网络编程 ———— UDP首部格式
Posted 爱敲代码的三毛
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了网络编程 ———— UDP首部格式相关的知识,希望对你有一定的参考价值。
接上一篇博客 Java Socket(UDP/TCP 套接字)
文章目录
UDP的特点
UDP传输的过程类似于寄信,UDP是无连接面向数据报的,即使在传输过程中出现丢包,UDP也不负责重发,UDP是不会关注对端是否真的收到了传过去的数据,就算出现包的到达顺序出错也没不会纠正。
1. 无连接
- 知道对端的IP和端口号就直接进行传输,不需要建立连接,socket创建好之后,就可以立即尝试读写数据了
2. 不可靠
- 不可靠就体现在无连接上,不建立连接就能直接通信,想发就发
- 没有任何的安全机制,发送端发送数据以后,如果因为网络故障该段无法发送给对方,UDP协议层也不会给应用层返回任何错误信息
- 也就是发送方不会关心接收方是否已经接收到了数据
- 这里需要注意一点,并不是所有UDP协议的应用层都是不可靠的,应用层序可以自己实现可靠的数据传输,通过增加 确认应答和重传机制,所以使用UDP协议最大的特点就是速度快。
3.面向数据报
- 应用层交给UDP多长的报文,UDP原样发送,既不拆分,也不会合并。但是因为报文最大是 64KB,所以在使用UDP来传输数据的时候,一定要注意报文的大小
- 如果发送端一次发送100个字节,那么接收端也必须一次接收100个字节,而不能循环接收10次,每次接收10个字节
4.全双工
- UDP的socket既能读,也能写,这就是全双工
UDP首部格式
去除掉下图的数据的部分就是真正的UDP首部格式
UDP首部格式由 源端口号、目的端口号、UDP长度和校验和组成
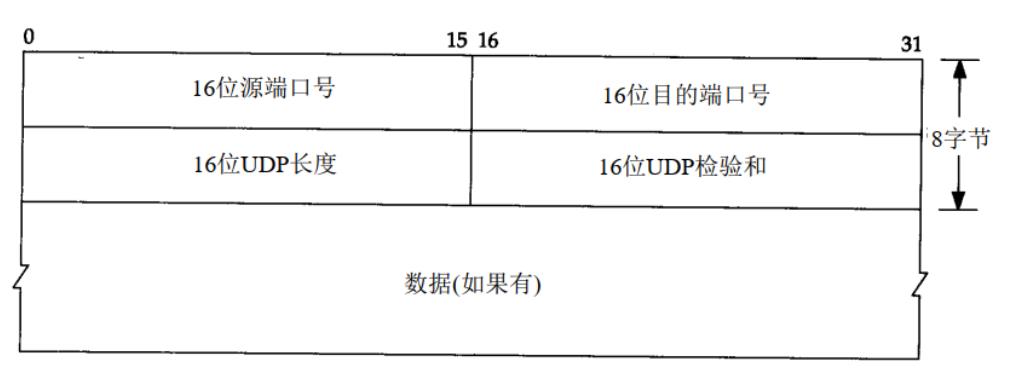
源端口号 (Source Port)
表示发送端端口号,字段长16位(两个字节)
目标端口号
表示接收端端口,字段长16位(两个字节)
包长度(UDP长度)
- 该字段保存了UDP首部的长度和数据长度之和,单位为字节
- 整个UDP数据报的长度 ,报头+载荷,使用两个字节的数据来表示,因为1字节,所以2个字能表示的数据范围0~65535个字节,一个UDP数据报,最大就是64KB
缓冲区
- UDP没有真正意义上的 发送缓冲区,发送的数据会直接交给内核,由内核将数据传给网络层协议进行后续的传输操作
- UDP具有接收缓冲区,但是这个接收缓冲区不能保证收到的UDP数据报的顺序和发送UDP数据报的顺序一致
- 如果缓冲区满了,再到达的UDP数据报就会被丢弃
校验和
- 网络上传输数据的时候,是可能出现一些问题的,网络上的数据本质都是一些 0/1 bit 流,这些bit流是通过光信号或者电信号来表示的
- 如果传输过程中,收到了一些干扰,就容易出现“比特翻转”情况~(0->1,1->0)
- 校验和,其实就是为了验证,看当前的数据是否出现问题了
- 校验和也不一定100%的就能进行校验,如果校验和正确,也不能保证数据一定对,但是如果校验和不正确,就能说明数据一定是错的
实际使用的校验和的算法有很多,其中比较常见的有crc和md5
CRC (循环冗余校验)
假设现在有一串数据,把它当成二进制数据,依次按照字节为单位,取出数据,然后把这些数据进行累加
short sum;
for (byte b : array)
sum += b;
//加着加着可能就溢出了,溢出的部分不要了
- 传输数据的时候,就把 数据+crc 校验和一起传输给目标
- 接收方同时接收到了 数据+crc校验和
- 接收方就需要验证一下,看看当前的数据是否是对的 (在网络传输中可能会存在bit翻转的情况)
- 接受方就按照同样的算法,再针对数据部分,计算一遍 crc 校验和,把把这个新计算的结果收到的crc校验和,进行对比,看看结果是不是一致
- 这个操作本质上,就是发送之前,算一遍 crc ,接收之后也算一遍crc
- 如果这个数据发送之前,和接收后数据内容不变,得到的crc也将是一样的
- 如果传输过程中出现了比特翻转,接收的内容和发送的内容就不一样了,此时算出来的两份 crc 也就是大概率不相同的(其实也有一定概率相同,两个不同的数据,算出的crc结果一致,这个概率整体来说还是比较小的)
md5
md5也是一种算法,md5应用的场景非常多,用来作为校验和,只是其中的一个 场景而已,本质上是一个“”非对称的哈希算法”
md5算法本质上就是针对数据进行一系列的数学变化
- 定长:无论输入的字符串是多长,得到的md5值都是固定长度 32位(4个字节)、64位(8个字节)、128位(16个字节)
- 分散:只要输入的字符串,哪怕只是变化了一点点,得到的md5值都会差别巨大(这也是哈希算法的核心)
- 不可逆:给定原串,很容易得到md5,但是给定md5值,理论上是无法恢复出原始的字符串的
因此很对地方都可以使用md5
- 作为hash算法
- 作为校验和
因为md5的第二个特性,就是比较分散,数据变了一点,此时得到的md5值都差别很大,如果两个字符串,md5值一致,这种概率是非常非常低的,比src要低很多,工程上就忽略不计了
下一篇《TCP首部格式》
以上是关于网络编程 ———— UDP首部格式的主要内容,如果未能解决你的问题,请参考以下文章