英雄联盟Python爬虫
Posted Harris-H
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了英雄联盟Python爬虫相关的知识,希望对你有一定的参考价值。
文章目录
英雄联盟Python爬虫
英雄主界面qq https://lol.qq.com/data/info-heros.shtml
1.英雄爬取
https://lol.qq.com/data/info-heros.shtml
get方法获取指定英雄信息。
https://lol.qq.com/data/info-heros.shtml?id=xxx
id=xxx
2.JS获取所有英雄信息
import json
import requests
from faker import Factory
from bs4 import BeautifulSoup
f = Factory.create()
def get_all_heros():
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
headers =
'user-agent': f.user_agent()
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
c = r.text
l = json.loads(c)['hero']
for i in l[:50]:
print("ID: 0 姓名:1 别名:2".format(i['heroId'], i['name'], i['alias']))
if __name__ == '__main__':
get_all_heros()
效果:

3.爬取比赛数据
第一个LOL网页爬取
http://www.wanplus.com/lol/playerstats
用到了csrf-token,post请求需要携带set-cookies 中的csrf-token即可。
import json
import time
import requests
from faker import Factory
from urllib import parse
f = Factory.create()
def get_token():
url = 'http://www.wanplus.com/lol/playerstats'
headers =
'user-agent': f.user_agent(),
'Referer': 'http://www.wanplus.com/lol/teamstats',
'Host': 'www.wanplus.com',
r = requests.get(url, headers=headers, allow_redirects=False)
r.encoding = r.apparent_encoding
c = r.cookies
r.close()
myCookies = c.get_dict()
# print(myCookies)
return str(int(c.get('wanplus_csrf')[9:]) + int(16777216)), myCookies
def get_competition():
url = 'http://www.wanplus.com/ajax/stats/list'
token, myCookies = get_token()
headers =
'user-agent': f.user_agent(),
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Host': 'www.wanplus.com',
'Origin': 'http://www.wanplus.com',
'Referer': 'http://www.wanplus.com/lol/playerstats',
'X-CSRF-Token': token,
'X-Requested-With': 'XMLHttpRequest',
formdata =
'_gtk': token,
'draw': '1',
'columns[0][data]': 'order',
'columns[0][name]': '',
'columns[0][searchable]': 'true',
'columns[0][orderable]': 'false',
'columns[0][search][value]': '',
'columns[0][search][regex]': 'false',
'columns[1][data]': 'playername',
'columns[1][name]': '',
'columns[1][searchable]': 'true',
'columns[1][orderable]': 'false',
'columns[1][search][value]': '',
'columns[1][search][regex]': 'false',
'columns[2][data]': 'teamname',
'columns[2][name]': '',
'columns[2][searchable]': 'true',
'columns[2][orderable]': 'false',
'columns[2][search][value]': '',
'columns[2][search][regex]': 'false',
'columns[3][data]': 'meta',
'columns[3][name]': '',
'columns[3][searchable]': 'true',
'columns[3][orderable]': 'false',
'columns[3][search][value]': '',
'columns[3][search][regex]': 'false',
'columns[4][data]': 'appearedTimes',
'columns[4][name]': '',
'columns[4][searchable]': 'true',
'columns[4][orderable]': 'true',
'columns[4][search][value]': '',
'columns[4][search][regex]': 'false',
'columns[5][data]': 'kda',
'columns[5][name]': '',
'columns[5][searchable]': 'true',
'columns[5][orderable]': 'true',
'columns[5][search][value]': '',
'columns[5][search][regex]': 'false',
'columns[6][data]': 'attendrate',
'columns[6][name]': '',
'columns[6][searchable]': 'true',
'columns[6][orderable]': 'true',
'columns[6][search][value]': '',
'columns[6][search][regex]': 'false',
'columns[7][data]': 'killsPergame',
'columns[7][name]': '',
'columns[7][searchable]': 'true',
'columns[7][orderable]': 'true',
'columns[7][search][value]': '',
'columns[7][search][regex]': 'false',
'columns[8][data]': 'mostkills',
'columns[8][name]': '',
'columns[8][searchable]': 'true',
'columns[8][orderable]': 'true',
'columns[8][search][value]': '',
'columns[8][search][regex]': 'false',
'columns[9][data]': 'deathsPergame',
'columns[9][name]': '',
'columns[9][searchable]': 'true',
'columns[9][orderable]': 'true',
'columns[9][search][value]': '',
'columns[9][search][regex]': 'false',
'columns[10][data]': 'mostdeaths',
'columns[10][name]': '',
'columns[10][searchable]': 'true',
'columns[10][orderable]': 'true',
'columns[10][search][value]': '',
'columns[10][search][regex]': 'false',
'columns[11][data]': 'assistsPergame',
'columns[11][name]': '',
'columns[11][searchable]': 'true',
'columns[11][orderable]': 'true',
'columns[11][search][value]': '',
'columns[11][search][regex]': 'false',
'columns[12][data]': 'mostassists',
'columns[12][name]': '',
'columns[12][searchable]': 'true',
'columns[12][orderable]': 'true',
'columns[12][search][value]': '',
'columns[12][search][regex]': 'false',
'columns[13][data]': 'goldsPermin',
'columns[13][name]': '',
'columns[13][searchable]': 'true',
'columns[13][orderable]': 'true',
'columns[13][search][value]': '',
'columns[13][search][regex]': 'false',
'columns[14][data]': 'lasthitPermin',
'columns[14][name]': '',
'columns[14][searchable]': 'true',
'columns[14][orderable]': 'true',
'columns[14][search][value]': '',
'columns[14][search][regex]': 'false',
'columns[15][data]': 'damagetoheroPermin',
'columns[15][name]': '',
'columns[15][searchable]': 'true',
'columns[15][orderable]': 'true',
'columns[15][search][value]': '',
'columns[15][search][regex]': 'false',
'columns[16][data]': 'damagetoheroPercent',
'columns[16][name]': '',
'columns[16][searchable]': 'true',
'columns[16][orderable]': 'true',
'columns[16][search][value]': '',
'columns[16][search][regex]': 'false',
'columns[17][data]': 'damagetakenPermin',
'columns[17][name]': '',
'columns[17][searchable]': 'true',
'columns[17][orderable]': 'true',
'columns[17][search][value]': '',
'columns[17][search][regex]': 'false',
'columns[18][data]': 'damagetakenPercent',
'columns[18][name]': '',
'columns[18][searchable]': 'true',
'columns[18][orderable]': 'true',
'columns[18][search][value]': '',
'columns[18][search][regex]': 'false',
'columns[19][data]': 'wardsplacedPermin',
'columns[19][name]': '',
'columns[19][searchable]': 'true',
'columns[19][orderable]': 'true',
'columns[19][search][value]': '',
'columns[19][search][regex]': 'false',
'columns[20][data]': 'wardskilledPermin',
'columns[20][name]': '',
'columns[20][searchable]': 'true',
'columns[20][orderable]': 'true',
'columns[20][search][value]': '',
'columns[20][search][regex]': 'false',
'order[0][column]': '4',
'order[0][dir]': 'desc',
'start': '0',
'length': '20',
'search[value]': '',
'search[regex]': 'false',
'area': '',
'eid': '1065',
'type': 'player',
'gametype': '2',
'filter': '"team":,"player":,"meta":',
# 字典转换为 k1 = v1 & k2 = v2
data = parse.urlencode(formdata)
# print(data)
r = requests.post(url, cookies=myCookies, data=data, headers=headers, allow_redirects=False)
r.encoding = r.apparent_encoding
c = r.text
# print("11111内容如下:----------------------------------------")
if len(c) < 100:
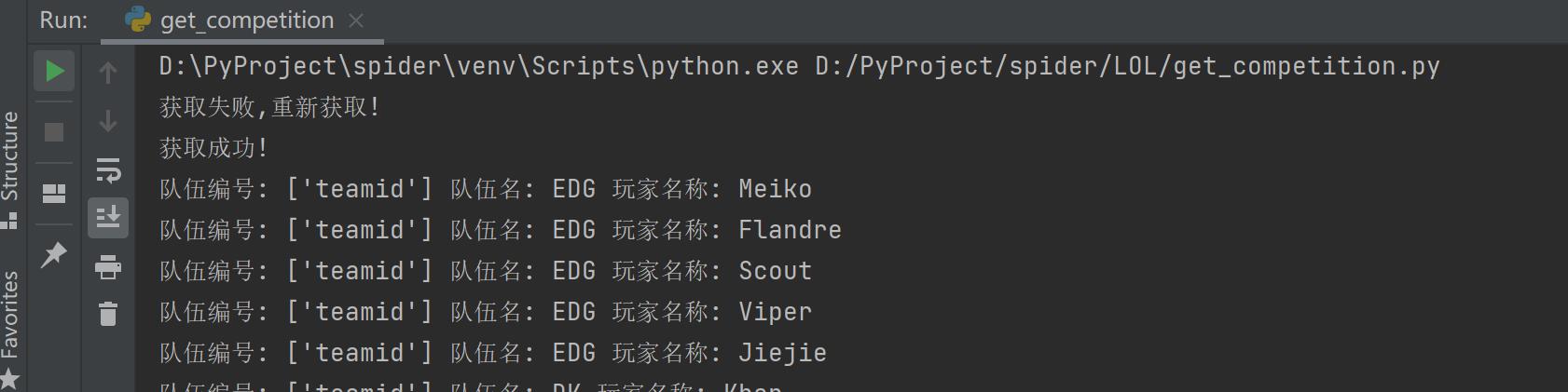
print('获取失败,重新获取!')
return False
print('获取成功!')
l = json.loads(c)['data']
for i in l[:20]:
print('队伍编号: 0 队伍名: 1 玩家名称: 2'.format(['teamid'], i['teamname'], i['playername']))
return True
def cookie_to_dic(mycookie):
dic =
for i in mycookie.split('; '):
dic[i.split('=')[0]] = i.split('=')[1]
return dic
if __name__ == '__main__':
while 1:
ok = get_competition()
if ok is True:
break
# test()
第二个LOL网页数据爬取
http://lol.admin.pentaq.com/
没有任何反爬和csrf-token认证:
from faker import Factory
import requests
import json
f = Factory.create()
def fun():
url = 'http://lol.admin.pentaq.com/api/tournament_team_data?tour=29&patch='
headers =
'user-agent': f.user_agent()
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
c = r.text
r.close()
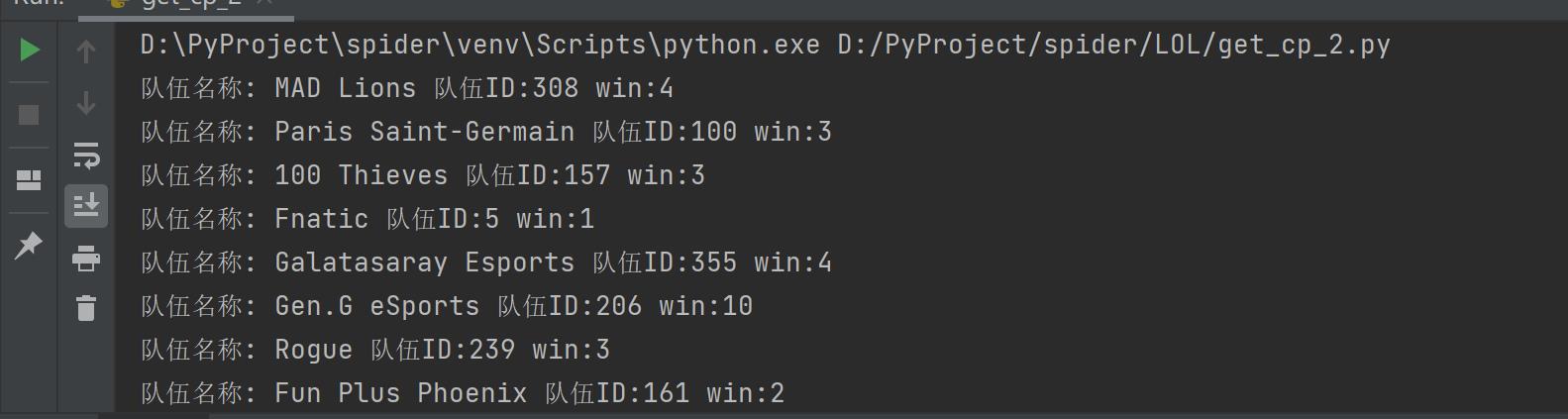
l = json.loads(c)['data']['teams_data']
for i in l[:20]:
print("队伍名称: 0 队伍ID:1 win:2".format(i['team_full_name'], i['team_id'], i['win']))
if __name__ == '__main__':
fun()
第三个LOL网页数据爬取
http://www.op.gg/champion/statistics
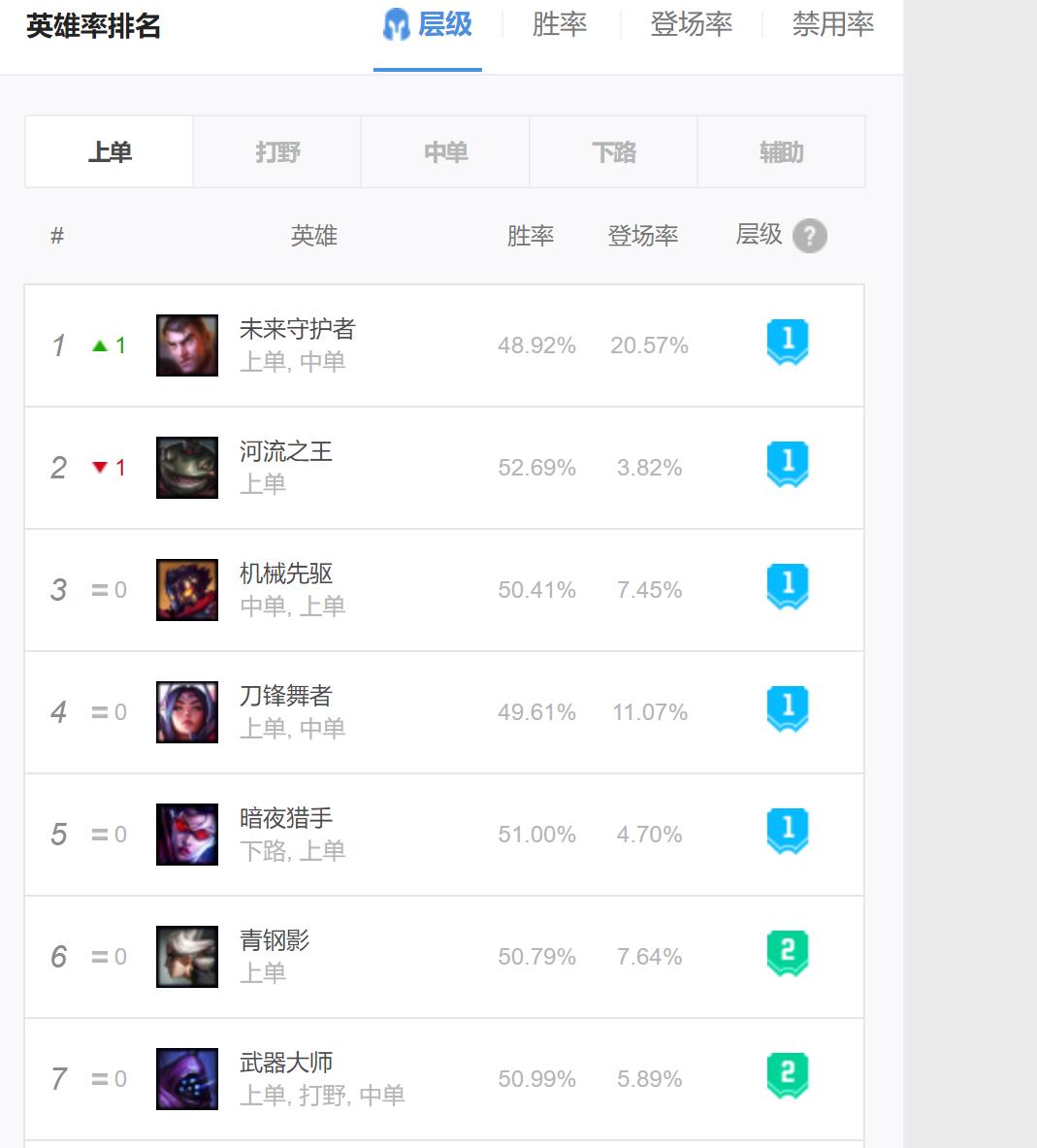
采用BeautifulSoup 即可。
from faker import Factory
import requests
from bs4 import BeautifulSoup
f = Factory.create()
def fun():
url = 'http://www.op.gg/champion/statistics'
headers =
'user-agent': f.user_agent(),
'Accept-Language': "zh-CN,zh;q=0.9,en;q=0.8'"
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
if r.status_code != 200:
return False
c = r.text
r.close()
# print(c)
if len(c) < 10000:
return False
html = BeautifulSoup(c, 'html.parser')
l = html.find('tbody', class_='tabItem champion-trend-tier-TOP').find_all('tr')
for x in l[:5]:
a = x.find_all('td')
tmp = a[3]
b = tmp.find_all('div')
name = b[0].text
pos = b[1].text.replace('\\t','').replace('\\n','')
print('rank: 0 name: 1 pos:2 胜率:3 登场率:4'.format(a[0].text, name, pos, a[4].text, a[5].text))
return True
# for c in l[:20]:
# a = c.find_all('td')
# tmp = a[3]
# b = tmp.find_all('div')
# name = b[0].text
# pos = b[1].text
# print('rank: 0] name: 1 pos:2 胜率:3 登场率:4'.format(a[0].text,name,pos,a[4].text,a[5].text))
if __name__ == '__main__':
while True:
ok = fun()
if ok:
break
4.多线程爬取LOL英雄皮肤图片
1.获取对应英雄url 列表,函数get_url_list()
2.下载对应的图片保存到文件夹download()
3.main()开启多线程执行爬取任务
import requests
import json
import os
from faker import Factory
from multiprocessing.dummy import Pool as ThreadPool
import time
f = Factory.create()
headers =
'user-agent': f.user_agent()
def get_url_list():
url = 'https://game.gtimg.cn/images/lol/act/img/js/heroList/hero_list.js'
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
c = r.text
Heros = json.loads(c)["hero"] # 156个hero信息
idList = []
for hero in Heros:
hero_id = hero["heroId"]
idList.append(hero_id)
# print(idList)
def spider(url):
r = requests.get(url, headers=headers)
r.encoding = r.apparent_encoding
c = r.text
r.close()
res_dict = json.loads(c)
skins = res_dict["skins"] # 15个hero信息
for index, hero in enumerate(skins): # 这里使用到enumerate获取下标,以便文件图片命名;
item = # 字典对象
item['name'] = hero["heroName"]
item['skin_name'] = hero["name"]
if hero["mainImg"] == '':
continue
item['imgLink'] = hero["mainImg"]
# print(item)
download(index + 1, item)
def download(index, contdict):
name = contdict['name']
path = "皮肤/" + name
if not os.path.exists(path):
os.makedirs(path)
content = requests.get(contdict['imgLink'