Java岗大厂面试百日冲刺Day52— 数据库8 (日积月累,每日三题)
Posted _陈哈哈
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java岗大厂面试百日冲刺Day52— 数据库8 (日积月累,每日三题)相关的知识,希望对你有一定的参考价值。
大家好,我是陈哈哈,北漂五年。相信大家和我一样,
都有一个大厂梦,作为一名资深Java选手,深知面试重要性,接下来我准备用100天时间,基于Java岗面试中的高频面试题,以每日3题的形式,带你过一遍热门面试题及恰如其分的解答。
一路走来,随着问题加深,发现不会的也愈来愈多。但底气着实足了不少,相信不少朋友和我一样,日积月累才是最有效的学习方式!想起高三时一个同学的座右铭:只有沉下去,才能浮上来。共勉(juan)。

工地坐标:深圳
作者:胡巴
车票
本栏目Java开发岗高频面试题主要出自以下各技术栈:Java基础知识、集合容器、并发编程、JVM、Spring全家桶、MyBatis等ORMapping框架、mysql数据库、Redis缓存、RabbitMQ消息队列、Linux操作技巧等。
面试题1:谈谈你对InnoDB和MyISAM这两个引擎的理解吧?

一、InnoDB
先说InnoDB吧,InnoDB 从 MySQL5.5(2010年) 版本代替 MyISAM 成为默认引擎,可以说只要玩儿过 MySQL 的,都用过InnoDB,相比MyISAM强调性能,InnoDB 侧重于提供事务支持以及外部键等高级数据库功能。
1、支持事务。默认的事务隔离级别为可重复读(REPEATABLE-READ),通过MVCC(并发版本控制)来实现。
InnoDB的
AUTOCOMMIT默认是打开的,即每条SQL语句会默认被封装成一个事务,自动提交,这样会影响速度,所以最好是把多条SQL语句显示放在begin和commit之间,组成一个事务去提交。
2、使用的锁粒度默认为行级锁,可以支持更高的并发;当然,也支持表锁,但不支持页锁。
其实有这两点就足以奠定InnoDB在存储引擎中的霸主地位了。你知道的,使用场景真的太多了。
3、支持外键约束;外键约束其实降低了表的查询速度,但是增加了表之间的耦合度。个人感觉很鸡肋的功能,在我们开发中是不允许用外键的,表之间的关联在业务层进行控制即可,否则投产后很可能会对功能和性能造成影响。
4、InnoDB的主键范围更大,最大是MyISAM的2倍。同时,可以通过自动增长列,方法是auto_increment。
5、配合一些热备工具可以支持在线热备份;
6、在InnoDB中存在着缓冲管理,通过缓冲池(innodb_buffer_size),可以将部分索引和数据缓存起来,加快查询的速度;
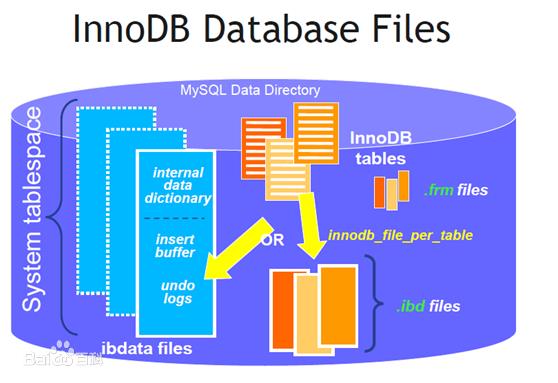
7、对于InnoDB类型的表,其数据的物理组织形式是聚簇表。所有的数据按照主键来组织。数据和索引放在一块,都位于B+树的叶子节点上;
8、DELETE FROM table时,InnoDB不会重新建立表,而是一行一行的删除。其实在MySQL后台就是给这行数据的is_delete字段加了标识,实际不会直接清空磁盘内容,当然这也是InnoDB能通过flashback等插件快速找回误删数据的特性(后门儿)之一。
不爽的是,当你删除一张大表后会发现磁盘空间不降反增,别惊讶,磁盘增加的那部分其实是只事务日志信息,想详细了解的同学可以参考我的另一篇文章《delete、truncate、drop的区别有哪些,该如何选择》
InnoDB的存储表和索引有下面两种形式:
- 共享表空间存储:所有的表和索引存放在同一个表空间中。
- 多表空间存储:表结构放在.frm文件,数据和索引放在.ibd文件中。分区表的话,每个分区对应单独的.ibd文件,分区表的定义可以查看我的其他文章。使用分区表的好处在于提升查询效率。
- 对于
InnoDB来说,最大的优势在于支持事务,当然这是以牺牲效率为代价的。
二、MyISAM
还有好多同学在面试回答 InnoDB 和 MyISAM 区别的时候,依然会带上 InnoDB 不支持全文检索,MyISAM 支持对 BLOB 和 TEXT 的前500个字符索引云云,那是5、6年之前的答案啦。那么MyISAM有哪些特点呢?
1、不支持事务。这也算特点???没错,就是这么不要脸。不支持事务,像是挣脱了枷锁,在读写(Insert、select)效率上,要高于InnoDB不少。场景在:日志记录、调查统计表时,绝对值得一用。对了,不支持事务,自然就不支持锁!
2、体积小,质量大。MyISAM的索引和数据是分开的,并且索引是有压缩的,内存使用率就对应提高了不少。同时能加载更多索引,而Innodb的索引和数据是紧密捆绑的,没有使用压缩从而会造成 Innodb 比 MyISAM 数据文件体积庞大很多。
每张MyISAM表在磁盘上会对应三个文件。
- .frm文件:存储表的定义数据
- .MYD文件:存放表具体记录的数据
- .MYI文件:存储索引

3、从以往经验来说,select count(*)和order by大概是使用最频繁的,大概能占了整个sql总语句的60%以上的操作,而这种操作Innodb其实也是会锁表的,很多人以为Innodb是行级锁,那个只是where对它主键是有效,非主键的还是会锁全表的。
当然,我也可以给where、group by、order by的字段都加索引对吧。不用想了,就是都会加。
4、常常应用部门需要我给他们定期某些表的数据,MyISAM的话很方便,只要发给他们对应那表的(frm.MYD,MYI)的文件,让他们自己在对应版本的数据库启动就行,而Innodb就需要导出.sql了,因为光给别人文件,受字典数据文件的影响,对方是无法使用的。
5、没有where的count(*)使用MyISAM要比InnoDB快得多。的select count() 是非常快的;MyISAM内置了一个计数器,把表的总行数(row)存储在磁盘上,当执行 select count() from t 时,直接返回总数据。当时,当 count(*) 语句包含 where条件时,两种引擎的操作流程是一样的。
6、DELETE FROM table时,MyISAM会先将表结构备份到一张虚拟表中,然后执行drop,最后根据备份重建该表。这是我使用这两个引擎时让我感觉区分最明显的特性之一。
追问:平时开发中你是怎么选择这两个引擎的?
- 是否要支持事务;
- 读多写少可以倾向 MyISAM,如果写比较频繁就用InnoDB。
- 系统奔溃后,MyISAM恢复起来更困难,我之前出现过表损坏情况,能否接受,不能接受选 InnoDB;
- 不知道用什么就用InnoDB。

课间休息,来记录一下小梅同学出差西安前一天,坐标:济南。
面试题2:用过视图么?为什么要使用视图?
视图是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。
视图是存储在数据库中的查询的SQL语句,视图有两个特点:
- 安全,方便控制权限,我们知道视图是可以隐藏一些数据的。如:个税表,可以用视图查询只显示姓名,地址,而不显示个税号和工资数等。
- 可使复杂的查询易于理解和使用。这个视图就像一个窗口,从中只能看到你想看的数据列。或许你查询一个视图时感觉很简单,其实这个视图数据是通过复杂的得来的。真是纸上得来终觉浅。
其实在我们日常工作中,公司对数据库的管理,不仅仅细化到用户权限这层,用户权限下又包括用户能访问哪些表、那些视图、哪些存储过程,对于很多数据并不会公开的,因此在你们开发时,DBA同事只给你们部门分几个视图也是常见的事儿。
追问1:那视图都有哪些优点呢?
1、 视图能简化用户操作
视图机制使用户可以将注意力集中在所关心地数据上。如果这些数据不是直接来自基本表,则可以通过定义视图,使数据库看起来结构简单、清晰,并且可以简化用户的的数据查询操作。例如,那些定义了若干张表连接的视图,就将表与表之间的连接操作对用户隐藏起来了。换句话说,用户所作的只是对一个虚表的简单查询,而这个虚表是怎样得来的,用户无需了解。
2、 视图使用户能以多种角度看待同一数据
视图机制能使不同的用户以不同的方式看待同一数据,当许多不同种类的用户共享同一个数据库时,这种灵活性是非常必要的。
例如,Student表涉及全校15个院系学生数据,可以在其上定义15个视图,每个视图只包含一个院系的学生数据,并只允许每个院系的主任查询和修改本原系学生视图。
一般是这样做的:创建一个视图,定义好该视图所操作的数据。之后将用户权限与视图绑定。这样的方式是使用到了一个特性:grant语句可以针对视图进行授予权限给不同的用户使用。
3、 视图对重构数据库提供了一定程度的逻辑独立性
数据的物理独立性是指用户的应用程序不依赖于数据库的物理结构。数据的逻辑独立性是指当数据库重构造时,如增加新的关系或对原有的关系增加新的字段,用户的应用程序不会受影响。层次数据库和网状数据库一般能较好地支持数据的物理独立性,而对于逻辑独立性则不能完全的支持。
在关系型数据库中,数据库的重构造往往是不可避免的。重构数据库最常见的是将一个基本表“垂直”地分成多个基本表。例如:将学生关系Student(ID,Sname,sex,age,class),分为SX(SID,Sname,age)和SY(SID,sex,class)两个关系。这时原表Student为SX表和SY表自然连接的结果。如果建立一个视图Student:
CREATE VIEW Student(SID,Sname,sex,age,class)AS SELECT SX.ID,SX.Sname,SY.sex,
SX.age,SY.class FROM Student1 SX,Student2 SY WHERE SX.SID=SY.SID;
这样尽管数据库的逻辑结构改变了(变为SX和SY两个表了),但应用程序不必修改,因为新建立的视图定义为用户原来的关系,使用户的外模式保持不变,用户的应用程序通过视图仍然能够查找数据。
当然,视图只能在一定程度上提供数据的逻辑独立,比如由于视图的更新是有条件的,因此应用程序中修改数据的语句可能仍会因为基本表构造的改变而改变。
4、安全性
有了视图机制,就可以在设计数据库应用系统时,对不同的用户定义不同的视图,使机密数据不出现在不应该看到这些数据的用户视图上。这样视图机制就自动提供了对机密数据的安全保护功能。

课间休息,来一波我们家小哈近照~啥都要学,难道你还想穿鞋?
作者:陈小哈
面试题3:mysql里记录货币用什么数据类型比较好?你们是怎么存的?
在支付类项目中,只要涉及到钱,就是大事,稍有不注意就可能出个p0事故。这不,前段时间字节一位同事又因一个p0事故压力过大出了意外。惋惜。
在MySQL中,FLOAT、DOUBLE、DECIMAL都是常用来存小数的类型,我们先看看他们各数据类型的特点:
- FLOAT:浮点型,含字节数为4,32bit,
近似数值,尾数精度 16,数值范围为-3.4E38~3.4E38(7个有效位) - DOUBLE:
双精度实型,含字节数为8,64bit数值范围-1.7E308~1.7E308(15个有效位) - DECIMAL(x,y):数字型,128bit,
不存在精度损失,常用于银行帐目计算。(28个有效位)
Decimal(n,m)表示数值中共有n位数,其中整数n-m位,小数m位。例:decimal(10,6),数值中共有10位数,其中整数占4位,小数占6位。
例:decimal(2,1),此时,插入数据18.8、18等会出现数据溢出错误的异常;插入1.23或1.2345…会自动四舍五入成1.2;插入2会自动补成2.0,以确保2位的有效长度,其中包含1位小数。
一般用decimal(18,2),长度18,保存2位小数。
不使用float或者double的原因,是因为float和double是以二进制存储的,所以有一定的误差。
比如:在数据库中c1,c2,c3分别存储类型是float(10,2),decimal(10,2),float类型。
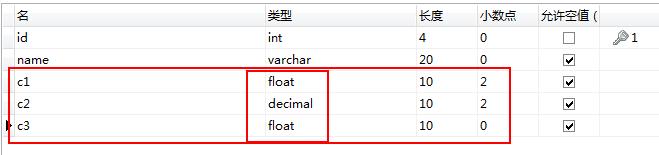
INTO test (c1,c2,c3) VALUES (1234567.23,1234567.23,1234567.23)
新增后的数据如下图:

可以看出,使用float类型存储有一定的误差。因此使用decimal(x,y)类型。其实每个公司具体情况不同,像我们公司在数据库记录金额时使用的是扩大10000倍的整数来存。如存1.5元时,库中存的就是15000,不用小数来存,在业务代码层控制转换,个人感觉挺香的。
每日小结
今天我们复习了面试中常问的数据库相关问题,今天的内容你做到心中有数了么?对了,如果你的朋友也在准备面试,请将这个系列扔给他,如果他认真对待,肯定会感谢你的!!好了,今天就到这里,学废了的同学,记得在评论区留言:打卡。,给同学们以激励。
以上是关于Java岗大厂面试百日冲刺Day52— 数据库8 (日积月累,每日三题)的主要内容,如果未能解决你的问题,请参考以下文章