推荐系统学习05-libFM
Posted Lenskit
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了推荐系统学习05-libFM相关的知识,希望对你有一定的参考价值。
介绍
分解机(FM)是一个通过特征工程模拟大多数分解模型的通用方法。libFM是一个实现以随机梯度下降stochastic gradient descent (SGD)和可选择最小二乘alternating least squares (ALS) optimization以及使用蒙特卡洛的贝叶斯推理Bayesian inference using Markov Chain Monte Carlo (MCMC)为特征的分解机的软件。
原句:libFM is a software implementation for factorization machines that features stochastic gradient descent (SGD) and alternating least squares (ALS) optimization as well as Bayesian inference using Markov Chain Monte Carlo (MCMC).
项目github主页:https://github.com/srendle/libfm
文件一览:

编译
进入libfm-1.42.src目录,输入 “make all”
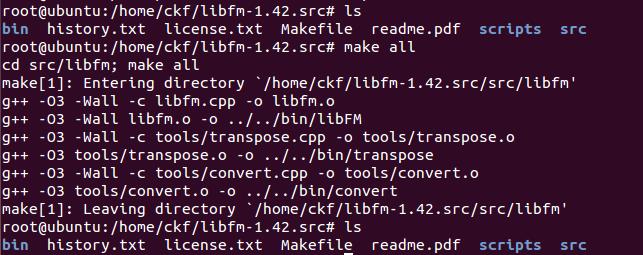
bin目录下有convert、transpose和libFM三个可执行文件。
convert:Converting Recommender Files
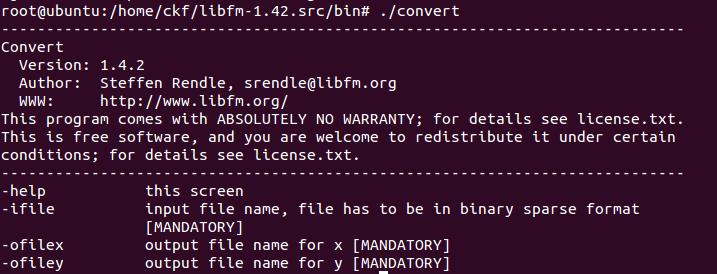
libFM(这里有很多参数,后面会说)

transpose:For MCMC and ALS learning, a transposed design matrix is used
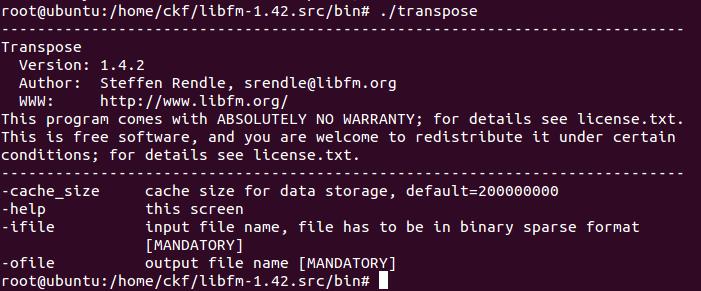
参数说明
补充,刚刚上面显示的libFM命令中有很多参数,分为强制性参数(运行时必须指定)和可选参数。
强制参数

即task要指定,到底是classification还是regression,分类还是回归。
train和test数据集要指定。
dim要指定,k0,k1,k2。
下面举个例子: An FM for a regression task using bias, 1-way interactions and a factorization of k = 8 for pairwise interactions:
./libFM -task r -train ml1m-train.libfm -test ml1m-test.libfm -dim ’1,1,8’ 
可选参数,又分为基本参数和高级参数。
基本参数

out:将测试数据集的预测写到指定的文件。
rlog:一个关于统计生成的每次迭代的日志文件。
verbosity:verbosity参数1,可以让libFM打印更多信息。这对检查数据是否正确寻找错误很有用。
高级参数


即可用meta选项给输入变量分组。分组可以在 MCMC, SGDA和ALS用到,来定义更加复杂的正则化结构。
还有一个是cache选项,如果内存不够,可以设置缓存大小。
下面是具体Learning Methods(下面例子中我用的数据集都是ijcnn1的)
By default MCMC inference is used for learning because MCMC is the most easiest to handle (no learning rate, no regularization). In libFM you can choose from the following learning methods: SGD, ALS, MCMC and SGDA. For all learning methods, the number of iterations iter has to be specified.
操作
libFM的输入数据支持两种文件格式:txt格式和二进制格式。txt推荐新手使用。
数据格式跟SVMlite和 LIBSVM的一样: Each row contains a training case (x,y) for the real-valued feature vector x with the target y. The row states first the value y and then the non-zero values of x. For binary classification, cases with y > 0 are regarded as the positive class and with y ≤ 0 as the negative class.
Example
4 0:1.5 3:-7.9
2 1:1e-5 3:2
-1 6:1 ...
这个文件包含三个案例。第一列表明了这三个案例分别的目标,即4是第一个目标,2是第二个目标,-1是第三个目标。在目标之后,每行都包含了x的非零元素,0:1意味着 x0 = 1.5, 3:-7.9 意味着 x3 = −7.9,即 xINDEX = VALUE.
上面例子就是下面的图:设计矩阵x和目标矩阵y

下面介绍一些操作
Converting Recommender Files
在推荐系统中,一个像 userid itemid rating 这样的文件格式经常被使用。一个把这样数据集(或者更加复杂的像在上下文感知设置中)转换libFM文件格式的perl脚本在scripts目录中,使用:
./triple_format_to_libfm.pl -in ratings.dat -target 2 -delete_column 3 -separator "::"如果一个单数据集包含多个文件,比如,一个train和一个test分部,那么转换脚本应该把两个文件都写进去:
./triple_format_to_libfm.pl -in train.txt,test.txt -target 2 -separator "\\t"
其余具体转换自行阅读项目中的readme。(转换为.x,.y和.xt)
示例
要说明一下的是,现在网上找train和test数据集还是挺难的,因为现在MovieLens提供的数据集需要你手动分割。幸好还有一个网站上可以找到train和test数据集,https://www.csie.ntu.edu.tw/~cjlin/libsvmtools/datasets/,也就是LibSVM format,这上面的数据集是libFM支持的。
我找的是binary类型的,ijcnn1数据集

Stochastic Gradient Descent (SGD)

example
./libFM -task r -train ml1m-train.libfm -test ml1m-test.libfm -dim ’1,1,8’ -iter 1000 -method sgd
-learn_rate 0.01 -regular ’0,0,0.01’ -init_stdev 0.1
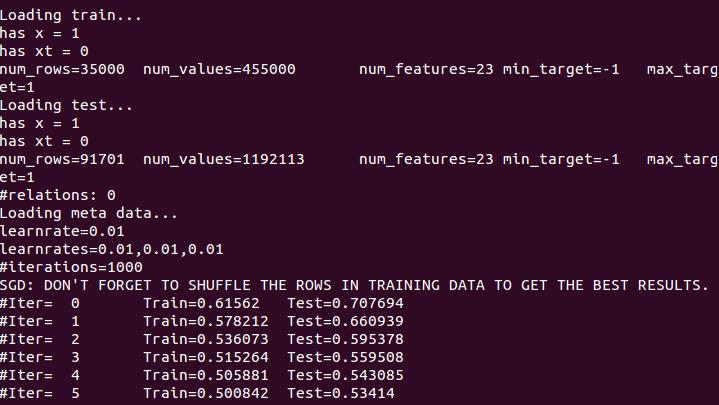
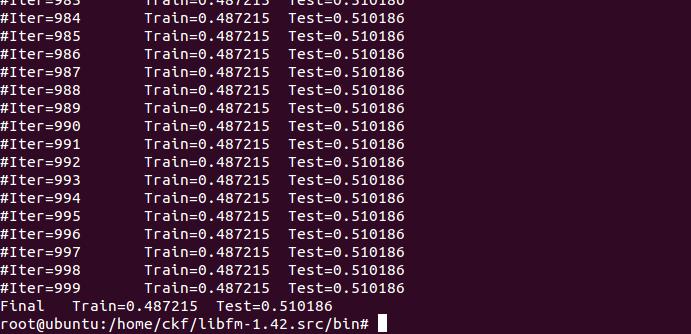
Alternating Least Squares (ALS)

Example
./libFM -task r -train ml1m-train.libfm -test ml1m-test.libfm -dim ’1,1,8’ -iter 1000 -method als
-regular ’0,0,10’ -init_stdev 0.1


Markov Chain Monte Carlo (MCMC)

Example
./libFM -task r -train ml1m-train.libfm -test ml1m-test.libfm -dim ’1,1,8’ -iter 1000
-method mcmc -init_stdev 0.1

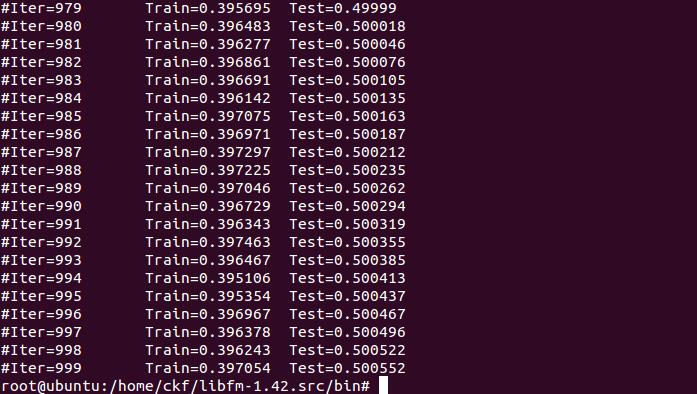
其余事例可查阅项目中的readme。
以上是关于推荐系统学习05-libFM的主要内容,如果未能解决你的问题,请参考以下文章