论文写作分析之四《基于ALBERT-TextCNN模型的多标签医疗文本分类方法》
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文写作分析之四《基于ALBERT-TextCNN模型的多标签医疗文本分类方法》相关的知识,希望对你有一定的参考价值。
论文名称:《基于ALBERT-TextCNN模型的多标签医疗文本分类方法》
发布期刊:《山东大学学报(理学版)》
期刊信息:CSCD

论文写作分析摘要:本文非常简单。网络模型是直接把BERT和TextCNN拼接起来的;亮点在于应用领域的新颖,即医疗文本。本次博客主要来批斗一下这篇论文。
【注】:本文感觉没有创新,模型是用BERT的最后一层接上TextCNN,这不是基操嘛。看完这篇刊上CSCD的论文,感觉我现在就能发论文毕业了。
[2] 参考论文分解
这篇论文的模型图:
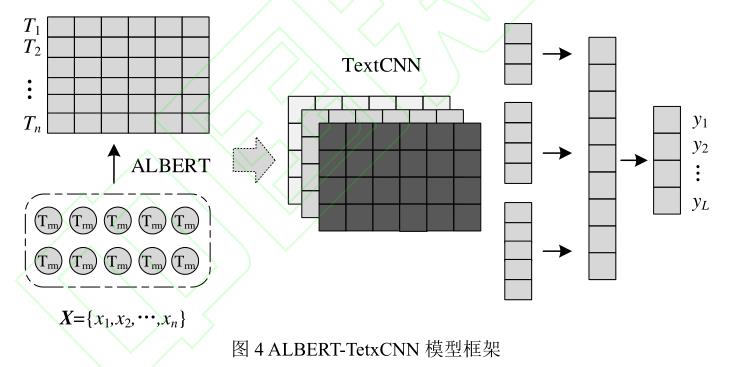
这就是BERT模型最常使用的一个方法。把BERT模型的后面几层用在下游任务。
个人觉得论文的“标签预测”部分,有很大问题。截图如下:

只写了 “输出每条健康问句文本对每个主题类别标签的预测概率”,拿到概率之后,如何确定哪些标签是真?哪些是假?并没有说,反而是直接写道 “健康问句文本所属主题类别的标签预测采用交叉熵损失函数”。这完全没有关系啊。损失函数应该单拿一个小节展开说。
这一段,我个人觉得,没有逻辑、避重就轻。
然后论文的“模型评估”部分,也很一般。截图如下:

只写了最基础的3种评价指标。
【注】论文通篇比较水。
以上是关于论文写作分析之四《基于ALBERT-TextCNN模型的多标签医疗文本分类方法》的主要内容,如果未能解决你的问题,请参考以下文章