数据治理:编译Atlas安装包
Posted Lansonli
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据治理:编译Atlas安装包相关的知识,希望对你有一定的参考价值。
编译Atlas安装包
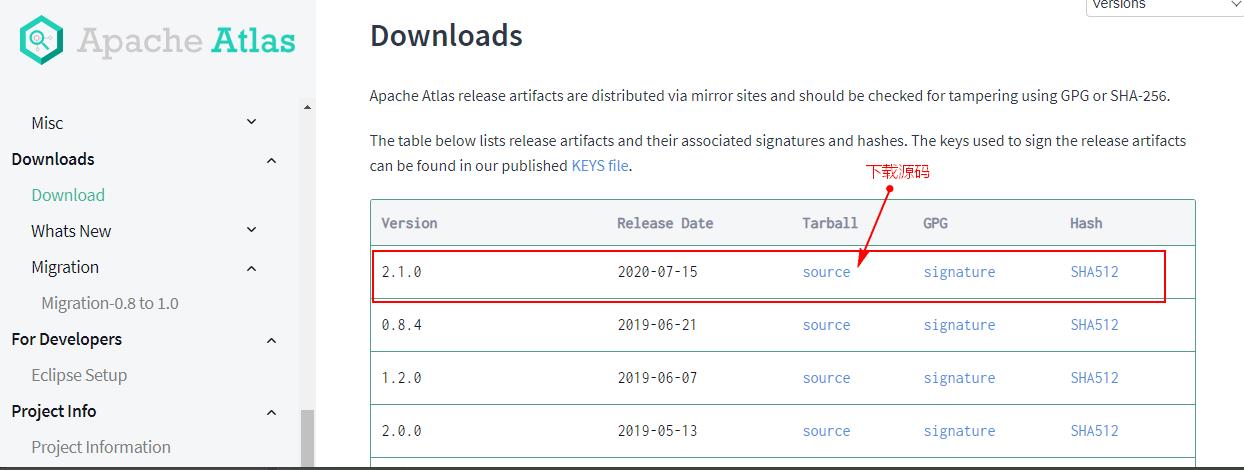
一、Atlas2.1.0源码下载
Atlas官网没有提供Atlas的安装包,需要下载Atlas的源码后编译安装,下载Atlas源码需要登录Atlas官网下载Atlas:https://atlas.apache.org/#/Downloads,选择2.1.0版本:
二、Atlas与其他框架依赖
Atlas内部架构使用到了kafka来做元数据注入和消费,使用到了janus gragh图数据做数据读写,这个图数据库内部又使用了HBase和Solr做数据存储和搜索。Kafka和HBase又需要使用zookeeper。HBase又依赖于HDFS。以上这些所有框架在安装Atlas时可以使用Atlas集成自带的,也可以使用外部安装好的,一般企业开发中,都会选择让Atlas使用外部安装好的这些框架,所以打包时需要选择不使用内嵌框架方式。
Atlas依赖的框架有如下:Zookeeper、HDFS、Hive、HBase、Kafka、Solr,默认集群中已经安装好了除Solr之外的框架,此教程使用的版本如下:
| 服务名称 | 使用版本 |
| Zookeeper | 3.4.13 |
| Hadoop | 3.1.4 |
| Hive | 3.1.2(最低要求3.1.0) |
| HBase | 2.2.6 (最低要求2版本之上) |
| Kafka | 0.11.0.3 |
| Solr | 5.5.1(官网要求Atlas2.1.0对应版本) |
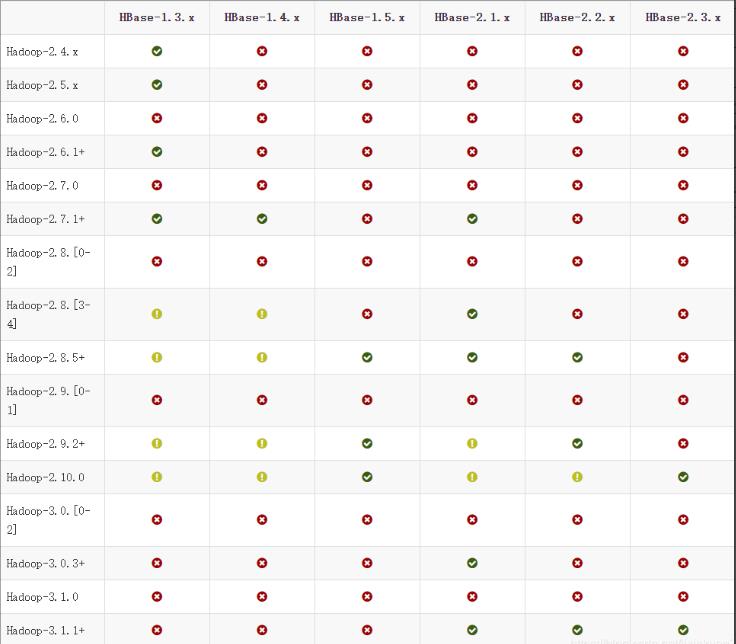
由于后期安装的Atlas版本是2.1.0 最新版,Atlas需要监控Hive中的元数据,Atlas2.1.0版本支持的Hive版本最低为3.1.0,HBase版本最低是HBase2版本之上,Hive3.0+版本之上与Hadoop3.x+版本以上兼容,HBase2版本与Hadoop版本兼容关系如下图示,所以这里综合考虑选择Hadoop3.1.4版本,Hive选择3.1.2版本,HBase选择2.2.6版本。
三、安装Hadoop3.1.4版本
- 安装Hadoop3.1.4版本之前首先卸载旧的Hadoop版本,卸载步骤如下:
1、停止HDFS集群,在Zookeeper中删除HDFS对应的元数据目录
[root@node3 bin]# zkCli.sh
[zk: localhost:2181(CONNECTED) 5] rmr /hadoop-ha
[zk: localhost:2181(CONNECTED) 6] rmr /yarn-leader-election2、删除各个节点上的HDFS安装包
# node1节点
[root@node1 bin]# cd /software/
[root@node1 software]# rm -rf ./hadoop-2.9.2/
#node2节点
[root@node2 bin]# cd /software/
[root@node2 software]# rm -rf ./hadoop-2.9.2/
#node3节点
[root@node3 bin]# cd /software/
[root@node3 software]# rm -rf ./hadoop-2.9.2/
#node4节点
[root@node4 bin]# cd /software/
[root@node4 software]# rm -rf ./hadoop-2.9.2/
#node5节点
[root@node5 bin]# cd /software/
[root@node6 software]# rm -rf ./hadoop-2.9.2/
3、删除5个节点上的/opt/data/目录下除了zookeeper外的目录
#此目录是安装Hadoop 时生成的配置目录,重装需要删除
rm -rf /opt/data/hadoop
rm -rf /opt/data/journal4、删除各个节点上HADOOP_HOME 环境变量
这里也可以不删除,后面重建后,直接修改,然后Source即可生效即可。
- 安装Hadoop3.1.4版本步骤如下:
1)节点划分
| 节点IP | 节点名称 | NN | DN | ZK | ZKFC | JN | RM | NM |
| 192.168.179.4 | node1 | ★ | ★ | ★ | ||||
| 192.168.179.5 | node2 | ★ | ★ | ★ | ||||
| 192.168.179.6 | node3 | ★ | ★ | ★ | ★ | |||
| 192.168.179.7 | node4 | ★ | ★ | ★ | ★ | |||
| 192.168.179.8 | node5 | ★ | ★ | ★ | ★ |
2)下载Hadoop3.1.4版本
下载地址:Apache Hadoop

3)上传下载好的Hadoop安装包到node1节点上,并解压
[root@node1 software]# tar -zxvf ./hadoop-3.1.4.tar.gz4)在node1节点上配置Hadoop的环境变量
[root@node1 software]# vim /etc/profile
export HADOOP_HOME=/software/hadoop-3.1.4/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#使配置生效
source /etc/profile5)配置$HADOOP_HOME/etc/hadoop下的hadoop-env.sh文件
#导入JAVA_HOME
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/
6)配置$HADOOP_HOME/etc/hadoop下的hdfs-site.xml文件
<configuration>
<property>
<!--这里配置逻辑名称,可以随意写 -->
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<property>
<!-- 禁用权限 -->
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<property>
<!-- 配置namenode 的名称,多个用逗号分割 -->
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>node1:8020</value>
</property>
<property>
<!-- dfs.namenode.rpc-address.[nameservice ID].[name node ID] namenode 所在服务器名称和RPC监听端口号 -->
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>node2:8020</value>
</property>
<property>
<!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>node1:50070</value>
</property>
<property>
<!-- dfs.namenode.http-address.[nameservice ID].[name node ID] namenode 监听的HTTP协议端口 -->
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>node2:50070</value>
</property>
<property>
<!-- namenode 共享的编辑目录, journalnode 所在服务器名称和监听的端口 -->
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://node3:8485;node4:8485;node5:8485/mycluster</value>
</property>
<property>
<!-- namenode高可用代理类 -->
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<!-- 使用ssh 免密码自动登录 -->
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<property>
<!-- journalnode 存储数据的地方 -->
<name>dfs.journalnode.edits.dir</name>
<value>/opt/data/journal/node/local/data</value>
</property>
<property>
<!-- 配置namenode自动切换 -->
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>7)配置$HADOOP_HOME/ect/hadoop/core-site.xml
<configuration>
<property>
<!-- 为Hadoop 客户端配置默认的高可用路径 -->
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<property>
<!-- Hadoop 数据存放的路径,namenode,datanode 数据存放路径都依赖本路径,不要使用 file:/ 开头,使用绝对路径即可
namenode 默认存放路径 :file://$hadoop.tmp.dir/dfs/name
datanode 默认存放路径 :file://$hadoop.tmp.dir/dfs/data
-->
<name>hadoop.tmp.dir</name>
<value>/opt/data/hadoop/</value>
</property>
<property>
<!-- 指定zookeeper所在的节点 -->
<name>ha.zookeeper.quorum</name>
<value>node3:2181,node4:2181,node5:2181</value>
</property>
</configuration>8)配置$HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<!-- 配置yarn为高可用 -->
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<!-- 集群的唯一标识 -->
<name>yarn.resourcemanager.cluster-id</name>
<value>mycluster</value>
</property>
<property>
<!-- ResourceManager ID -->
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<!-- 指定ResourceManager 所在的节点 -->
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node1</value>
</property>
<property>
<!-- 指定ResourceManager 所在的节点 -->
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node2</value>
</property>
<property>
<!-- 指定ResourceManager Http监听的节点 -->
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node1:8088</value>
</property>
<property>
<!-- 指定ResourceManager Http监听的节点 -->
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node2:8088</value>
</property>
<property>
<!-- 指定zookeeper所在的节点 -->
<name>yarn.resourcemanager.zk-address</name>
<value>node3:2181,node4:2181,node5:2181</value>
</property>
<property>
<!-- 关闭虚拟内存检查 -->
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 启用节点的内容和CPU自动检测,最小内存为1G -->
<!--<property>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>true</value>
</property>-->
</configuration>9)配置$HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>10)配置$HADOOP_HOME/etc/hadoop/workers文件
[root@node1 ~]# vim /software/hadoop-3.1.4/etc/hadoop/workers
node3
node4
node511)配置$HADOOP_HOME/sbin/start-dfs.sh 和stop-dfs.sh两个文件中顶部添加以下参数,防止启动错误
HDFS_DATANODE_USER=root
HDFS_DATANODE_SECURE_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_JOURNALNODE_USER=root
HDFS_ZKFC_USER=root12)配置$HADOOP_HOME/sbin/start-yarn.sh和stop-yarn.sh两个文件顶部添加以下参数,防止启动错误
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root13)将配置好的Hadoop安装包发送到其他4个节点
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node2:/software/
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node3:/software/
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node4:/software/
[root@node1 ~]# scp -r /software/hadoop-3.1.4 node5:/software/14)在node2、node3、node4、node5节点上配置HADOOP_HOME
#分别在node2、node3、node4、node5节点上配置HADOOP_HOME
vim /etc/profile
export HADOOP_HOME=/software/hadoop-3.1.4/
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:
#最后记得Source
source /etc/profile15)启动HDFS和Yarn
#在node3,node4,node5节点上启动zookeeper
zkServer.sh start
#在node1上格式化zookeeper
[root@node1 ~]# hdfs zkfc -formatZK
#在每台journalnode中启动所有的journalnode,这里就是node3,node4,node5节点上启动
hdfs --daemon start journalnode
#在node1中格式化namenode
[root@node1 ~]# hdfs namenode -format
#在node1中启动namenode,以便同步其他namenode
[root@node1 ~]# hdfs --daemon start namenode
#高可用模式配置namenode,使用下列命令来同步namenode(在需要同步的namenode中执行,这里就是在node2上执行):
[root@node2 software]# hdfs namenode -bootstrapStandby
#node1上启动HDFS,启动Yarn
[root@node1 sbin]# start-dfs.sh
[root@node1 sbin]# start-yarn.sh
注意以上也可以使用start-all.sh命令启动Hadoop集群。16)访问WebUI
访问HDFS : http://node1:50070

访问Yarn WebUI :http://node1:8088
17)停止集群
#停止集群
[root@node1 ~]# stop-dfs.sh
[root@node1 ~]# stop-yarn.sh
注意:以上也可以使用 stop-all.sh 停止集群。四、安装Hive3.1.2版本
- 安装Hive之前首先卸载旧版本的Hive1.2.1,卸载步骤如下:
1)删除node1、node3节点上的Hive安装包
#在node1节点删除Hive安装包
[root@node1 ~]# cd /software/
[root@node1 software]# rm -rf ./hive-1.2.1/
#在node3节点删除Hive安装包
[root@node3 ~]# cd /software/
[root@node3 software]# rm -rf ./hive-1.2.1/2)登录mysql ,删除Hive元数据库hive
[root@node2 ~]# mysql -u root -p123456
mysql> drop database hive;3)删除node1、node3节点上的hive 环境变量
这里也可以不删除,后面直接修改即可。
安装Hive3.1.2版本步骤如下:
1)节点划分
| 节点IP | 节点名称 | Hive服务器 | Hive客户端 | MySQL |
| 192.168.179.4 | node1 | ★ | ||
| 192.168.179.5 | node2 | ★ | ||
| 192.168.179.6 | node3 | ★ |
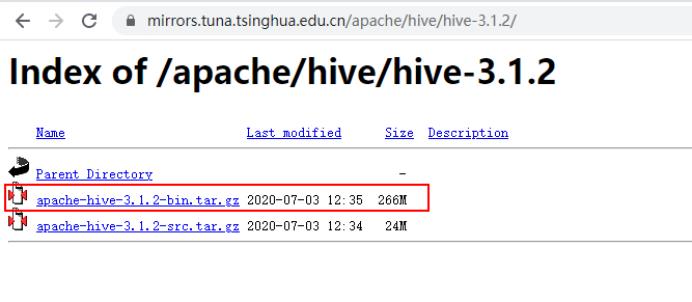
2)下载Hive3.1.2版本
下载地址:Index of /apache/hive/hive-3.1.2
3)将下载好的Hive安装包上传到node1节点上,并修改名称
[root@node1 ~]# cd /software/
[root@node1 software]# tar -zxvf ./apache-hive-3.1.2-bin.tar.gz
[root@node1 software]# mv apache-hive-3.1.2-bin hive-3.1.2
4)将解压好的Hive安装包发送到node3节点上
[root@node1 ~]# scp -r /software/hive-3.1.2/ node3:/software/
5)配置node1、node3两台节点的Hive环境变量
vim /etc/profile
export HIVE_HOME=/software/hive-3.1.2/
export PATH=$PATH:$HIVE_HOME/bin
#source 生效
source /etc/profile6)在node1节点$HIVE_HOME/conf下创建hive-site.xml并配置
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://node2:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>123456</value>
</property>
</configuration>7)在node3节点$HIVE_HOME/conf/中创建hive-site.xml并配置
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>false</value>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://node1:9083</value>
</property>
</configuration>8)node1、node3节点删除$HIVE_HOME/lib下“guava”包,使用Hadoop下的包替换
#删除Hive lib目录下“guava-19.0.jar ”包
[root@node1 ~]# rm -rf /software/hive-3.1.2/lib/guava-19.0.jar
[root@node3 ~]# rm -rf /software/hive-3.1.2/lib/guava-19.0.jar
#将Hadoop lib下的“guava”包拷贝到Hive lib目录下
[root@node1 ~]# cp /software/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar /software/hive-3.1.2/lib/
[root@node3 ~]# cp /software/hadoop-3.1.4/share/hadoop/common/lib/guava-27.0-jre.jar /software/hive-3.1.2/lib/9)将“mysql-connector-java-5.1.47.jar”驱动包上传到node1节点的$HIVE_HOME/lib目录下
上传后,需要将mysql驱动包传入$HIVE_HOME/lib/目录下,这里node1,node3节点都需要传入。
10)在node1节点中初始化Hive
#初始化hive,hive2.x版本后都需要初始化
[root@node1 ~]# schematool -dbType mysql -initSchema11)在服务端和客户端操作Hive
#在node1中登录Hive ,创建表test
[root@node1 conf]# hive
hive> create table test (id int,name string,age int ) row format delimited fields terminated by '\\t';
#向表test中插入数据
hive> insert into test values(1,"zs",18);
#在node1启动Hive metastore
[root@node1 hadoop]# hive --service metastore &
#在node3上登录Hive客户端查看表数据
[root@node3 lib]# hive
hive> select * from test;
OK
1 zs 18
五、安装HBase2.2.6版本
由于后期安装的Atlas版本是2.1.0,需要的HBase版本至少是HBase2版本之上,所以这里安装HBase2.2.6,HBase2.x版本支持的Hadoop版本为2.7.1+以上。
- 首先卸载旧版本HBase ,卸载步骤如下:
1)删除HBase在Zookeeper中的元数据
[root@node5 software]# zkCli.sh
[zk: localhost:2181(CONNECTED) 1] rmr /hbase2)在node3、node4、node5节点上删除HBase安装包
[root@node3 ~]# cd /software/
[root@node3 software]# rm -rf ./hbase-1.2.9/
[root@node4 ~]# cd /software/
[root@node4 software]# rm -rf ./hbase-1.2.9/
[root@node5 ~]# cd /software/
[root@node6 software]# rm -rf ./hbase-1.2.9/
3)删除node3、node4、node5节点上的HBase环境变量
这里也可以不删除,后面直接修改即可。
- 重新安装HBase步骤如下:
1)下载HBase 2.2.6
下载地址:https://archive.apache.org/dist/hbase/2.2.6/

2)规划HBase集群节点
| 节点IP | 节点名称 | HBase服务 |
| 192.168.179.6 | node3 | RegionServer |
| 192.168.179.7 | node4 | HMaster,RegionServer |
| 192.168.179.8 | node5 | RegionServer |
#将下载好的HBase安装包上传至node4节点/software下,并解压
[root@node4 software]# tar -zxvf ./hbase-2.2.6-bin.tar.gz当前节点配置HBase环境变量
#配置HBase环境变量
[root@node4 software]# vim /etc/profile
export HBASE_HOME=/software/hbase-2.2.6/
export PATH=$PATH:$HBASE_HOME/bin
#使环境变量生效
[root@node4 software]# source /etc/profile3)配置$HBASE_HOME/conf/hbase-env.sh
#配置HBase JDK
export JAVA_HOME=/usr/java/jdk1.8.0_181-amd64/
#配置 HBase不使用自带的zookeeper
export HBASE_MANAGES_ZK=false4)配置$HBASE_HOME/conf/hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>node3,node4,node5</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
</configuration>
5)配置$HBASE_HOME/conf/regionservers,配置RegionServer节点
node3
node4
node5
6)配置backup-masters文件
手动创建$HBASE_HOME/conf/backup-masters文件,指定备用的HMaster,需要手动创建文件,这里写入node5,在HBase任意节点都可以启动HMaster,都可以成为备用Master ,可以使用命令:hbase-daemon.sh start master启动。
#创建 $HBASE_HOME/conf/backup-masters 文件,写入node5
[root@node4 conf]# vim backup-masters
node57)复制hdfs-site.xml到$HBASE_HOME/conf/下
[root@node4 conf]# scp /software/hadoop-3.1.4/etc/hadoop/hdfs-site.xml /software/hbase-2.2.6/conf/
8)将HBase安装包发送到node3,node5节点上,并在node3,node5节点上配置HBase环境变量
[root@node4 software]# cd /software
[root@node4 software]# scp -r ./hbase-2.6.2 node3:/software/
[root@node4 software]# scp -r ./hbase-2.6.2 node5:/software/
注意:在node3、node5上配置HBase环境变量。
9)重启Zookeeper、重启HDFS及启动HBase集群
#注意:一定要重启Zookeeper,重启HDFS,在node4节点上启动HBase集群[root@node4 software]# start-hbase.sh
#访问WebUI,http://node4:16010。停止集群:在任意一台节点上stop-hbase.sh
六、安装Solr 5.5.1
Solr是Apache下的一个顶级开源项目,采用Java开发,它是基于Lucene的全文搜索服务器。Solr提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,它可运行在Jetty(Solr内置的小服务器,类似于一个小型Tomcat服务器)、Tomcat等这些Servlet容器中。Solr索引的实现方法很简单,用POST方法向Solr服务器发送一个描述Field及其内容的XML文档,Solr根据XML文档添加、删除、更新索引。Solr搜索只需要发送HTTP GET请求,然后对Solr返回XML、JSON等格式的查询结果进行解析,组织页面布局。另外,Solr不提供构建UI的功能,它只提供了一个管理界面,通过管理界面可以查询Solr的配置和运行情况。
Solr下载地址:http://archive.apache.org/dist/lucene/solr/5.5.1/solr-5.5.1.tgz
- 下载完成后,按照下面步骤进行Solr安装:
1)划分节点
这里搭建Solr采用分布式方式安装,节点划分如下:
| 节点IP | 节点名称 | Solr服务 |
| 192.168.179.6 | node3 | solr |
| 192.168.179.7 | node4 | solr |
| 192.168.179.8 | node5 | solr |
2)将下载好的Solr安装包上传至node3节点,并解压
[root@node3 software]# tar -zxvf ./solr-5.5.1.tgz 3)配置Solr bin目录下 solr.in.sh文件
编辑 $SOLR_HOME/bin/solr.in.sh文件,修改以下内容,也可追加写入,ZK_HOST:配置zookeeper集群,这里需要使用zookeeper来协调Solr集群节点。SOLR_HOST:指定当前SOLR节点Host。
ZK_HOST="node3:2181,node4:2181,node5:2181"
SOLR_HOST="node3"4)将Solr安装包分发到node4,node5节点上
#分发到node4,node5节点
[root@node3 software]# scp -r ./solr-5.5.1 node4:/software/
[root@node3 software]# scp -r ./solr-5.5.1 node5:/software/
#分发完成之后,需要在node4,node5节点$SOLR_HOME/bin/solr.in.sh中修改对应的SOLR_HOST为对应节点。
SOLR_HOST="node4"
SOLR_HOST="node5"5)每台节点启动zookeeper
[root@node3 ~]# zkServer.sh start
[root@node4 ~]# zkServer.sh start
[root@node5 ~]# zkServer.sh start
6)在每台节点启动Solr
#进入每台节点$SOLR_HOME/bin下,启动Solr
[root@node3 bin]# ./solr start
[root@node4 bin]# ./solr start
[root@node5 bin]# ./solr start
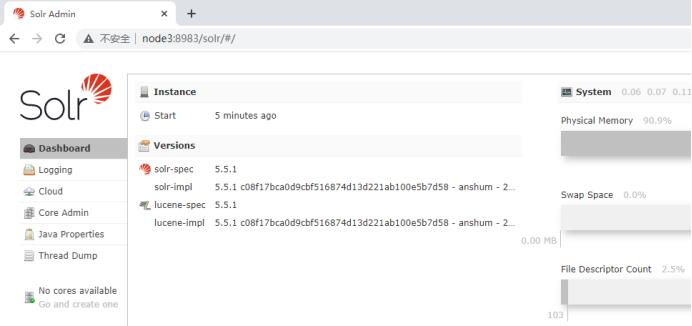
7)查看Solr WebUI
访问任意一台节点 http://node3:8983/ 查看WebUI
七、安装Maven 3.6.3
由于编译Atlas源码需要用到Maven进行编译,这里需要安装Maven,Maven只需要安装到一台节点即可,在安装Maven节点上后期进行编译Atlas源码包。Maven下载地址:http://maven.apache.org/download.cgi 这里下载Maven版本为:3.6.3,下载Maven完成后,按照以下步骤配置Maven。
1)上传Maven安装包到node3节点,并解压
[root@node3 software]# tar -zxvf ./apache-maven-3.6.3-bin.tar.gz2)配置Maven环境变量
#打开 /etc/profile在最后追加以下内容
[root@node3 software]# vim /etc/profile
export MAVEN_HOME=/software/apache-maven-3.6.3/
export PATH=$PATH:$MAVEN_HOME/bin
#配置环境变量生效
[root@node3 software]# source /etc/profile3)检查是否安装Maven成功
[root@node3 software]# mvn -v
Apache Maven 3.6.3 (cecedd343002696d0abb50b32b541b8a6ba2883f)
Maven home: /software/apache-maven-3.6.3
Java version: 1.8.0_181, vendor: Oracle Corporation, runtime: /usr/java/jdk1.8.0_181-amd64/jre
Default locale: en_US, platform encoding: UTF-8
OS name: "linux", version: "3.10.0-957.el7.x86_64", arch: "amd64", family: "unix"4)修改默认下载源为阿里镜像源
为了编译源码下载包更快,可以修改$MAVEN_HOME/conf/settings.xml文件,添加阿里镜像源,注意:将以下内容放在“<mirrors>...</mirrors>”之间。此外,maven下载包默认对应的仓库位置在$user.home/.m2/repository 目录下,”$user.home”为当前用户家目录。
<!-- 添加阿里云镜像-->
<mirror>
<id>nexus-aliyun</id>
<mirrorOf>central</mirrorOf>
<name>Nexus aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public</url>
</mirror>
<mirror>
<id>UK</id>
<name>UK Central</name>
<url>http://uk.maven.org/maven2</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>repo1</id>
<mirrorOf>central</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://repo1.maven.org/maven2/</url>
</mirror>
<mirror>
<id>repo2</id>
<mirrorOf>central</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://repo2.maven.org/maven2/</url>
</mirror>
八、编译Atlas源码
- 编译Atlas源码步骤如下:
1)将下载好的Atlas安装包上传到node3节点上,并解压
[root@node3 software]# tar -zxvf ./apache-atlas-2.1.0-sources.tar.gz 2) 修改Atlas pom.xml文件
修改文件/software/apache-atlas-sources-2.1.0/pom.xml中663行,将各大数据组件对应的版本改成与自己集群中对应的版本。
<hadoop.version>3.1.4</hadoop.version>
<hbase.version>2.2.6</hbase.version>
<solr.version>5.5.1</solr.version>
<hive.version>3.1.2</hive.version>
<kafka.version>0.11.0.3</kafka.version>
<zookeeper.version>3.4.13</zookeeper.version>3)修改Atlas源码中disto目录下pom.xml文件
由于在子工程distro中,HBase和solr的下载路径是外网,这里修改替换成清华大学下载网址,速度更快。需要修改“/software/apache-atlas-sources-2.1.0/distro”路径下pom.xml的大概254&258行。
<hbase.tar>http://mirrors.tuna.tsinghua.edu.cn/apache/hbase/$hbase.version/hbase-$hbase.version-bin.tar.gz</hbase.tar>
<solr.tar>http://mirrors.tuna.tsinghua.edu.cn/apache/lucene/solr/$solr.version/solr-$solr.version.tgz</solr.tar>4)编译Atlas源码
#进入/software/apache-atlas-sources-2.1.0目录
[root@node3 ~]# cd /software/apache-atlas-sources-2.1.0
#将编译器的初始堆内存调大,在把最大堆内存调大,因为文件比较大,用的内存比较多
[root@node3 apache-atlas-sources-2.1.0]# export MAVEN_OPTS="-Xms2g -Xmx2g"
#执行以下命令编译
[root@node3 apache-atlas-sources-2.1.0]# mvn clean -DskipTests package -Pdist
注意:如果想使用内置的hbase和solr可以执行以下命令进行编译,不过编译过程很痛苦:
mvn clean -DskipTests package -Pdist,embedded-hbase-solr
历经千辛万苦,Atlas编译完成,此图为证:

注意:以上编译可能会由于网络波动在中途出现编译不通过问题,可以直接重新执行编译命令,同时结合编译错误解决。
5)查看编译好的安装包
进入目录“/software/apache-atlas-sources-2.1.0/distro/target”下,查看编译好的安装包及解压好的包。

6)编译完成之后,可以将maven下载的仓库打包保存,方便后期再次编译
[root@node3 ~]# cd ~
[root@node3 ~]# tar -czvf mvn_repo.tar.gz ./.m2/ 九、编译错误解决
1)“Cannot dowload ....linux-x64-72_binging.node”

编译过程中遇到以上错误,原因是对应的网站不能访问,被墙掉了,可以根据给出的网址手动单独下载“linux-x64-72_binging.node”,下载完成后上传到“/software”目录下,在环境变量中加入:
export SASS_BINARY_PATH=/software/linux-x64-72_binding.node附件如下:
source生效后,重新执行编译命令,当编译完成后,需要手动删除此环境变量。
2)“npm install”卡住,不继续进行

这种情况是npm(和vue前端相关管理工具)安装不上,按照以下命令,可以预先安装上npm,安装完成后,一定重新打开xshell页面,进入对应路径继续编译。
[root@node3 ~]# curl --silent --location https://rpm.nodesource.com/setup_10.x | bash -
[root@node3 ~]# yum install -y nodejs
[root@node3 ~]# npm install -g cnpm --registry=https://registry.npm.taobao.org3)Maven下载“pentaho-aggdesigner-algorithm-5.1.5-jhyde”包卡住

这个包在阿里云镜像中不存在,只能由外网下载,这里下载太慢导致下载不下来,所以直接找个Maven仓库,找到对应的“pentaho-aggdesigner-algorithm-5.1.5-jhyde.jar”上传到Maven仓库“/root/.m2/repository/org/pentaho/pentaho-aggdesigner-algorithm/5.1.5-jhyde”目录下即可。此jar包的附件如下:
- 📢博客主页:https://lansonli.blog.csdn.net
- 📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
- 📢本文由 Lansonli 原创,首发于 CSDN博客🙉
- 📢大数据系列文章会每天更新,停下休息的时候不要忘了别人还在奔跑,希望大家抓紧时间学习,全力奔赴更美好的生活✨
以上是关于数据治理:编译Atlas安装包的主要内容,如果未能解决你的问题,请参考以下文章