Java 线程池的实现原理,你真的理解吗?
Posted Java知音_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java 线程池的实现原理,你真的理解吗?相关的知识,希望对你有一定的参考价值。
点击关注公众号,实用技术文章及时了解
来源:guobinhit.blog.csdn.net/article/
details/105654919
1 线程状态
既然要说线程,我们就先来了解一下线程的几种状态:
public enum State
NEW,
RUNNABLE,
BLOCKED,
WAITING,
TIMED_WAITING,
TERMINATED;
如上述代码所示,其来自于java.lang.Thread类,State为Thread类的内部公共枚举类,表示线程的 6 种状态。
NEW,新建状态。尚未启动的线程的状态。
RUNNABLE,可运行状态。处于
RUNNABLE状态的线程正在 JVM 中执行,但它可能正在等待来自操作系统(如处理器)的其他资源。BLOCKED,阻塞状态。处于
BLOCKED状态的线程正在等待监视器锁以便进入同步代码块或同步方法,或者在调用Object.wait()方法后准备重入同步代码块或同步方法。WAITING,等待状态。处于
WAITING状态的线程正在等待另一个线程执行特定的动作,例如需要另一个线程调用Object.notify()或者Object.notifyAll()进行唤醒。当调用以下无参方法时,线程会进入WAITING状态:Object.wait()Thread.join()LockSupport.park()
TIMED_WAITING,具有指定等待时间的线程状态。当调用以下具有指定正等待时间的方法时,线程会进入
TIMED_WAITING状态:Thread.sleep(millis)Object.wait(timeout)Thread.join(millis)LockSupport.parkNanos(blocker, nanos)LockSupport.parkUntil(blocker, deadline)
TERMINATED,终止状态。当线程执行完成后,处于
TERMINATED状态。
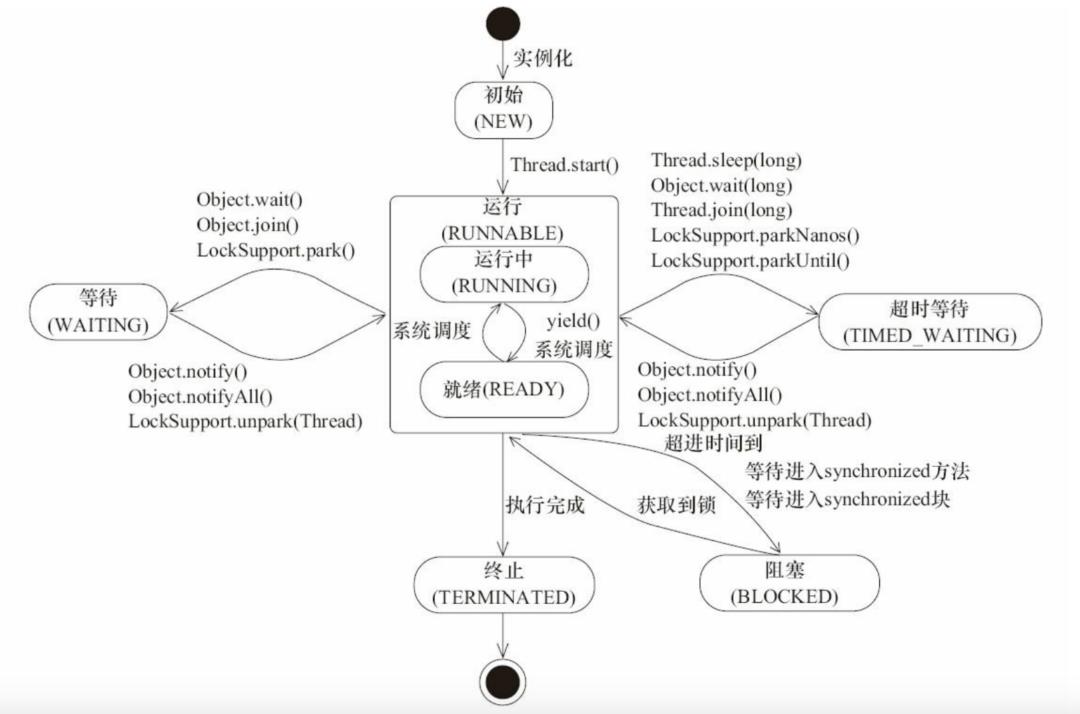
如上图所示,展示了线程在各种状态之间流转的详细图谱。
2 线程池
2.1 线程池的作用
我们知道,线程的创建是一项比较消耗资源的操作,如果我们频繁的创建线程,不仅会大量消耗内存资源,也会导致 CPU 的使用率飙高,因为线程的切换也会导致 CPU 的状态切换。那么,既然创建线程这么消耗资源,又该如何解决这个问题?
线程池就是为了解决这个问题而设计的,通过使用线程池,可以达到以下效果:
降低资源消耗:通过重用线程来降低线程创建和销毁的资源消耗。
提高响应速度:任务到达时不需要等待线程创建就可以立即执行。
提高线程的可管理性:线程池可以统一管理、分配、调优和监控。
2.2 线程池的实现
在 Java 语言中,线程池是通过ThreadPoolExecutor实现的,其全参构造器为:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
if (corePoolSize < 0 ||
maximumPoolSize <= 0 ||
maximumPoolSize < corePoolSize ||
keepAliveTime < 0)
throw new IllegalArgumentException();
if (workQueue == null || threadFactory == null || handler == null)
throw new NullPointerException();
this.corePoolSize = corePoolSize;
this.maximumPoolSize = maximumPoolSize;
this.workQueue = workQueue;
this.keepAliveTime = unit.toNanos(keepAliveTime);
this.threadFactory = threadFactory;
this.handler = handler;
其中,各参数的含义分别为:
corePoolSize,核心线程数,表示要保留在线程池中的线程数,即使它们处于空闲状态,如果设置了
allowCoreThreadTimeOut参数,则该参数的最小值可以为零。maximumPoolSize,最大线程数,表示线程池中允许同时存在的最大线程数量。
keepAliveTime,存活时间,当线程池中的线程数量大于
corePoolSize时,该参数表示多余的空闲线程在终止之前等待新任务的最长时间。也就是说,如果多余的空闲线程在等待时间超过keepAliveTime之后仍没有收到任务,则自动销毁。unit,时间单位,表示
keepAliveTime参数的时间单位。workQueue,工作队列,在任务被执行前,该队列用于保存任务。该队列只能持有被execute方法提交的Runnable类型的任务。
threadFactory,线程工厂,执行器创建新线程时使用的工厂。
handler,拒绝策略,当达到线程数量边界和队列容量而阻止执行时使用的处理策略。
特别地,在ThreadPoolExecutor中,重载了很多构造器,用于满足我们不同的使用需求。其中,参数最少的重载构造器是:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue)
this(corePoolSize, maximumPoolSize, keepAliveTime, unit, workQueue,
Executors.defaultThreadFactory(), defaultHandler);
由上述代码可知,在创建一个ThreadPoolExecutor的时候,我们至少需要指定corePoolSize、maximumPoolSize、keepAliveTime、unit和workQueue这五个参数,而threadFactory和handler,则是可以使用默认值:
threadFactory,默认使用DefaultThreadFactory线程工厂;
handler,默认使用AbortPolicy拒绝策略。
对于线程工厂,在Executors类内部,还提供了一个PrivilegedThreadFactory工厂类,用于捕获访问控制上下文和类加载器。当然,我们也可以通过实现ThreadFactory接口或继承DefaultThreadFactory类来自定义线程池的工厂类。
对于拒绝策略,在ThreadPoolExecutor类内部,则是提供了四种拒绝策略的实现,分别是:
AbortPolicy,默认策略,直接抛出异常;
DiscardPolicy,直接丢弃任务;
DiscardOldestPolicy,丢弃阻塞队列中靠最前的任务,然后调用execute方法重试;
CallerRunsPolicy,使用调用者所在的线程执行任务。
同理,我们也可以自己实现RejectedExecutionHandler接口来自定义线程池的拒绝策略。说到这里,我们可能会有一个疑问,那就是:什么时候使用拒绝策略呢?当阻塞队列满了并且没有空闲的工作线程时,如果继续提交任务,就会使用拒绝策略来“拒绝”任务了。在这里,我们可以详细的梳理一遍ThreadPoolExecutor的执行过程:
创建
ThreadPoolExecutor线程池执行器,默认并不会立即创建执行线程。接收到一个新任务之后,检查当前执行线程数量是否小于
corePoolSize数量,如果是,则是创建一个新的执行线程,来执行该任务;否则,将该任务放入工作队列。如果工作队列也满了,则判断当前执行线程数量是否小于
maximumPoolSize数量,如果是,则创建一个新的执行线程,来执行该任务;否则,执行拒绝策略。如果当前执行线程的数量大于
corePoolSize并且没有新的任务需要处理,则在等待keepAliveTime时间之后,自动销毁当前执行线程数量 -corePoolSize数量的线程,使执行线程的数量维持在corePoolSize的数量。
2.2.1 线程池内部状态
在ThreadPoolExecutor中,使用以下常量值表示线程的状态:
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0));
private static final int COUNT_BITS = Integer.SIZE - 3;
private static final int CAPACITY = (1 << COUNT_BITS) - 1;
// runState is stored in the high-order bits
private static final int RUNNING = -1 << COUNT_BITS;
private static final int SHUTDOWN = 0 << COUNT_BITS;
private static final int STOP = 1 << COUNT_BITS;
private static final int TIDYING = 2 << COUNT_BITS;
private static final int TERMINATED = 3 << COUNT_BITS;
// Packing and unpacking ctl
private static int runStateOf(int c) return c & ~CAPACITY;
private static int workerCountOf(int c) return c & CAPACITY;
private static int ctlOf(int rs, int wc) return rs | wc; 其中,AtomicInteger类型的变量ctl功能非常强大:使用低 29 位表示线程池中的线程数量,使用高 3 位表示线程池的运行状态:
RUNNING:-1 << COUNT_BITS,即高3位为111,该状态的线程池会接收新任务,并处理阻塞队列中的任务;SHUTDOWN:0 << COUNT_BITS,即高3位为000,该状态的线程池不会接收新任务,但会处理阻塞队列中的任务;STOP :1 << COUNT_BITS,即高3位为001,该状态的线程不会接收新任务,也不会处理阻塞队列中的任务,而且会中断正在运行的任务;TIDYING :2 << COUNT_BITS,即高3位为010;TERMINATED:3 << COUNT_BITS,即高3位为011;
在ThreadPoolExecutor创建完成后,我们需要调用execute方法…
推荐
PS:因为公众号平台更改了推送规则,如果不想错过内容,记得读完点一下“在看”,加个“星标”,这样每次新文章推送才会第一时间出现在你的订阅列表里。点“在看”支持我们吧!
以上是关于Java 线程池的实现原理,你真的理解吗?的主要内容,如果未能解决你的问题,请参考以下文章