Policy Evaluation收敛性炼丹与数学家
Posted 3A是个坏同志
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Policy Evaluation收敛性炼丹与数学家相关的知识,希望对你有一定的参考价值。
完美的学习算法
昨天和同学在群里讨论DRL里bad case的问题。突然有同学提出观点:“bad case其实并不存在,因为一些算法已经理论证明了具有唯一极值点,再加上一些平滑技巧指导优化器,就必然可以收敛。”
当听到这个观点时,我是一时语塞。因为当前深度学习研究的最大问题就是,花了很大资源训练的千万参数神经网络根本不work,一切都白白浪费。因此才有NAS之类方法尝试根据一些训练初期的动力学性质调整结构,找出合适的超参数,但也是效果平平。如果真有一个这么完美的学习算法,那岂不是任何问题都能解决了?但根据我掌握的常识,这是不可能的。且不说学术界根本就没有这种工作。收敛性显然与网络结构和优化器有关,怎么会在无视这些设置的情况下证明出一个forall的结果呢?
我问他这个问题。他说:“根据证明,任务规模只与收敛速度有关,与是否收敛无关。只要接一个足够强的神经网络,就能……”
其实说到这我大概就知道他说的那个“证明”是怎么回事了。不过为了确认一下,我还是把他说的那篇“证明文章”要了过来,一看发现果然是那种车轱辘证明。
压缩映射与线性收敛速度
这篇“证明文章”是DRL的知名工作soft actor-critic。所谓收敛证明在16页paper里占了一页。其实粗读就可以看出,文章中的“收敛证明”是针对“tabular setting”,即离散形式。对于连续形式,文中指出需要使用神经网络对Policy Evaluation进行逼近,后面就转进到神经网络的实现细节上了。而Policy Evaluation能否收敛就决定了整个算法能否收敛,此处Policy Evaluation使用神经网络逼近,核心就转到了神经网络能否收敛。可神经网络一个任务一个样,它能不能收敛才是最核心的问题,然而文章并没有涉及。事实上,现在地球上没有学者能解答这个问题。
说到这,可能有同学在想:如果能保证离散情况下收敛就已经能解决很多问题了。可是你有没有想过,所谓“离散收敛连续不收敛”,里面的gap在哪里?在连续情形下不成立,离散情况下就会那么完美吗?当然不可能。
根据我的理解,SAC论文中收敛性的证明过程实际与传统策略迭代收敛的证明类似,只是它补充了他们工作带来的改动(最大熵项等)不影响原先证明的成立。所以我直接使用传统策略迭代收敛证明来说明问题——很多年前读到这个证明时我还是个中学生,当时就是一眼一过:哦,它能收敛。然后就没再管了。可是现在再去看就不禁会想到问题,就像那位同学说的一样,这个证明过程是压根不考虑任务的,只是基于强化学习的假设,(你要做的这个任务的)状态划分符合马尔可夫过程,然后直接给出证明:在这个马尔科夫链上迭代,策略估计必然收敛。然后基于策略估计收敛推出算法整体收敛。实际上做过强化学习的同学都会有感觉,策略估计是非常关键的一步,也是非常容易出错的一步(动不动就训不动了)。它在压根不考虑任务的情况下,轻飘飘地就给出了收敛的结论,而且是“线性速度收敛”,这么好的事,它到底是怎么做的?它证明的“收敛”和我们说的是一回事吗?
对于策略估计的证明有一点复杂。我们尽量聚焦于需要关注的两个关键点:
1. 贝尔曼方程是个压缩映射
2. 如果是压缩映射,服从压缩映射定理,以线性速度收敛到唯一不动点
这个证明网上的解释有很多,但大多不直观。我用一个我的直观理解来不太严格地解释这两点。对于第一点,原证明过程为:
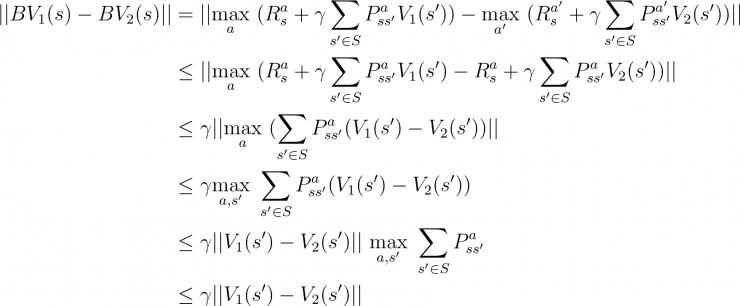
第一步中, 与
与  分别为
分别为 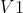 与
与 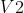 下的最优动作。第二步中,将后项放到前项的
下的最优动作。第二步中,将后项放到前项的 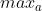 中,相当于选择了一个在 下更不好的动作。因此后项价值变小,整体变大,引入了不等号。把这个过程反过来思考就可以理解,应用贝尔曼算子后值会被压缩的关键原因就在于更优的动作会被更频繁选择(更优的策略会被更频繁应用),也就是Exploitation。实际做过强化学习的都知道,只有Exploitation不可能那么完美。
中,相当于选择了一个在 下更不好的动作。因此后项价值变小,整体变大,引入了不等号。把这个过程反过来思考就可以理解,应用贝尔曼算子后值会被压缩的关键原因就在于更优的动作会被更频繁选择(更优的策略会被更频繁应用),也就是Exploitation。实际做过强化学习的都知道,只有Exploitation不可能那么完美。
那该证明中是怎么处理Exploration的呢?这是在另一个部分,证明策略提升的过程:
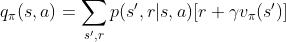
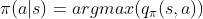
说白了就是遍历每个状态,然后又在每个状态下,遍历每个动作,分别计算被遍历到的状态下每个动作对应的价值 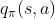 ,取使得价值最大的动作作为当前状态的最新策略——说到这你就知道为啥他这“证明”不用考虑任务而且只能用于离散情况了。因为他就是暴力把所有情况都看了一遍,连续的你就没法都看一遍了啊;P
,取使得价值最大的动作作为当前状态的最新策略——说到这你就知道为啥他这“证明”不用考虑任务而且只能用于离散情况了。因为他就是暴力把所有情况都看了一遍,连续的你就没法都看一遍了啊;P
再看看压缩映射定理中的所谓线性收敛速度:
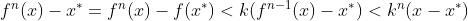
这个就很好理解了。寻找不动点的迭代过程是在函数 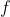 的定义域上的(可以理解为状态空间或者策略空间)。这个所谓“线性收敛速度”给出的是一个上界,这个“线性复杂度”的n(式中的
的定义域上的(可以理解为状态空间或者策略空间)。这个所谓“线性收敛速度”给出的是一个上界,这个“线性复杂度”的n(式中的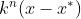 )实际等同于定义域大小,即问题规模,虽然说起来是线性,但计算出这个组合数的过程是个指数!贴着这个上界实现的“强化学习算法”说白了和把“所有组合都试一遍就能找到最大最小值”没啥区别,所以这个上界对于大部分问题都没有实际意义。
)实际等同于定义域大小,即问题规模,虽然说起来是线性,但计算出这个组合数的过程是个指数!贴着这个上界实现的“强化学习算法”说白了和把“所有组合都试一遍就能找到最大最小值”没啥区别,所以这个上界对于大部分问题都没有实际意义。
相信大家都记得很多年前AI攻破国际象棋后,很多下围棋的人说计算机永远不可能攻破围棋,因为围棋的状态数比全宇宙粒子数都多。他们把状态数等同于问题难度,就和这个式子中的所谓“线性上界”没区别。但我们真的需要遍历每个状态吗?使用专门设计的算法,alphago只探测了状态空间的很小一部分,就成为了世界第一。这也是强化学习的核心:如何设计算法更高效地探测状态空间、更新策略。可能我们设计的算法不是线性复杂度,但我们的算法却比这个上界更快,因为二者的n根本就是不一样的!我们关心复杂度的目的是让它最后跑起来更快,而并非是那个式子表面上是个什么形状。这也是为什么我说前段时间很多OIer在空间刷屏的近似多项式最大流算法并不会对OI有什么改变(笑),因为里面用的技巧过于复杂,即使实现出来真实速度大概也不会快于当前主流方法。我们关心的“收敛性”,也是我们设计的这个探测算法是否能够收敛,而不是在考虑“把所有情况都看一遍”这个傻方法。如果有人看了这个看起来很高深的证明,就感觉所有强化学习算法都能收敛、所有强化学习算法都是线性复杂度,只能说他根本没搞清楚自己在干嘛。
数学家的炼丹
虽然那位同学不是数学工作者,我也不是数学工作者。但很多数学工作者也犯过类似的错误。相信大家都看过“计算机的终点是数学”这种说法,然后对搞数学的人很迷信。但真学数学的人就一定明白自己在干嘛吗?我看不是。不管是什么领域,真正懂的人都是很少的。我和很多学数学比较入魔的同学交流过类似神经网络的优化问题,但我非常坏,没告诉他我说的是神经网络,很多人就被我骗了,斩钉截铁地给我一个高深的手法:加这个约束,加那个平滑,然后根据某个高深的理论,就肯定能收敛。可是为什么机器学习界从来没有这种完美的方法,是因为搞计算机的对这些数学理论都一窍不通吗?其实道理很简单,任何东西都不是free的。只要加了约束,就必然会限制表达能力,限制了表达能力,就会影响梯度分布——就算待优化的流形再平滑,但大部分区域梯度都是0,在实际数据上没法work,又有什么用呢?他们之所以会犯这种错误,其实也是不明白自己在干嘛——我不说“神经网络”这个名词,光凭符号描述,他们就根本不知道面前的这个复杂系统到底是什么样的,从来没实现过自己的算法,不借助计算机的力量去看一看、试一试,只会用纸笔和脑子,这样是没法摸到复杂系统的形状的。这也是为什么那位同学能那么坚定地说出“存在完美学习算法”这种匪夷所思的结论——因为他也一样,压根没试过这些算法,没观察过训练过程,自己一想当然,就张冠李戴了。
还有一些同学是只能看到自己眼前的一点东西,搞一些真空中的球形理论,然后鄙视搞机器学习人,说他们都是“炼丹”。可炼丹是基于一些生产环境目前用不了的trick把效果提了几个点,你搞的是基于一些不现实的假设搞出的一些不知道什么时候才能用上的理论,谁又比谁高多少呢?在我看来,这些一瓶不满半瓶晃的数学学生搞的就是数学界的“炼丹”,和工业界胡写代码满嘴设计模式,机器学习界乱搭模型炼丹的计算机学生没什么区别。
我认识的一些同学,CMO获奖之后去了姚班,从此戴上了痛苦面具——自己数学那么好,搞数学不就完了,学这些计算机的东西干嘛?相信很多喜爱数学的同学都有这种想法。可是我觉得学习很重要的一点就是对知识要谦虚,永远保持好奇。很多人看了很多书和论文,记住了一些表面知识和吓人的术语,可是却没有深刻的理解它们后面的涵义。这时候编程其实是一个认识到自己错误的很好工具,因为你能用满嘴的术语骗过身边的同学,却骗不过计算机。即使是纯数学的理论,也可以用coq等定理证明器辅助学习。但你要是动手能力不高,遇到编程这类一点点困难就往后缩,长此以往,就很难学会真正的知识了。
我相信,在现在,一个不会写程序的“数学家”,成就永远无法超过计算机科学家。因为面对实际的复杂问题,很多东西不借助计算机的帮助,是根本无法看到的。认为数学不需要计算机、甚至鄙视计算机的人,其实只是被书本知识打倒,然后就臣服于它,可却没想到,从此被一叶障目,看不到背后更大的世界。
以上是关于Policy Evaluation收敛性炼丹与数学家的主要内容,如果未能解决你的问题,请参考以下文章