K8S实战系列2:Pod工作负载与服务
Posted 琦彦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了K8S实战系列2:Pod工作负载与服务相关的知识,希望对你有一定的参考价值。
文章系列
回顾
容器,其实是一种特殊的进程而已。
现在,你应该可以理解,对 Docker 项目来说,它最核心的原理实际上就是为待创建的用户进程:
- 启用 Linux Namespace 配置;
- 设置指定的 Cgroups 参数;
- 切换进程的根目录(Change Root)
Kubernetes 是云原生时代的操作系统
Kubernetes 项目所做的,其实就是将“进程组”的概念映射到了容器技术中,并使其成为了这个云计算“操作系统”里的“一等公民”。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VvcAdTEl-1650714444487)(https://cdn.jsdelivr.net/gh/Fly0905/note-picture@main/img/202204230918650.png)]
Pod 就是 Kubernetes 世界里的“应用”;而一个应用,可以由多个容器组成。
按照这幅图的线索,我们从容器这个最基础的概念出发,首先遇到了容器间“紧密协作”关系的难题,于是就扩展到了 Pod;
Pod 这个看似复杂的 API 对象,实际上就是对容器的进一步抽象和封装而已。
所以,Pod 对象,其实就是容器的升级版。它对容器进行了组合,添加了更多的属性和字段。这就好比给集装箱四面安装了吊环,使得 Kubernetes 这架“吊车”,可以更轻松地操作它。
在具体实现中,实际状态往往来自于 Kubernetes 集群本身。
比如,kubelet 通过心跳汇报的容器状态和节点状态,或者监控系统中保存的应用监控数据,或者控制器主动收集的它自己感兴趣的信息,这些都是常见的实际状态的来源。
而期望状态,一般来自于用户提交的 YAML 文件。
Kubernetes Pod详解
Kubernets概览
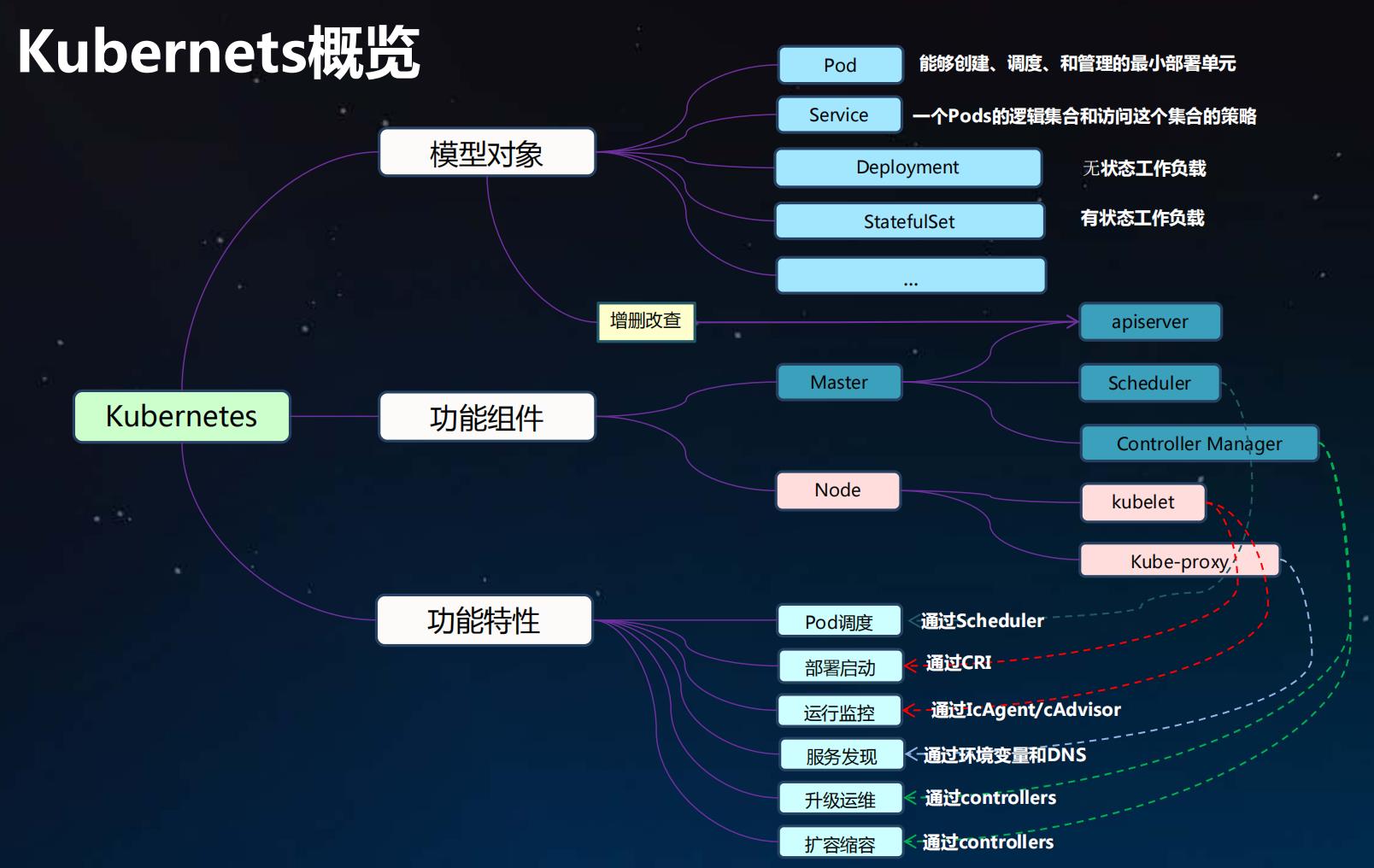
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W9556ihZ-1650714444489)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]
Kubernetes关键概念-Pod
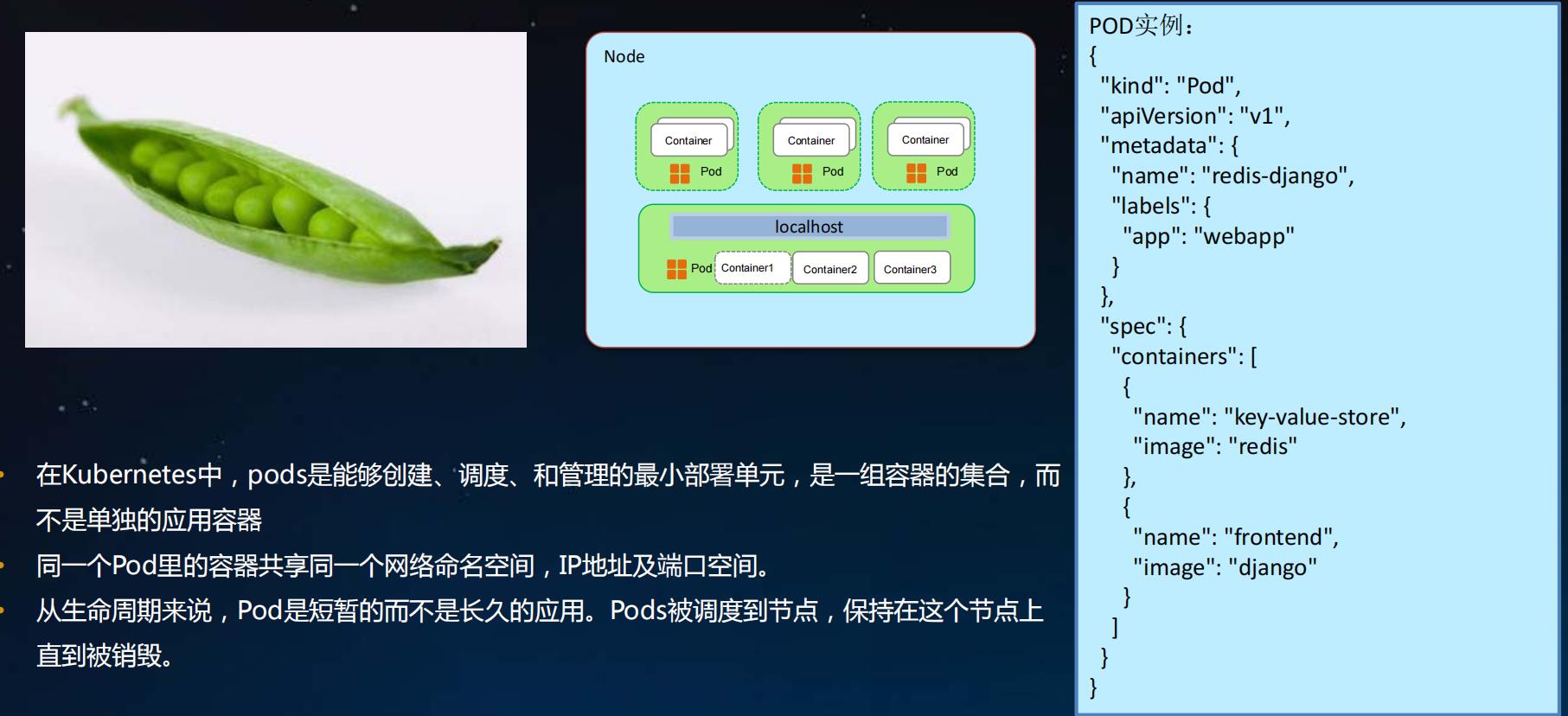
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-otGzBBdt-1650714444490)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]
- 在Kubernetes中, pods是能够创建、调度、和管理的最小部署单元,是一组容器的集合,而不是单独的应用容器
- 同一个Pod里的容器共享同一个网络命名空间, IP地址及端口空间。
- 从生命周期来说, Pod是短暂的而不是长久的应用。 Pods被调度到节点,保持在这个节点上直到被销毁。
1. Pod详解-容器
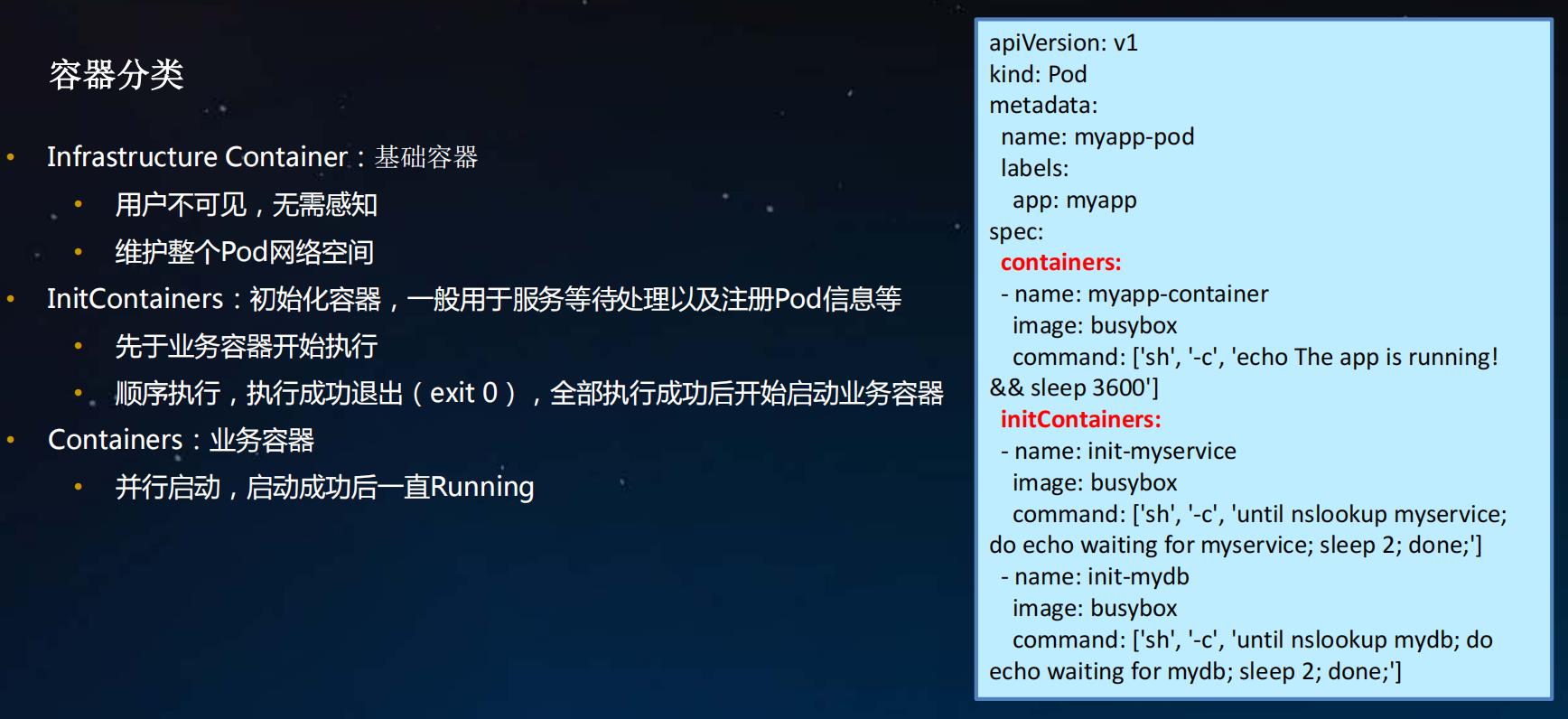
Infrastructure Container: 基础容器
- 用户不可见,无需感知
- 维护整个Pod网络空间
InitContainers:初始化容器,一般用于服务等待处理以及注册Pod信息等
- 先于业务容器开始执行
- 顺序执行,执行成功退出( exit 0),全部执行成功后开始启动业务容器
Containers:业务容器
- 并行启动,启动成功后一直Running
使用 Init 容器
因为 Init 容器具有与应用容器分离的单独镜像,其启动相关代码具有如下优势:
- Init 容器可以包含一些安装过程中应用容器中不存在的实用工具或个性化代码。 例如,没有必要仅为了在安装过程中使用类似
sed、awk、python或dig这样的工具而去FROM一个镜像来生成一个新的镜像。 - Init 容器可以安全地运行这些工具,避免这些工具导致应用镜像的安全性降低。
- 应用镜像的创建者和部署者可以各自独立工作,而没有必要联合构建一个单独的应用镜像。
- Init 容器能以不同于 Pod 内应用容器的文件系统视图运行。因此,Init 容器可以访问 应用容器不能访问的 Secret 的权限。
- 由于 Init 容器必须在应用容器启动之前运行完成,因此 Init 容器 提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件。 一旦前置条件满足,Pod 内的所有的应用容器会并行启动。
参考: https://kubernetes.io/zh/docs/concepts/workloads/pods/init-containers/
Init 容器示例
下面是一些如何使用 Init 容器的想法:
-
等待一个 Service 完成创建,通过类似如下 shell 命令:
for i in 1..100; do sleep 1; if dig myservice; then exit 0; fi; done; exit 1 -
注册这个 Pod 到远程服务器,通过在命令中调用 API,类似如下:
curl -X POST http://$MANAGEMENT_SERVICE_HOST:$MANAGEMENT_SERVICE_PORT/register \\ -d 'instance=$(<POD_NAME>)&ip=$(<POD_IP>)' -
在启动应用容器之前等一段时间,使用类似命令:
sleep 60 -
克隆 Git 仓库到卷中。
-
将配置值放到配置文件中,运行模板工具为主应用容器动态地生成配置文件。 例如,在配置文件中存放
POD_IP值,并使用 Jinja 生成主应用配置文件。
容器基本组成

2. Pod详解-资源需求和QoS
资源请求和限制的原理
- spec.containers[].resources.requests.cpu 作用在CpuShares,表示分配cpu 的权重,争抢时的分配比例
- spec.containers[].resources.requests.memory 主要用于kube-scheduler调度器,对容器没有设置意义
- spec.containers[].resources.limits.cpu 作用CpuQuota和CpuPeriod,单位为微秒,计算方法为:CpuQuota/CpuPeriod,表示最大cpu最大可使用的百分比,如500m表示允许使用1个cpu中的50%资源
- spec.containers[].resources.limits.memory 作用在Memory,表示容器最大可用内存大小,超过则会OOM
以下面定义的cpu-mem-request-limit.yaml为例,研究下pod中定义的requests和limits应用在docker生效的参数:
apiVersion: v1
kind: Pod
metadata:
name: cpu-mem-request-limit
namespace: fly-test
labels:
name: cpu-mem-request-limit
spec:
containers:
- name: cpu-mem-request-limit
image: nginx:1.7.9
imagePullPolicy: IfNotPresent
ports:
- name: nginx-port-80
protocol: TCP
containerPort: 80
resources:
requests:
cpu: 0.25
memory: 128Mi
limits:
cpu: 500m
memory: 256Mi
1、获取容器的id号,可以通过kubectl describe pods cpu-mem-request-limit的containerID获取到容器的id,或者登陆到node-3节点通过名称过滤获取到容器的id号,默认会有两个pod:一个通过pause镜像创建,另外一个通过应用镜像创建
[root@gv41New95 2-pod-resource]# docker container list | grep cpu-mem-request-limit
d9b2a8b67fea 84581e99d807 "nginx -g 'daemon of…" About a minute ago Up 59 seconds k8s_cpu-mem-request-limit_cpu-mem-request-limit_fly-test_3cd9ea76-259b-4b64-98f2-ff61c8965cb5_0
ec09131f6e05 registry.aliyuncs.com/google_containers/pause:3.2 "/pause" About a minute ago Up 59 seconds k8s_POD_cpu-mem-request-limit_fly-test_3cd9ea76-259b-4b64-98f2-ff61c8965cb5_0
2、查看docker容器详情信息
[root@node-3 ~]# docker container inspect d9b2a8b67fea
[
"Image": "sha256:84581e99d807a703c9c03bd1a31cd9621815155ac72a7365fd02311264512656",
"ResolvConfPath": "/var/lib/docker/containers/2fe0498ea9b5dfe1eb63eba09b1598a8dfd60ef046562525da4dcf7903a25250/resolv.conf",
"HostConfig":
"Binds": [
"/var/lib/kubelet/pods/66958ef7-507a-41cd-a688-7a4976c6a71e/volumes/kubernetes.io~secret/default-token-5qwmc:/var/run/secrets/kubernetes.io/serviceaccount:ro",
"/var/lib/kubelet/pods/66958ef7-507a-41cd-a688-7a4976c6a71e/etc-hosts:/etc/hosts",
"/var/lib/kubelet/pods/66958ef7-507a-41cd-a688-7a4976c6a71e/containers/ cpu-mem-request-limit/1cc072ca:/dev/termination-log"
],
"ContainerIDFile": "",
"LogConfig":
"Type": "json-file",
"Config":
"max-size": "100m"
,
"UTSMode": "",
"UsernsMode": "",
"ShmSize": 67108864,
"Runtime": "runc",
"ConsoleSize": [
0,
0
],
"Isolation": "",
"CpuShares": 256, CPU分配的权重,作用在requests.cpu上
"Memory": 268435456, 内存分配的大小,作用在limits.memory上
"NanoCpus": 0,
"CgroupParent": "kubepods-burstable-pod66958ef7_507a_41cd_a688_7a4976c6a71e.slice",
"BlkioWeight": 0,
"BlkioWeightDevice": null,
"BlkioDeviceReadBps": null,
"BlkioDeviceWriteBps": null,
"BlkioDeviceReadIOps": null,
"BlkioDeviceWriteIOps": null,
"CpuPeriod": 100000, CPU分配的使用比例,和CpuQuota一起作用在limits.cpu上
"CpuQuota": 50000,
"CpuRealtimePeriod": 0,
"CpuRealtimeRuntime": 0,
"CpusetCpus": "",
"CpusetMems": "",
"Devices": [],
"DeviceCgroupRules": null,
"DiskQuota": 0,
"KernelMemory": 0,
"MemoryReservation": 0,
"MemorySwap": 268435456,
"MemorySwappiness": null,
"OomKillDisable": false,
"PidsLimit": 0,
"Ulimits": null,
"CpuCount": 0,
"CpuPercent": 0,
"IOMaximumIOps": 0,
"IOMaximumBandwidth": 0,
,
]
CPU period 则是默认的 100 ms(100000 us)
CPU quota 如果没有任何限制(即:-1)
CPU和内存请求和限制的目的
通过为集群中运行的容器配置CPU和内存请求和限制,你可以有效利用集群节点上可用的CPU和内存资源。 通过将 Pod 的CPU和内存请求保持在较低水平,你可以更好地安排 Pod 调度。 通过让CPU和内存限制大于CPU和内存请求,你可以完成两件事:
- Pod 可以进行一些突发活动,从而更好的利用可用CPU和内存。
- Pod 在突发活动期间,可使用的CPU和内存被限制为合理的数量。
如果你没有指定CPU和内存限制
如果你没有为一个容器指定内存限制,则自动遵循以下情况之一:
- 容器可无限制地使用CPU和内存。容器可以使用其所在节点所有的可用CPU和内存, 进而可能导致该节点调用 OOM Killer。 此外,如果发生 OOM Kill,没有资源限制的容器将被杀掉的可行性更大。
- 运行的容器所在命名空间有默认的CPU和内存限制,那么该容器会被自动分配默认限制。 集群管理员可用使用 LimitRange 来指定默认的内存限制。
如果你设置了 CPU 限制和内存但未设置 CPU 请求和内存
如果你为容器指定了 CPU 限制值但未为其设置 CPU 请求,Kubernetes 会自动为其 设置与 CPU 限制相同的 CPU 请求值。
类似的,如果容器设置了内存限制值但未设置 内存请求值,Kubernetes 也会为其设置与内存限制值相同的内存请求。
https://kubernetes.io/zh/docs/tasks/configure-pod-container/assign-memory-resource/
https://kubernetes.io/zh/docs/tasks/configure-pod-container/assign-cpu-resource/
QoS
QoS 类为 Guaranteed的 Pod
- Pod 中的每个容器都必须指定内存限制和内存请求。
- 对于 Pod 中的每个容器,内存限制必须等于内存请求。
- Pod 中的每个容器都必须指定 CPU 限制和 CPU 请求。
- 对于 Pod 中的每个容器,CPU 限制必须等于 CPU 请求。
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "700m"
QoS 类为 Burstable 的 Pod
-
Pod 不符合 Guaranteed QoS 类的标准。
-
Pod 中至少一个容器具有内存或 CPU 请求。
resources:
limits:
memory: "200Mi"
requests:
memory: "100Mi"
QoS 类为 BestEffort 的 Pod
没有设置内存和 CPU 限制或请求
不同的 QoS 表现
不同的 Qos 在调度和底层表现有什么样的不同?

不同的 Qos,它其实在调度和底层表现上都有一些不一样。比如说调度表现, 调度器只会使用 request 进行调度,也就是不管你配了多大的 limit,它都不会进行调度使用,它只会使用 request 进行调度。
在底层上,不同的 Qos 表现更不相同。比如说 CPU,它其实是按 request 来划分权重的,不同的 Qos,它的 request 是完全不一样的,比如说像 Burstable 和 BestEffort,它可能 request 可以填很小的数字或者不填,这样的话,它的权重其实是非常低的。像 BestEffort,它的权重可能是只有 2,而 Burstable 或 Guaranteed,它的权重可以多到几千。
另外,当我们开启了 kubelet 的一个特性,叫 cpu-manager-policy=static 的时候,我们 Guaranteed Qos,如果它的 request 是一个整数的话,比如说配了 2,它会对 Guaranteed Pod 进行绑核。也就是具体像下面这个例子,它分配 CPU0 和 CPU1 给 Guaranteed Pod。
https://www.yuque.com/u974625/ogyvd1/oh9igq
QoS 应用场景之一:Eviction
Kubernetes 为 Pod 设置这样三种 QoS 类别,具体有什么作用呢?
实际上,QoS 划分的主要应用场景,是当宿主机资源紧张的时候,kubelet 对 Pod 进行 Eviction(即资源回收)时需要用到的。
具体地说,当 Kubernetes 所管理的宿主机上不可压缩资源短缺时,就有可能触发 Eviction。比如,可用内存(memory.available)、可用的宿主机磁盘空间(nodefs.available),以及容器运行时镜像存储空间(imagefs.available)等等。
目前,Kubernetes 为你设置的 Eviction 的默认阈值如下所示:
memory.available<100Mi
nodefs.available<10%
nodefs.inodesFree<5%
imagefs.available<15%
当然,上述各个触发条件在 kubelet 里都是可配置的。比如下面这个例子:
kubelet --eviction-hard=imagefs.available<10%,
memory.available<500Mi,
nodefs.available<5%,
nodefs.inodesFree<5%
--eviction-soft=imagefs.available<30%,nodefs.available<10%
--eviction-soft-grace-period=imagefs.available=2m,nodefs.available=2m
--eviction-max-pod-grace-period=600
在这个配置中,你可以看到Eviction 在 Kubernetes 里其实分为 Soft 和 Hard 两种模式。
其中,Soft Eviction 允许你为 Eviction 过程设置一段“优雅时间”,比如上面例子里的 imagefs.available=2m,就意味着当 imagefs 不足的阈值达到 2 分钟之后,kubelet 才会开始 Eviction 的过程。
而 Hard Eviction 模式下,Eviction 过程就会在阈值达到之后立刻开始。
Kubernetes 计算 Eviction 阈值的数据来源,主要依赖于从 Cgroups 读取到的值,以及使用 cAdvisor 监控到的数据。
当宿主机的 Eviction 阈值达到后,就会进入 MemoryPressure 或者 DiskPressure 状态,从而避免新的 Pod 被调度到这台宿主机上。
而当 Eviction 发生的时候,kubelet 具体会挑选哪些 Pod 进行删除操作,就需要参考这些 Pod 的 QoS 类别了。
- 首当其冲的,自然是 BestEffort 类别的 Pod。
- 其次,是属于 Burstable 类别、并且发生“饥饿”的资源使用量已经超出了 requests 的 Pod。
- 最后,才是 Guaranteed 类别。并且,Kubernetes 会保证只有当 Guaranteed 类别的 Pod 的资源使用量超过了其 limits 的限制,或者宿主机本身正处于 Memory Pressure 状态时,Guaranteed 的 Pod 才可能被选中进行 Eviction 操作。
当然,对于同 QoS 类别的 Pod 来说,Kubernetes 还会根据 Pod 的优先级来进行进一步地排序和选择。
资源配额的工作方式:
- 不同的团队可以在不同的命名空间下工作,目前这是非约束性的,在未来的版本中可能会通过 ACL (Access Control List 访问控制列表) 来实现强制性约束。
- 集群管理员可以为每个命名空间创建一个或多个 ResourceQuota 对象。
- 当用户在命名空间下创建资源(如 Pod、Service 等)时,Kubernetes 的配额系统会 跟踪集群的资源使用情况,以确保使用的资源用量不超过 ResourceQuota 中定义的硬性资源限额。
- 如果资源创建或者更新请求违反了配额约束,那么该请求会报错(HTTP 403 FORBIDDEN), 并在消息中给出有可能违反的约束。
- 如果命名空间下的计算资源 (如
cpu和memory)的配额被启用,则用户必须为 这些资源设定请求值(request)和约束值(limit),否则配额系统将拒绝 Pod 的创建。 提示: 可使用LimitRanger准入控制器来为没有设置计算资源需求的 Pod 设置默认值。
如何满足 Pod 资源要求?
上面介绍完了基础资源的使用方式,也就是我们做到了如何满足 Pod 资源要求。下面做一个小结:
-
Pod 要配置合理的资源要求
-
CPU/Memory/EphemeralStorage/GPU
- 第一类是 CPU 资源;
- 第二类是 memory;
- 第三类是 ephemeral-storage,一种临时存储;
- 第四类是通用的扩展资源,比如说像 GPU
**在扩展资源上,Kubernetes 有一个要求,即扩展资源必须是整数的,所以我们没法申请到 0.5 的 GPU 这样的资源,只能申请 1 个 GPU 或者 2 个 GPU。**可以借助社区方案。
-
-
通过 Request 和 Limit 来为不同业务特点的 Pod 选择不同的 QoS
-
Guaranteed:敏感型,需要业务保障;
是一类高的 Qos Class,一般用 Guaranteed 来为一些需要资源保障能力的 pod 进行配置;
-
Burstable:次敏感型,需要弹性业务
中等的一个 Qos label,一般会为一些希望有弹性能力的 pod 来配置 Burstable;
-
BestEffort:可容忍性业务(尽力而为)
是一种尽力而为式的服务质量
-
资源请求和限制的生产建议
- requests和limits资源定义推荐不超过1:2,避免分配过多资源而出现资源争抢,发生OOM;
- pod中默认没有定义resource,推荐给namespace定义一个limitrange,确保pod能分到资源;
- 防止node上资源过度而出现机器hang住或者OOM,建议node上设置保留和驱逐资源,如保留资源–system-reserved=cpu=200m,memory=1G,驱逐条件–eviction hard=memory.available<500Mi。
3. Pod详解-健康检查
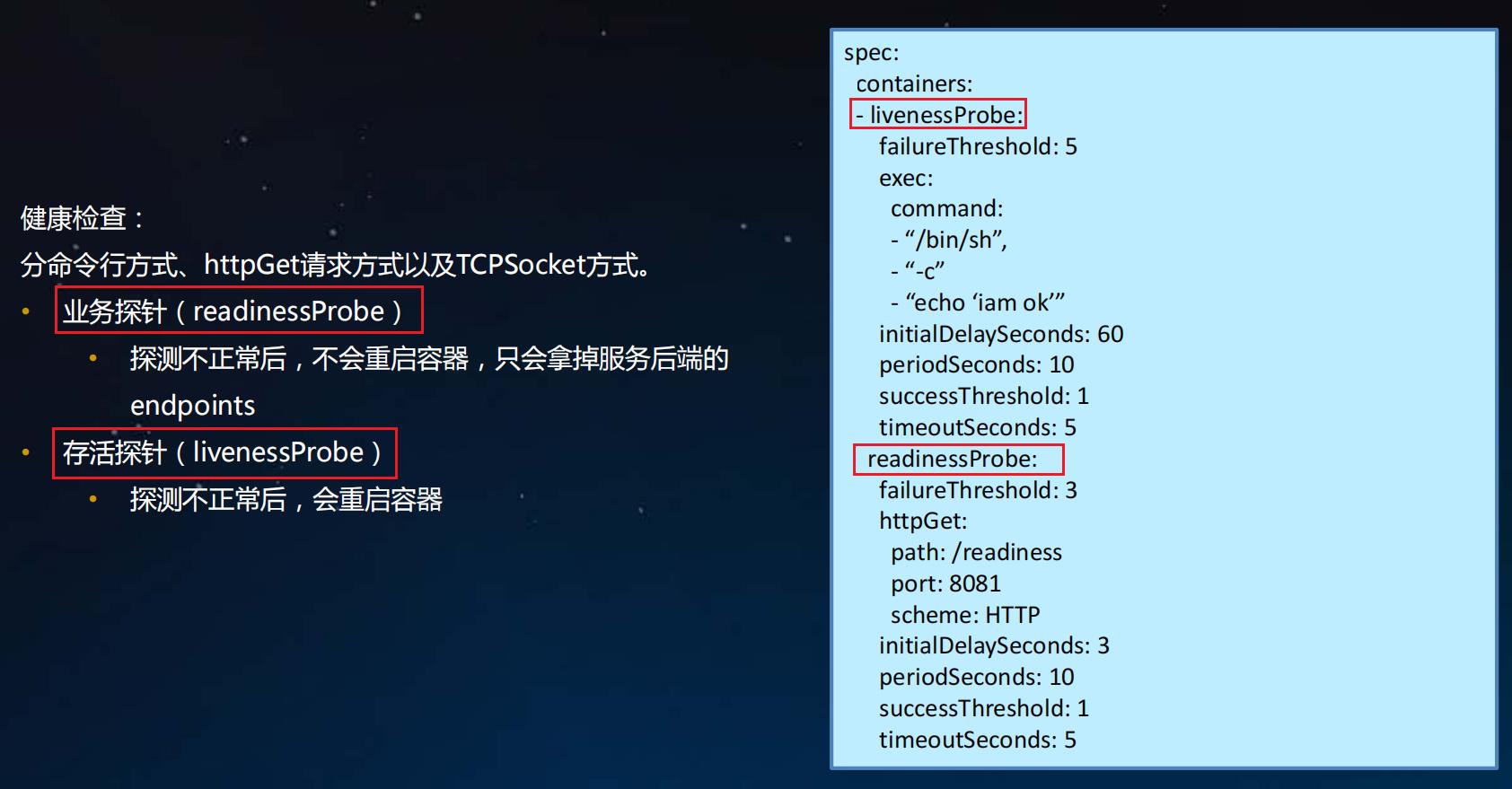
三种探针Probe
应用在运行过程中难免会出现错误,如程序异常,软件异常,硬件故障,网络故障等,kubernetes提供Health Check健康检查机制,当发现应用异常时会自动重启容器,将应用从service服务中剔除,保障应用的高可用性。k8s定义了三种探针Probe:
- liveness probes 在线检查机制,检查应用是否可用,如死锁,无法响应,异常时会自动重启容器; 用于存活检查,检查容器内部运行状态
- readiness probes 准备就绪检查,通过readiness是否准备接受流量,准备完毕加入到endpoint,否则剔除; 用于健康检查和服务探测机制
- startup probes 启动检查机制,应用一些启动缓慢的业务,避免业务长时间启动而被前面的探针kill掉
三种健康检查方法
每种探测机制支持三种健康检查方法,分别是命令行exec,httpGet和tcpSocket,其中exec通用性最强,适用与大部分场景,tcpSocket适用于TCP业务,httpGet适用于web业务。
- exec 提供命令或shell的检测,在容器中执行命令检查,返回码为0健康,非0异常
- httpGet http协议探测,在容器中发送http请求,根据http返回码判断业务健康情况
- tcpSocket tcp协议探测,向容器发送tcp建立连接,能建立则说明正常
配置探测器
Probe 有很多配置字段,可以使用这些字段精确地控制活跃和就绪检测的行为:
initialDelaySeconds:容器启动后要等待多少秒后才启动存活和就绪探测器, 默认是 0 秒,最小值是 0。periodSeconds:执行探测的时间间隔(单位是秒)。默认是 10 秒。最小值是 1。timeoutSeconds:探测的超时后等待多少秒。默认值是 1 秒。最小值是 1。successThreshold:探测器在失败后,被视为成功的最小连续成功数。默认值是 1。 存活和启动探测的这个值必须是 1。最小值是 1。failureThreshold:当探测失败时,Kubernetes 的重试次数。 对存活探测而言,放弃就意味着重新启动容器。 对就绪探测而言,放弃意味着 Pod 会被打上未就绪的标签。默认值是 3。最小值是 1。
参考:https://kubernetes.io/zh/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
4. Pod详解-配置文件
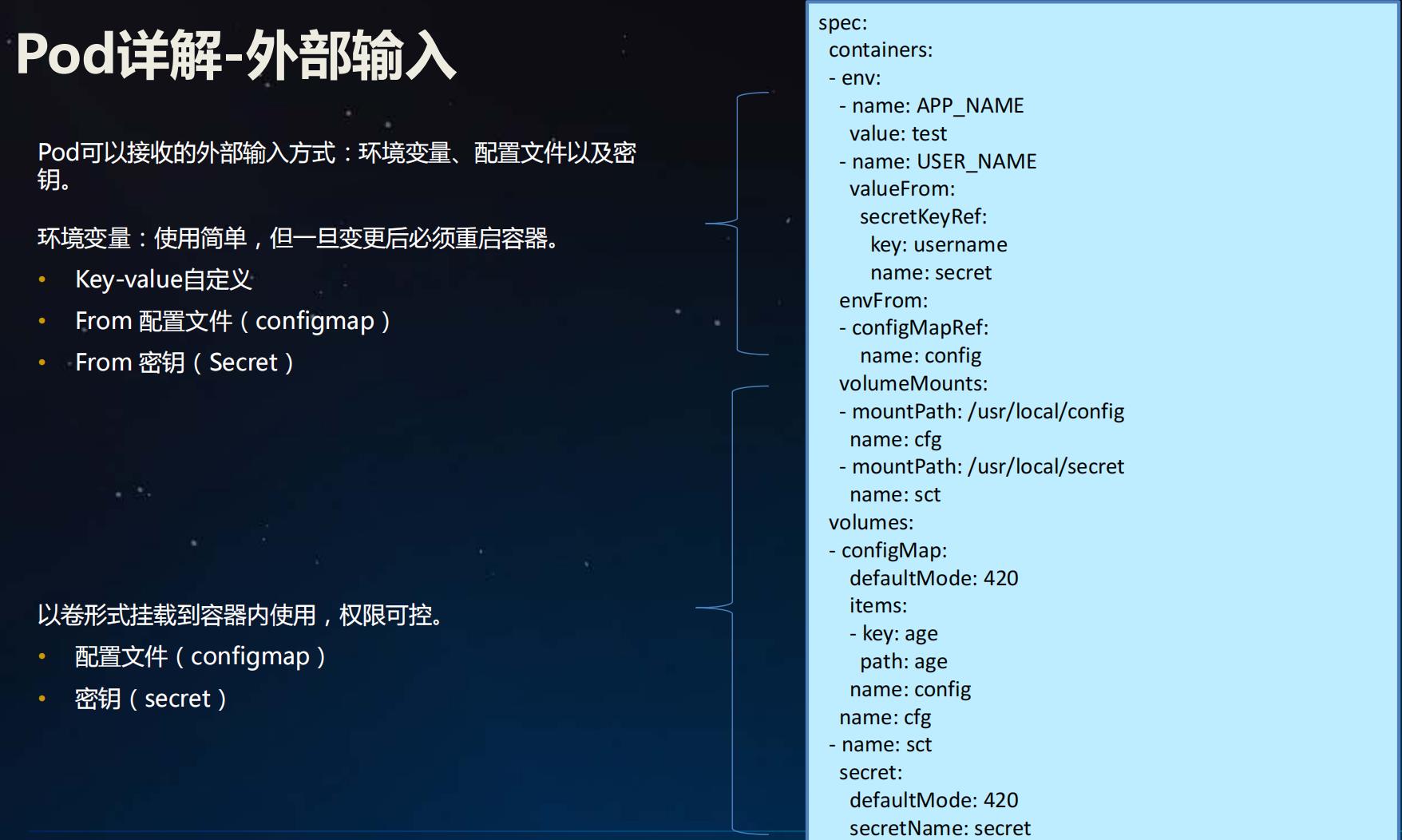
配置文件( ConfigMap)及密钥( Secret)介绍

参考:
https://kubernetes.io/zh/docs/tasks/configure-pod-container/configure-pod-configmap/
https://kubernetes.io/zh/docs/tasks/configmap-secret/managing-secret-using-config-file/
5. Pod详解-持久化存储
volume存储

kubernetes容器中的数据是临时的,即当重启重启或crash后容器的数据将会丢失,此外容器之间有共享存储的需求,所以kubernetes中提供了volume存储的抽象,volume后端能够支持多种不同的plugin驱动,通过.spec.volumes中定义一个存储,然后在容器中.spec.containers.volumeMounts调用,最终在容器内部以目录的形式呈现。
kubernetes内置能支持多种不同的驱动类型,大体上可以分为四种类型:
公/私有云驱动接口,如awsElasticBlockStore实现与aws EBS集成,
开源存储驱动接口,如ceph rbd,实现与ceph rb块存储对接
本地临时存储,如hostPath,
kubernetes对象API驱动接口,实现其他对象调用,如configmap,每种存储支持不同的驱动,
如下介绍:
1. 公/私有云驱动接口
| 类型 | 说明 |
|---|---|
| awsElasticBlockStore | AWS的EBS云盘 |
| azureFile | 微软NAS存储 |
| gcePersistentDisk | google云盘 |
| cinder | openstack cinder云盘 |
| vsphereVolume | VMware的VMFS存储 |
| scaleIO | EMC分布式存储 |
2. 开源存储驱动接口
| 类型 | 说明 |
|---|---|
| ceph rbd | ceph块存储 |
| cephfs | glusterfs存储 |
| nfs | nfs文件 |
| flexvolume | 社区标准化驱动 |
| csi | 社区标准化驱动 |
3. 本地临时存储
| 类型 | 说明 |
|---|---|
| hostpath | 宿主机文件 |
| emptyDir | 临时目录 |
emptyDir是host上定义的一块临时存储,通过bind mount的形式挂载到容器中使用,容器重启数据会保留,容器删除则volume会随之删除。
hostPath与emptyDir类似提供临时的存储,hostPath适用于一些容器需要访问宿主机目录或文件的场景,对于数据持久化而言都不是很好的实现方案。
4. kubernetes对象API驱动接口
| 类型 | 说明 |
|---|---|
| configMap | 调用configmap对象,注入配置文件 |
| secrets | 调用secrets对象,注入秘文配置文件 |
| persistentVolumeClaim | 通过pvc调用存储 |
| downloadAPI | |
| projected |
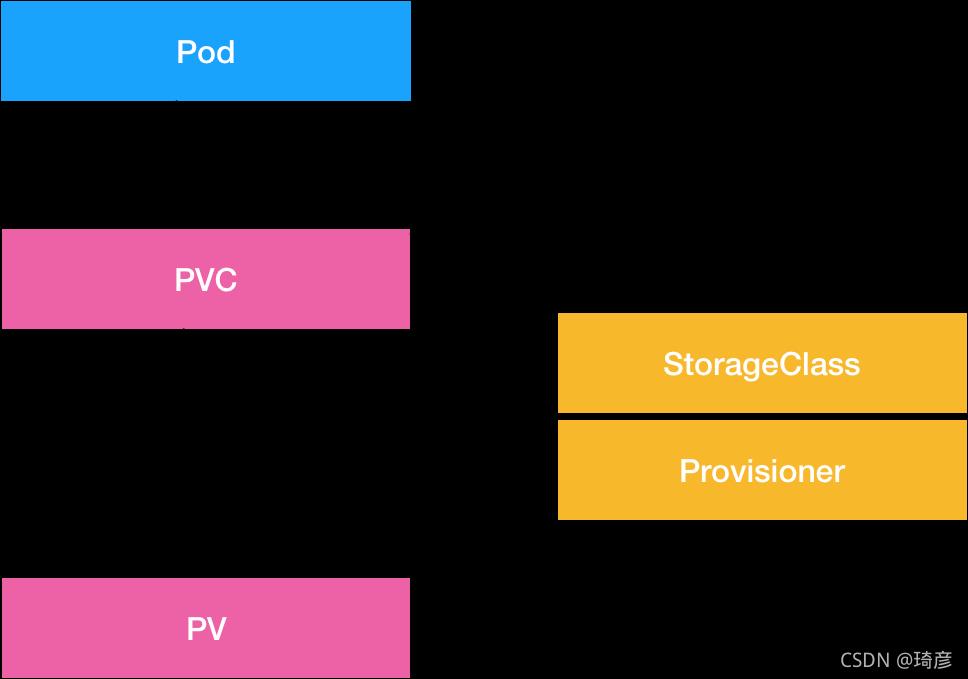
PV,PVC和StorageClass
- Volume 存储卷,独立于容器,后端和不同的存储驱动对接
- PV Persistent Volume持久化存储卷,和node类似,是一种集群资源,由管理员定义,对接不同的存储
- PVC PersistentVolumeClaims持久化存储声明,和pod类似,作为PV的使用者
- StorageClass 动态存储类型,分为静态和动态两种类型,通过在PVC中定义存储类型,自动创建所需PV
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Hh7r1GPj-1650714444497)(https://cdn.jsdelivr.net/gh/Fly0905/note-picture@main/img/202204222056762.png)]
pv, pvc和storageclass关系
 [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vUHepFxx-1650714444499)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-vUHepFxx-1650714444499)(data:image/gif;base64,R0lGODlhAQABAPABAP///wAAACH5BAEKAAAALAAAAAABAAEAAAICRAEAOw==)]
从图中我们可以看到,在这个体系中:
- PVC 描述的,是 Pod 想要使用的持久化存储的属性,比如存储的大小、读写权限等。
- PV 描述的,则是一个具体的 Volume 的属性,比如 Volume 的类型、挂载目录、远程存储服务器地址等。
- 而 StorageClass 的作用,则是充当 PV 的模板。并且,只有同属于一个 StorageClass 的 PV 和 PVC,才可以绑定在一起。
当然,StorageClass 的另一个重要作用,是指定 PV 的 Provisioner(存储插件)。这时候,如果你的存储插件支持 Dynamic Provisioning 的话,Kubernetes 就可以自动为你创建 PV 了。
Kubernetes 为我们提供了一套可以自动创建 PV 的机制,即:Dynamic Provisioning。相比之下,人工管理 PV 的方式就叫作 Static Provisioning。Dynamic Provisioning 机制工作的核心,在于一个名叫 StorageClass 的 API 对象。
容器持久化存储涉及的概念比较多,试着总结一下整体流程。
用户提交请求创建pod,Kubernetes发现这个pod声明使用了PVC,那就靠PersistentVolumeController帮它找一个PV配对。
没有现成的PV,就去找对应的StorageClass,帮它新创建一个PV,然后和PVC完成绑定。
新创建的PV,还只是一个API 对象,需要经过“两阶段处理”变成宿主机上的“持久化 Volume”才真正有用:
- 第一阶段由运行在master上的AttachDetachController负责,为这个PV完成 Attach 操作,为宿主机挂载远程磁盘;
- 第二阶段是运行在每个节点上kubelet组件的内部,把第一步attach的远程磁盘 mount 到宿主机目录。这个控制循环叫VolumeManagerReconciler,运行在独立的Goroutine,不会阻塞kubelet主循环。
完成这两步,PV对应的“持久化 Volume”就准备好了,POD可以正常启动,将“持久化 Volume”挂载在容器内指定的路径。
简而言之:
StorageClass (SC):存储类,类似存储池的概念,包括了存储池的一些信息;
PersistenVolume (PV):持久卷,独立的存储资源对象,其生命周期与Pod无关;
PersistenVolumeClaim (PVC): 声明,代表计算任务对存储资源的需求。
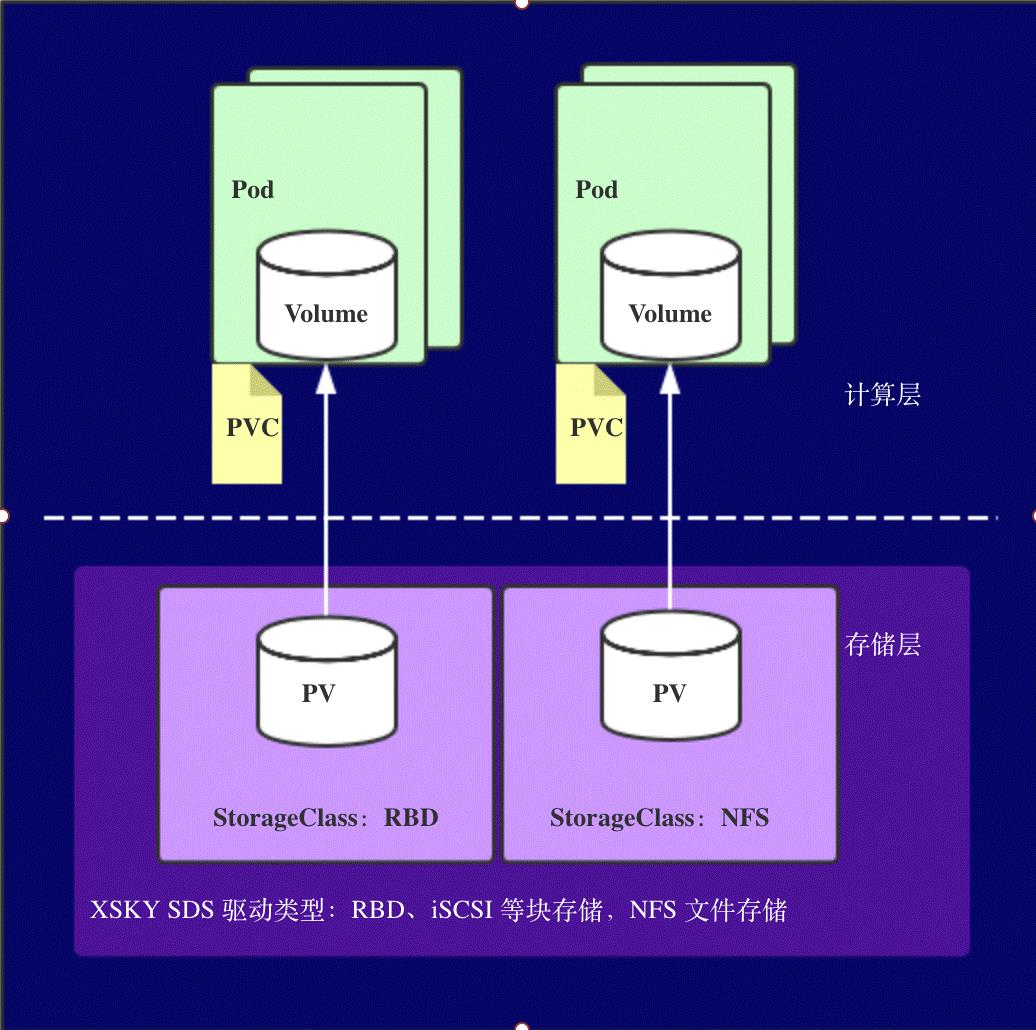
这种存储结构是为了解决
- 有状态的容器实例需要持久化卷;
- 容器实例动态提供新卷;
- 不同类型的应用需要不同访问模式的存储卷;
- 解耦计算资源和存储资源。
6. Pod详解-服务域名发现
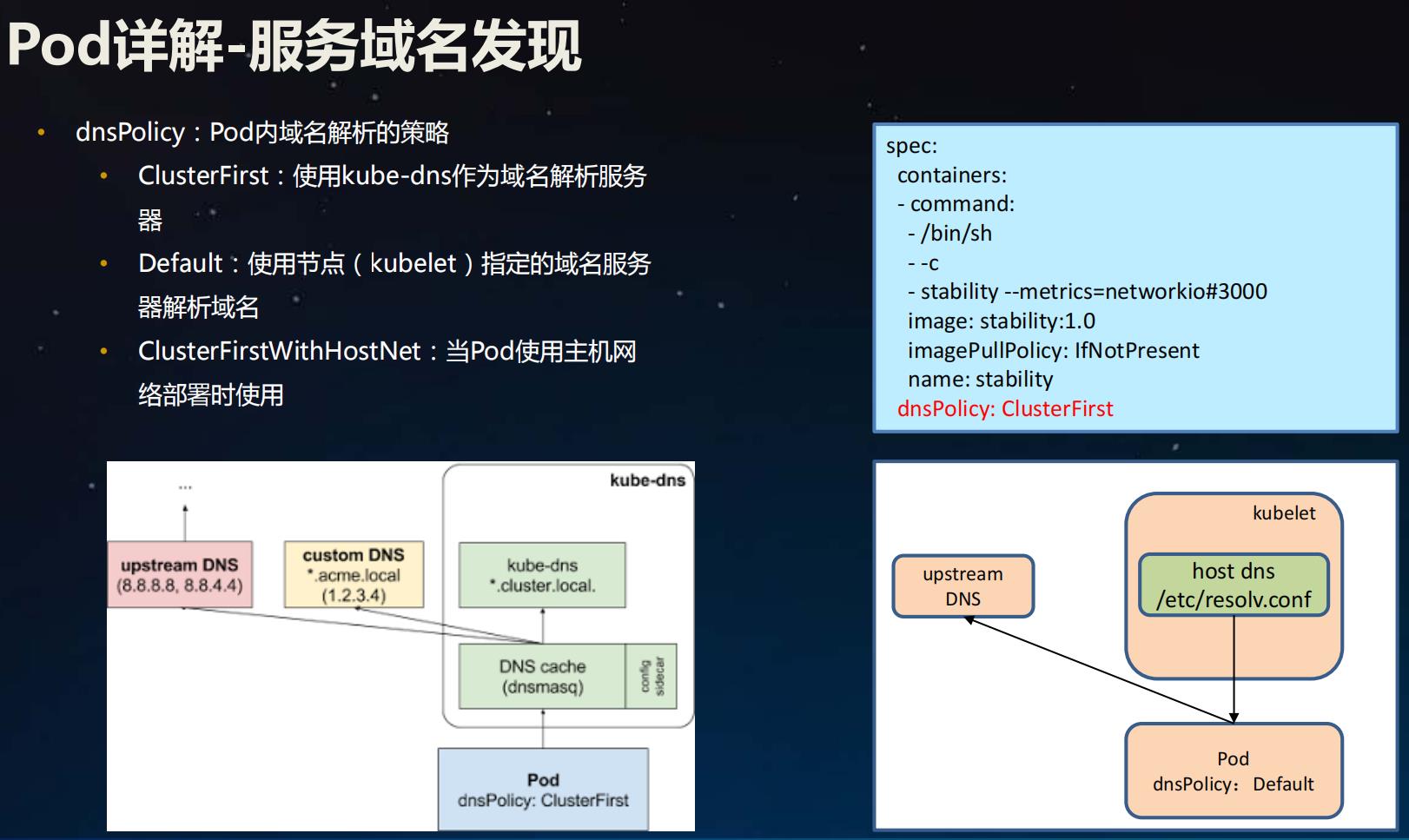
dnsPolicy: Pod内域名解析的策略
- **ClusterFirst:**使用kube-dns作为域名解析服务器
- **Default:**使用节点( kubelet)指定的域名服务器解析域名
- **ClusterFirstWithHostNet:**当Pod使用主机网络部署时使用
如何快速编写yaml文件
通过定义模版快速生成
设置
dryRun查询参数来触发空运行
通过定义模版快速生成,kubectl create apps -o yaml --dry-run的方式生成,–dry-run仅仅是试运行,并不实际在k8s集群中运行,通过指定-o yaml输出yaml格式文件,生成后给基于模版修改即可,如下:
[root@node-1 demo]# kubectl create deployment demo --image=nginx:latest --dry-run -o yaml
apiVersion: apps/v1
kind: Deployment
metadata:
creationTimestamp: null
labels:
app: demo
name: demo
spec:
replicas: 1
selector:
matchLabels:
app: demo
strategy:
template:
metadata:
creationTimestamp: null
labels:
app: demo
spec:
containers:
- image: nginx:latest
name: nginx
resources:
status:
explain命令
explain命令堪称是语法查询器,可以查到每个字段的含义,使用说明和使用方式,如想要查看Pod的spec中containers其他支持的字段,可以通过kubectl explain Pod.spec.containers的方式查询,如下:
[root@node-1 demo]# kubectl explain Pods.spec.containers
KIND: Pod
VERSION: v1
RESOURCE: containers <[]Object>
DESCRIPTION:
List of containers belonging to the pod. Containers cannot currently be
added or removed. There must be at least one container in a Pod. Cannot be
updated.
A single application container that you want to run within a pod.
FIELDS:
args <[]string> #命令参数
Arguments to the entrypoint. The docker image's CMD is used if this is not
provided. Variable references $(VAR_NAME) are expanded using the
container's environment. If a variable cannot be resolved, the reference in
the input string will be unchanged. The $(VAR_NAME) syntax can be escaped
with a double $$, ie: $$(VAR_NAME). Escaped references will never be
expanded, regardless of whether the variable exists or not. Cannot be
updated. More info:
https://kubernetes.io/docs/tasks/inject-data-application/define-command-argument-container/#running-a-command-in-a-shell
image <string> #镜像定义
Docker image name. More info:
https://kubernetes.io/docs/concepts/containers/images This field is
optional to allow higher level config management to default or override
container images in workload controllers like Deployments and StatefulSets.
ports <[]Object> #端口定义
List of ports to expose from the container. Exposing a port here gives the
system additional information about the network connections a container
uses, but is primarily informational. Not specifying a port here DOES NOT
prevent that port from being exposed. Any port which is listening on the
default "0.0.0.0" address inside a container will be accessible from the
network. Cannot be updated.
readinessProbe <Object> #可用健康检查
Periodic probe of container service readiness. Container will be removed
from service endpoints if the probe fails. Cannot be updated. More info:
https://kubernetes.io/docs/concepts/workloads/pods/pod-lifecycle#container-probes
resources <Object> #资源设置
Compute Resources required by this container. Cannot be updated. More info:
https://kubernetes.io/docs/concepts/configuration/manage-compute-resources-container/
...省略部分输出...
volumeMounts <[]Object> #挂载存储
Pod volumes to mount into the container's filesystem. Cannot be updated