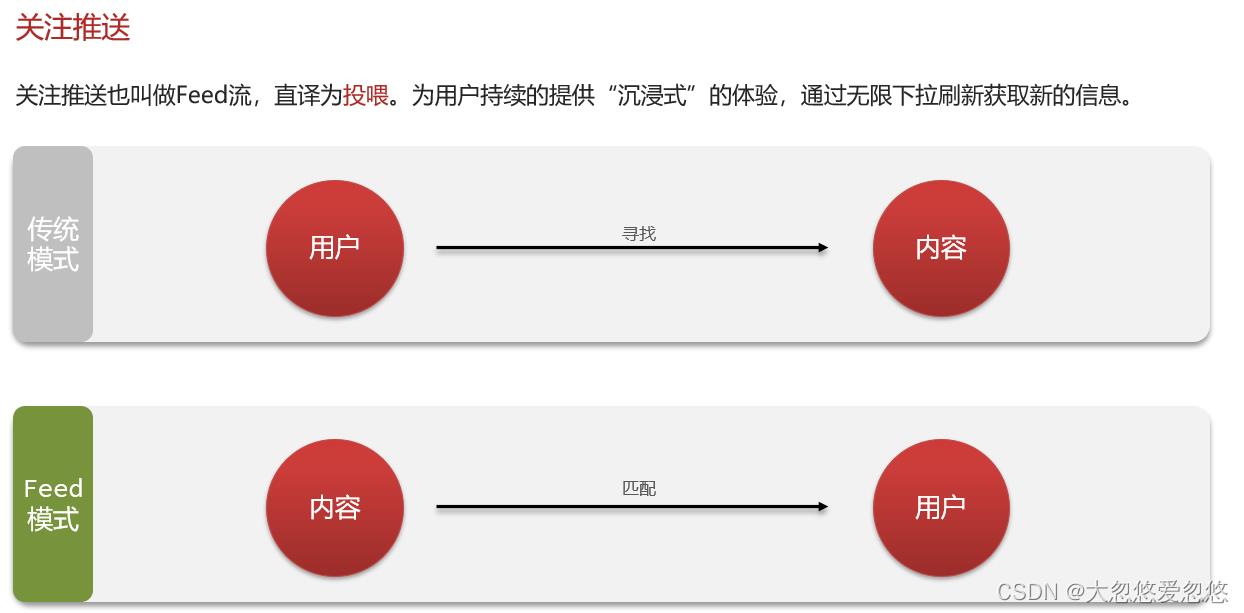

拉模式
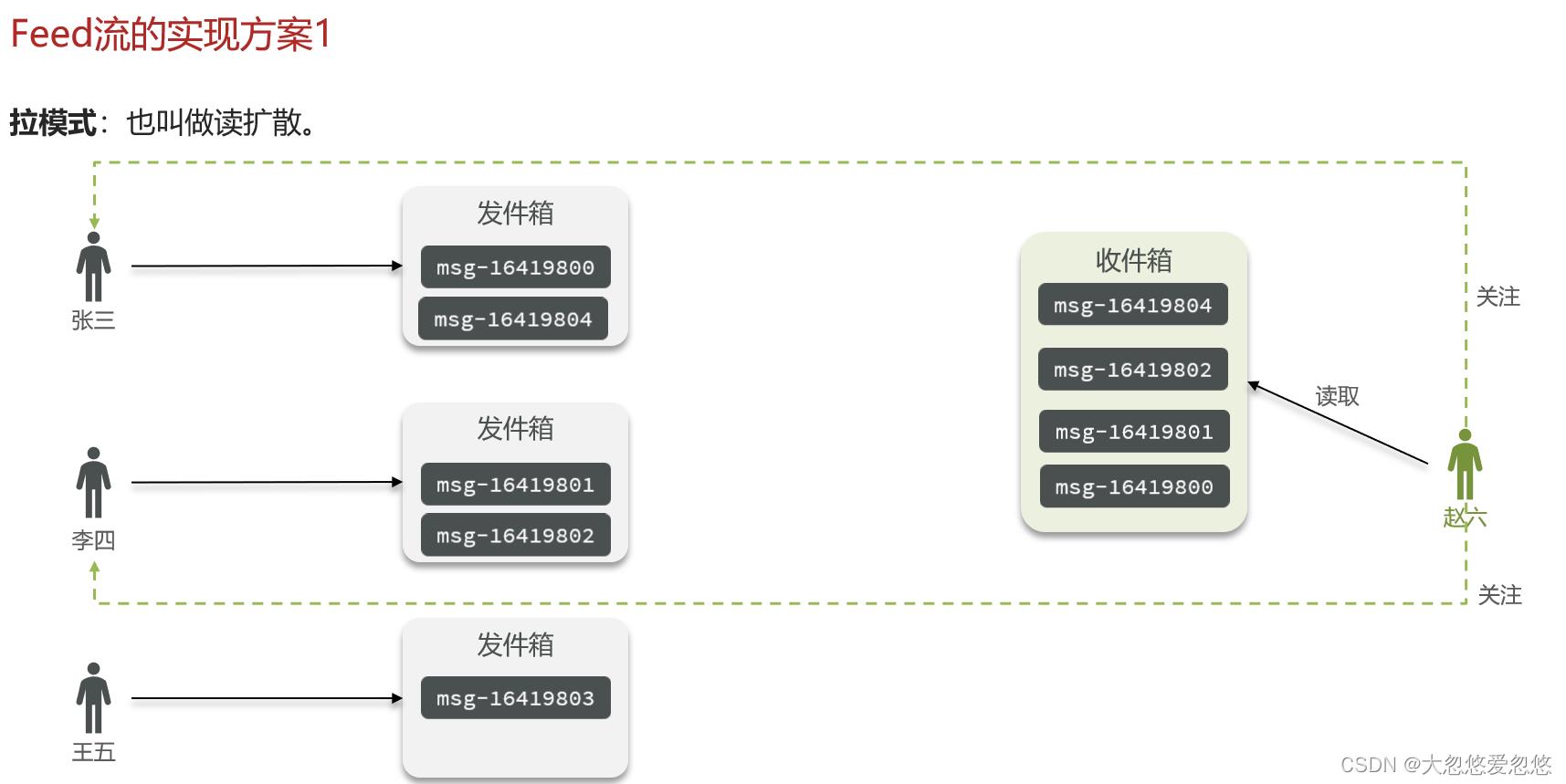
拉模式顾名思义就是用户主动去拉取他所关注的用户发布的信息,该模式最大缺点是延迟高,因为一下子需要去拉取大量的消息,优点是占用内存少,因为消息只需要存一份在发件箱,而收件箱消息一般读完就不需要用了,可以直接删除
推模式
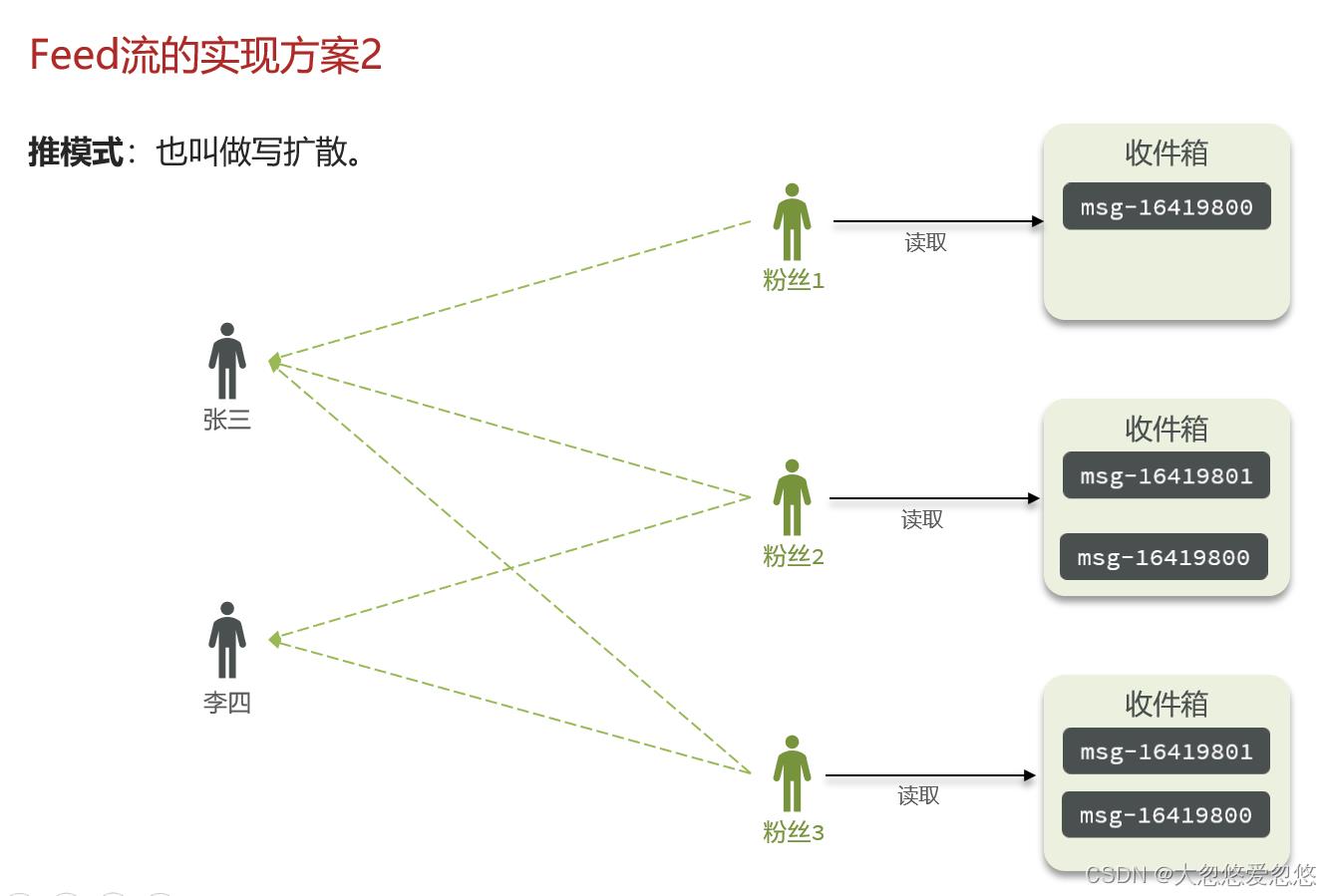
推模式就是用户在发消息的时候,不会先将消息放入收件箱等着粉丝来取,而是直接把这些消息发送给所有关注了他的粉丝们,这样粉丝读取消息的延迟低了,因为不需要再去拉取一遍了。最大的缺点是每一份消息都需要被赋值多份进行存储,对内存消耗大
推拉结合
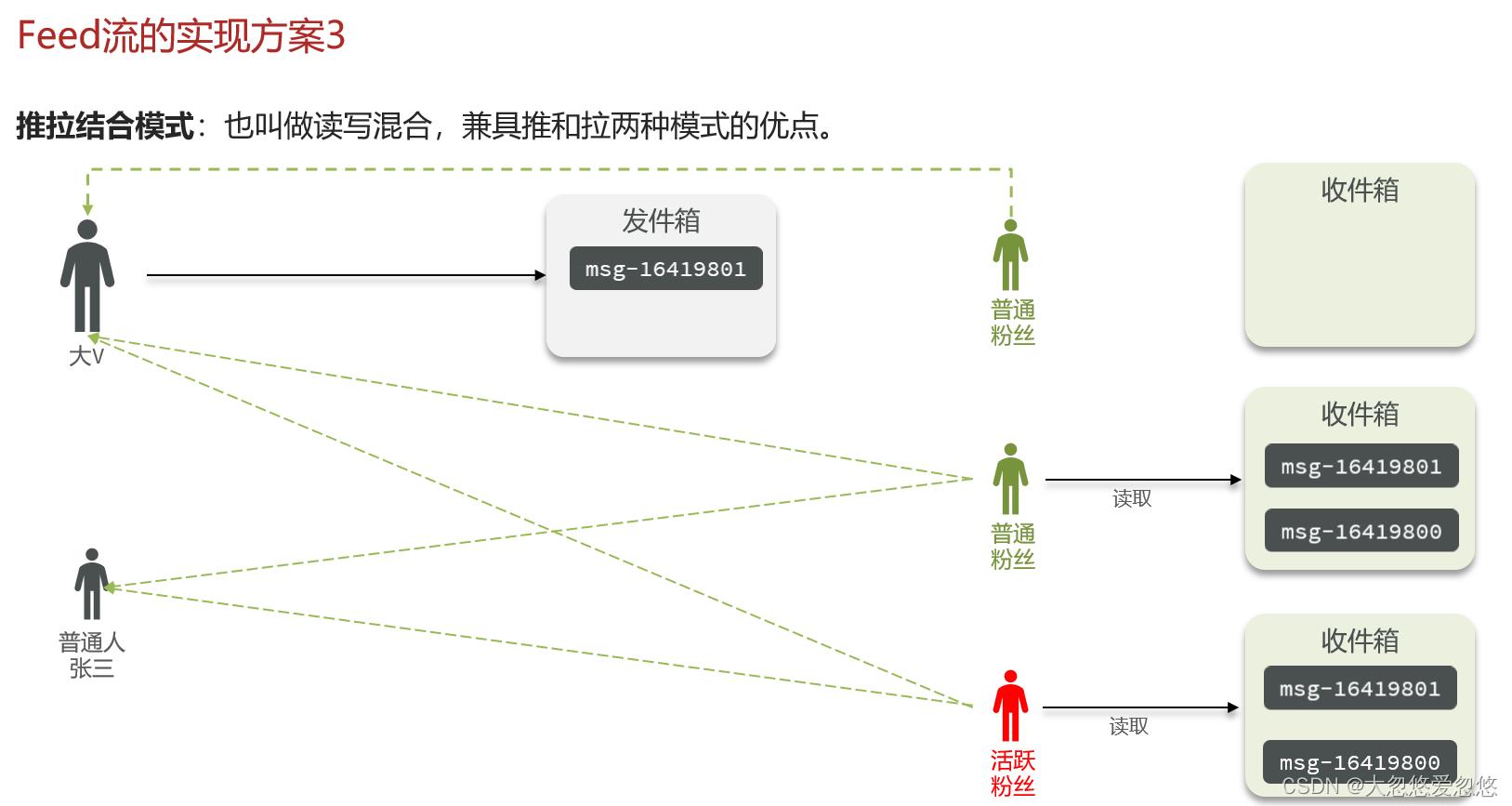
针对不同用户采用不同的推拉模式,例如: 对于活跃粉丝来说,因为其需要频繁读取,我们需要考虑其读取的延迟性,因此采用推模式。
对于普通粉丝来说,其访问频率很低,我们可以采用拉模式,等到哪一天他上线了,想要查看消息的时候,去拉一下即可,而如果该粉丝一直不上线,那么就无需接收任何消息,这样一来就可以节约内存。
小结
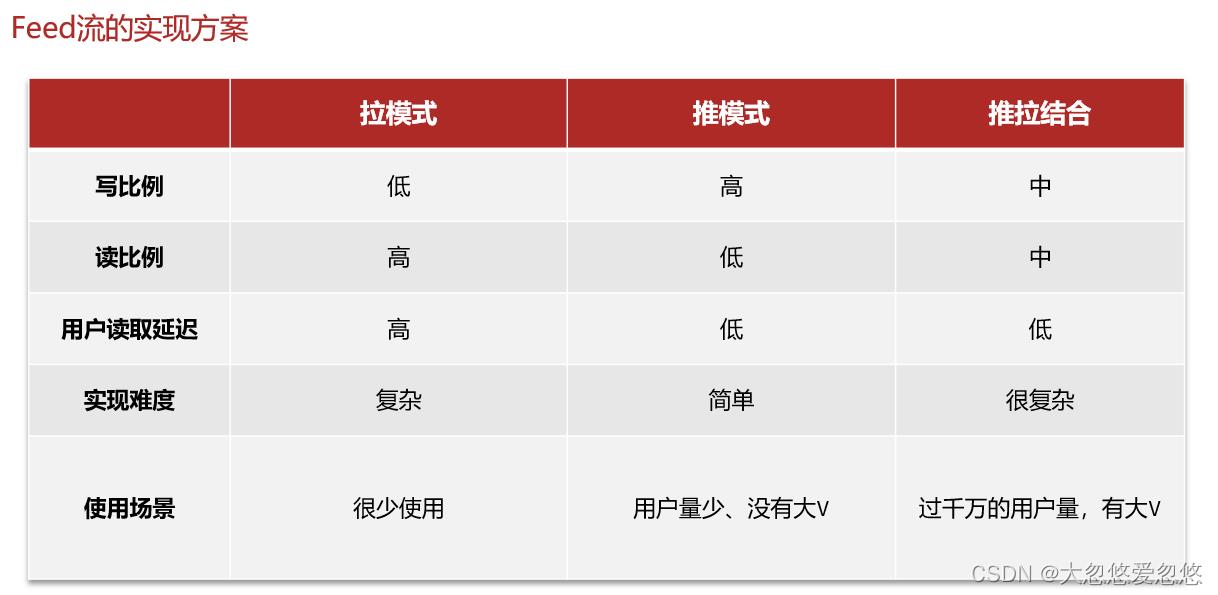
基于推模式实现关注推送

因为数据需要有序,因此我们很自然联想到了list集合和sortedSet
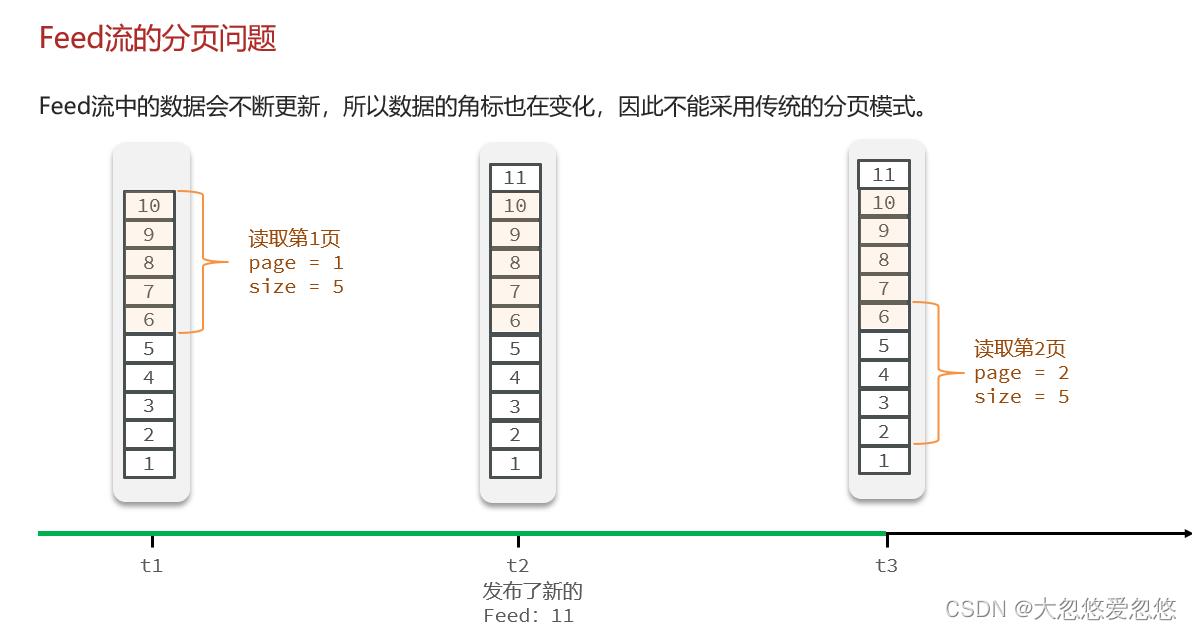
传统分页模式可以使用list集合实现
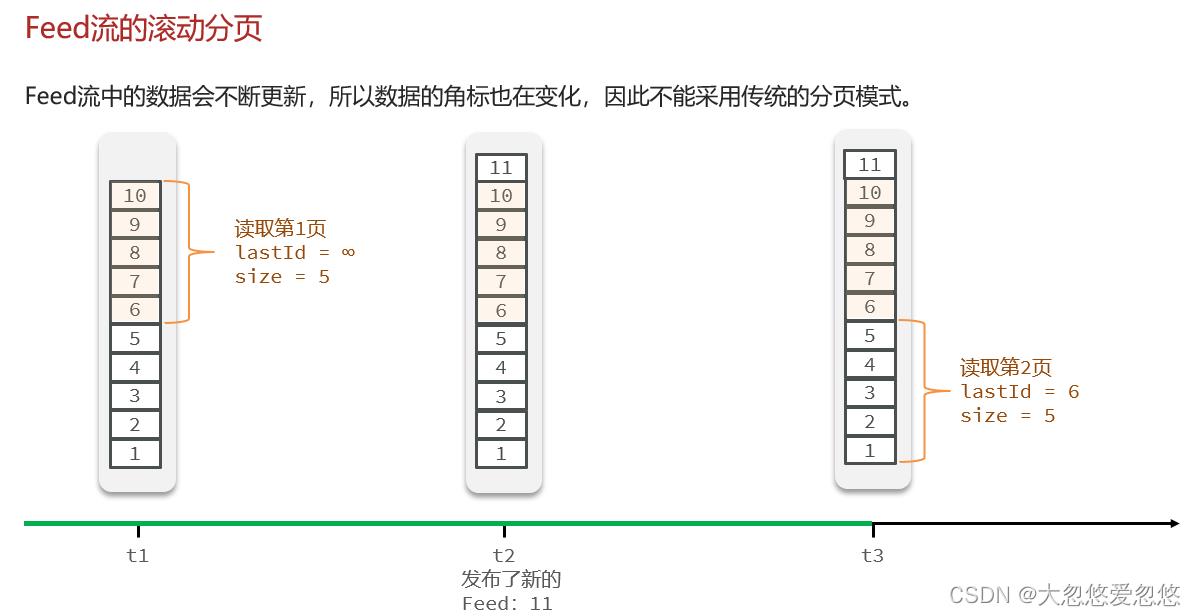
sortedSet可以利用score排名作为角标,来完成根据角标进行分页的功能
发布博客的代码如下:
@Service
public class BlogServiceImpl extends ServiceImpl<BlogMapper, Blog> implements IBlogService
@Autowired
private IFollowService iFollowService;
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Override
public Result saveBlog(Blog blog)
// 获取登录用户
UserDTO user = UserHolder.getUser();
blog.setUserId(user.getId());
// 保存探店博文
boolean save = save(blog);
if(!save)
return Result.fail("新增失败");
//查询笔记作者的所有粉丝,推送笔记id给所有粉丝
List<Follow> follows = iFollowService.query().eq("follow_user_id", user.getId()).list();
//4.推送笔记id给所有粉丝
for (Follow follow : follows)
//4.1获取粉丝id
Long userId = follow.getUserId();
//4.2推送--使用set集合进行存放
String key="feed:"+userId;
//score使用当前时间戳表示
stringRedisTemplate.opsForZSet().add(key,blog.getId().toString(), System.currentTimeMillis());
return Result.ok(blog.getId());
推送测试:

推送功能实现了,下面就是去实现指定用户下拉刷新查看被推送到的博客列表了
如何使用sorted_sort实现分页呢?
因为我们要使用降序排列,因此要选取命令前加上REV的

max和min指定了需要查询score分数的范围,offset是偏移量,count是个数
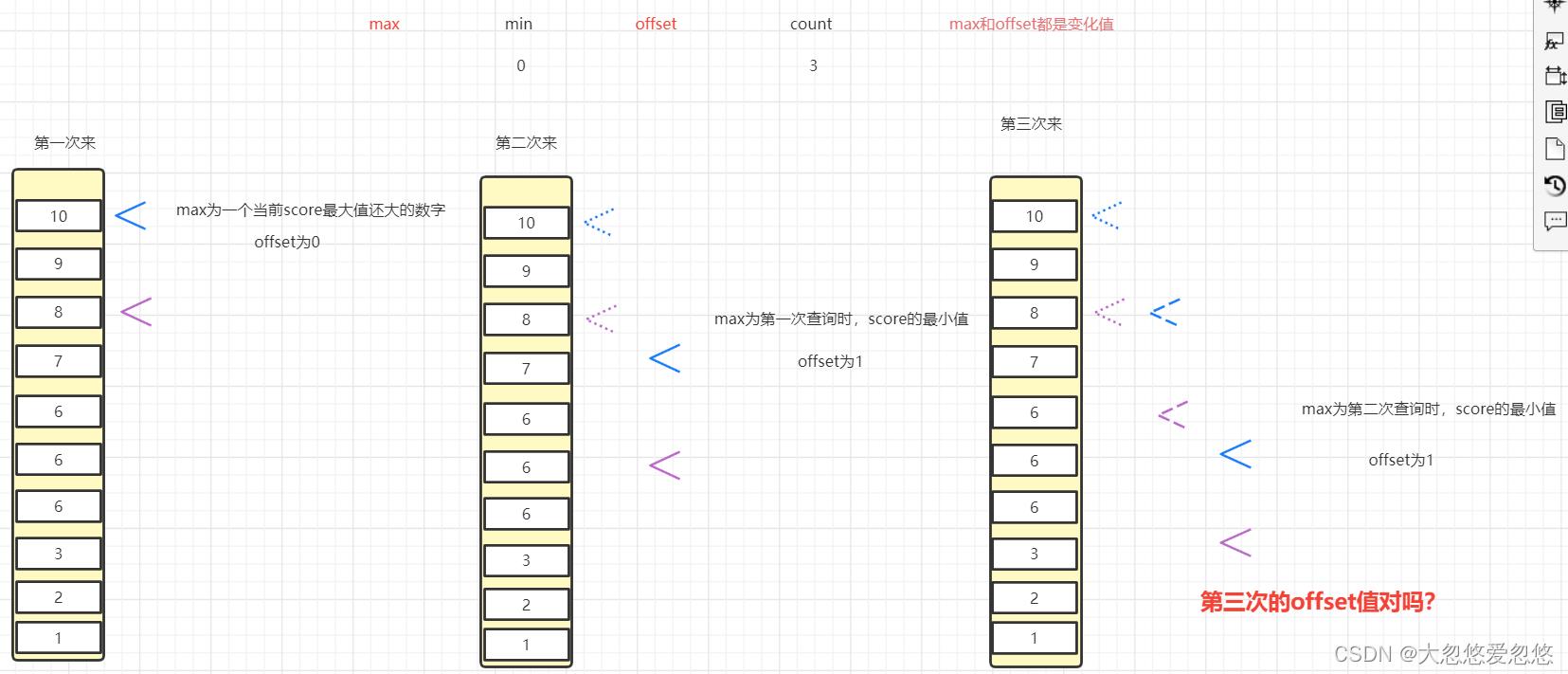
因为是降序查询,那么我们score的min最小值范围就应该为0,然后最大值第一次应该为当前时间戳,第二次应该为上次查询出来的分数最小值,然后count就是当前页显示的记录条数,应该为固定值,offset第一次应该为0,表示从当前分数范围内记录第一条开始返回,返回count个记录数
第二次查询时,offset应该给1,因为这里max是小于等于,即他会把上一次最小分数也算进去,因此我们需要去掉该记录,偏移量为1
但是这里还是有一个问题,就是如果上一次最小分数的记录同时存在多条的话,那么我们的offset就应该为这多条记录的数量,而不能是一了
具体代码实现分页
先准备一个用户存储分页结果的对象
@Data
public class ScrollResult
private List<?> list;
private Long minTime;
private Integer offset;
分页查询代码:
@Override
public Result queryBlogOfFollow(Long max, Integer offset)
//1.获取当前用户
Long id = UserHolder.getUser().getId();
//2.查询收件箱
String key=FEED_KEY+id;
Set<ZSetOperations.TypedTuple<String>> scores = stringRedisTemplate.opsForZSet()
.reverseRangeByScoreWithScores(key, 0, max, offset, 2);
if(scores==null||scores.isEmpty())
return Result.ok(Collections.emptyList());
List<Long> ids=new ArrayList<>(scores.size());
//上一次查询的最小时间戳
Long mintime=0L;
//相同最小时间戳的个数
int count=1;
for (ZSetOperations.TypedTuple<String> typedTuple : scores)
//获取id
ids.add(Long.valueOf(typedTuple.getValue()));
//获取分数(时间戳)
long timeValue = typedTuple.getScore().longValue();
if(mintime==timeValue)
count++;
else
mintime=timeValue;
count=1;
//查询博客列表返回
//listByIds底层是使用in查询,in查询默认升序,与我们需要的降序规则不符,我们需要手动指定排序规则
String idStr = StrUtil.join(",", ids);
List<Blog> blogs = query().in("id",ids).last("ORDER BY FIELD(id,"+idStr+")").list();
//封装并返回
ScrollResult r=new ScrollResult();
r.setList(blogs);
r.setOffset(count);
r.setMinTime(mintime);
return Result.ok(r);

附近商户
GEO数据结构

geo底层是zset
附近商铺搜索
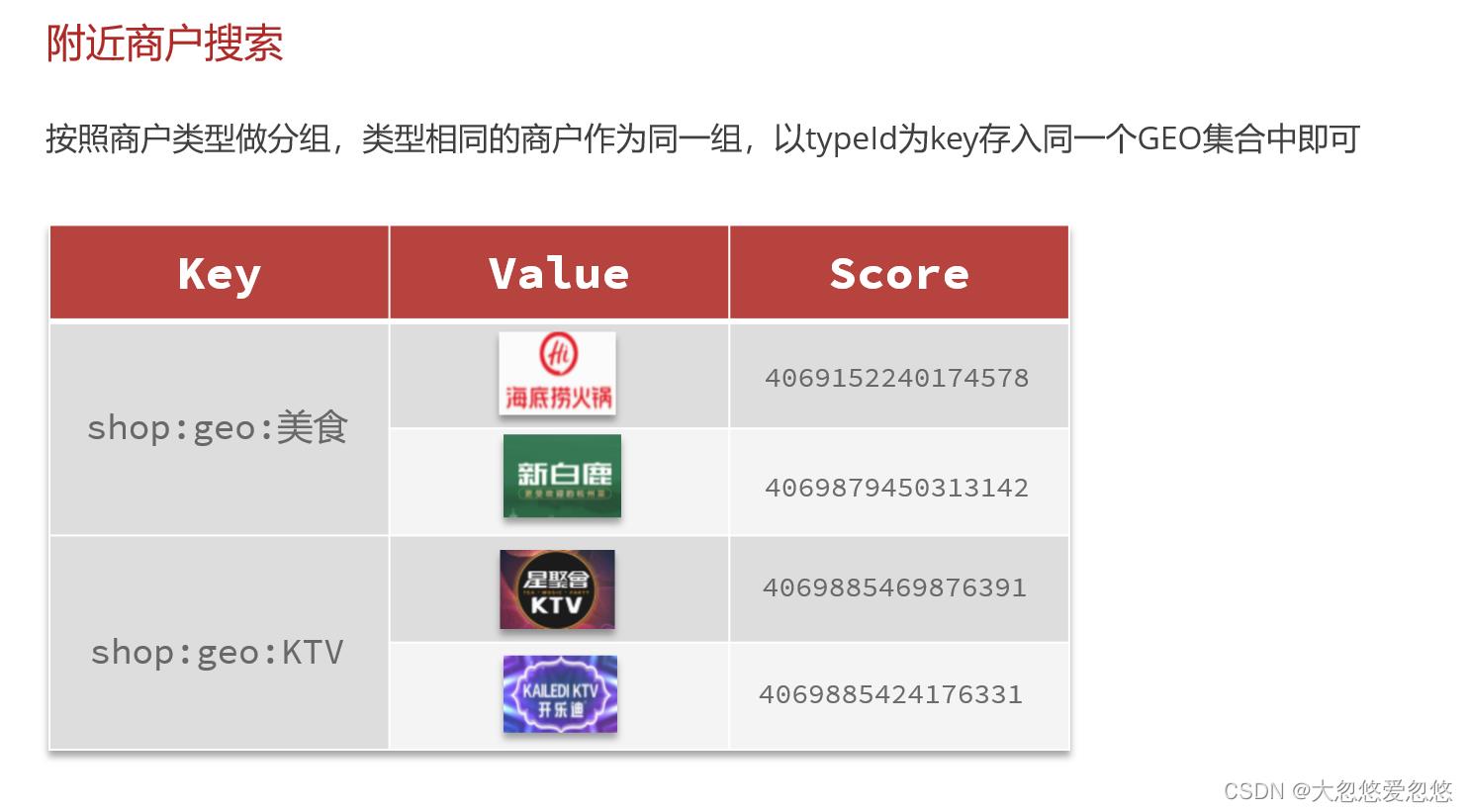
Score是经纬度计算得到的hash字符串
从数据库导入附近商铺信息数据到Redis
@Test
public void loadShopData()
//1.查询店铺信息
List<Shop> list = shopService.list();
//2.把店铺分组,按照typeId分组
Map<Long, List<Shop>> collect = list.stream().collect(Collectors.groupingBy(Shop::getTypeId));
//3.分批写入redis
for (Map.Entry<Long, List<Shop>> entry : collect.entrySet())
//获取类型id
Long typeId = entry.getKey();
String key = SHOP_GEO_KEY + typeId;
//获取同类型的店铺的集合
List<Shop> value = entry.getValue();
List<RedisGeoCommands.GeoLocation<String>> locations=new ArrayList<>(value.size());
//写入redis GEOADD key 经度,纬度,member
for (Shop shop : value)
locations.add(new RedisGeoCommands.GeoLocation<String>(
shop.getId().toString(),
new Point(shop.getX(),shop.getY())
));
stringRedisTemplate.opsForGeo().add(key,locations);

SpringDataRedis的2.3.9版本并不支持Redis 6.2提供的GEOSEARCH命令,因此我们需要提升版本,修改自己的pom文件,如下:
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
</exclusion>
<exclusion>
<groupId>lettuce-core</groupId>
<artifactId>io.lettuce</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
<version>2.6.2</version>
</dependency>
<dependency>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
<version>6.1.8.RELEASE</version>
</dependency>
代码应用:
@Override
public Result queryShopByType(Integer typeId, Integer current, Double x, Double y)
//判断是否需要根据坐标查询
if(x==null||y==null)
//不需要坐标查询,按数据库查询
Page<Shop> page = query().eq("type_id", typeId)
.page(new Page<>(current, SystemConstants.DEFAULT_PAGE_SIZE));
//返回数据
return Result.ok(page.getRecords());
//计算分页参数---current页码
int from=(current-1)*SystemConstants.DEFAULT_PAGE_SIZE;
int end=current*SystemConstants.DEFAULT_PAGE_SIZE;
//查询redis,按照距离排序,分页。
String key=SHOP_GEO_KEY+typeId;
//GEOSEARCH key BYLONLAT x y BYRADIUS 10 WITHDISTANCE
GeoResults<RedisGeoCommands.GeoLocation<String>> list = stringRedisTemplate.opsForGeo()
.search(key,
//指定中心点--经纬度
GeoReference.fromCoordinate(x, y),
//搜索半径--默认单位为米
new Distance(5000),
//结果里面带上距离
RedisGeoCommands.GeoSearchCommandArgs.newGeoSearchArgs().includeDistance()
//从第一条开始到end条记录后结束--我们需要手动剪裁出from部分
.limit(end));
//解析出id
if (list == null)
return Result.ok(EMPTY_LIST);
List<GeoResult<RedisGeoCommands.GeoLocation<String>>> content = list.getContent();
if(content.size()<from)
return Result.ok(EMPTY_LIST);
//截取from~end部分
ArrayList<Object> ids = new ArrayList<>(content.size());
HashMap<Object, Distance> distanceMap = new HashMap<>(content.size());
content.stream().skip(from).forEach(res->
//获取店铺id
String shopIdStr = res.getContent().getName();
ids.add(Long.valueOf(shopIdStr));
//获取距离
Distance distance = res.getDistance();
distanceMap.put(shopIdStr,distance);
);
//根据id查询shop
String idStr = StrUtil.join(",", ids);
List<Shop> shops = query().in("id", ids).last("ORDER BY FIELD(id," + idStr + ")").list();
for (Shop shop : shops)
shop.setDistance(distanceMap.get(shop.getId().toString()).getValue());
return Result.ok(shops);
签到
BitMap学习



签到功能实现

代码:
@Override
public Result sign()
//1.获取当前登录用户
Long userId = UserHolder.getUser().getId();
//2.获取日期
LocalDateTime now = LocalDateTime.now();
//拼接key
String format = now.format(DateTimeFormatter.ofPattern(":yyyy/MM"));
String key=USER_SIGN_KEY+userId+format;
//获取今天是本月的第几天
int dayOfMonth = now.getDayOfMonth();
//写入redis setbit key offset 1
stringRedisTemplate.opsForValue().setBit(key,dayOfMonth-1,true);
return Result.ok();
连续签到统计

获取当然用户本月的签到记录—bitmap,然后从从该bitmap最后一位开始与1做与运算,通过不断累加得到结果为1的数量,来计算出本月连续签到的天数,直到某次与运算结果为0返回

@Override
public Result signCount()
//1.获取当前登录用户
Long userId = UserHolder.以上是关于Redis进阶学习05---Feed流,GEO地理坐标的应用,bitmap的应用,HyperLogLog实现UV统计的主要内容,如果未能解决你的问题,请参考以下文章