Python入门自学进阶-Web框架——6Django的ORM-多对多admin应用
Posted kaoa000
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python入门自学进阶-Web框架——6Django的ORM-多对多admin应用相关的知识,希望对你有一定的参考价值。
对于多对多关系,如前面的Book和Author表,进行多对多关联插入时,有两种方法:
第一种是前面介绍的通过book.author.add(*作者对象列表)来增加,这叫做正向查询插入,因为多对多字段定义在Book中,为author,通过book.author就是正向。
book = models.Book.objects.filter(id=2)[0]
authors = models.Author.objects.filter(id__gt=2)
book.author.add(*authors)
第二种是反向查询插入,通过author进行插入
author = models.Author.objects.filter(id=2)[0]
books = models.Book.objects.filter(id__gt=2)
author.book_set.add(*books)
这里要注意的是book_set是固定的写法,就是表名的小写加下划线set(表名小写_set),因为在Author表中没有显示的字段与Book表关联,Django自动使用这个名来关联,而books是上面获取的书的对象集合。通过author.book_set就是反向插入
多对多关系表,可以使用Django的ManyToManyField()建立,也可以自己手工建立,假设我们自己建立,定义类Book2Author:
class Book2Author(models.Model):
book = models.ForeignKey("Book",on_delete=models.DO_NOTHING)
author = models.ForeignKey("Author",on_delete=models.DO_NOTHING)
# 这两个字段都不需要加_id,Django会自动增加
# 手动创建多对多的表,定义了外键后,还需要定义联合唯一
class Meta:
unique_together = ["author","book"]
# 这用来确定book和author两个字段联合唯一操作这张表,可以使用:
models.Book2Author.objects.create(book_id=2,author_id=3);
一对一的表:是一对多的特例,也可以使用ForeignKey来生成:
publisher = models.ForeignKey("Publish",unique=true)
表记录的删除:
models.Book.objects.filter(id=3).delete()
删除表Book中的id=3的记录,同时,对于关联表中设置了on_delete为级联操作的表中的记录也同时删除。
表记录的修改:
models.Book.objects.filter(id=3).update(name="dsafdsa")
这里要注意,使用update的对象必须是QuerySet,所以前面的查找只用是filter,不能用get,get返回的是model对象,没有update方法。
使用save方法也可实现修改,但是效率不高,对全部字段都做了保存,即使有的字段没做修改,update只修改更改的字段。update()方法会返回一个整型数值,表示受影响的记录条数
表记录的查询:
filter(**kwargs)、all()、get(**kwargs)
对查询的结果再进行处理:values(*field)、values_list(*field)、exclude(**kwargs)、order_by(*field)、reverse()、distinct()、count()、exists()、first()、last()等
惰性机制:
所谓惰性机制就是:Publisher.objects.all()或者.filter()等都只是返回了一个QuerySet(查询结果集对象),它并不会马上执行sql,而是当调用QuerySet的时候才执行。
对于每次创建一个对象,想显示对应的raw sql,需要在settings加上日志记录部分:
LOGGING =
'version': 1,
'disable_existing_loggers': False,
'handlers':
'console':
'level':'DEBUG',
'class':'logging.StreamHandler',
,
,
'loggers':
'django.db.backends':
'handlers': ['console'],
'propagate': True,
'level':'DEBUG',
,
会打印出SQL语句
QuerySet可迭代,可切片,这两种操作都是对QuerySet的使用,这时操作数据库,即执行sql语句。
多表关联查询:
对象形式的查找:
还是前面的例子,我找到了一本书《骆驼祥子》,现在想打印出这本书的出版社的名字:
book_obj = models.Book.objects.filter(title="骆驼祥子")[0] # 取到书对象
print(book_obj.publisher.name) # 通过外键publisher拿到对应出版社对象,直接点name即打印出出版社名称。这是正向查找
有一个出版社,想找出此出版社出版的所有书的名字:
pub_obj = models.Publish.objects.filter(name="人民出版社")[0]
pub_obj.book_set.values("title")
以上是反向查找。
了不起的双下划线(__)之单表条件查询
# models.Tb1.objects.filter(id__lt=10, id__gt=1) # 获取id大于1 且 小于10的值,这里逗号分隔是and关系。
# models.Tb1.objects.filter(id__in=[11, 22, 33]) # 获取id等于11、22、33的数据
# models.Tb1.objects.exclude(id__in=[11, 22, 33]) # not in
# models.Tb1.objects.filter(name__contains="ven") # 包含
# models.Tb1.objects.filter(name__icontains="ven") # icontains大小写不敏感
# models.Tb1.objects.filter(id__range=[1, 2]) # 范围bettwen and
# startswith,istartswith, endswith, iendswith,
了不起的双下划线(__)之关联表查询:
以上面的例子:找到了一本书《骆驼祥子》,现在想打印出这本书的出版社的名字models.Publish.objects.filter(book__title="骆驼祥子").values("name")
models.Book.objects.filter(title="骆驼祥子").values("publisher__name")
人民出版社出版的所有书的名字:
models.Book.objects.filter(publisher__name="人民出版社").values("title")
对象、QuerySet都有一个query属性,存储着这个结果的sql语句。
聚合查询和分组查询:
都叫聚合函数,区别是处理的对象不同,聚合是处理的一个对象,分组是处理的多个对象。
聚合查询:
aggregate(*args,**kwargs):通过对QuerySet进行计算,返回一个聚合值的字典。aggregate()中每一个参数都指定一个包含在字典中的返回值。即在查询集上生成聚合。
Book.objects.all().aggregate(Avg('price')) #求所有书的平均价格
Book.objects.filter(authors_id=1).aggregate(Avg('price'))
先查询出一个对象,即QuerySet,再对这个对象执行聚合查询
aggregate()子句的参数描述了我们想要计算的聚合值,在这个例子中,是Book模型中price字段的平均值 aggregate()是QuerySet 的一个终止子句,意思是说,它返回一个包含一些键值对的字典。键的名称是聚合值的 标识符,值是计算出来的聚合值。键的名称是按照字段和聚合函数的名称自动生成出来的。如果你想要为聚合值指定 一个名称,可以向聚合子句提供它: Book.objects.aggregate(average_price=Avg('price')) 'average_price': 34.35
所有图书价格的最大值和最小值,可以这样查询:
Book.objects.aggregate(Avg('price'), Max('price'), Min('price'))
结果: 'price__avg': 34.35, 'price__max': Decimal('81.20'), 'price__min': Decimal('12.99')
分组查询:
annotate(*args,**kwargs):可以通过计算查询结果中每一个对象所关联的对象集合,从而得出总计值(也可以是平均值或总和),即为查询集的每一项生成聚合。
查询每一个作者出的书的价格的平均值:
Book.objects.values("authors__name").annotate(Sum('price')) #先根据作者名字把书分成多组,然后对每组的price字段执行求和操作,这就是分组查询,其查询结果可能如下:
['authors__name':'老舍','price__sum':Decimal('123.10'),'authors__name':'鲁迅','price__sum':Decimal('110.50'),'authors__name':'巴金','price__sum':Decimal('163.10')]
F查询和Q查询:
F查询,使用查询条件的值,专门取对象中某列值的操作
如:想要修改所有Book表中书的价格,价格提高10%
models.Book.objects.all().update(price=price*1.1) #这是按照经验做的更新,提示错误,price是字段,这里当做变量用了,修改如下:
models.Book.objects.all().update(price=F("price")*1.1)
Q查询:查询条件为或的关系
models.Book.objects.filter(Q(id=3) | Q(title="php")) #找id为3或者title为php的书,|符号,即管道符是或的关系,&是与的关系,~是非的关系。
#1 Q对象(django.db.models.Q)可以对关键字参数进行封装,从而更好地应用多个查询
q1=models.Book.objects.filter(Q(title__startswith='P')).all()
print(q1)#[<Book: Python>, <Book: Perl>]
# 2、可以组合使用&,|操作符,当一个操作符是用于两个Q的对象,它产生一个新的Q对象。
Q(title__startswith='P') | Q(title__startswith='J')
# 3、Q对象可以用~操作符放在前面表示否定,也可允许否定与不否定形式的组合
Q(title__startswith='P') | ~Q(pub_date__year=2005)
admin的配置:
Django admin是Django自带的一个后台app,提供了后台管理功能
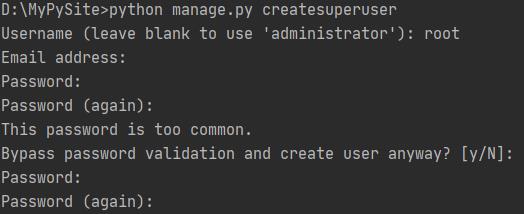
启用admin的过程,创建好项目后,执行数据库表的创建,即migrate,然后创建用户名和密码
python manage.py createsuperuser
Django admin相当于一个页面版的数据库管理系统,可以管理数据库表,是通过注册model类来实现的。
1、语言的设置:在setting.py 文件中修改以下选项
LANGUAGE_CODE = 'en-us' #LANGUAGE_CODE = 'zh-hans'
2、ModelAdmin类:
管理界面的定制类,如需要扩展特定的model界面需要从这个类继承
3、注册model类到admin,实现对相应表的管理,两种方式:
<1> 使用register的方法
admin.site.register(Book,MyAdmin)
<2> 使用register的装饰器
@admin.register(Book)
在相关应用的admin.py中进行注册:
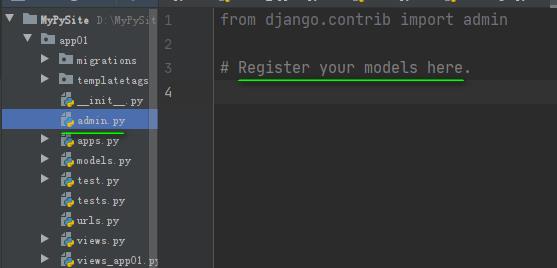
使用第一种方法,在我的测试环境中,即3.2.11中,是没有register方法的,只能使用装饰器来进行注册:
from django.contrib import admin
from app01.models import *
# Register your models here.
@admin.register(Book)
class AuthorAdmin(admin.ModelAdmin):
pass结果:
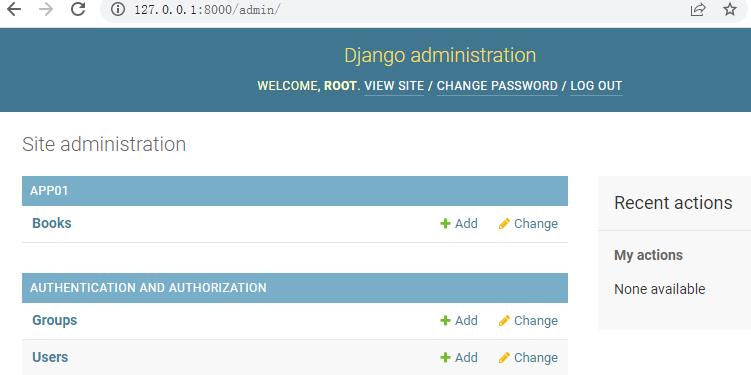
可以看到,增加了app01应用,增加了一个Books,但是我们注册的Book,这里显示的是Books,自动增加了一个s。点击Books进入:
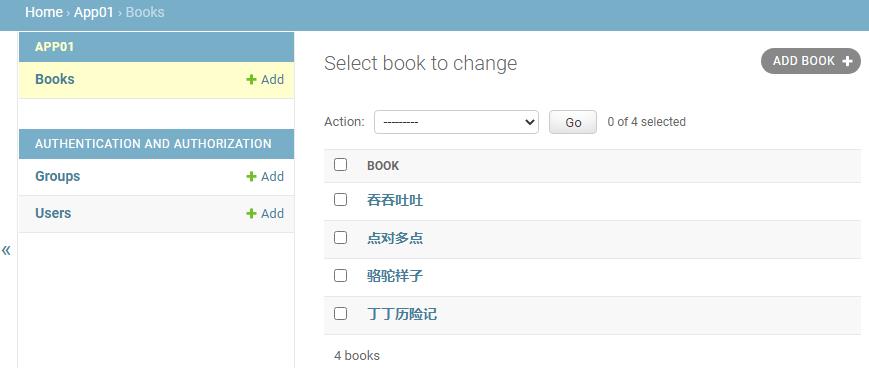
这里为什么显示的是书名呢?因为在定义Book这个model时,定义了:
def __str__(self):
return self.title
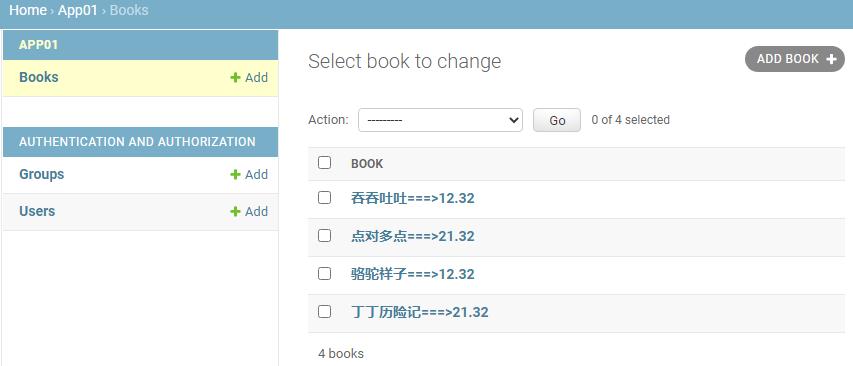
这里就是打印各个Book对象,修改:return self.title + "===>"+str(self.price),结果:
点击“ADD BOOK”
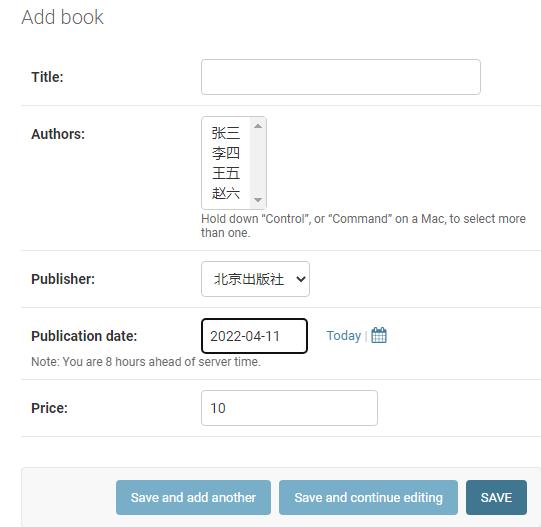
这里作者,即Authors显示了作者名,也是应为Authors中定义了__str__(self),否则会显示Author object
设置LANGUAGE_CODE='zh-hans'后,界面
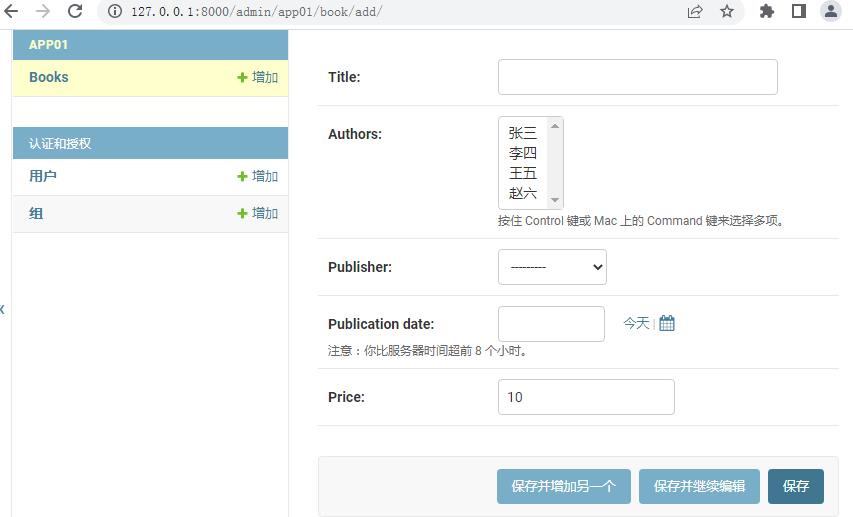
现在Book显示只显示了书的名字,如果想显示所有字段,需要进行定制,即修改前面装饰器装饰的AuhtorAdmin类:
from django.contrib import admin
from app01.models import *
# Register your models here.
@admin.register(Book)
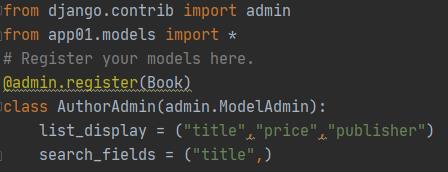
class AuthorAdmin(admin.ModelAdmin):
list_display = ("title","price","publisher")
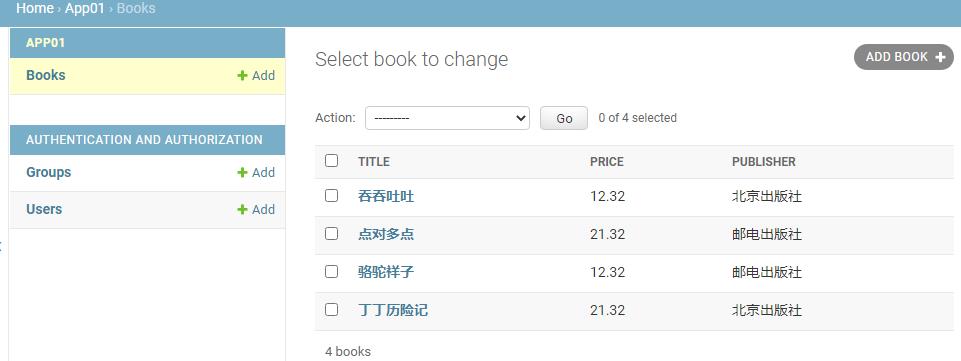
相应的还有:
- list_display: 指定要显示的字段
- search_fields: 指定搜索的字段
- list_filter: 指定列表过滤器
- ordering: 指定排序字段
显示的Books列标题是类中定义的字段名,想修改一下,如想显示一个汉字名称,这时要在注册的类,这里就是Book中,字段定义中使用verbose_name=参数:
class Book(models.Model):
title = models.CharField(max_length=100,verbose_name="书名")
authors = models.ManyToManyField(Author) # 多对多,外键可以放到任意一方
publisher = models.ForeignKey(Publisher,on_delete=models.CASCADE,verbose_name="出版社") # 一对多,表中字段是publisher_id,Django自动处理的
publication_date = models.DateField()
price = models.DecimalField("价格",max_digits=5,decimal_places=2,default=10)
def __str__(self):
return self.title注意,直接在第一参数位置写别名和使用verbose_name=别名效果相同。如下图
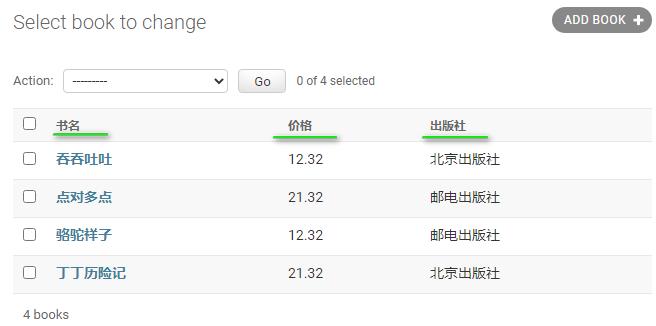
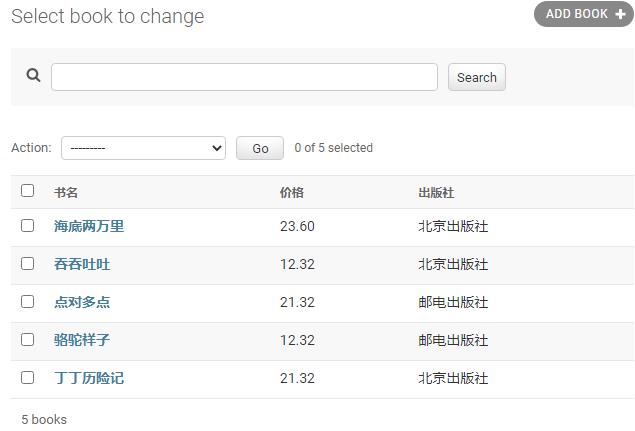
search_fields: 指定搜索的字段,添加一个搜索框,按照指定的字段查询:
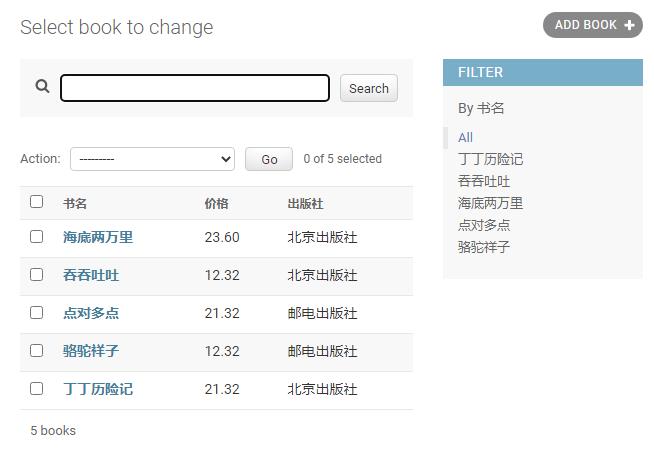
list_filter: 指定列表过滤器:添加 : list_filter = ("title",)
以上是关于Python入门自学进阶-Web框架——6Django的ORM-多对多admin应用的主要内容,如果未能解决你的问题,请参考以下文章