Elasticsearch超详学习
Posted Link.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch超详学习相关的知识,希望对你有一定的参考价值。
Elasticsearch学习
- 一、ElasticSearch简介
- 二、Elasticsearch核心概念
- 三、Elasticsearch 安装
- 四、ElasticSearch的客户端操作
- 五、IK分词器
- 六、Kibana使用
- 七、使用Java编程操作ElasticSearch
- 八、Spring Data ElasticSearch
一、ElasticSearch简介
1.什么是ElasticSearch
Elaticsearch,简称为es
-
E:EalsticSearch 搜索和分析的功能
-
L:Logstach 搜集数据的功能,类似于flume,是日志收集系统
-
K:Kibana 数据可视化,可以用图表的方式来去展示,文不如表,表不如图,是数据可视化平台
-
es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
2.es的优点
-
具有分布式的功能
-
数据高可用,集群高可用
-
API简单
-
多语言支持
-
支持PB级别的数据
-
完成搜索的功能和分析功能
-
基于Lucene,隐藏了Lucene的复杂性,提供简单的API
二、Elasticsearch核心概念
1.索引 index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,还有一个订单数据的索引。在一个集群中,可以定义任意多的索引。我们在使用mysql或者Oracle的时候,为了区分数据,我们会建立不同的数据库,库下面还有表的。es功能就像一个关系型数据库,在这个数据库我们可以往里面添加数据,查询数据。
2.类型 type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。好比数据库里面的一张表。相当于表结构的描述,描述每个字段的类型
3.字段Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
4.映射 mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分析器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
5.文档 document
一个文档是一个可被索引的基础信息单元。文档就是最终的数据了,可以认为一个文档就是一条记录。是es里面最小的数据单元,就好比数据库表里面的一条数据
6.集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群
7.节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
8.分片 shards
-
一台服务器,无法存储大量的数据,es把一个index里面的数据,分为多个shard,分布式的存储在各个服务器上面。
-
作用:水平分割/扩展你的内容容量。
- 在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
9.复制 replicas
-
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,es允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
-
作用:在分片/节点失败的情况下,提供了高可用性。
- 扩展搜索量/吞吐量
-
默认情况下,es中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
10.理解
我们可以对应数据库来理解:
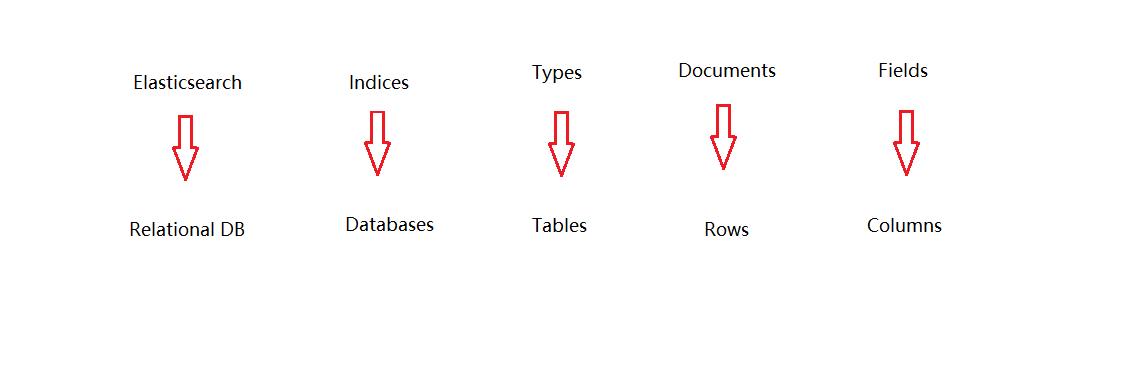
比如:书包含有书的类型、作者、价格
- 在数据库中表示如下:
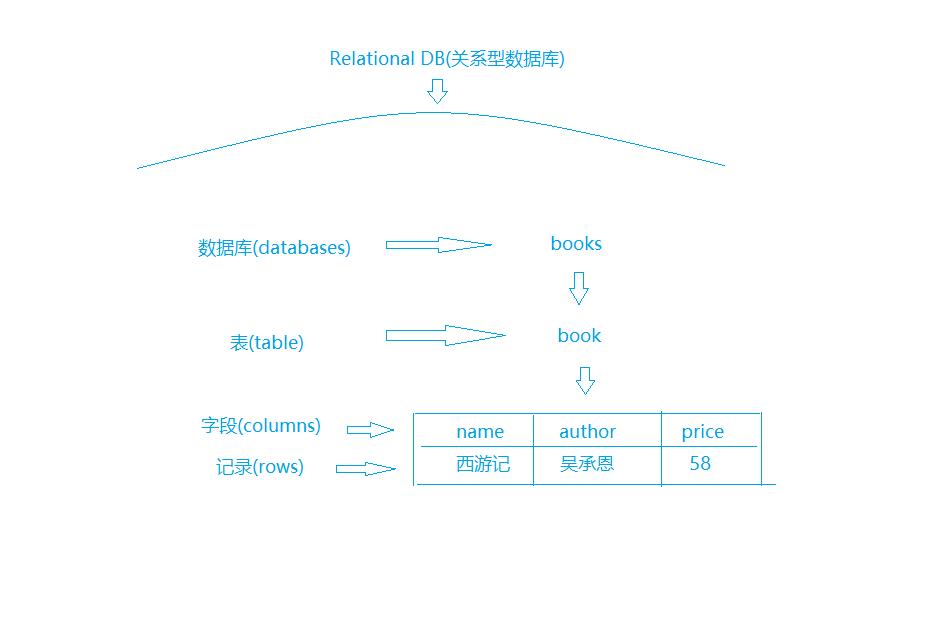
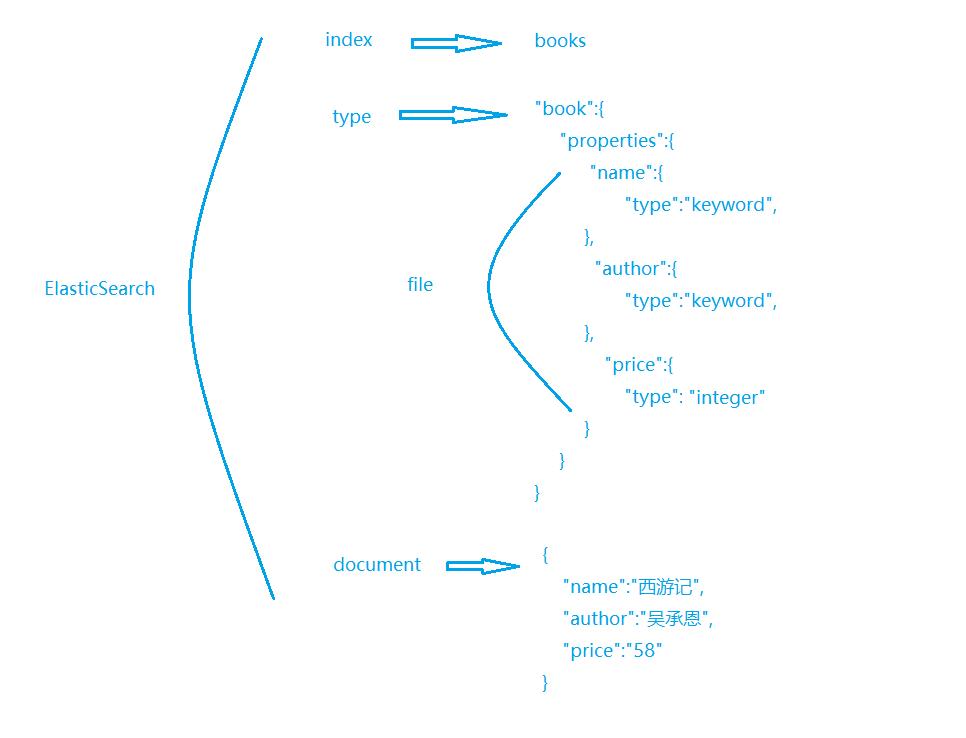
- 在es中表示如下:
- 首先建立一个名叫books 的索引,然后创建一个名叫 book 的类型,类型是通过 Mapping 来定义每个字段的类型
- 类型、作者都是 Keyword 类型,价格是Integer 类型,最后就是把数据组织成 Json 格式存放进去了。
三、Elasticsearch 安装
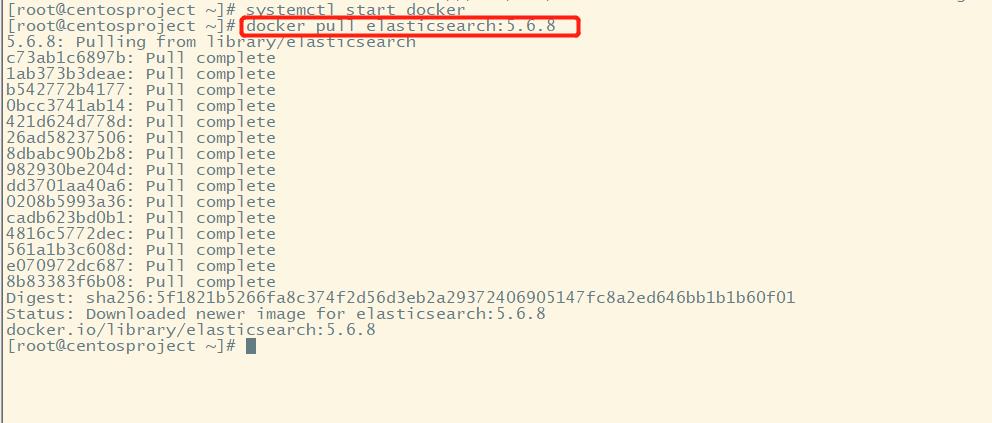
1.这里使用docker镜像下载
docker pull elasticsearch:5.6.8
如图:
2.安装es容器
docker run -di --name=es -p 9200:9200 -p 9300:9300 elasticsearch:5.6.8
如图:

3.测试
9200端口为Web管理平台端口
9300为服务默认端口
浏览器输入地址访问: http://虚拟机IP地址:9200/

4.开启远程连接
上面完成安装后,es并不能正常使用,elasticsearch从5版本以后默认不开启远程连接,程序直接连接会报错误
我们需要修改es配置开启远程连接:
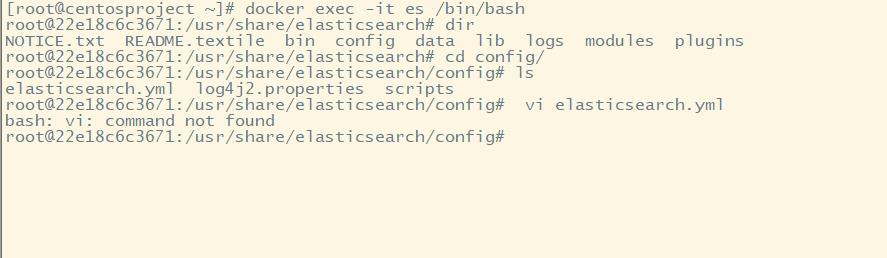
#1.进入容器
docker exec -it es /bin/bash
#2.进入config目录
cd config
#3.vi命令无法识别,因为docker容器里面没有该命令,我们可以安装该编辑器。
apt-get update
apt-get install vim
如图:
#4.等待安装好了后,修改elasticsearch.yml配置
vi elasticsearch.yml
#添加下面一行代码:
cluster.name: my-elasticsearch
如图:

#5.重启docker
docker restart es
5.出现问题
1.重启后发现重启启动失败了,因为elasticsearch在启动的时候会进行一些检查,比如最多打开的文件的个数以及虚拟内存区域数量等等,如果你放开了此配置,意味着需要打开更多的文件以及虚拟内存,所以我们还需要系统调优:
#6.修改limits.conf
vi/etc/security/limits.conf
#7.添加下面两行代码:
* soft nofile 65536
* hard nofile 65536
nofile是单个进程允许打开的最大文件个数
soft nofile 是软限制 hard nofile是硬限制
如图:

2.修改vi /etc/sysctl.conf
#8.修改sysctl.conf
vi /etc/sysctl.conf
#9.添加下面一行代码
#限制一个进程可以拥有的VMA(虚拟内存区域)的数量
vm.max_map_count=655360
如图:

#10.执行下面命令 修改内核参数马上生效
sysctl -p
#11.重启
reboot
6.跨域配置
#12修改配置文件:elasticsearch.yml增加三句命令
http.cors.enabled: true #允许elasticsearch跨域访问,默认是false
http.cors.allow-origin: "*" #表示跨域访问允许的域名地址
network.host: 192.168.220.100 #这里写自己的虚拟机地址
#13.重启docker
docker restart es
#如果想让容器开启重启,可以执行下面命令
docker update --restart=always 容器名称或者容器id
如图:

四、ElasticSearch的客户端操作
1.使用elasticsearch-head
ElasticSearch不同于Solr自带图形化界面,我们可以通过安装ElasticSearch的head插件,完成图形化界面的效果,完成索引数据的查看。
1.这里采用本地安装方式进行head插件的安装: 下载head插件
2.将elasticsearch-head-master压缩包解压到任意目录,要和elasticsearch的安装目录区别开
3. 下载nodejs
4. 将grunt安装为全局命令 ,Grunt是基于Node.js的项目构建工具
#在elasticsearch-head-master存放位置下输入cmd打开控制台
#输入如下执行命令:
1.cnpm install -g grunt-cli
如图:

#2.再输入指令
npm install
#3.将head插件启动
grunt server

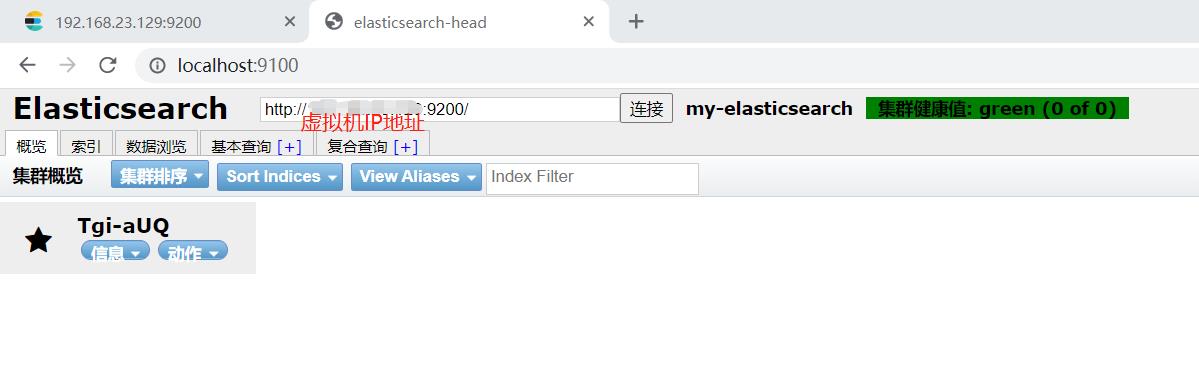
测试:打开浏览器,输入 http://localhost:9100
此时连接 http://虚拟机IP地址:9200可以看到健康值说明成功了
2.使用Postman工具进行Restful接口访问
2.1ElasticSearch的接口语法:
curl -X<VERB> '<PROTOCOL>://<HOST>:<PORT>/<PATH>?<QUERY_STRING>' -d '<BODY>
| 参数 | 解释 |
|---|---|
| VERB | 适当的 HTTP 方法 或 谓词 : GET 、 POST 、 PUT 、 HEAD 或者 DELETE |
| PROTOCOL | http 或者 https |
| HOST | Elasticsearch 集群中任意节点的主机名,或者用 localhost 代表本地机器上的节点 |
| PORT | 运行 Elasticsearch HTTP 服务的端口号,默认是 9200 |
| PATH | API 的终端路径 |
| QUERY_STRING | 任意可选的查询字符串参数 |
| BODY | 一个 JSON 格式的请求体 |
2.2创建索引index
- 创建索引(方式一)
#请求url:
PUT 192.168.23.129:9200/aaa
#请求体:
"mappings":
"article":
"properties":
"id":
"type": "long",
"store": true,
"index":"not_analyzed"
,
"title":
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"standard"
,
"content":
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"standard"
如图:
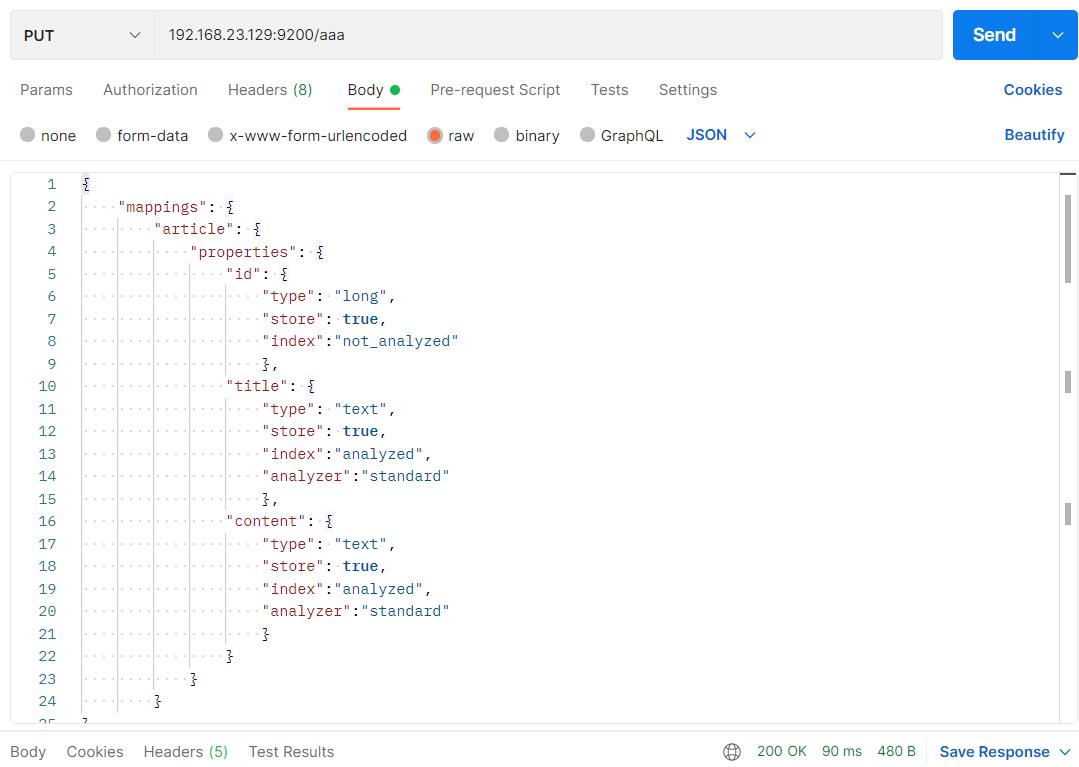
响应结果:

elasticsearch-head查看:
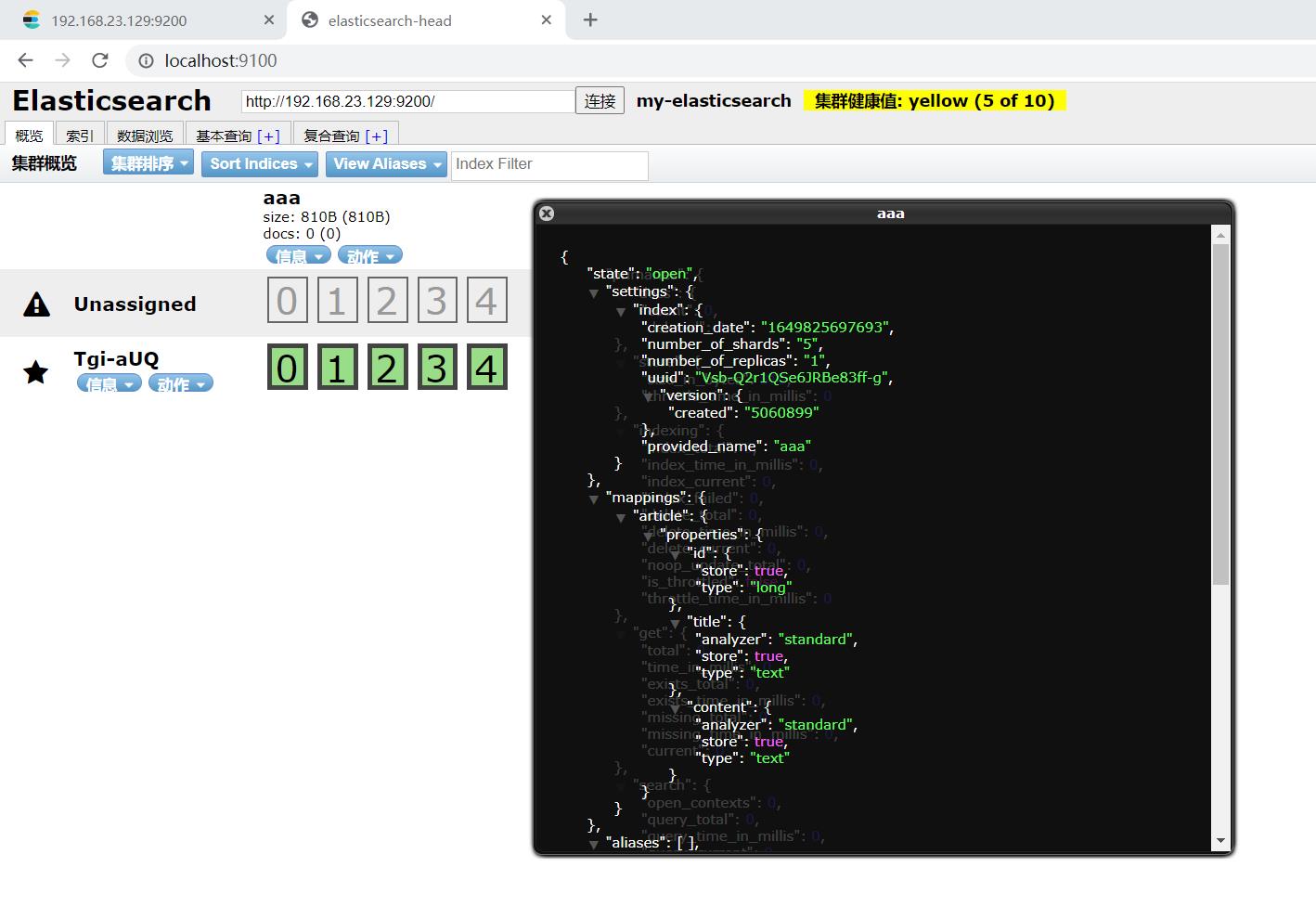
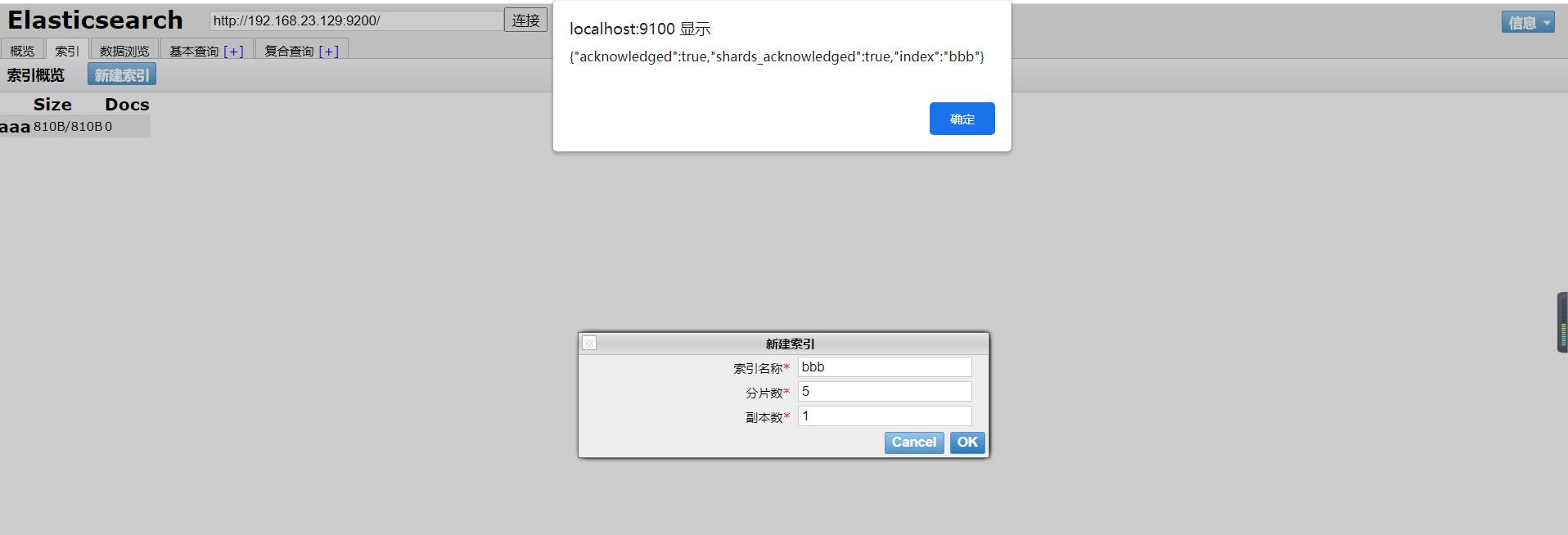
- 创建索引(方式二)
如图用head图形化界面工具里的新建索引:
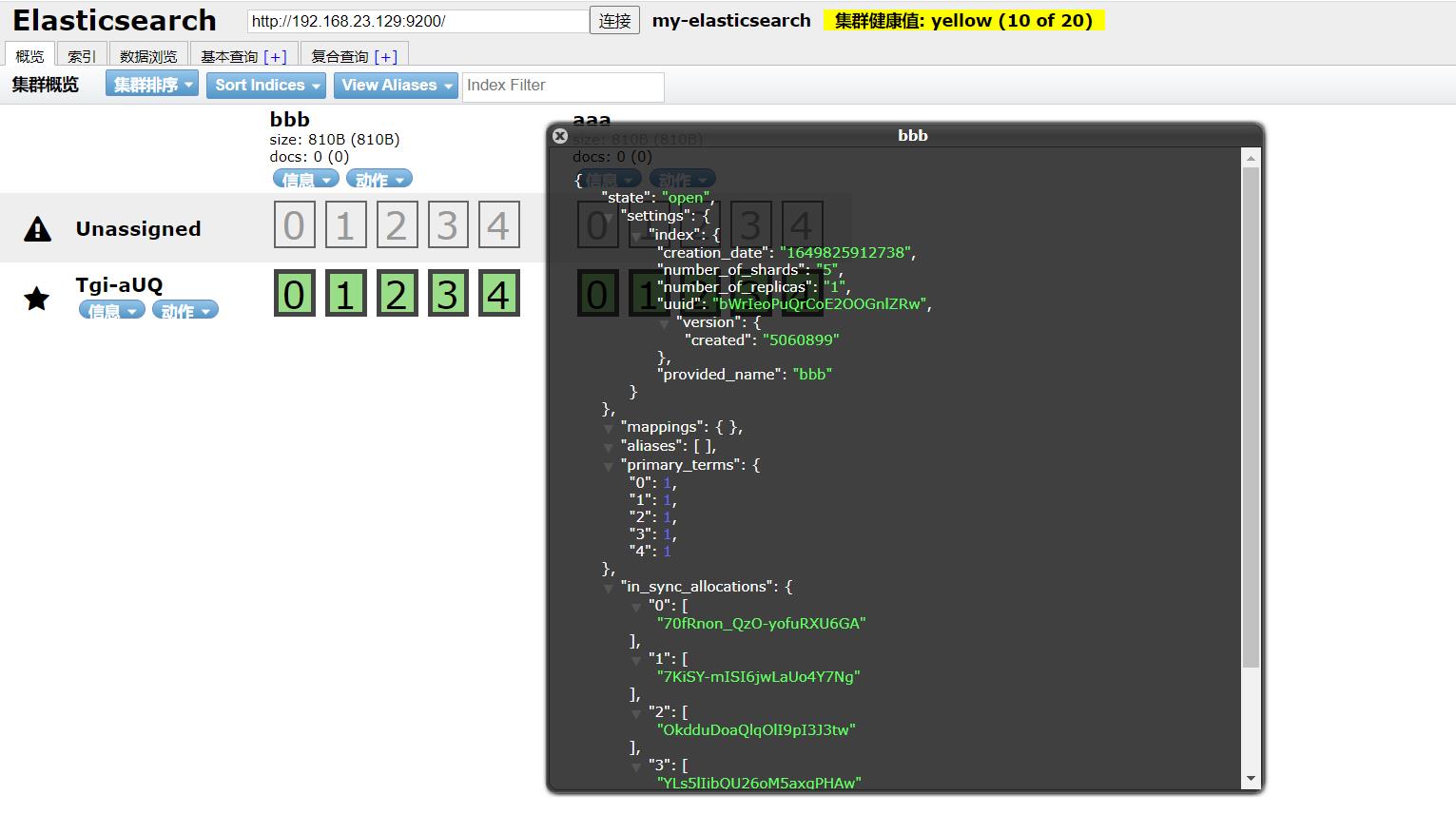
elasticsearch-head查看:
2.3设置映射mapping
- 设置Mapping
刚刚只是单纯的创建了bbb索引,并没有设置mapping信息,下面给bbb设置mapping信息。当然也可以创建索引的同时创建mapping信息(后面使用过)
#请求url:
POST http://192.168.23.129:9200/bbb/hello/_mappin
#请求体:
"hello":
"properties":
"id":
"type": "long",
"store": true
,
"title":
"type": "text",
"store": true,
"index":true,
"analyzer":"standard"
,
"content":
"type": "text",
"store": true,
"index":true,
"analyzer":"standard"
如图:
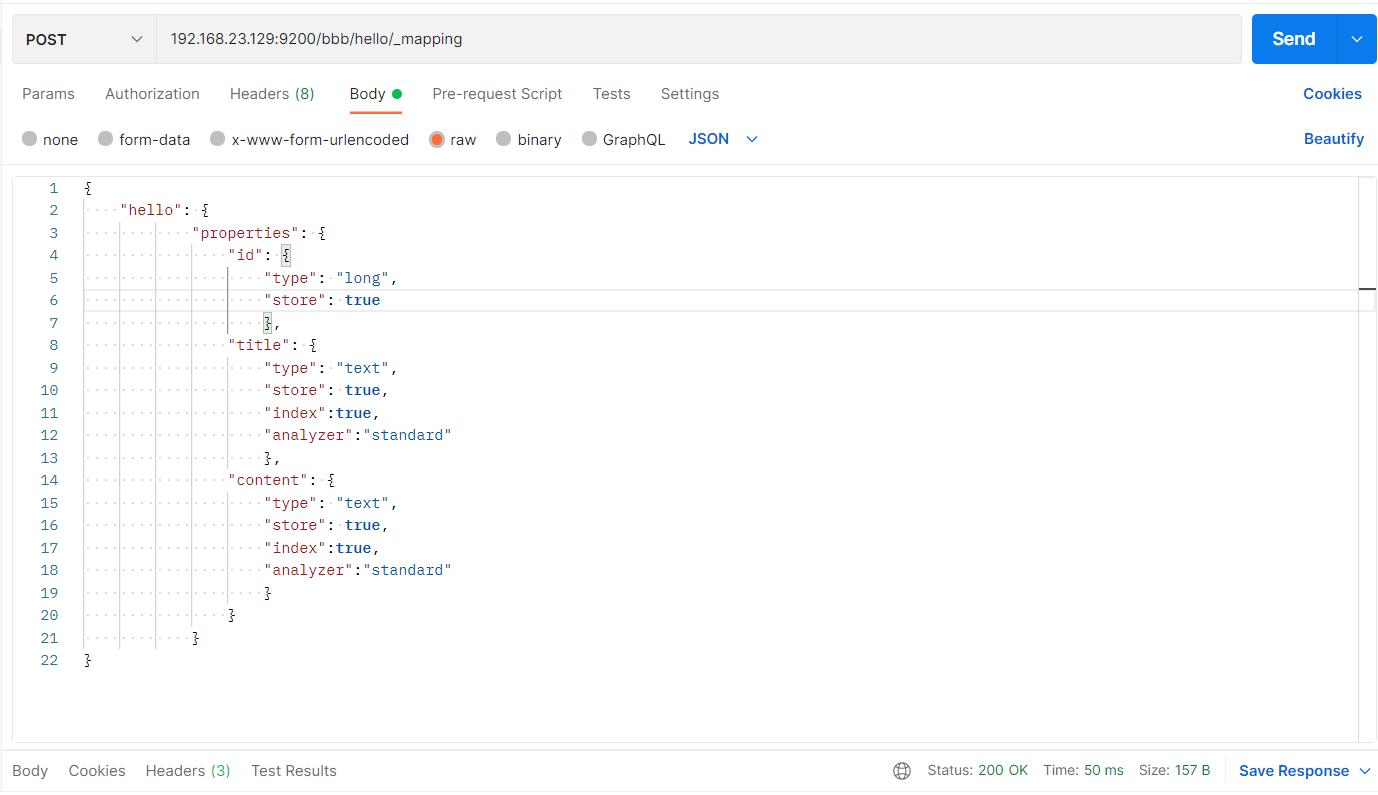
响应结果:

elasticsearch-head查看:
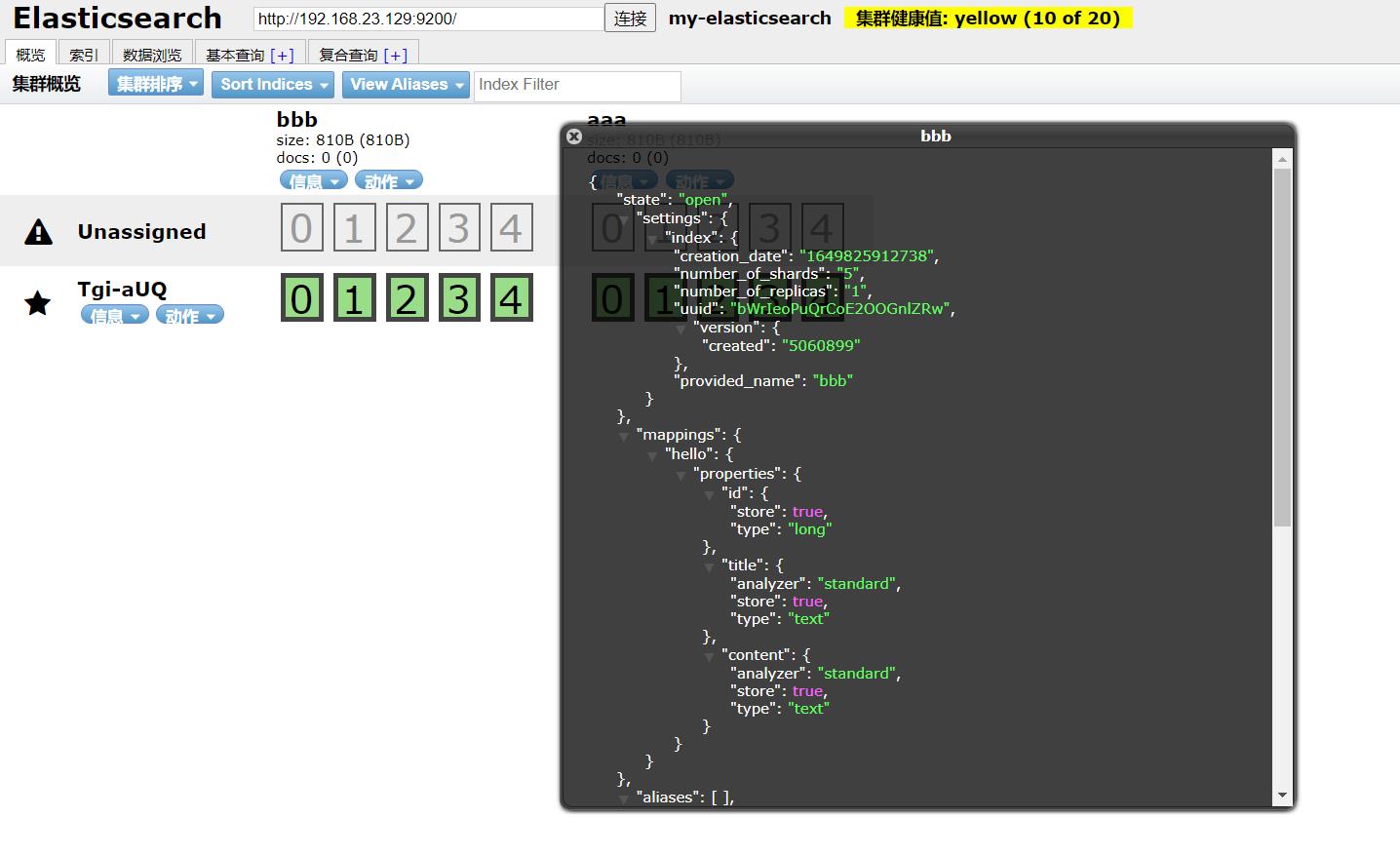
2.4删除索引index
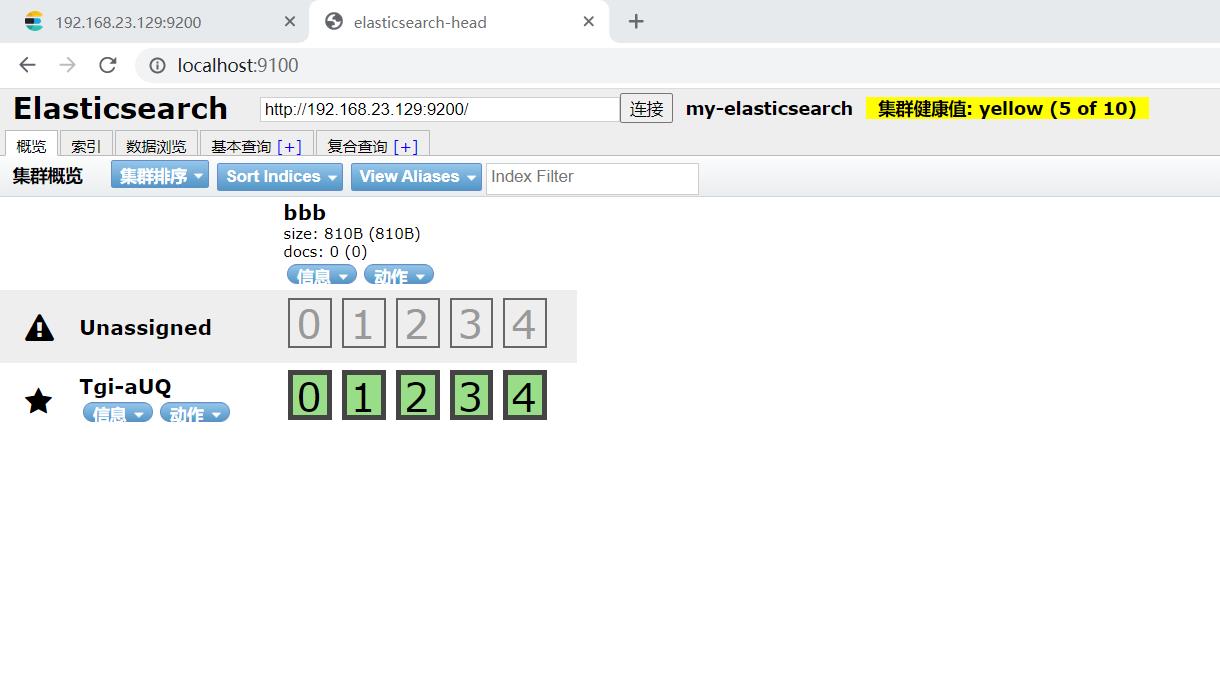
删除索引aaa
#请求url:
DELETE 192.168.23.129:9200/aaa
如图:

elasticsearch-head查看,aaa已被删除:
2.5创建文档document
#请求url:
POST 192.168.23.129:9200/bbb/hello/1
#请求体:
"id":1,
"title":"aaa",
"content":"bbb"
如图:
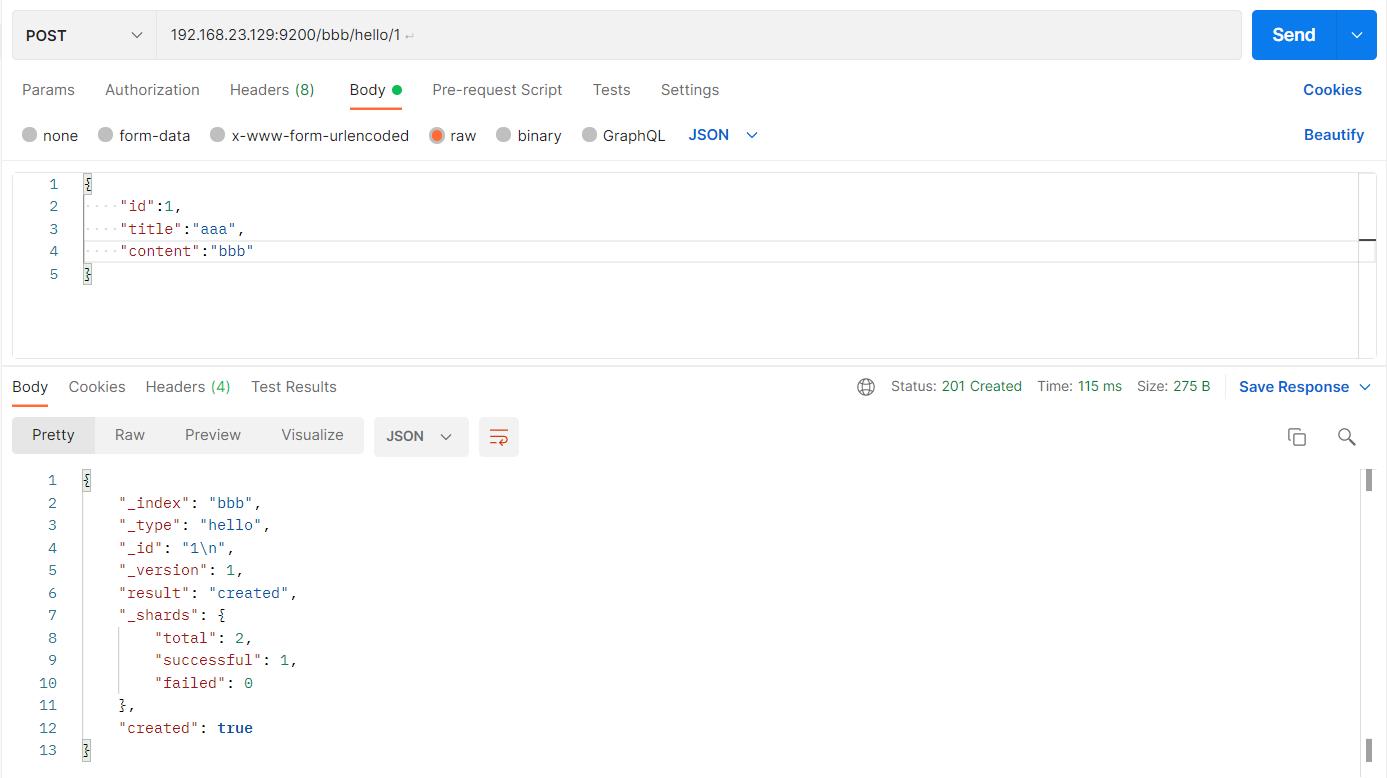
elasticsearch-head查看:
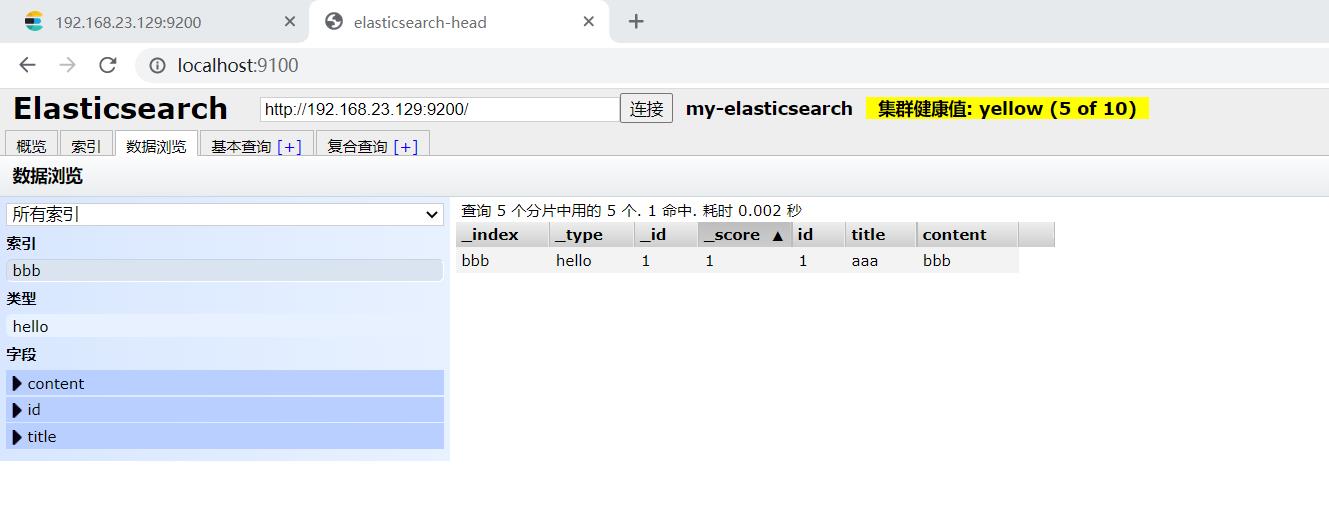
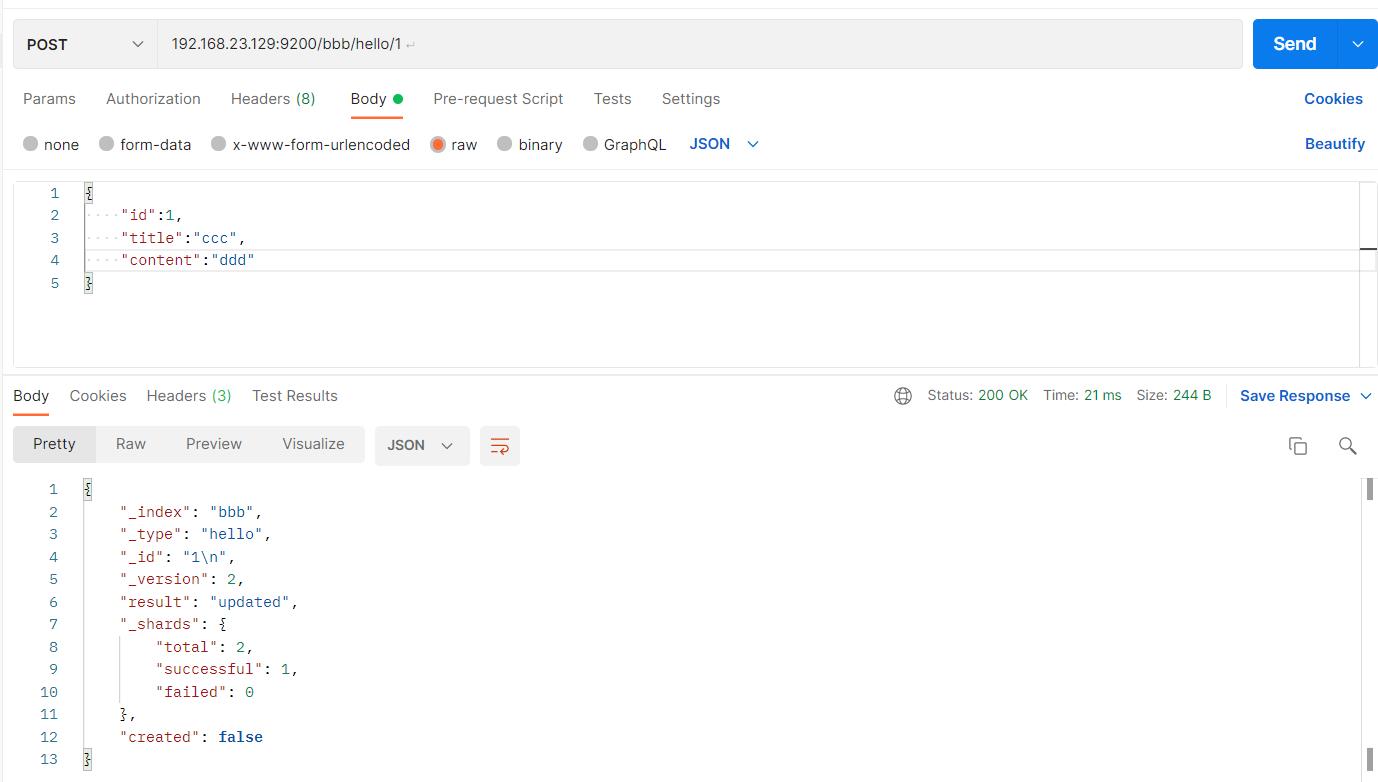
2.6修改文档document
#请求url:
POST 192.168.23.129:9200/bbb/hello/1
#请求体:
"id":1,
"title":"ccc",
"content":"ddd"
如图:
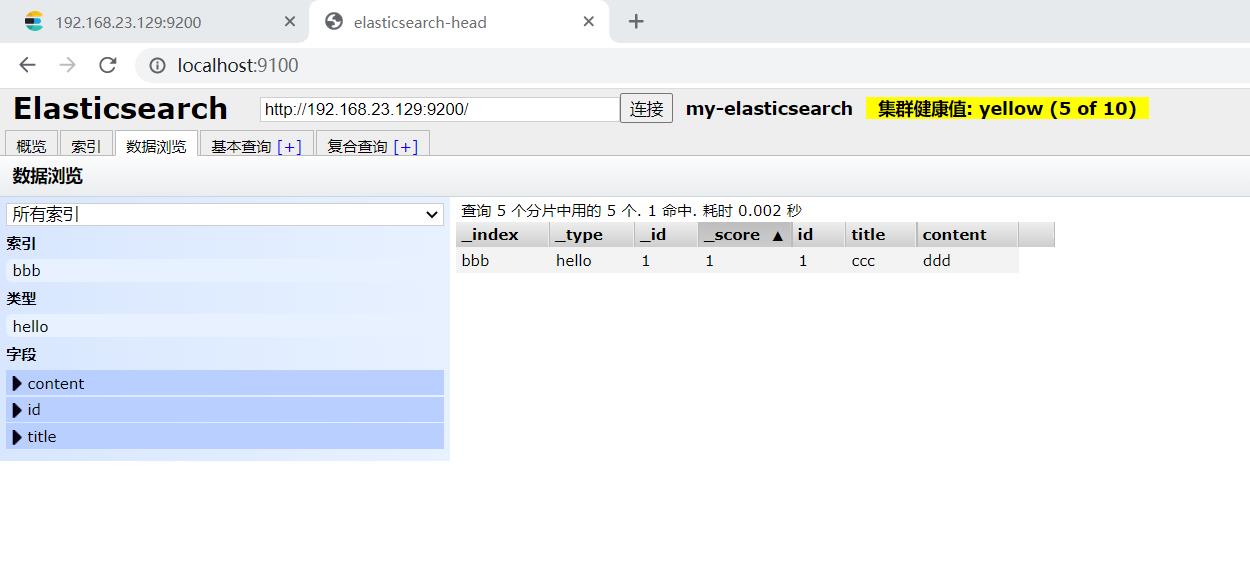
elasticsearch-head查看:
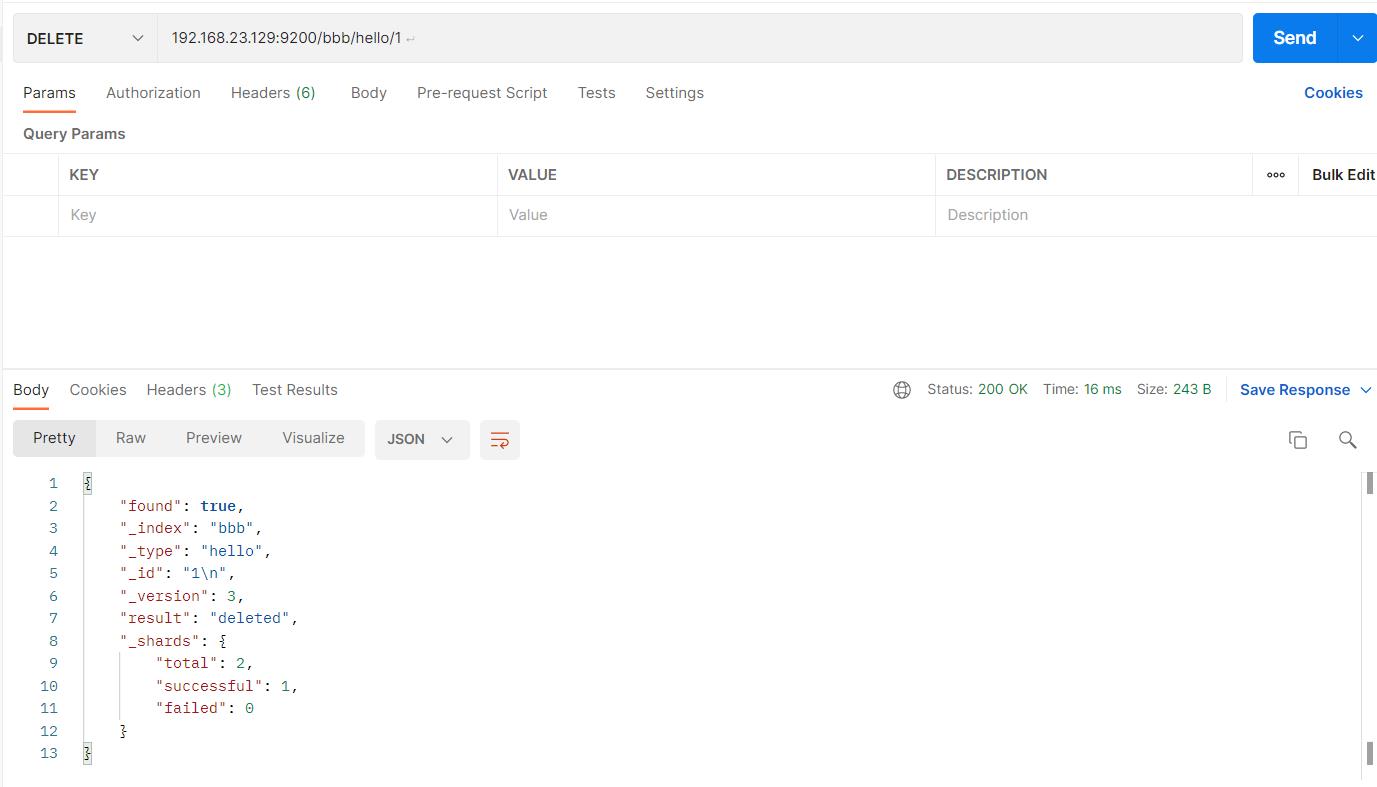
2.7删除文档document
#请求url:
DELETE 192.168.23.129:9200/bbb/hello/1
如图:
elasticsearch-head查看:
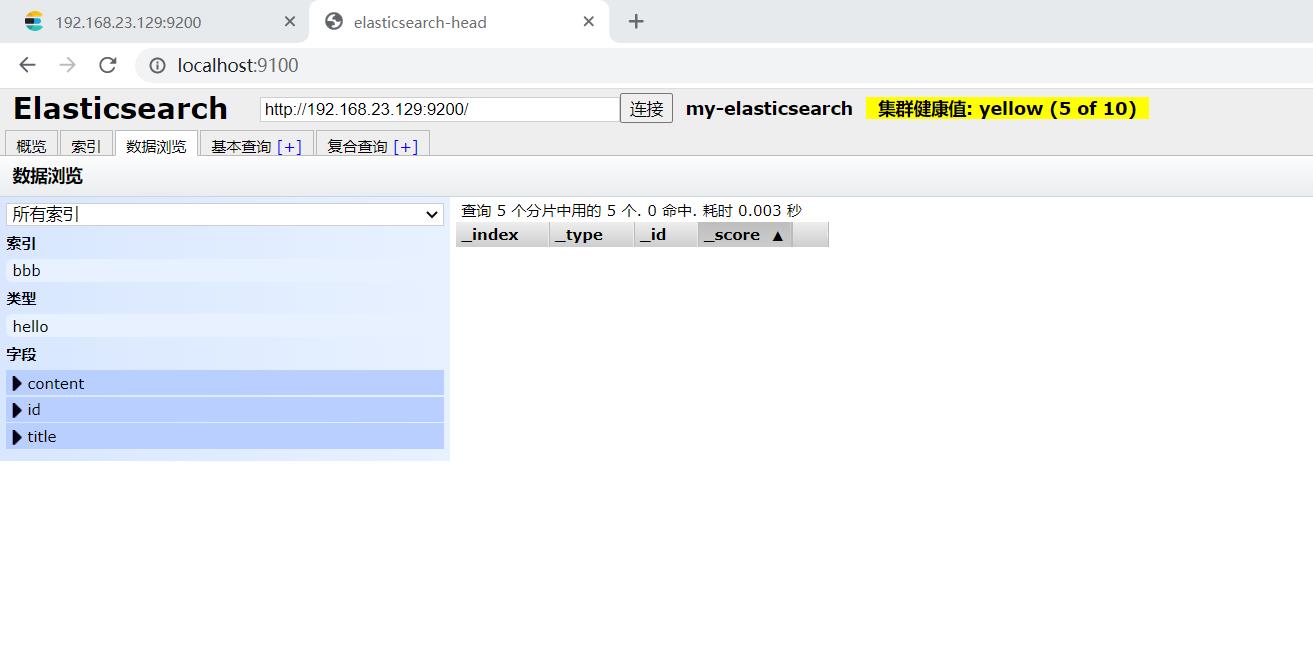
2.8查询文档-根据id查询
这里新建一个document用来查询
#新建一个document
POST 192.168.23.129:9200/bbb/hello/1
"id":1,
"title":"床前明月光aaa",
"content":"疑是地上霜bbb"
#查询文档-根据id查询
GET 192.168.23.129:9200/bbb/hello/1
如图:
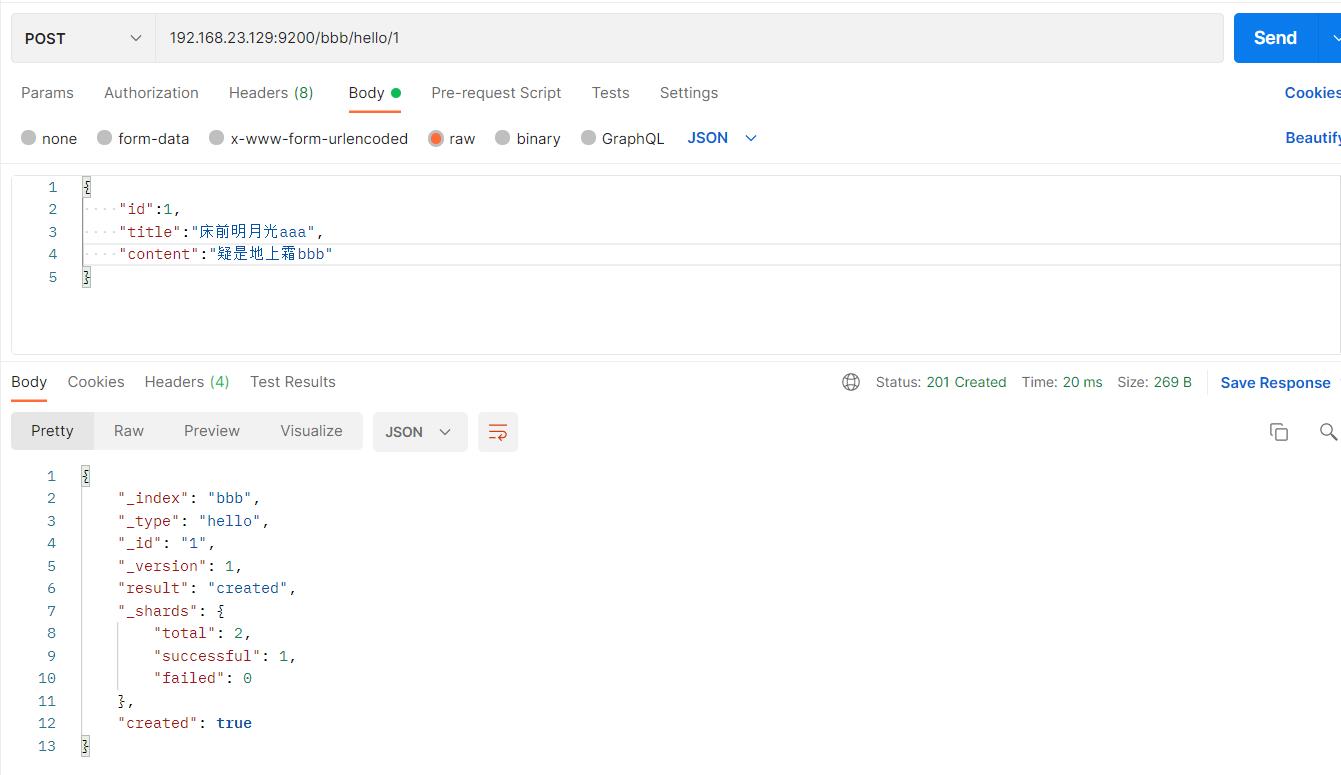
elasticsearch-head查看:
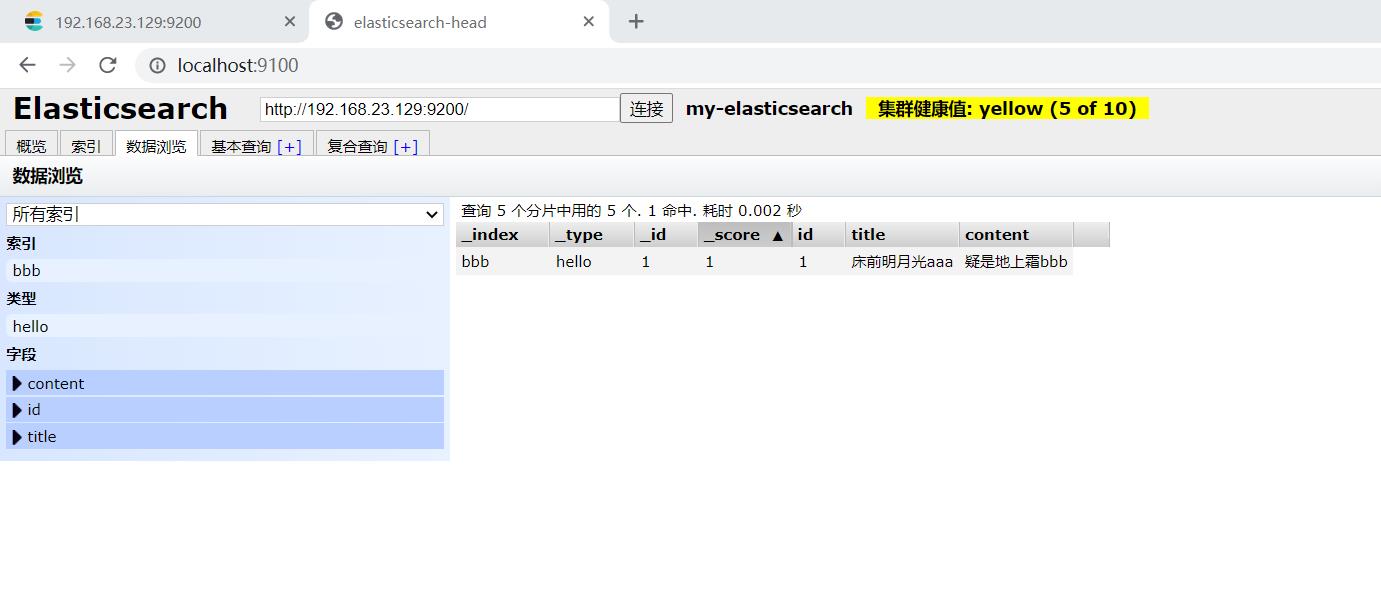
2.9查询文档-querystring查询
#请求url:
POST 192.168.23.129:9200/bbb/hello/_search
"query":
"query_string":
"default_field": "title",
"query": "床前明月光"
如图:

#请求url:
POST 192.168.23.129:9200/bbb/hello/_search
"query":
"query_string":
"default_field": "title",
"query": "夜光"
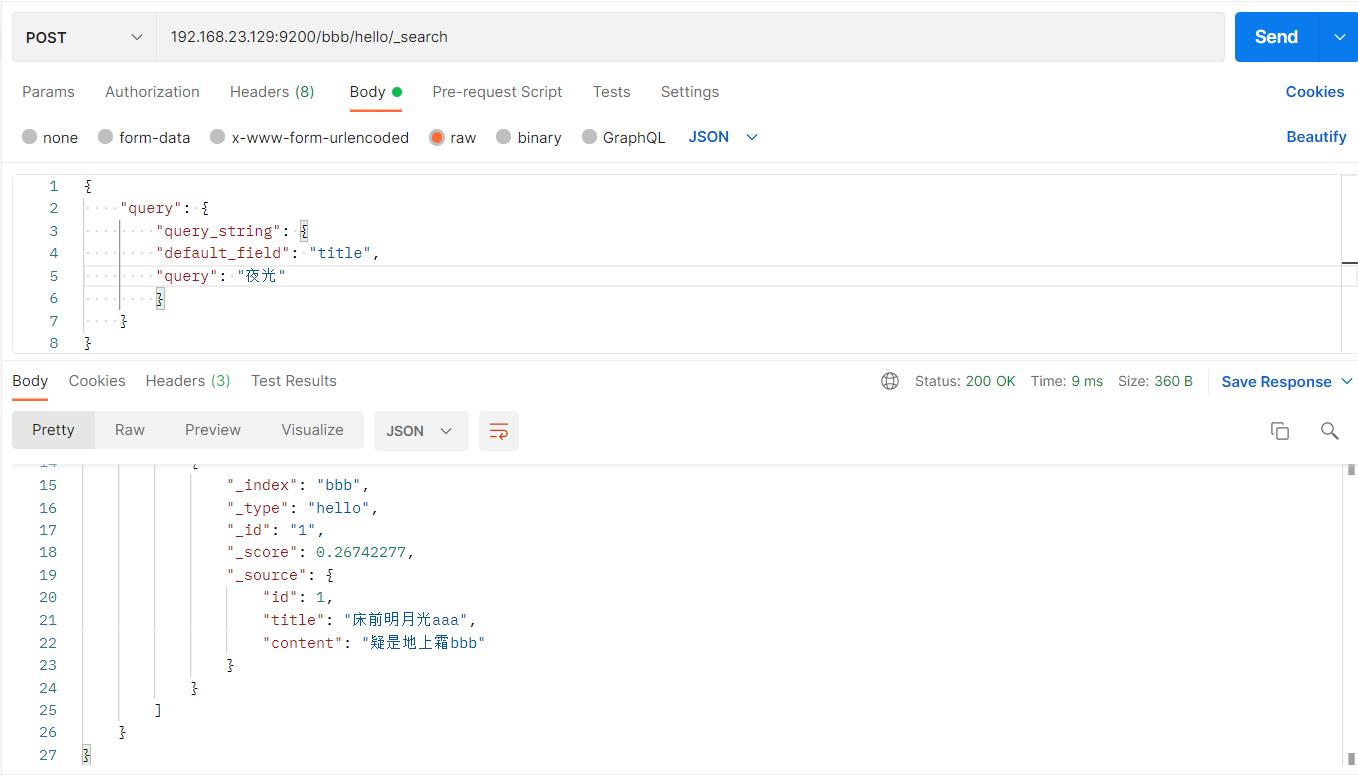
以上根据“床前明月光”和“夜光”都可以查到title,显然“夜光”查到的并不符合我们的需求,而且查到的也很不合理,这是因为分词器的原因,用querystring查询会进行分词,此时用的是Standard分词。
2.10查询文档-term查询
#请求url:
POST 192.168.23.129:9200/bbb/hello/_search
"query":
"term":
"title": "前"
如图:
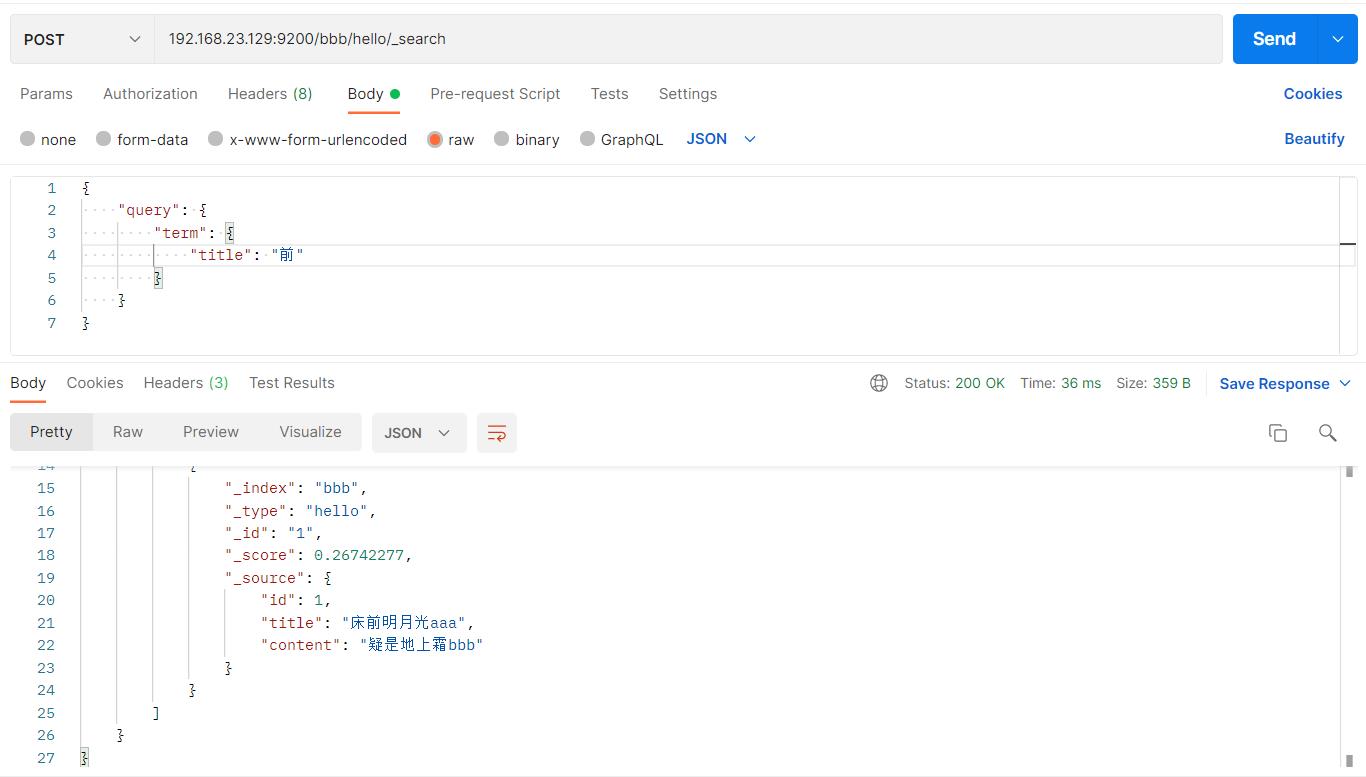
#请求url:
POST 192.168.23.129:9200/bbb/hello/_search
"query":
"term":
"title": "床前"
如图:
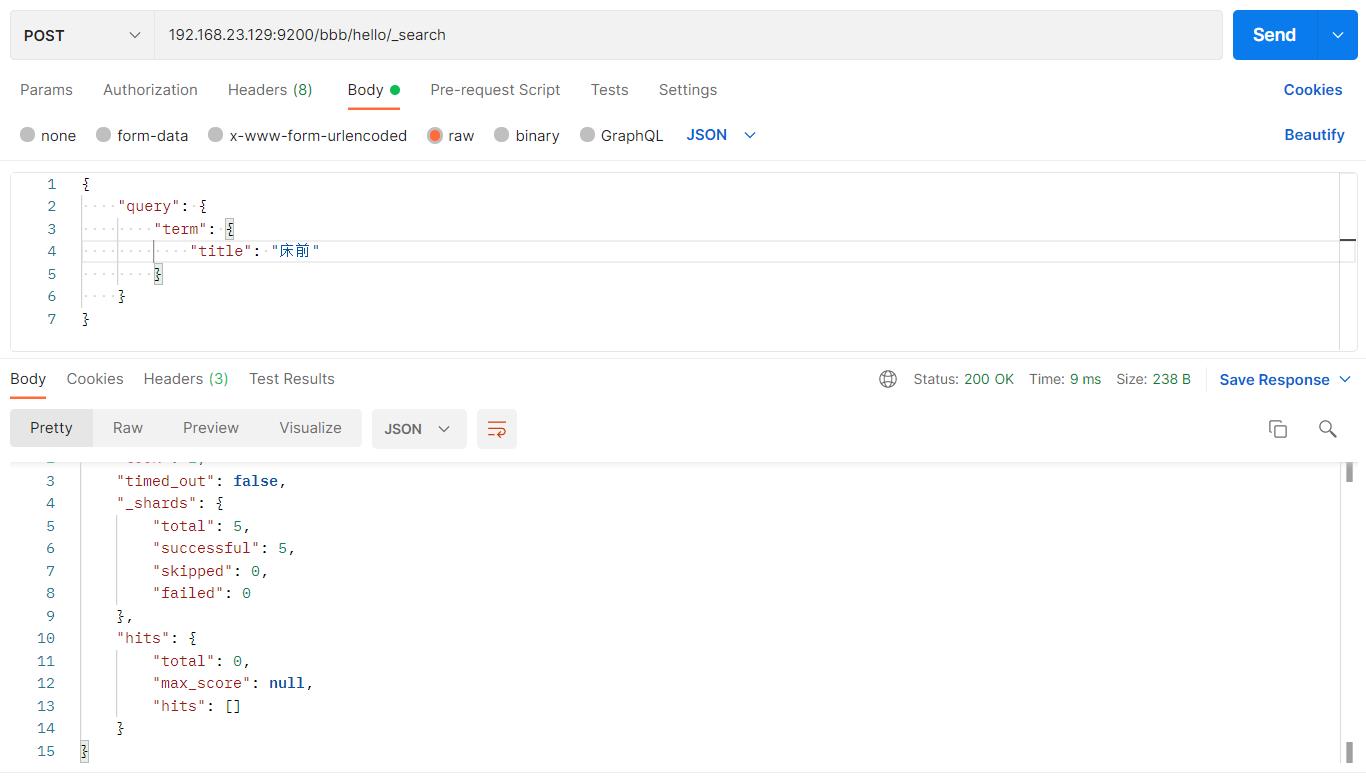
以上根据“前”可以查到title,而“床前”查不到title,这是因为用term查询不会进行分词。
五、IK分词器
-
简介:
IK Analyzer 是一个开源的,基于 java 语言开发的轻量级的中文分词工具包。从 2006年 12 月推出 1.0 版开始, IKAnalyzer 已经推出了 4 个大版本。最初,它是以开源项目Luence 为应用主体的,结合词典分词和文法分析算法的中文分词组件。从 3.0 版本开始,IK 发展为面向 Java 的公用分词组件,独立 Lucene 项目,同时提供了对 Lucene 的默认优化实现。在 2012 版本中,IK 实现了简单的分词歧义排除算法,标志着 IK 分词器从单纯的词典分词向模拟语义分词衍化。 -
分词:即把一段中文或者别的划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,会把数据库中或者索引库中的数据进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如前面的Standard分词会把“床前明月光”分成“床”,“前”,“明“,”月”,“光”这显然是不符合要求的,所以我们需要安装中文分词器ik来解决这个问题。
-
IK提供了两个分词算法:ik_smart和ik_max_word,其中ik_smart为最少切分,ik_max_word为最细粒度划分
1.安装ik分词器
- IK分词器下载地址
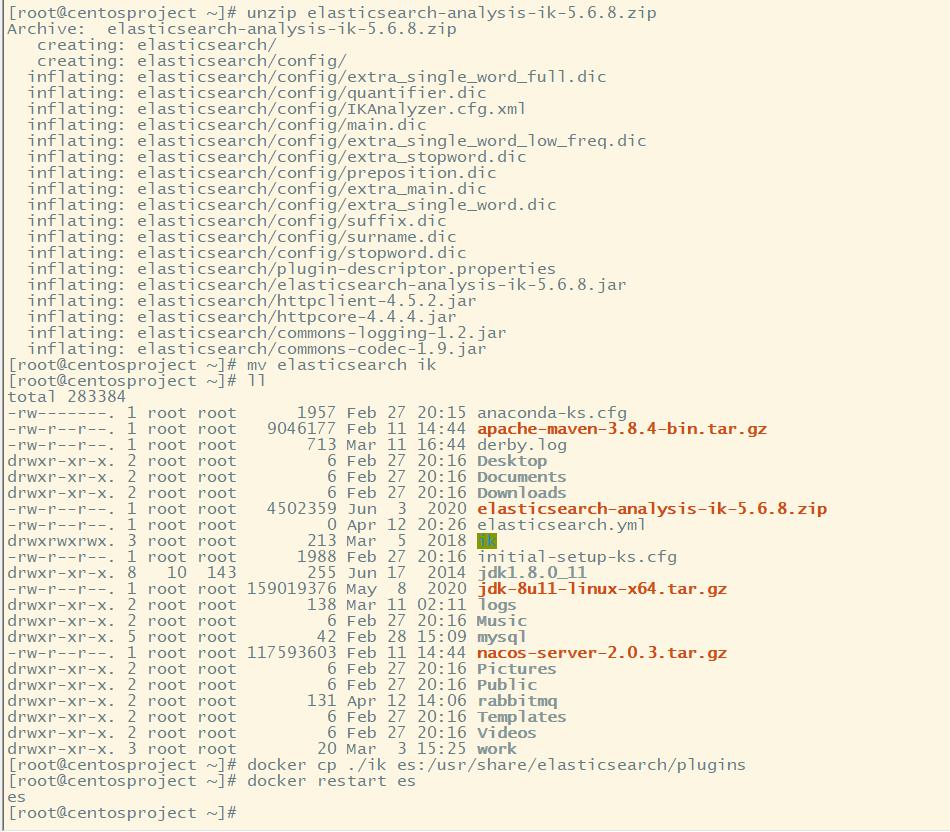
- 将ik分词器上传到服务器上,然后解压,指令如下:
#解压
unzip elasticsearch-analysis-ik-5.6.8.zip
#改名为ik
mv elasticsearch ik
#将ik目录拷贝到docker容器的plugins目录下
docker cp ./ik es:/usr/share/elasticsearch/plugins
如图:
- IK分词器测试
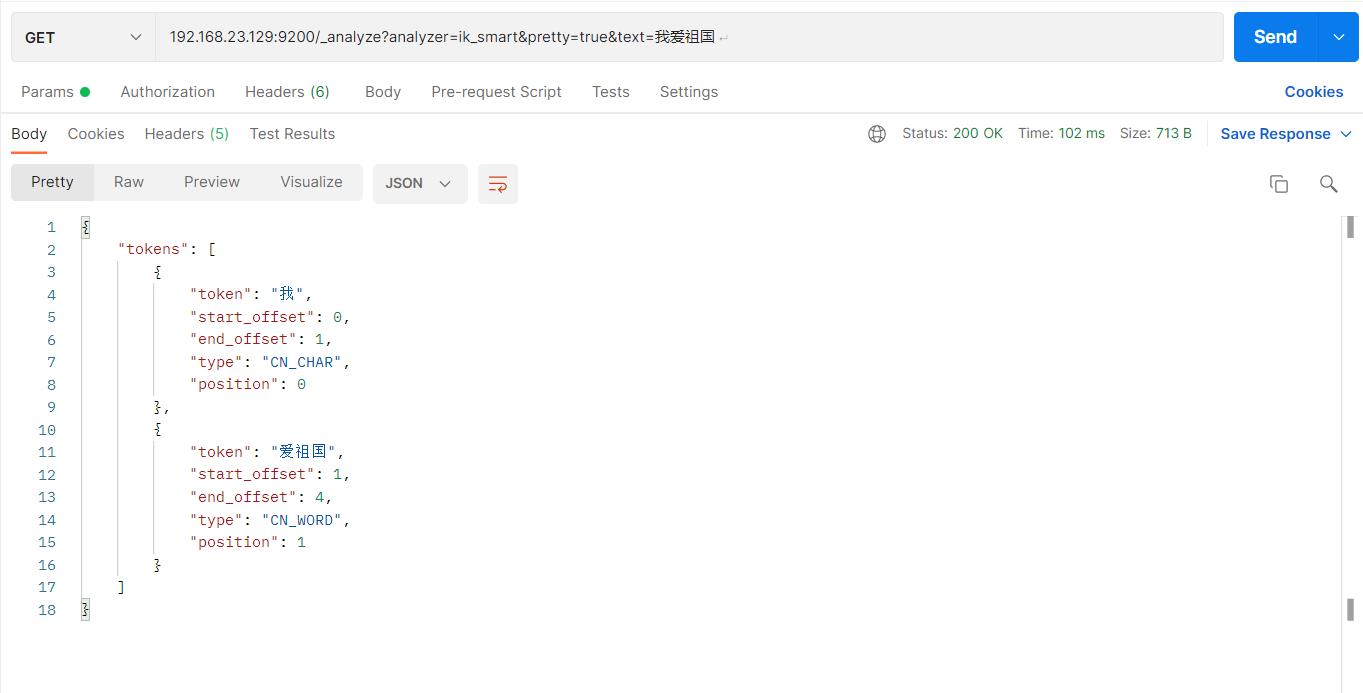
此时测试ik_smart
访问:http://192.168.23.129:9200/_analyze analyzer=ik_smart&pretty=true&text=我爱祖国
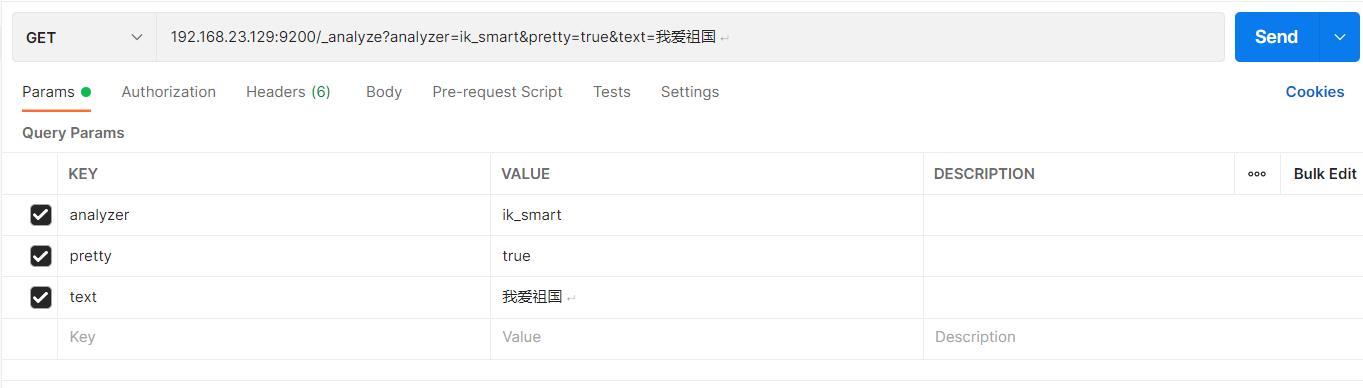
结果如下:
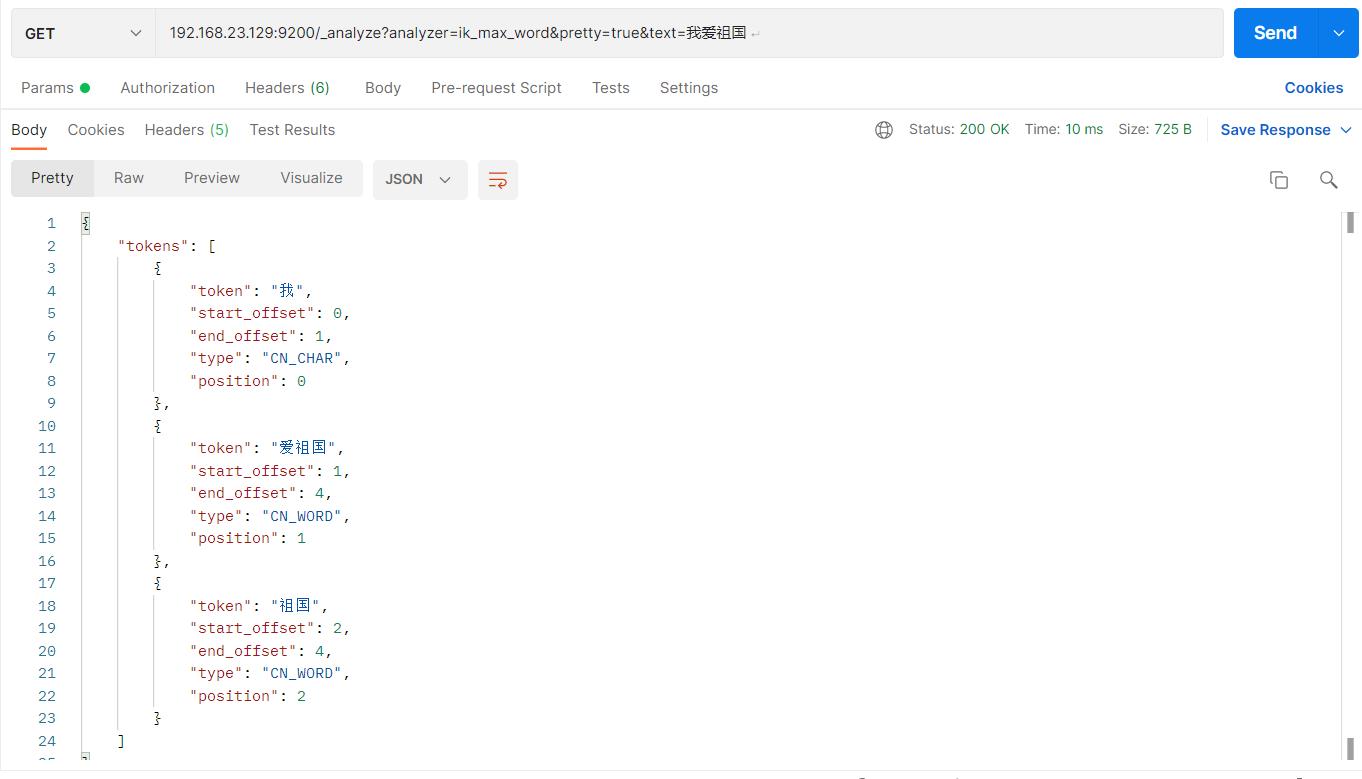
此时测试ik_max_word
访问:http://192.168.23.129:9200/_analyze analyzer=ik_max_word&pretty=true&text=我爱祖国
2.使用ik分词器
- 未使用ik分词器
#请求url:
POST 192.168.23.129:9200/bbb/hello/_search
"query":
"term":
"title": "月"
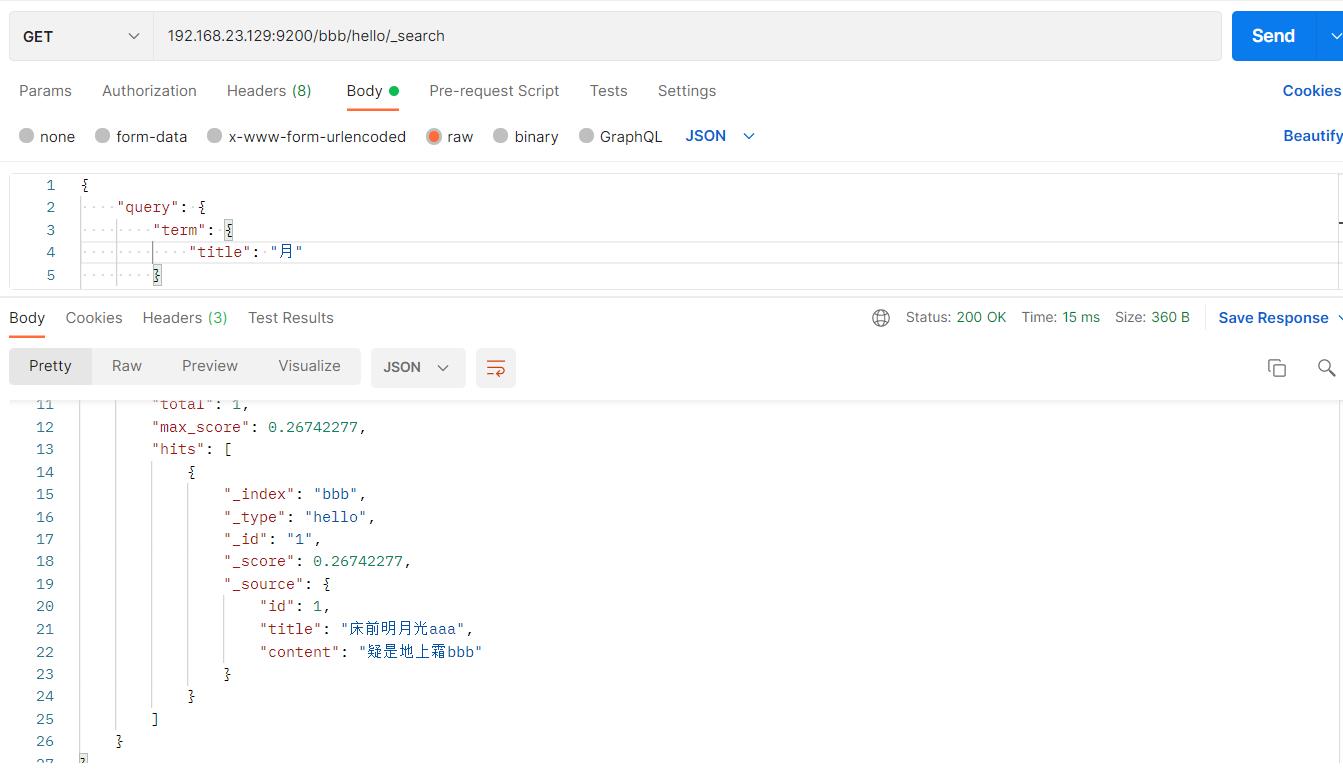
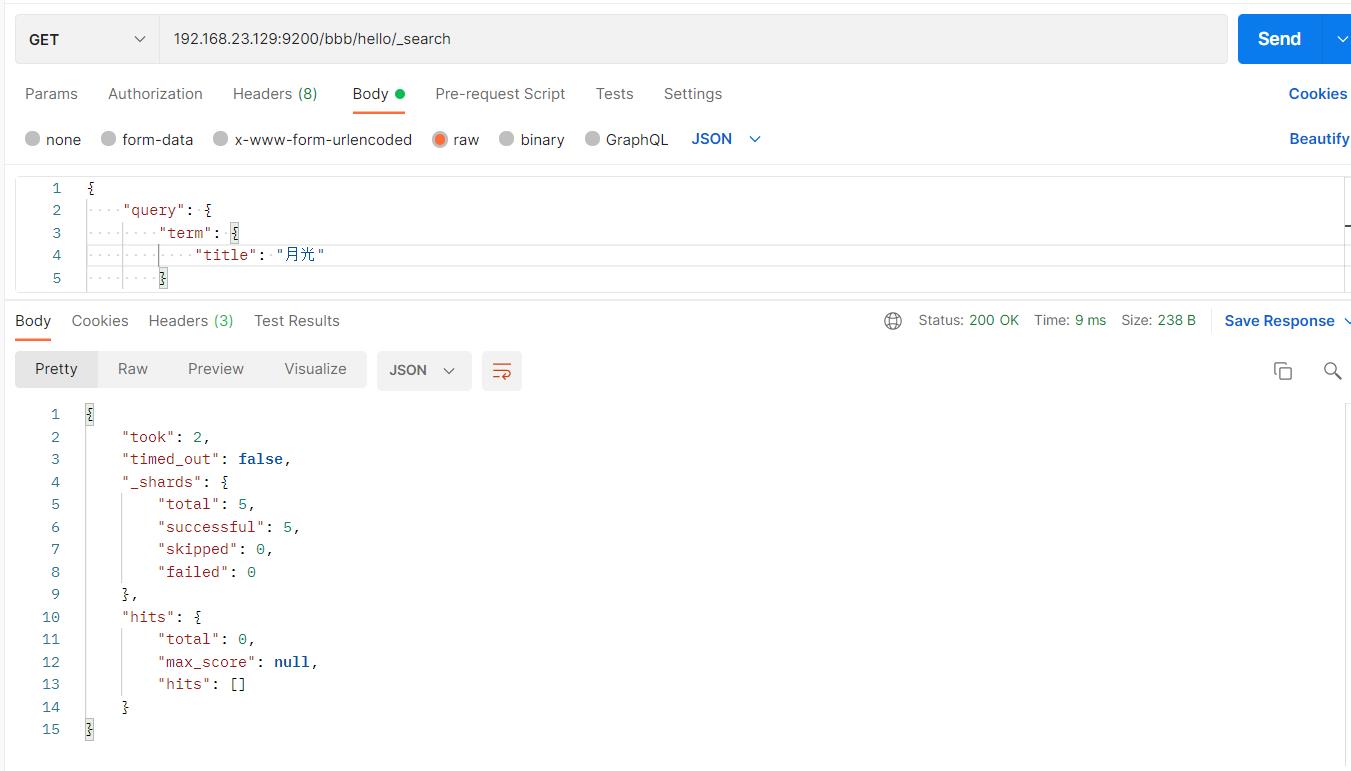
“床前明月光”分成“床”,“前”,“明“,”月”,“光”,所以“月”查得到,“月光”查不到
- 接下来咱们使用ik分词器
先创建一个使用ik分词器的新的索引ccc
PUT 192.168.23.129:9200/ccc
"mappings":
"article":
"properties":
"id":
"type": "long",
"store": true,
"index":"not_analyzed"
,
"title":
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"ik_max_word"
,
"content":
"type": "text",
"store": true,
"index":"analyzed",
"analyzer":"ik_max_word"
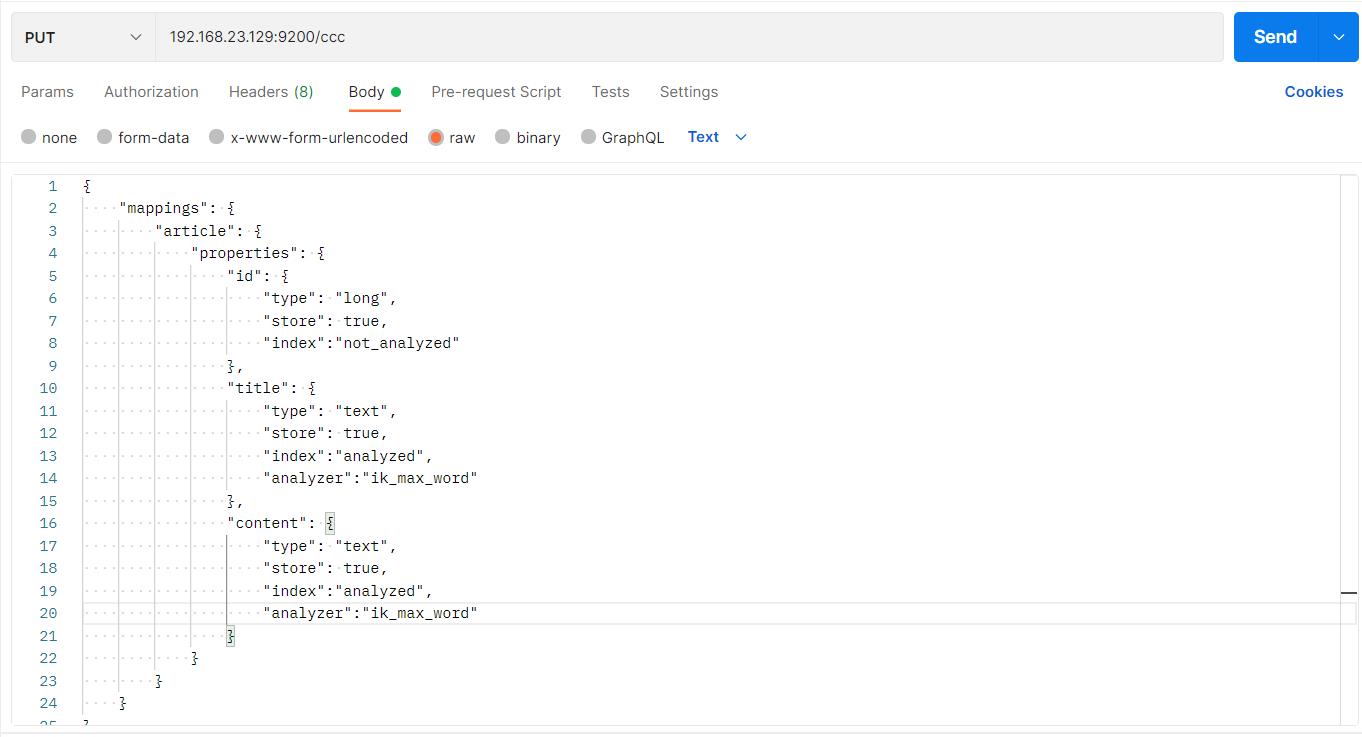
响应结果:

再创建document
#请求url:
POST 192.168.23.129:9200/ccc/article/1
#请求体:
"id":1,
"title":"床前明月光aaa",
"content":"疑是地上霜bbb"
如图:

- 此时再次使用ik分词器的term查询
#请求url:
POST 192.168.23.129:9200/ccc/article/_search
"query":
"term":
"title": "月光"
可以查到了
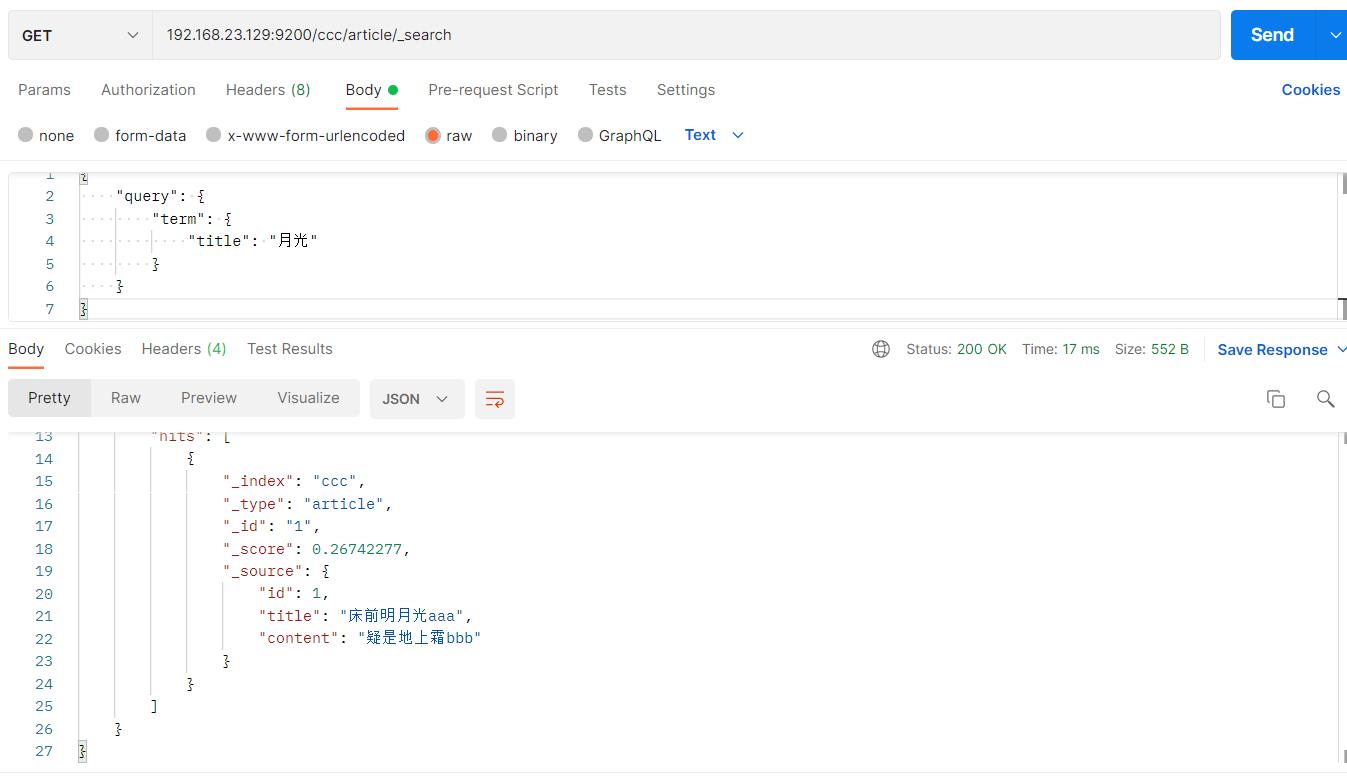
- 此时使用ik分词器querystring查询
#请求url:
POST 192.168.23.129:9200/ccc/article/_search
"query":
"query_string":
"default_field": "title",
"query": "夜光"
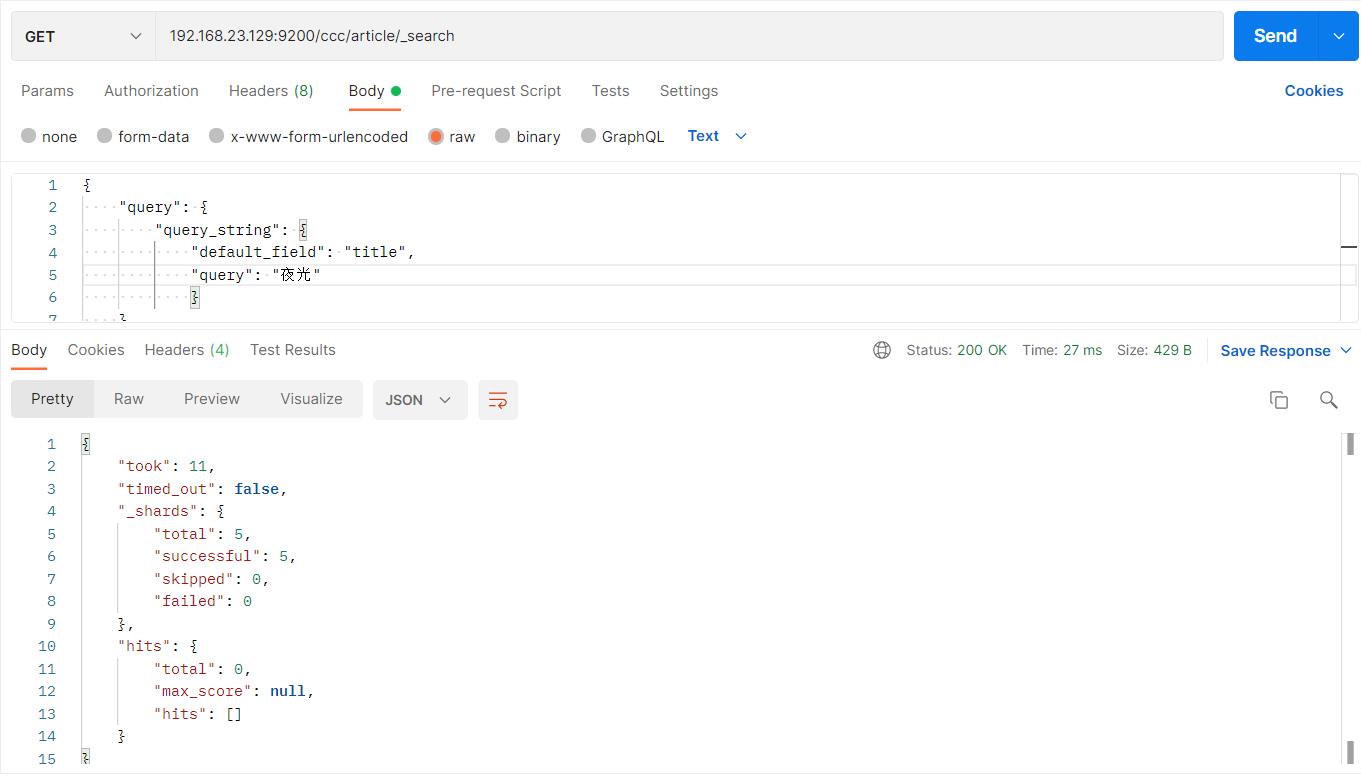
之前使用Standard分词器可以根据“夜光”查到,此时结果查不到了
六、Kibana使用
介绍
- Kibana 是一款开源的数据分析和可视化平台,它是 Elastic Stack 成员之一,设计用于和 Elasticsearch协作。您可以使用 Kibana 对 Elasticsearch 索引中的数据进行搜索、查看、交互操作。您可以很方便的利用图表、表格及地图对数据进行多元化的分析和呈现。
- Kibana 可以使大数据通俗易懂。它很简单,基于浏览器的界面便于您快速创建和分享动态数据仪表板来追踪 Elasticsearch 的实时数据变化。
- 搭建 Kibana 非常简单。您可以分分钟完成 Kibana 的安装并开始探索 Elasticsearch 的索引数据 — 没有代码、不需要额外的基础设施。
1.Kibana下载安装
这里使用虚拟机的docker镜像下载
指令如下:
#镜像下载
docker pull docker.io/kibana:5.6.8
#安装kibana容器
docker run -it -d -e ELASTICSEARCH_URL=http://192.168.23.129:9200 --name kibana
-p 5601:5601 kibana:5.6.8
安装后访问:http://192.168.23.129:5601 如下:
如图所示安装成功:

如图便是我们之前的数据了:

2.DSL语句使用
#查看所有索引
GET /_cat/indices?v
#删除某个索引
DELETE /skuinfo
#新增索引
PUT /user
#创建映射
PUT /user/userinfo/_mapping
"properties":
"name":
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart",
"store": false
,
"city":
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart",
"store": false
,
"age":
"type": "long",
"store": false
,
"description":
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart",
"store": false
#新增文档数据 id=1
PUT /user/userinfo/1
"name":"a",
"age":22,
"city":"beijing",
"description":"i love you"
#更新数据,id=1
PUT /user/userinfo/4
"name":"b",
"description":"you love me"
#根据ID查询
GET /user/userinfo/1
#恢复文档数据 id=1
PUT /user/userinfo/1
"name":"a",
"age":22,
"city":"beijing",
"description":"i love you"
#使用POST更新某个域的数据
POST /user/userinfo/1/_update
"doc":
"name":"b",
"description":"you love me"
#根据ID查询
GET /user/userinfo/1
#删除数据
DELETE user/userinfo/1
#查询所有
GET /user/_search
#根据ID查询
GET /user/userinfo/1
#搜索排序
GET /user/_search
"query":
"match_all":
,
"sort":
"age":
"order":"desc"
#分页实现
GET /user/_search
"query":
"match_all":
,
"sort":
"age":
"order":"desc"
,
"from": 0,
"size": 2
#查询-term
GET _search
"query":
"term":
"city":"武汉"
#查询-terms 允许多个Term
GET _search
"query":
"terms":
"city":
[
"武汉",
"广州"
]
#match查询
GET _search
"query":
"match":
"description": "武汉"
#过滤-range 范围过滤
#gt表示> gte表示=>
#lt表示< lte表示<=
GET _search
"query":
"range":
"age":
"gte": 30,
"lte": 57
#过滤搜索 exists:是指包含某个域的数据检索
GET _search
"query":
"exists":
"field":"address"
#过滤搜索 bool
#must : 多个查询条件的完全匹配,相当于 and。
#must_not : 多个查询条件的相反匹配,相当于 not。
#should : 至少有一个查询条件匹配, 相当于 or。
GET _search
"query":
"bool":
"must": [
"term":
"city":
"value": "深圳"
,
"range":
"age":
"gte":20,
"lte":99
]
#查询所有 match_all
GET _search
"query":
"match_all":
#字符串匹配
GET _search
"query":
"match":
"description": "武汉"
#前缀匹配 prefix
GET _search
"query":
"prefix":
"name":
"value": "赵"
#多个域匹配搜索
GET _search
"query":
"multi_match":
"query": "深圳",
"fields": [
"city",
"description"
]
#过滤-range 范围过滤
#gt表示> gte表示=>
#lt表示< lte表示<=
GET _search
"query":
"bool":
"must": [
"match":
"city": "深圳武汉"
],
"filter":
"range":
"age":
"gte": 20,
"lte": 60
七、使用Java编程操作ElasticSearch
- pox.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.lxs</groupId>
<artifactId>es-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.6.8</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.24</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.12</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.8.1</version>
</dependency>
</dependencies>
</project>
1.创建索引index
//创建索引
public void test1() throws Exception
// 创建Client连接对象
TransportClient client;
//创建一个client对象
Settings settings = Settings.builder().put("cluster.name", "my-elasticsearch").build();
//2:客户端
client = new PreBuiltTransportClient(settings);
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("192.168.23.129"), 9300));
//创建名称为ddd的索引
client.admin().indices().prepareCreate("ddd").get();
//释放资源
client.close();
2.创建映射mapping
public void test2() throws Exception
// 创建Client连接对象
TransportClient client;
//创建一个client对象
Settings settings = Settings.builder().put("cluster.name", "my-elasticsearch").build();
//2:客户端
client = new PreBuiltTransportClient(settings);
client.addTransportAddress(new InetSocketTransportAddress(InetAddress.getByName("192.168.23.129"), 9300));
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.startObject("article")
.startObject("properties")
.startObject("id")
.field("type", "integer").field("store", "yes")
.endObject()
.startObject("title")
.field(Elasticsearch 学习之子聚集过滤