python入门之后须掌握的知识点(模块化编程时间模块)
Posted 汀、
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了python入门之后须掌握的知识点(模块化编程时间模块)相关的知识,希望对你有一定的参考价值。
相关文章:
全网最详细超长python学习笔记、14章节知识点很全面十分详细,快速入门,只用看这一篇你就学会了!
python入门合集:
python快速入门【三】-----For 循环、While 循环
python入门之后须掌握的知识点(excel文件处理+邮件发送+实战:批量化发工资条)【2】
1 模块化
好处:
●提高了代码的可维护性
●避免函数名和变量名冲突
分类:
●内置标准模块(又 称标准库)
●第三方开源模块
●自定义模块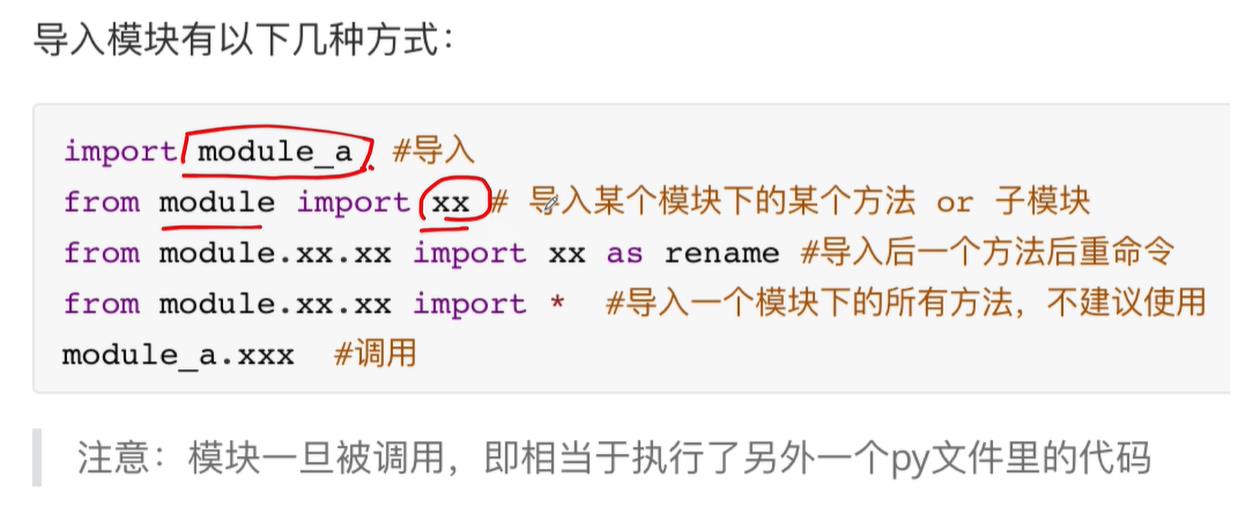
1.1 自定义模块
新建:
def test():
print("调用")
print("调用了")import python1
python1.test()
调用了
调用不同目录下调用:会报错 No module xxx
import sys
print(sys.path)
'e:\\\\360MoveData\\\\Users\\\\小丁\\\\Desktop\\\\test\\\\temp',
'H:\\\\Anaconda3-2020.02\\\\envs\\\\parl2\\\\python38.zip',
'H:\\\\Anaconda3-2020.02\\\\envs\\\\parl2\\\\DLLs',
'H:\\\\Anaconda3-2020.02\\\\envs\\\\parl2\\\\lib',
'H:\\\\Anaconda3-2020.02\\\\envs\\\\parl2',
'H:\\\\Anaconda3-2020.02\\\\envs\\\\parl2\\\\lib\\\\site-packages'可以看到首先是我在解释器parl2,其次是当前文件所在的目录
添加路径:给列表添加指定路径即可【但路径是绝对路径】
import sys
addpath='e:\\\\360MoveData\\\\Users\\\\小丁\\\\Desktop\\\\test'
sys.path.append(addpath)
print(sys.path)
'e:\\\\360MoveData\\\\Users\\\\小丁\\\\Desktop\\\\test\\\\temp',
'H:\\\\Anaconda3-2020.02\\\\envs\\\\parl2\\\\python38.zip',
'H:\\\\Anaconda3-2020.02\\\\envs\\\\parl2\\\\DLLs',
'H:\\\\Anaconda3-2020.02\\\\envs\\\\parl2\\\\lib',
'H:\\\\Anaconda3-2020.02\\\\envs\\\\parl2',
'H:\\\\Anaconda3-2020.02\\\\envs\\\\parl2\\\\lib\\\\site-packages',
'e:\\\\360MoveData\\\\Users\\\\小丁\\\\Desktop\\\\test'但绝对路径可移植很差,可以写成动态的
import sys
import os
addpath='e:\\\\360MoveData\\\\Users\\\\小丁\\\\Desktop\\\\test'
print(__file__) #打印当前脚本文件路径
print(os.path.dirname(__file__)) #只保留目录名
print(os.path.dirname(os.path.dirname(__file__)))
sys.path.append(addpath)
e:\\360MoveData\\Users\\小丁\\Desktop\\test\\temp\\模块导入2.py
e:\\360MoveData\\Users\\小丁\\Desktop\\test\\temp
e:\\360MoveData\\Users\\小丁\\Desktop\\test最终改成动态的为:
import sys
import os
# addpath='e:\\\\360MoveData\\\\Users\\\\小丁\\\\Desktop\\\\test'
print(__file__) #打印当前脚本文件路径
print(os.path.dirname(__file__))
base_path=os.path.dirname(os.path.dirname(__file__))
sys.path.append(base_path)
import python1
调用了1.2 包的使用

一个包就是一个文件夹,根据业务线分类不同创建不同目录文件。
在文件夹下创建一个名字为:__init__.py python文件即可
创建包:并在子目录下创建py文件demo

跨包导入【demo1中导入demo2】
在pycharm中直接这样就可以,路径会自动添加
import sys
from test.b.b2 import demo2
调用了在vscode执行需要添加路径,再调用包
import sys
import os
# base_path=os.path.dirname(os.path.dirname(__file__))
base_path='e:\\\\360MoveData\\\\Users\\\\小丁\\\\Desktop\\\\test'
# print(__file__)
sys.path.append(base_path)
from b.b2 import demo2动态写法:就是dirname三次:

其中只要调用了b2文件就会执行其目录下的init文件,以及b __init__都会执行
1.3 os&sys模块
常用模块列举:


sys主要用:
import sys
sys.path #获取系统变量
sys.argv #脚本参数2 时间处理模块
2.1 time




●time.localtime([secs1]):将一个时间戳转换为当前时区的struct_ time。若secs参 数未提供,
则以当前时间为准。
import time
print(time.localtime())
time.struct_time(tm_year=2022, tm_mon=4, tm_mday=10, tm_hour=13, tm_min=29, tm_sec=21, tm_wday=6, tm_yday=100, tm_isdst=0)●time.gmtime( [secs]) :和localtime(方法类似,gmtime()方 法是将一个时间戳转换为UTC时区
(0时区)的struct _time。
●time. time():返回当前时间的时间戳。
●time .mktime(t):将一个struct_ time转化为时间戳。
●time. sleep(secs) :线程推迟指定的时间运行,单位为秒。
import time
s_time = time. time()
time. sleep(3)
print(f"cost time. time() - s_time")
时间花费3秒●time.strftime(format[,t]):把一个代表时间的元组或者struct_time (如由
time.localtime()和time.gmtime(返回)转化为格式化的时间字符串。如果t未指定,将传入
time.localtime()。
-
print(time.strftime("%Y %m/%d %H:%M:%S") ) 2022 04/10 13:36:46
●time.strptime(string[, format]): 把一个格式化时间字符串转化为struct_ time。 实际上它
和strftime()是逆操作。
- 举例: time.strptime( '2017-10-3 17:54' , "8Y-8m-8d 8H:8M") #输出time.struct_ time(tm_ year=2017, tm_ mon=10, tm_ mday=3, tm_ hour=17, tm_ min=54,tm_ sec=0, tm_ wday=1, tm_ yday=276, tm_ isdst=-1)
- 字符串转时间格式对应表

2.2 datetime模块

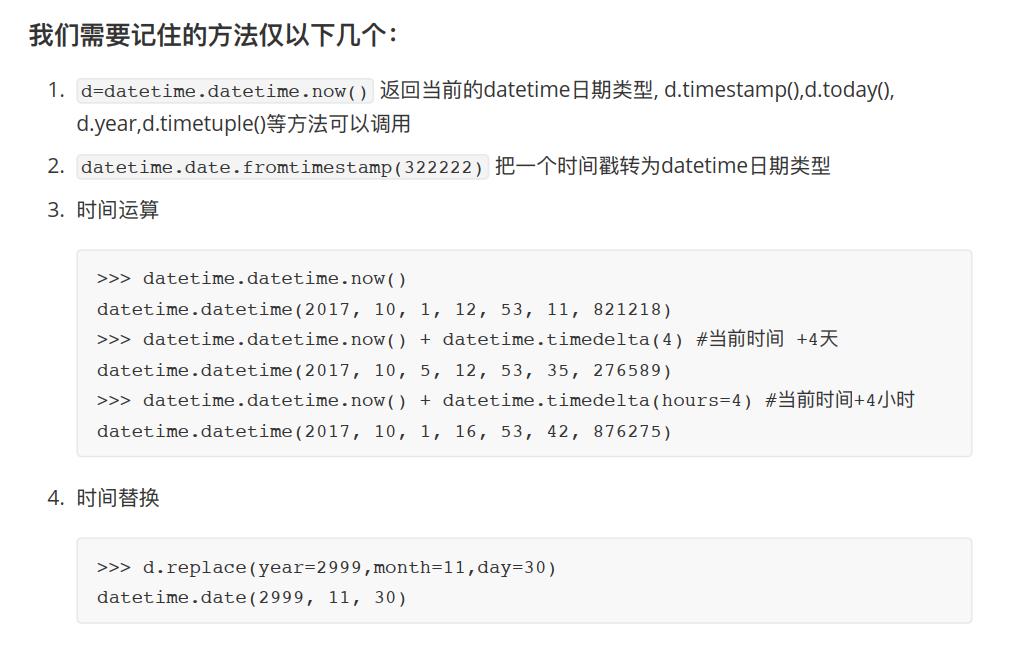
d =datetime. datetime. now( )
print(d + datetime. timedelta(5))
print(d + datetime. timedelta(hours=5))
2022-04-15 13:53:42.117113
2022-04-10 18:53:42.1171133.随机模块
3.1 random

3.2 json模块

- JSON⽀支持的数据类型
Python中的字符串串、数字、列列表、字典、集合、布尔 类型,都可以被序列列化成JSON字符串串,被其它任
何编程语⾔言解析
- 什么是序列列化?
序列列化是指把内存⾥里里的数据类型转变成字符串串,以使其能存储到硬盘或通过⽹网络传输到远程,因为硬盘
或⽹网络传输时只能接受bytes
- 为什么要序列列化?
你打游戏过程中,打累了了,停下来,关掉游戏、想过2天再玩, 2天之后,游戏⼜又从你上次停⽌止的地⽅方继续运⾏行行,你上次游戏的进度肯定保存在硬盘上了了,是以何种形式呢?游戏过程中产⽣生的很多临时数据是不不规律律的,可能在你关掉游戏时正好有10个列列表, 3个嵌套字典的数据集合在内存⾥里里,需要存下来?你如何存?把列列表变成⽂文件⾥里里的多⾏行行多列列形式?那嵌套字典呢?根本没法存。所以,若是有种办法可以直接把内存数据存到硬盘上,下次程序再启动,再从硬盘上读回来,还是原来的格式的话,那是极好的。
- 用于序列列化的两个模块
- json,⽤用于字符串串 和 python数据类型间进⾏行行转换
- pickle,⽤用于python特有的类型 和 python的数据类型间进⾏行行转换


json vs pickle:
JSON:
优点:跨语⾔言(不不同语⾔言间的数据传递可⽤用json交接)、体积⼩小
缺点:只能⽀支持int\\str\\list\\tuple\\dict
Pickle:
优点:专为python设计,⽀支持python所有的数据类型
缺点:只能在python中使⽤用,存储数据占空间⼤大
以上是关于python入门之后须掌握的知识点(模块化编程时间模块)的主要内容,如果未能解决你的问题,请参考以下文章