ResNetResNet论文学习笔记
Posted Rainbowman 0
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ResNetResNet论文学习笔记相关的知识,希望对你有一定的参考价值。
文章目录
最近一段时间在做毕设,整体节奏较为悠闲,毕设完成后也会分享在博客和我的网站。这两天比较闲,跟着子豪兄的视频和论文笔记,读了ResNet。
作为一名准研究生,我在看论文方面还存在相当多的不足。其实我一直不清楚自己要怎么去读一篇论文,是应该把里面的所有技术细节都完全弄明白,还是只去把握他的大体思想。我一直处于摇摆之中,有时候觉得需要把技术细节完全弄懂,这样心里才舒服;但这样做太费时间,有时候又感觉现阶段能做到把握论文的大体思想应该就够了,毕竟现成的代码库已经把这些细节实现都优化得很好了。这样的矛盾应该不少研究生都遇到过,我也相信自己会慢慢找到答案。
我还是想尽可能的将一篇论文的细节弄懂,但目前实力有限,因此本篇博客只当作记录,方便以后快速回顾。
0. 背景
何恺明大神在2016的CVPR上做了ResNet的报告,之后做报告的YOLOv1,这两个模型都非常重要!
我们经常在一些论文中看到计算机视觉的四大任务:图像分类、目标检测、语义分割和实例分割。这些任务基本都是使用深度学习来解决的,具体思路是:先用神经网络提取特征,再对这些特征进行分类或回归等一系列处理。因此提取特征就至关重要,就像R-CNN这篇论文中所说的:“Features matter!”
其实在我看来深度学习相较于机器学习的一大优势就是神经网络能自动提取原始数据深层的语义特征,部分取代了机器学习中的特征工程。
那么如何才能提取到更好的特征呢?之前的研究(VGG、GoogleNet)表明网络的深度越深,提取到的特征就越丰富,模型的表现更好。那么我们直接把网络加深不就可以提升网络性能了吗?
这种想法是非常自然的,但实际上随着网络的加深会出现一个反直觉的问题:网络退化。网络退化是指更深的网络却在训练集和测试集上的效果更差,效果还不如浅层网络,如下图所示。
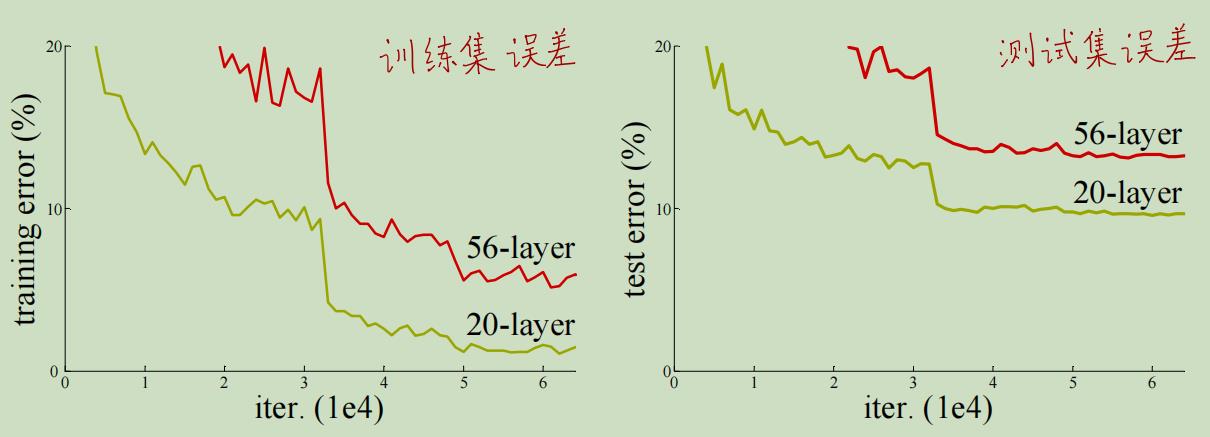
我们看到56层的网络在训练集和测试集上的误差都要高于20层的网络。注意网络退化、模型不
work和过拟合三者的区别,这三者是不一样的:
| 概念 | 解释 |
|---|---|
| 网络退化 | 深层的神经网络表现更差,在训练集和测试集上的效果都不如浅层网络 |
| 过拟合 | 模型在训练集上效果很好,但是在测试集上效果较差 |
| 模型不work | 模型在训练集上就没有出现收敛 |
我们在上图中可以看到,56层的模型在训练集上收敛了,因此模型是work的,但是却比20层的网络效果差,这就是网络退化现象。而且网络退化现象通过增加训练的迭代次数是无法解决的,并不是由训练“早停”导致的。
ResNet就解决了网络退化的现象,这样就可以通过增加网络深度来提升模型效果了。用作者的话说就是"can gain accuracy fromconsiderably increased depth. "(可以从显着增加的网络深度中获得准确性的提升。)
1. ResNet的大体思路
前面说了,简单的通过堆叠层数来加深网络会出现“网络退化”的问题。对于简单的层数堆叠,作者认为网络退化问题说明深层的网络不好被优化,随着网络加深,网络的收敛速度指数级下降,这就导致了训练集上的准确率较低,测试集上的效果固然也不好。
我们可以先回顾一下VGG模型,VGG19如下图左边所示。可以看到该网络由很多个模块(block)组成,每个block颜色相同。
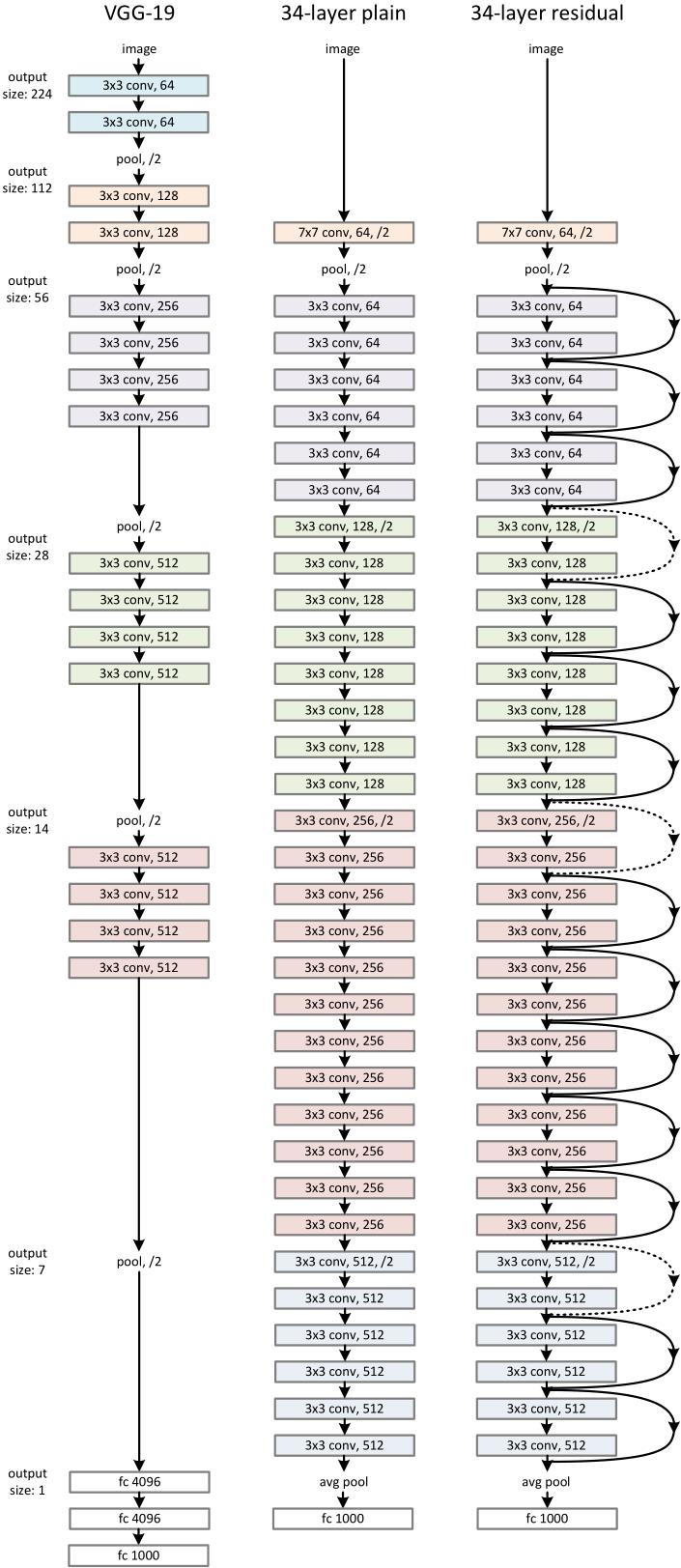
但是,我们简单的增加block的数量来使得网络加深会出现网络退化现象,所以作者使用“残差模块”来代替原有的block。残差模块如下图所示:
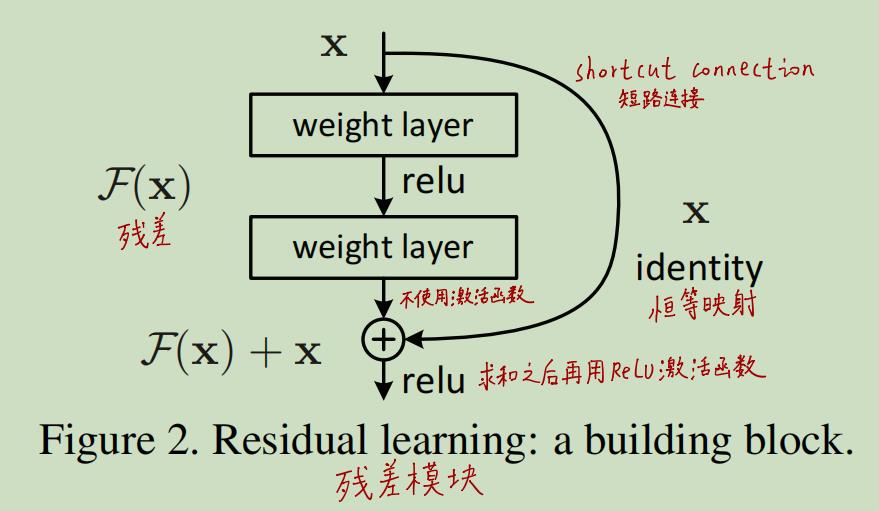
作者是这么考虑的:对于其他模型而言,每个block都学习到了一个底层的函数映射H(x),而现在的残差模块只用学习F(x),其中H(x) := F(x) + x。即残差模块只需要学习原输入x相较于底层映射H(x)的残差。理想情况下若原输入X已经够好,则只需要将残差F(x)置为零即可。
作者认为虽然block既能拟合底层映射H(x),也能拟合残差F(x),但拟合残差的难度更低一些。另外,该残差模块有几点很值得专门拎出来说一下:
(1)具有恒等映射Identity Mapping
恒等映射其实就是上图中右边的分支,说白了就是把原输入x原封不动的映射下来,然后与另一个分支拟合的残差F(x)相加。
恒等映射看起来非常简单,但却很重要,这是ResNet的核心。我们考虑下,为什么网络越深表现越差这一现象是反直觉的?因为我们认为网络越深,模型的效果最起码也能和浅层网络相当,只要把深层网络的前一部分与浅层网络保持一致,后一部分保持浅层网络的输出不变不就好了。但事实却是深层网络的效果比浅层网络要差,这就说明要让网络学习到“保持不变”(即恒等映射)是很难的。于是我们手动的给模块加一路恒等映射。
(2)残差模块并没有增加网络的参数
我们看到,残差模块相较于普通模块只是增加了一路shortcut connection,使用的是恒等映射(identity mapping),而恒等映射本身是不需要训练参数的。因此网络的复杂度并没有增加。比如在下图中的中间和右边的模型,中间的模型是普通模块的堆叠,右边的模型增加了残差模块,二者参数量相同。
2. ResNet网络结构
按照上面的思路,作者构建了ResNet18/34/50/101/152,后面的数字代表具有参数的层的数量。如ResNet34的结构如下图右边所示:
(相较于VGG,ResNet把max pooling换成了步长为2的卷积层,把最后的全连接层换成了全局平均池化层GAP,大大节省了参数量)
shortcut connection时F(x)与x的维度不同怎么办?
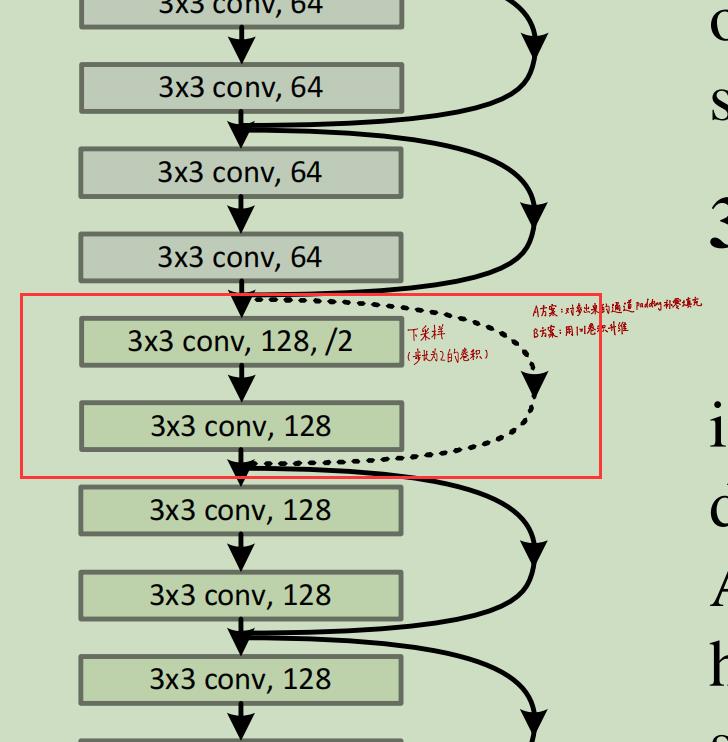
残差模块拟合的是残差F(x),最终还要和identity mapping那一路的x相加,即H(x) := F(x) + x.这就要求F(x)和x维度应该相同,这样才能做到逐元素的相加。上图中右侧的模型为ResNet34,其中的实线是同一个block之间的shortcut connection,所以F(x)和x的维度相同,可以直接相加。而虚线代表不同block之间的shortcut connection,此时F(x)和x维度不同【因为下采样导致F(x)的通道数(channel)是x的两倍】,此时要将x的维度和F(x)补齐。这里有两种思路:
(1)直接在x后面补几个全0的channel【未引入参数】
(2)对x使用1x1卷积升维处理【增加了参数量】
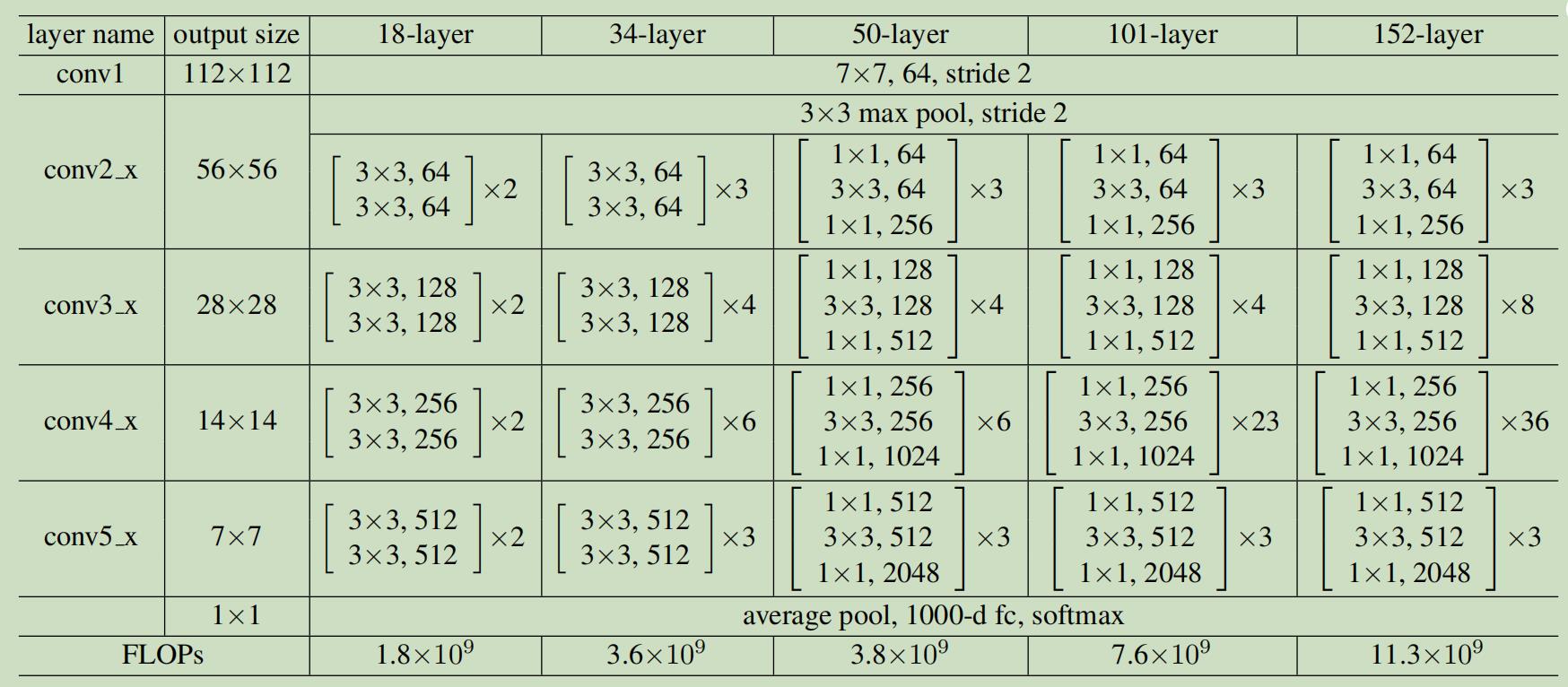
其中第二种的效果会更好一些,但提升不显著,这在之后会讨论。其余的ResNet网络结构详细设置如下图所示:
3. ResNet效果
3.1 ResNet是否解决了网络退化问题
我们说了ResNet主要目的就是为了解决网络退化问题,来看看实验结果如何:
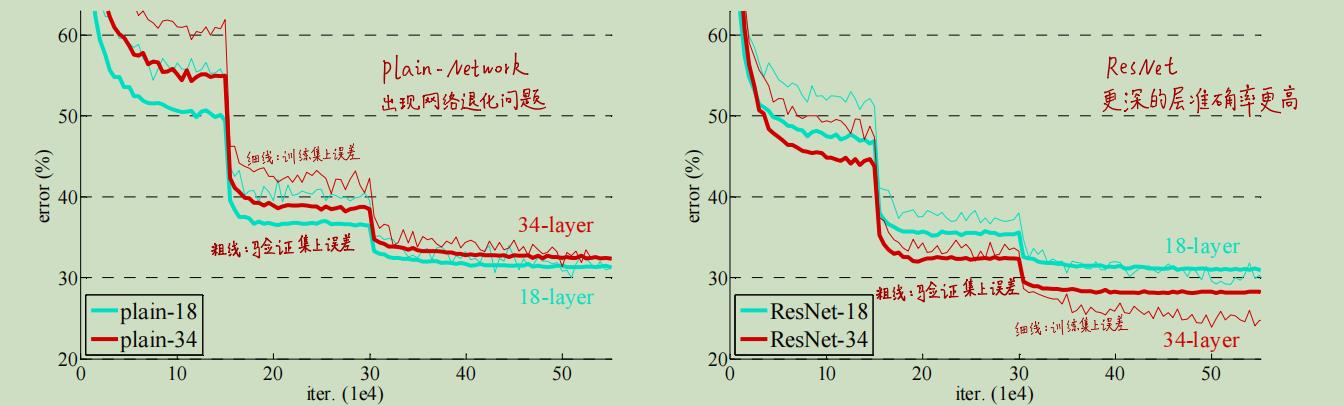
如图,作者对比了18层的浅层网络和34层的深层网络,左边的是普通的block堆叠,右边是使用了ResNet残差模块。作者在ImageNet上做实验,细线代表训练集上的误差,粗线代表验证集上的误差。
在左图中,34层网络的表现要比18层的差,而右图中显示,随着网络层数的加深,模型在训练集和验证集上都有更小的错误率。即网络退化问题被解决了!我们现在可以通过增加网络的深度来享受网络性能带来的提升啦!!(另外我们还可以看出ResNet在初期的收敛速度更快)
3.2 关于Shortcut Connection的对比实验
作者提出的残差模块如下图所示:
左边这一路是拟合残差F(x),右边这一路为shortcut connection,我们之前右边这一路使用的是identity mapping(恒等映射),即直接把x映射下来。实际上shortcut connection还有多种处理方法。
方案A:所有的shortcut connection都用identity mapping,即我们之前说的恒等映射,当遇到升维时直接补0.【这么处理未引入额外参数】
方案B:所有的shortcut connection都用identity mapping,即我们之前说的恒等映射,当遇到升维时使用1x1卷积.【这么处理在1x1卷积进行升维时引入了参数】
方案C:所有的shortcut connection都用1x1卷积【这么处理引入了很多额外的参数】
三种方案的对比实验如下:
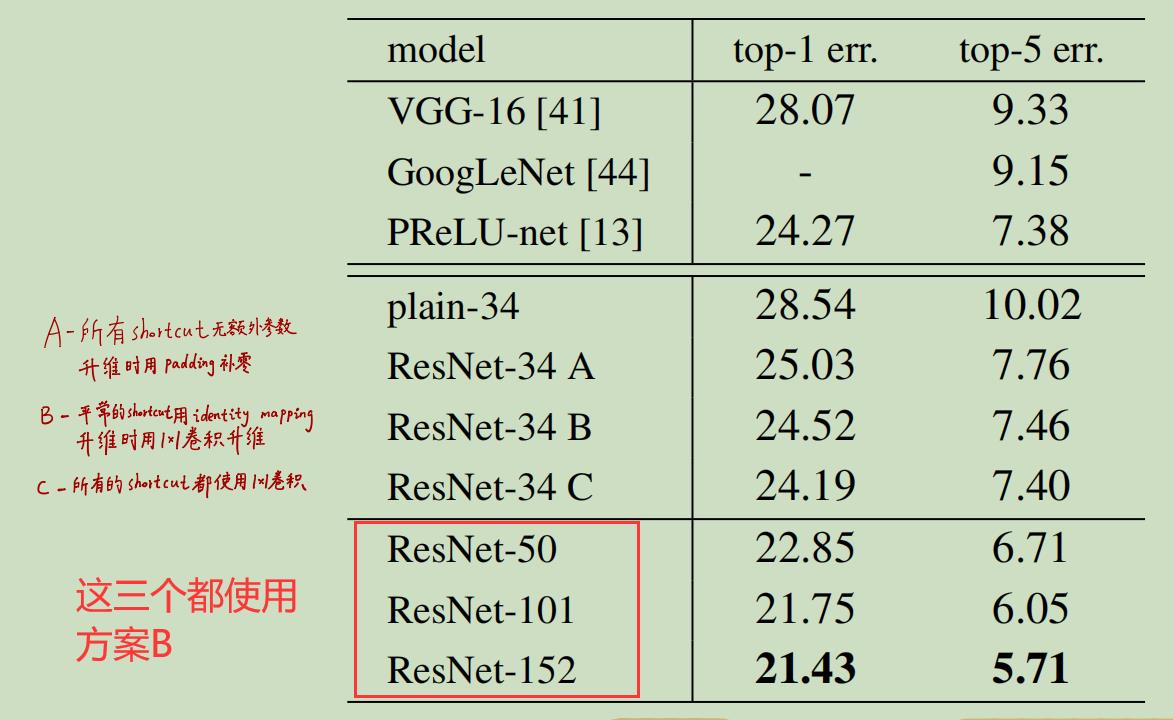
我们可以看出:
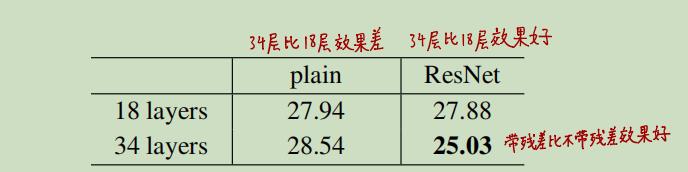
(1)ResNet-34的性能要比VGG16和GoogleNet好,也要比普通的34层深层网络好;
(2)网络深度相同时,A方案性能最差,B方案性能一般,C方案性能最好;(但不要忘了A方案未引入参数,而C方案引入了大量参数,当网络模型加深时参数量成倍增加)
(3)使用了ResNet后,网络越深,模型效果越好。
这里需要强调一点:虽然C方案要比B和A好,但这并不是解决“网络退化”问题的关键,网络退化模型得以解决的关键是引入了identity mapping这种shortcut connection(即方案A),而B和和C只是对A的改进,而且性能的提升并不显著,C方案却引入了大量参数,并不算经济。
3.3 对于更深层的ResNet使用Bottleneck结构
当ResNet层数变多时(如ResNet50/101/152),作者使用了如下图右边所示的Bottleneck结构:
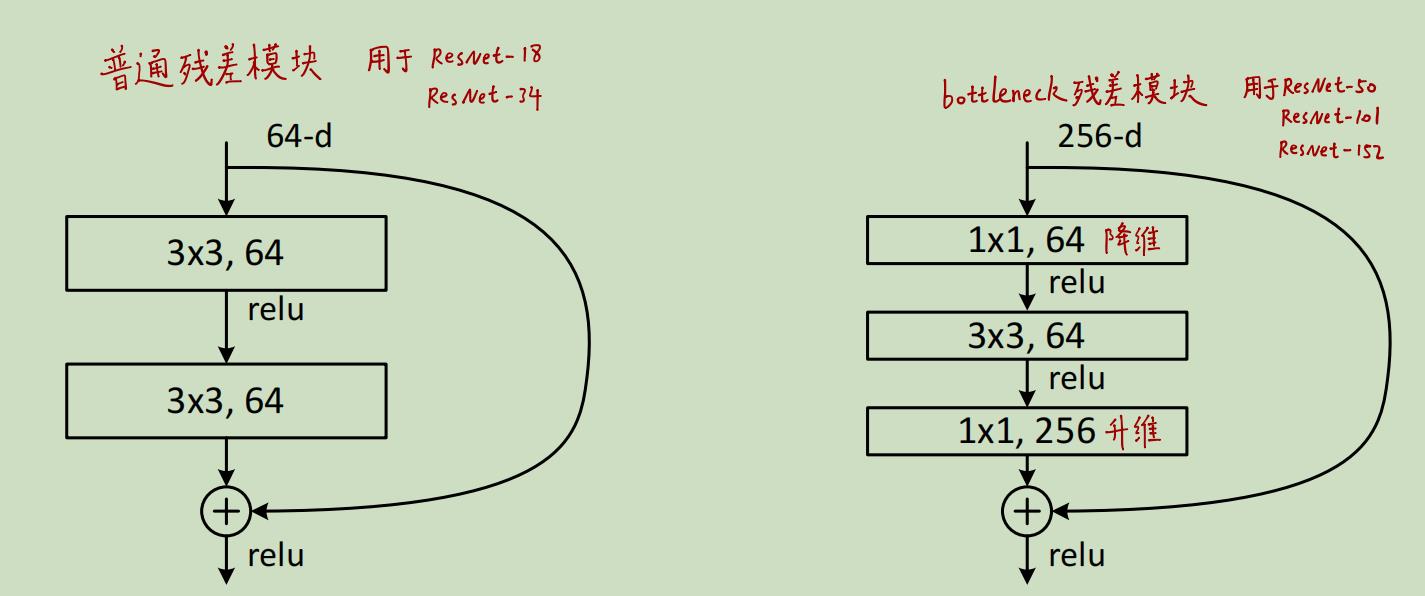
这么做可以减少参数量和计算量,节约训练时间。我们可以看到Bottleneck先使用1x1卷积对channel进行降维,然后使用3x3的卷积拟合残差,最后再使用1x1的卷积进行升维以保持和x的channel数一致。有点类似于沙漏,两边大中间小,所以被称为"bottleneck"(瓶颈)
3.4 ResNet网络可以无限深吗?
既然ResNet成功解决了网络退化的问题,可以享受加深网络来提升模型性能,那ResNet网络可以无限深吗?1000层的网络是否要比100层的网络效果更好?
作者在CIFAR-10数据集上对普通的20、32、44、56层网络和ResNet的22、32、44、56、110和1202层网络进行对比实验,结果如下图所示:
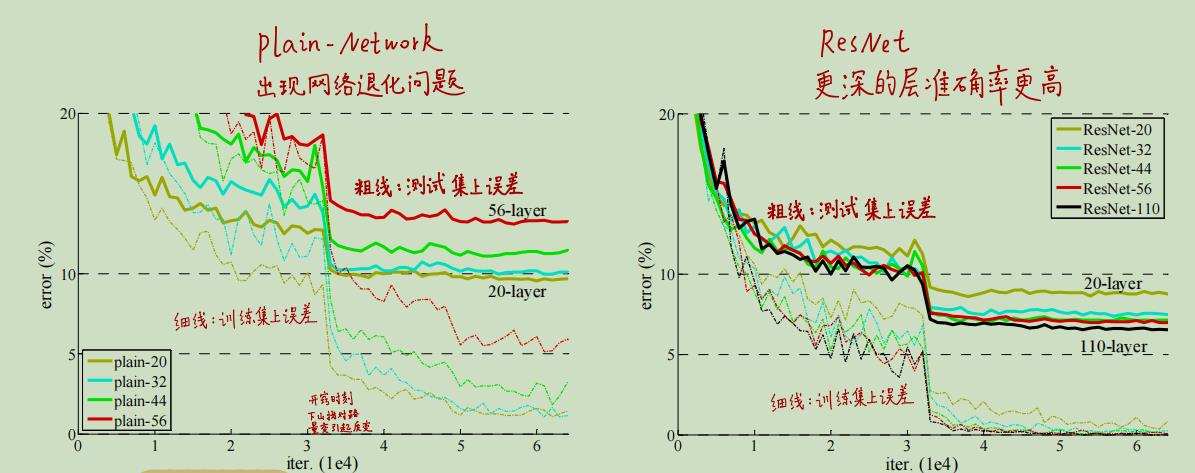
对比普通网络和ResNet,虚线为训练集上的误差,实线为测试集上的误差。效果和之前的类似,可以看出ResNet解决了模型退化的问题:网络越深,模型效果越好。那么网络可以无限深吗?
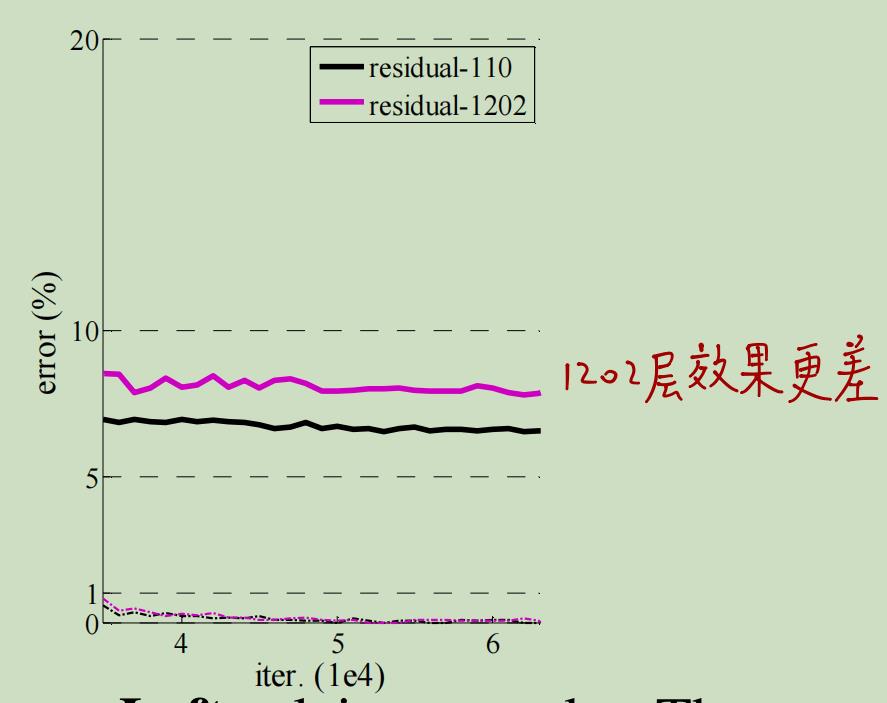
作者又对比了ResNet-110和ResNet-1202,这里值得一提的是作者在训练1202层的网络时并没有遇到优化困难的问题,网络依旧收敛且易于优化。实验结果如上图。
可以看到二者在训练集上都收敛,且训练集上的误差都很小,说明两个模型都是work的。且两个模型在测试集上的表现都不错。但是!!ResNet-1202在测试集上的表现不如ResNet-110。
这就说明,即使ResNet解决了网络退化的问题,网络仍然不能无限加深。至于为什么ResNet-1202的性能不如ResNet-110,作者解释是因为过拟合。毕竟ResNet-1202网络太深,参数过于多,而CIFAR-10只是一个很小的toy数据集。
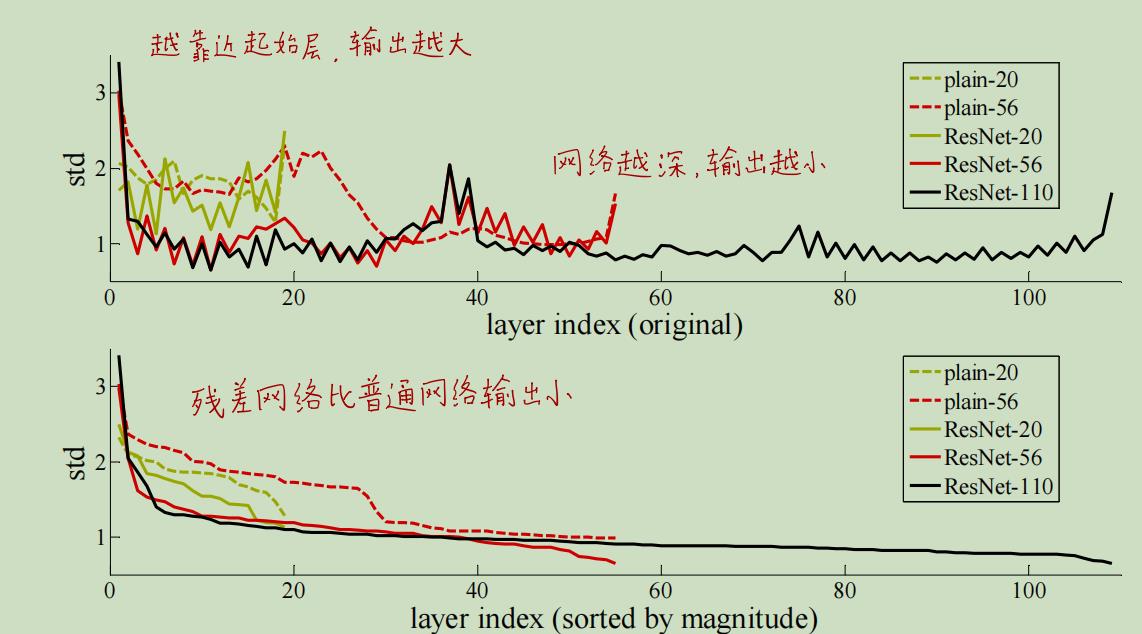
3.5 ResNet每层的响应(Response)要比普通网络小
作者还发现,ResNet的每层网络输出的响应值小于普通网络,这也比较好理解,毕竟ResNet每层网络是在拟合残差F(x),而非普通网络是在拟合底层映射H(x)。H(x):=F(x)+x。
以上就是ResNet的一些实验和重要结论。ResNet是网络结构,主要用来提取深层特征,因此可以泛化于很多视觉任务上。ResNet泛化的视觉模型在2015年的主要赛道全部夺冠,获得了ImageNet2015的分类、定位和目标检测以及COCO的目标检测和语义分割的冠军。
4. 两个我还没弄明白的技术细节
实际上在读论文时我还有两个细节问题没弄明白:
4.1 关于F(x)+x时给x进行升维时的操作
作者的处理思路是拟合残差,H(x):=F(x)+x,需要保证F(x)和x的维度相同。但是在下面的图中,当遇到下采样时F(x)输出的feature map的size应该变成了x的1/2,channel变成了x的2倍吧。为什么论文中只说给x缺少的channel补0让二者的维度相同呢?我咋感觉即使在缺少的channel上补0他俩feature map还是在size上不一样大。
4.2 Bottleneck结构
对于ResNet50/101/152这些深层网络而言,使用了bottleneck结构减少参数。但图中为什么input是256-d,按照table 1里的配置不应该还是64-d吗?
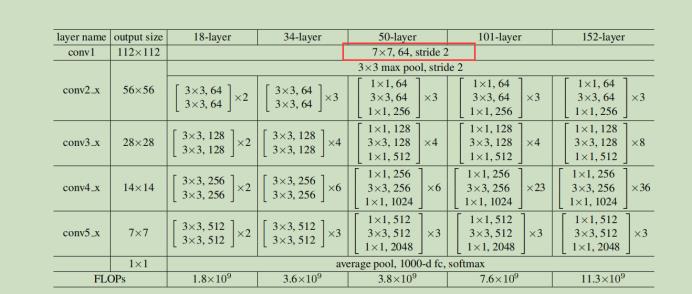
上图中的table显示ResNet50/101/152一开始都使用了64个7x7的卷积层进行处理,因此输出的feature map 的channel为64,紧接着用max pooling进行降维,降维后的feature map的size减半,但channel数不变,还是64。可为什么论文中的bottleneck的input为256维的呢??
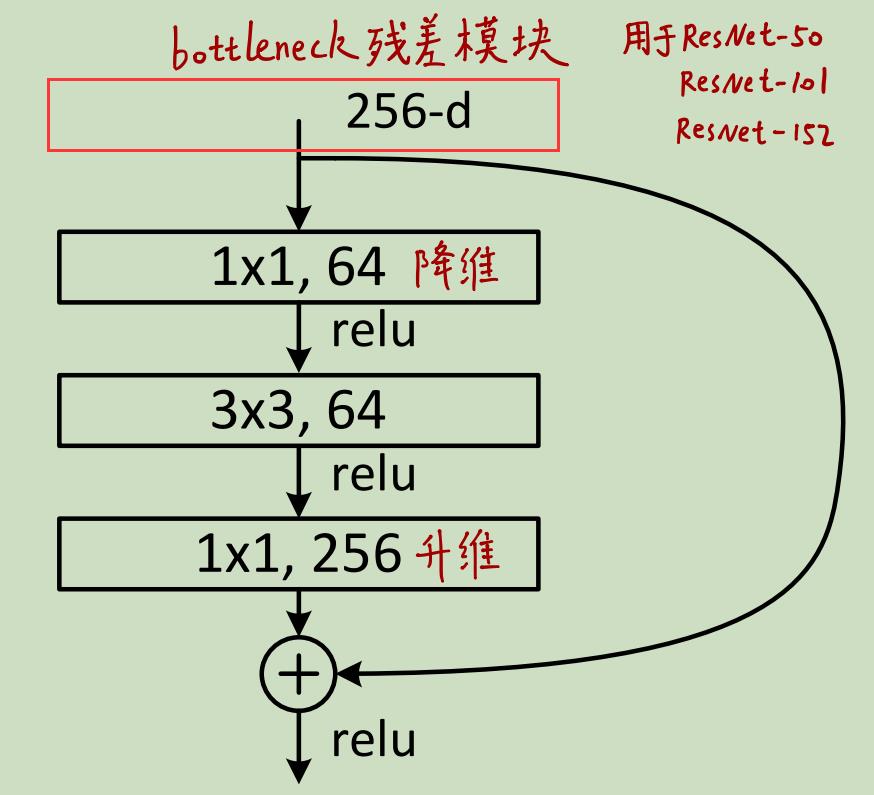
我想了很久还是没想明白,也许是不同的代码有不同的实现吧,又或许像这种技术实现上的细节根本没有纠结的必要?
以上两个问题如果有朋友知道请不吝赐教,周末愉快:)
(希望我的毕设能顺利完成!)
以上是关于ResNetResNet论文学习笔记的主要内容,如果未能解决你的问题,请参考以下文章