自制编译器---c++实现词法分析器
Posted yqtaowhu
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自制编译器---c++实现词法分析器相关的知识,希望对你有一定的参考价值。
一直想写一个编译器,在csdn上看到tyler_download网友用Java写的编译器,自己也有所启发,非常感谢他的分享,但是,感觉他的词法分析函数的调用过多,感觉很是不习惯,同时还很复杂,自己是学c/c++的,因此想用c++编写一个编译器。
在这个过程中,其中对我帮助最大的是一个外国的网友,虽然不知道他的名字,但是还是要感谢他。。。。
词法单元词法解析器在编译器中的作用,是将输入流解析为一种能够被语法解析器使用和管理的格式。他将输入文本分割,打标签,也就是用一些数值来指代一系列相应的字符串。
例如:
int a,b,c;
a=34;
b=56;
int c=a*b;经过词法单元会生成如下的形式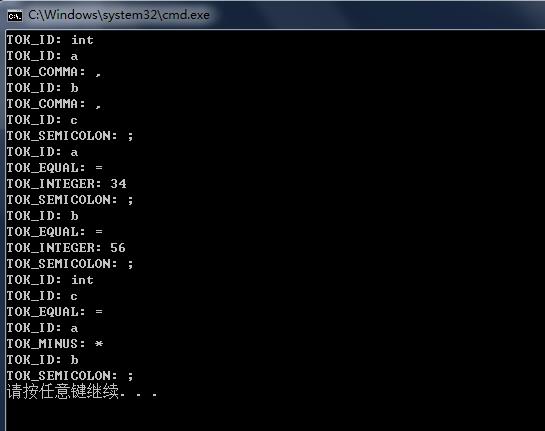
首先定义一组词法单元
#include <iostream>
#include <string>
using namespace std;
#define NTOKEN 1000
//定义词法单元值
enum TokenValue
TOK_COMMA, //逗号
TOK_DIV,
TOK_END,
TOK_EQUAL,
TOK_FOR,
TOK_ID,
TOK_IF,
TOK_INTEGER,
TOK_MINUS,
TOK_MULT,
TOK_PLUS,
TOK_SEMICOLON,
TOK_UNDEFINED,
TOK_WHILE,
;
string TOKEN_VALUE_DESCRIPTION[] =
"TOK_COMMA",
"TOK_DIV",
"TOK_END",
"TOK_EQUAL",
"TOK_FOR",
"TOK_ID",
"TOK_IF",
"TOK_INTEGER",
"TOK_MINUS",
"TOK_MULT",
"TOK_PLUS",
"TOK_SEMICOLON",
"TOK_UNDEFINED",
"TOK_WHILE",
;
//标签和标签的值
typedef struct _Token
int type;
string str;
Token;
然后在主程序中进行单词的分割
#include <stdio.h>
#include <ctype.h>
#include "lexer.h"
Token token[NTOKEN];
//输入参数为路径
int lexer(char *path)
FILE *fin;
int ch;
char buf[256], *p;
int n = 0;
if ((fin = fopen(path, "r")) == NULL)
fprintf(stderr, "Cant' open the file... :(\\n");
while ((ch = fgetc(fin)) != EOF)
if (ch <= ' ') continue; // [\\n\\t ]
p = buf;
switch (ch)
case '+':
token[n].type = TOK_PLUS;
token[n++].str = '+';
break;
case '-':
token[n].type = TOK_MINUS;
token[n++].str = '-';
break;
case '*':
token[n].type = TOK_MINUS;
token[n++].str = '*';
break;
case ';':
token[n].type = TOK_SEMICOLON;
token[n++].str = ';';
break;
case '=':
token[n].type = TOK_EQUAL;
token[n++].str = '=';
break;
case ',':
token[n].type = TOK_COMMA;
token[n++].str = ',';
break;
default:
break;
if (isalpha(ch)) // [A-Za-z][A-Za-z0-9],以字母开头为真
token[n].type = TOK_ID; //是一个标识符
*p++ = ch;
while (isalnum(ch = fgetc(fin))) *p++ = ch; //是否为字母或数字
ungetc(ch, fin);
*p++ = '\\0';
token[n++].str = buf;
if (isdigit(ch)) // [0-9]+
token[n].type = TOK_INTEGER;
*p++ = ch;
while (isdigit(ch = fgetc(fin))) *p++ = ch;
ungetc(ch, fin);
*p++ = '\\0';
token[n++].str = buf;
fclose(fin);
return n;
/*************************************************************************************
CMD下运行的结果。
void main(int argc, char* argv[])
int n;
int nToken = lexer(argv[1]);
for (n = 0; n < nToken; n++)
//printf("%s: %s\\n", TOKEN_VALUE_DESCRIPTION[token[n].type], token[n].str);
cout << TOKEN_VALUE_DESCRIPTION[token[n].type] << ": " << token[n].str << endl;
***************************************************************************************/
//vs上调试结果
void main(int argc, char* argv[])
int n;
char* input = "aa.txt";
int nToken = lexer(input);
for (n = 0; n < nToken; n++)
cout << TOKEN_VALUE_DESCRIPTION[token[n].type] << ": " << token[n].str << endl;
以上是关于自制编译器---c++实现词法分析器的主要内容,如果未能解决你的问题,请参考以下文章