多标签文本分类BERT for Sequence-to-Sequence Multi-Label Text Classification
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了多标签文本分类BERT for Sequence-to-Sequence Multi-Label Text Classification相关的知识,希望对你有一定的参考价值。
·阅读摘要:
本文在已有的SGM和BERT模型上改进,提出了SGM+BERT模型、混合模型。实验证明SGM+BERT模型收敛比BERT快很多,混合模型的效果最好。
·参考文献:
[1] BERT for Sequence-to-Sequence Multi-Label Text Classification
[2] SGM模型讲解,参考博客:【多标签文本分类】SGM: Sequence Generation Model for Multi-Label Classification
[3] Bert模型讲解,参考博客:【文本分类】BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
本文是改进模型类型的论文,重点全在模型上,其他部分可以不看。
本文提出了SGM+BERT模型、混合模型一共两个模型。
[1] SGM+BERT模型
如下图,是论文中的SGM+BERT模型:

如下图,是SGM模型:
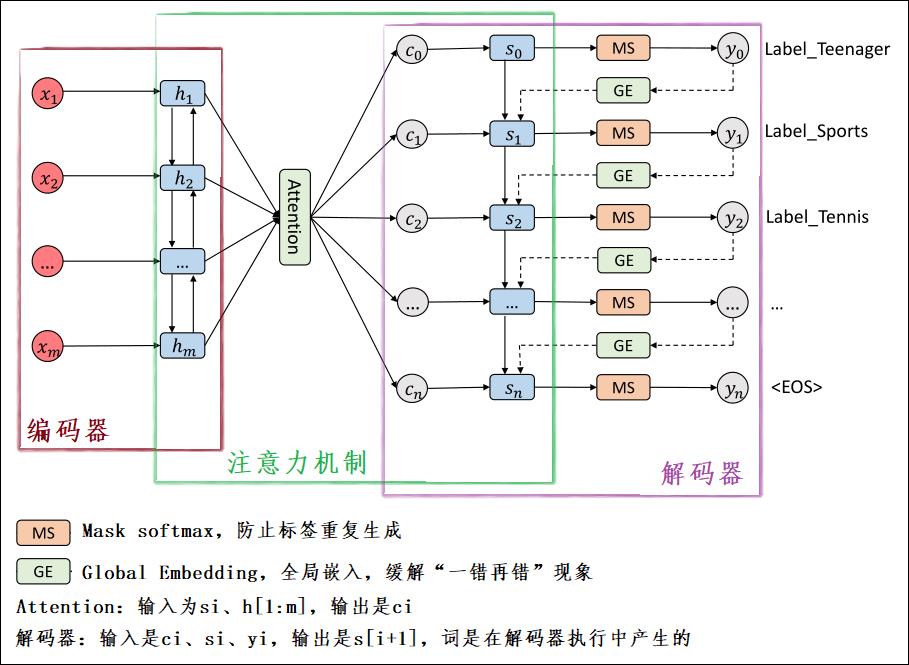
对比上述两个模型,可以看到,SGM+BERT模型只是在文字转词向量的时候,使用了BERT来获取文本嵌入的语言表示。其他和SGM模型是一模一样的。
论文中仅仅提到,SGM+BERT模型比SGM模型的好处在于,多标签BERT通常需要几十个epoch才能收敛,这与BERT+SGM模型不同,后者只需几百次迭代(不到半个epoch)就可以得到令人满意的结果。
SGM+BERT模型的具体流程如下:

· 1、对于一条文本来说,我们初始化这个文本即将被预测出来的标签集合
L
p
r
e
d
L_pred
Lpred为空,并且有已知的所有标签
L
L
L。
· 2、对该文本用BERT转化为词向量,再把词向量送入BiLSTM。
· 3、初始化解码器的初始数据。第一个词 < B O S > <BOS> <BOS>,和 S 0 S_0 S0。
· 4、进入解码器的循环里面了。数据送入BiLSTM进行解码。
· 5、把已经预测过的标签,对应位置置为负无穷,即 I t i I_ti Iti。这样的话,在第六步使用softmax的时候,就可以排除掉之前已经预测过的标签的干扰。
【注】:这一步叫做
Mask softmax,是在SGM那篇论文里的,感兴趣可以参考【多标签文本分类】SGM: Sequence Generation Model for Multi-Label Classification
· 6、softmax预测。
· 7、找出对应标签,添加到预测的标签集 L p r e d L_pred Lpred中。
[2] 混合模型
首先明确,混合的是BERT模型和SGM+BERT模型。
SGM+BERT模型比BERT模型快,但是效果并不好,论文探究了把两者的输出混合的算法,实验发现效果更好。算法如下:
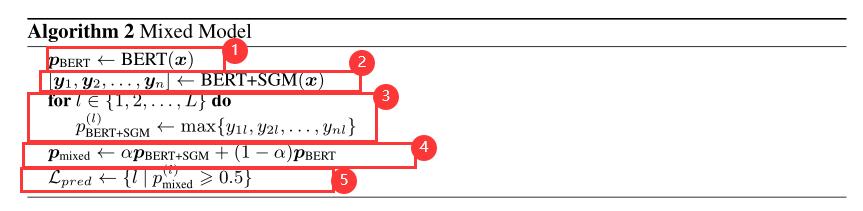
· 1、对于一条文本
x
x
x,先用BERT模型,接个全连接层、softmax,直接就可以得到每个标签的概率
p
B
E
R
T
p_BERT
pBERT。
· 2、对于一条文本 x x x,再用SGM+BERT模型,得到了 [ y 1 , y 2 , … … , y n ] [y_1,y_2,……,y_n] [y1,y2,……,yn],是解码器的n个时间步,每个时间步都能得到对L个类别的概率。
· 3、以L个标签来遍历,纵向从第2步的每个时间步中,找出最大的概率。
· 4、通过参数来把第1步和第3步的概率中和一下。
· 5、以第4步的概率为准,大于0.5的就算是该文本 x x x有此标签。
【注】:这个混合模型看起来很不靠谱……
以上是关于多标签文本分类BERT for Sequence-to-Sequence Multi-Label Text Classification的主要内容,如果未能解决你的问题,请参考以下文章