Linux内存从0到1学习笔记(九,内存优化调试之一 - kswapd0)
Posted 高桐@BILL
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux内存从0到1学习笔记(九,内存优化调试之一 - kswapd0)相关的知识,希望对你有一定的参考价值。
写在前面
Linux内核中有一个非常重要的内核线程kswapd,它负责在内存不足时回收页面。kswapd内核线程初始化时会为系统中每个内存结点创建一个名为“kswapd%"内核线程。对于UMA架构下常常是kswapd0线程。
因此我们可以把kswapd0看作是系统的虚拟内存管理程序,如果物理内存不够用,系统就会唤醒 kswapd0 进程。但是需要特别注意的是,由于kswapd0分配磁盘交换空间作缓存,因此会占用大量的CPU资源。
术语
swap
指的是一个交换分区或文件。负责在内存不足时,将部分内存上的数据交换到swap空间上,以便让系统不会因内存不够用而导致oom或者更致命的情况出现。所以,当内存使用存在压力,开始触发内存回收的行为时,就可能会使用swap空间。
在Linux上可以使用swapon -s命令查看当前系统上正在使用的交换空间有哪些,以及相关信息:

kswapd
Linux内核中有一个非常重要的内核线程kswapd,它负责在内存不足时回收页面。
watermark_scale_factor
======================
This factor controls the aggressiveness of kswapd. It defines the
amount of memory left in a node/system before kswapd is woken up and
how much memory needs to be free before kswapd goes back to sleep.
The unit is in fractions of 10,000. The default value of 10 means the
distances between watermarks are 0.1% of the available memory in the
node/system. The maximum value is 3000, or 30% of memory.
A high rate of threads entering direct reclaim (allocstall) or kswapd
going to sleep prematurely (kswapd_low_wmark_hit_quickly) can indicate
that the number of free pages kswapd maintains for latency reasons is
too small for the allocation bursts occurring in the system. This knob
can then be used to tune kswapd aggressiveness accordingly.一、页面回收机制调用路径
首先,我们来看下页面回收机制的主要调用路径(图片来自《奔跑吧,Linux内核!》,如下:

每个内存节点通过一个pg_data_t数据结构来描述物理内存的布局。kswapd传递的参数就是pg_data_t数据结构。
二、kswapd内存回收
2.1 内存水位标记 watermark)
在分配路径上,如果低水位(ALLOC_WMARK_LOW)的情况下无法成功分配内存,那么会通过wakeup_kswaped()函数唤醒kswapd内核线程来回收页面,以便释放一些内存。
2.2 kswapd唤醒路径
alloc_page --> __alloc_pages_nodemask() --> __alloc_pages_slowpath() --> wake_all_kswapds() --> wakeup_kswapd()
在kswapd的分配路径上的唤醒函数wakeup_kswapd()把kswapd_max_order和classzone_idx作为参数传递给kswapd内核线程。在分配路径上,如果低水位(ALLOC_WMARK_LOW)的情况下无法成功分配内存,那么会通过wakeup_kswaped()函数唤醒kswapd内核线程来回收页面,以便释放一些内存。
linux_mainline-5.17.0/mm/vmscan.c
4533 /*
4534 * A zone is low on free memory or too fragmented for high-order memory. If
4535 * kswapd should reclaim (direct reclaim is deferred), wake it up for the zone's
4536 * pgdat. It will wake up kcompactd after reclaiming memory. If kswapd reclaim
4537 * has failed or is not needed, still wake up kcompactd if only compaction is
4538 * needed.
4539 */
4540 void wakeup_kswapd(struct zone *zone, gfp_t gfp_flags, int order,
4541 enum zone_type highest_zoneidx)
4542
4543 pg_data_t *pgdat;
4544 enum zone_type curr_idx;
4545
4546 if (!managed_zone(zone))
4547 return;
4548
4549 if (!cpuset_zone_allowed(zone, gfp_flags))
4550 return;
4551
4552 pgdat = zone->zone_pgdat;
4553 curr_idx = READ_ONCE(pgdat->kswapd_highest_zoneidx);
4554
4555 if (curr_idx == MAX_NR_ZONES || curr_idx < highest_zoneidx)
4556 WRITE_ONCE(pgdat->kswapd_highest_zoneidx, highest_zoneidx);
4557
4558 if (READ_ONCE(pgdat->kswapd_order) < order)
4559 WRITE_ONCE(pgdat->kswapd_order, order);
4560
4561 if (!waitqueue_active(&pgdat->kswapd_wait))
4562 return;
4563
4564 /* Hopeless node, leave it to direct reclaim if possible */
4565 if (pgdat->kswapd_failures >= MAX_RECLAIM_RETRIES ||
4566 (pgdat_balanced(pgdat, order, highest_zoneidx) &&
4567 !pgdat_watermark_boosted(pgdat, highest_zoneidx)))
4568 /*
4569 * There may be plenty of free memory available, but it's too
4570 * fragmented for high-order allocations. Wake up kcompactd
4571 * and rely on compaction_suitable() to determine if it's
4572 * needed. If it fails, it will defer subsequent attempts to
4573 * ratelimit its work.
4574 */
4575 if (!(gfp_flags & __GFP_DIRECT_RECLAIM))
4576 wakeup_kcompactd(pgdat, order, highest_zoneidx);
4577 return;
4578
4579
4580 trace_mm_vmscan_wakeup_kswapd(pgdat->node_id, highest_zoneidx, order,
4581 gfp_flags);
4582 wake_up_interruptible(&pgdat->kswapd_wait);
4583 在系统中可以从/proc/zoneinfo文件中查看当前系统的相关的信息和使用情况。
2.3 /proc/zoneinfo
我们可以通过“cat /proc/zoninfo”来查看每个Node中不同zone区域的统计信息,如下:
bill@bill-VirtualBox:~$ cat /proc/zoneinfo
Node 0, zone DMA
per-node stats
nr_inactive_anon 4694
nr_active_anon 114895
nr_inactive_file 141277
nr_active_file 66066
nr_unevictable 0
nr_slab_reclaimable 11617
nr_slab_unreclaimable 10038
nr_isolated_anon 0
nr_isolated_file 0
workingset_nodes 0
workingset_refault 0
workingset_activate 0
workingset_restore 0
workingset_nodereclaim 0
nr_anon_pages 115306
nr_mapped 60868
nr_file_pages 211629
nr_dirty 234
nr_writeback 0
nr_writeback_temp 0
nr_shmem 4915
nr_shmem_hugepages 0
nr_shmem_pmdmapped 0
nr_file_hugepages 0
nr_file_pmdmapped 0
nr_anon_transparent_hugepages 0
nr_unstable 0
nr_vmscan_write 0
nr_vmscan_immediate_reclaim 0
nr_dirtied 18242
nr_written 4311
nr_kernel_misc_reclaimable 0
pages free 3977
min 67
low 83
high 99
spanned 4095
present 3998
managed 3977
protection: (0, 3426, 3867, 3867, 3867)
nr_free_pages 3977
nr_zone_inactive_anon 0
nr_zone_active_anon 0
nr_zone_inactive_file 0
nr_zone_active_file 0
nr_zone_unevictable 0
nr_zone_write_pending 0
nr_mlock 0
nr_page_table_pages 0
nr_kernel_stack 0
nr_bounce 0
nr_zspages 0
nr_free_cma 0
numa_hit 0
numa_miss 0
numa_foreign 0
numa_interleave 0
numa_local 0
numa_other 0
pagesets
cpu: 0
count: 0
high: 0
batch: 1
vm stats threshold: 2
node_unreclaimable: 0
start_pfn: 1
Node 0, zone DMA32
pages free 634266
min 14908
low 18635
high 22362
spanned 1044480
present 913392
managed 889680
protection: (0, 0, 441, 441, 441)
nr_free_pages 634266
nr_zone_inactive_anon 4660
nr_zone_active_anon 100019
nr_zone_inactive_file 100862
nr_zone_active_file 35798
nr_zone_unevictable 0
nr_zone_write_pending 74
nr_mlock 0
nr_page_table_pages 5231
nr_kernel_stack 4208
nr_bounce 0
nr_zspages 0
nr_free_cma 0
numa_hit 468245
numa_miss 0
numa_foreign 0
numa_interleave 0
numa_local 468245
numa_other 0
pagesets
cpu: 0
count: 70
high: 378
batch: 63
vm stats threshold: 12
node_unreclaimable: 0
start_pfn: 4096
Node 0, zone Normal
pages free 2372
min 1919
low 2398
high 2877
spanned 131072
present 131072
managed 112936
protection: (0, 0, 0, 0, 0)
nr_free_pages 2372
nr_zone_inactive_anon 34
nr_zone_active_anon 14876
nr_zone_inactive_file 40415
nr_zone_active_file 30268
nr_zone_unevictable 0
nr_zone_write_pending 160
nr_mlock 0
nr_page_table_pages 1176
nr_kernel_stack 2192
nr_bounce 0
nr_zspages 0
nr_free_cma 0
numa_hit 252639
numa_miss 0
numa_foreign 0
numa_interleave 32495
numa_local 252639
numa_other 0
pagesets
cpu: 0
count: 49
high: 186
batch: 31
vm stats threshold: 6
node_unreclaimable: 0
start_pfn: 1048576
Node 0, zone Movable
pages free 0
min 0
low 0
high 0
spanned 0
present 0
managed 0
protection: (0, 0, 0, 0, 0)
Node 0, zone Device
pages free 0
min 0
low 0
high 0
spanned 0
present 0
managed 0
protection: (0, 0, 0, 0, 0)
以normal为例进行解读,如下:
Node 0, zone Normal
pages free 2372
min 1919
low 2398
high 2877
spanned 131072 ==> spanned_pages
present 131072 ==> present_pages
managed 112936 ==> managed_pages
protection: (0, 0, 0, 0, 0)
......page_low: 当空闲页面的数量达到page_low所标定的数量的时候,kswapd线程将被唤醒,并开始释放回收页面。这个值默认是page_min的2倍。
page_min: 当空闲页面的数量达到page_min所标定的数量的时候, 分配页面的动作和kswapd线程同步运行
page_high: 当空闲页面的数量达到page_high所标定的数量的时候, kswapd线程将重新休眠,通常这个数值是page_min的3倍
spanned_pages: 代表的是这个zone中所有的页,包含空洞,计算公式是: zone_end_pfn - zone_start_pfn
present_pages: 代表的是这个zone中可用的所有物理页,计算公式是:spanned_pages-hole_pages
managed_pages: 代表的是通过buddy管理的所有可用的页,计算公式是:present_pages - reserved_pages,三者的关系是spanned_pages > present_pages > managed_pages
如上Normal zone有三个水位:min, low和high(单位为page大小),标志着当前zone中内存分配压力。当系统中可用内存紧张时,内核kswapd将会被被唤醒,并依据对应水位执行相应的回收操作。
kswapd和这3个参数的互动关系如下图:
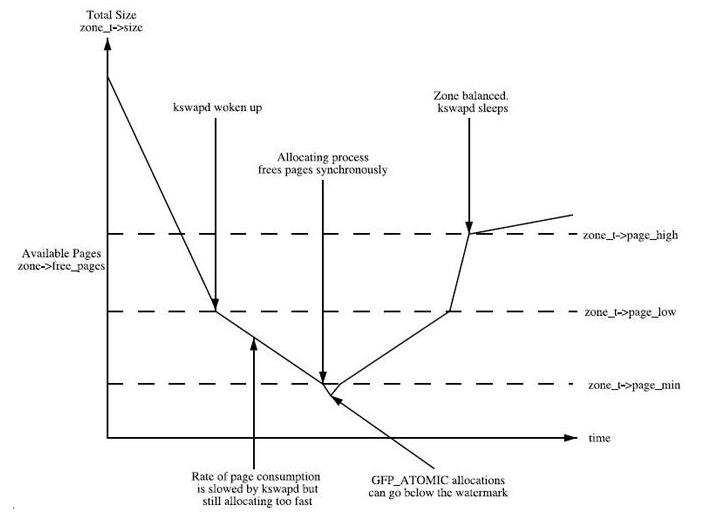
总结下来就是,当系统剩余内存低于watermark[low]的时候,内核的kswapd开始起作用,进行内存回收。直到剩余内存达到watermark[high]的时候停止。如果内存消耗导致剩余内存达到了或超过了watermark[min]时,就会触发直接回收(direct reclaim)。
三、/proc/sys/vm/swappiness
/proc/sys/vm/swappiness的值如下,

linux_mainline-5.17.0/Documentation/admin-guide/sysctl/vm.rst swappiness ========== This control is used to define the rough relative IO cost of swapping and filesystem paging, as a value between 0 and 200. At 100, the VM assumes equal IO cost and will thus apply memory pressure to the page cache and swap-backed pages equally; lower values signify more expensive swap IO, higher values indicates cheaper. Keep in mind that filesystem IO patterns under memory pressure tend to be more efficient than swap's random IO. An optimal value will require experimentation and will also be workload-dependent. The default value is 60. For in-memory swap, like zram or zswap, as well as hybrid setups that have swap on faster devices than the filesystem, values beyond 100 can be considered. For example, if the random IO against the swap device is on average 2x faster than IO from the filesystem, swappiness should be 133 (x + 2x = 200, 2x = 133.33). At 0, the kernel will not initiate swap until the amount of free and file-backed pages is less than the high watermark in a zone.
这个值范围定义在0~200。如果这个值设置为100表示内存发生回收时,从swap交换内存和从cache回收内存的优先级一样。
如果值为0,则kernel不会初始化swap,直到当前的剩余内存和文件映射内存的总和低于high的水位值。
最后
我的理解总结下来就是,当系统剩余内存低于watermark[low]的时候会触发kswapd,kswapd会根据swappiness的值来确认是否优先进行内存页的换出。需要注意的是,zoneinfo中,不同的zone有不同的水位值,我们在从meminfo计算剩余内存的时候,free的值是总的剩余内存,需要减去其他zone的剩余内存后再和当前对应zone的水位进行比较,以确认是否会触发kswapd进行页换出。
以上是关于Linux内存从0到1学习笔记(九,内存优化调试之一 - kswapd0)的主要内容,如果未能解决你的问题,请参考以下文章