Elasticsearch:Reindex API 使用和故障排除的 3 个实践
Posted Elastic 中国社区官方博客
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Elasticsearch:Reindex API 使用和故障排除的 3 个实践相关的知识,希望对你有一定的参考价值。

使用 Elasticsearch 时,你可能希望将数据从一个索引移动到另一个索引,甚至从一个 Elasticsearch 集群移动到另一个 Elasticsearch 集群。 可以使用多种方法来实现这个,Reindex API 就是其中之一。
在这篇博文中,我将讨论 reindex API、如何知道 API 是否正常工作、可能导致潜在故障的原因以及如何排除故障。
在这篇博文结束时,你将了解 Reindex API 的选项以及如何自信地运行它。
Reindex API 是跨多个用例的最有用的 API 之一:
- 在集群之间传输数据(从远程集群重新索引)
- 重新定义、更改和/或更新映射
- 通过摄入管道(ingest pipeline)处理和索引
- 清除已删除的文档以回收存储空间
- 通过查询过滤器将大索引分成更小的组
在中型或大型索引中运行 reindex API 时,完整的 reindex 可能需要超过 120 秒,这意味着你将没有 reindex API 最终响应,你不知道它何时完成,是否有效,或者 如果有失败。
让我们来看看!
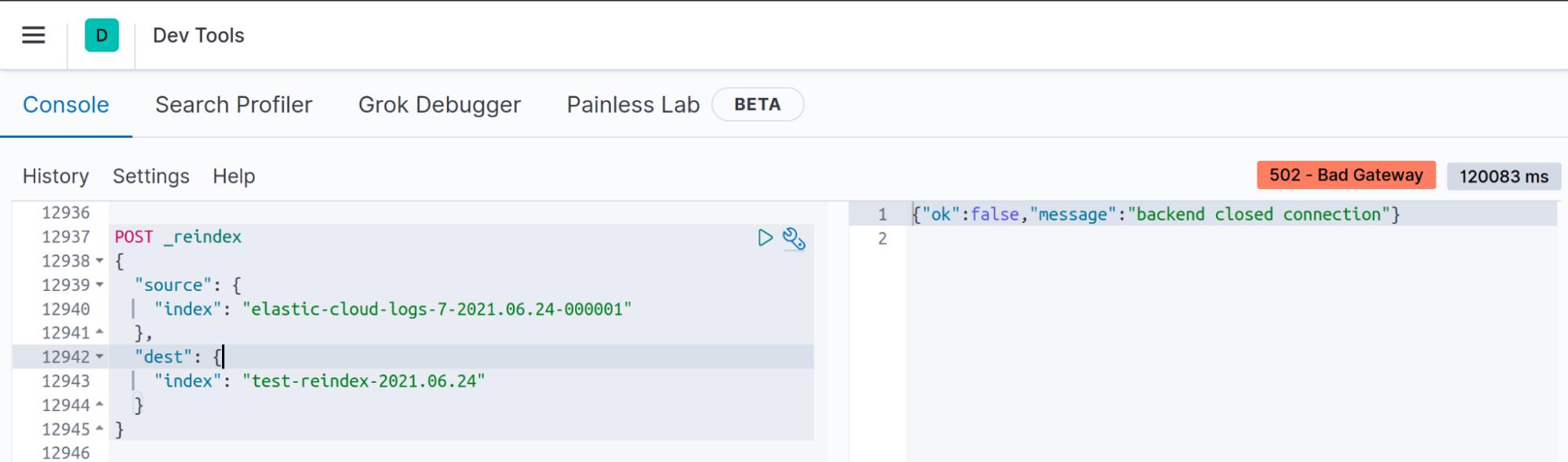
症状: In Kibana Dev tools, “Backend closed connection”
当你使用中型或大型索引执行 reindex API 时,客户端和 Elasticsearch 之间的连接会超时,但这并不意味着不会执行 reindex。
问题
你的客户端将在 N 秒后关闭非活动套接字,例如在 Kibana 中,如果 reindex 操作无法在 120 秒内完成(v7.13 中的默认 server.socketTimeout 值),你将看到 “backend closed connection” 消息。
解决方案 #1 - 获取集群上运行的任务列表
这不是一个真正的问题,即使你在 Kibana 中有此消息,Elasticsearch 也在后台运行重新索引 API。
你可以跟踪 reindex API 的执行,并使用 _task API 查看所有指标:
GET _tasks?actions=*reindex&wait_for_completion=false&detailed此 API 将向你显示当前在 Elasticsearch 集群中运行的所有 reindex API,如果你在此列表中没有看到你的 reindex API,则表示它已经完成。 如果大家想找一个鲜活的例子的话,那么你可以阅读我之前的文章 “Elasticsearch:如何分析和优化 Elastic 部署的存储空间”。在那篇文章中,有一个叫做 reindex 的操作。由于索引比较大,reindex 需要较长的时间。你完全可以看到上面所描述的这个现象。

正如你在图片上看到的,我们有关于创建、更新甚至冲突的文档的详细信息。
解决方案 #2 - 将 reindex 结果存储在 _tasks
如果你知道 reindex 操作将花费超过 120 秒(120 秒是 Kibana 开发工具超时),你可以使用查询参数 wait_for_completion=false 存储 reindex API 结果,这将允许你在结束时获取状态 使用 _task API 的 reindex API(你也可以从 “.tasks” 索引中获取文档,如 wait_for_completion=false 文档中所述)。
POST _reindex?wait_for_completion=false
"conflicts": "proceed",
"source":
"index": "<source-index-name>"
,
"dest":
"index": "<dest-index-name>"
当你使用 “wait_for_completion=false” 执行重新索引时,响应将类似于:
"task" : "a9Aa_I_ZSl-4bjR5vZLnSA:247906"
你需要保留此处提供的任务以搜索重新索引结果(你将看到创建的文档数量、冲突甚至错误,完成后你将看到花费的时间、批次数……等):
GET _tasks/a9Aa_I_ZSl-4bjR5vZLnSA:247906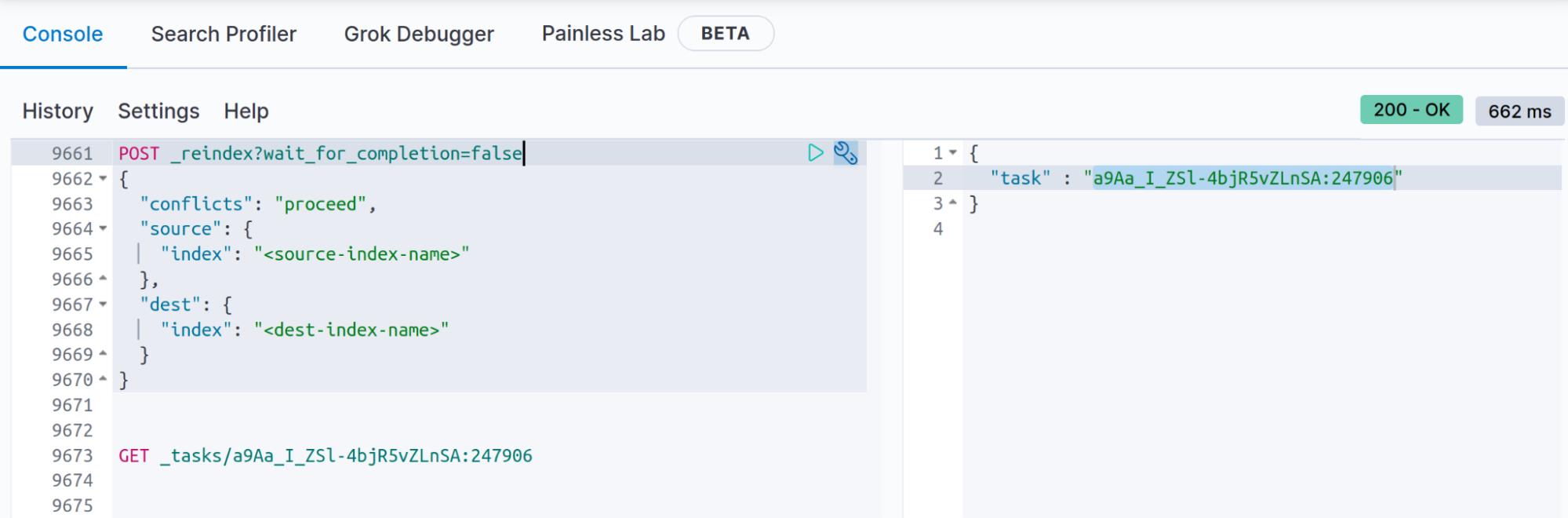
症状:Your reindex API is not in the _task API list.
如果使用上面提到的 API 找不到你的 reindex API 操作,可能是不同的问题,我们将一一进行。
问题
如果 reindex API 的操作没有被列出,则意味着它已完成,因为没有更多文档要重新索引或因为出现错误。
我们将使用 _cat count API 来查看存储在两个索引上的文档数量,如果这个数字不同,则意味着你的 reindex API 执行以某种方式失败。
GET _cat/count/<source-index-name>?h=count
GET _cat/count/<dest-index-name>?h=count你需要将 <source-index-name> / <dest-index-name> 替换为你在重新索引 API 中使用的索引名称
解决方案 #1 - 这是一个冲突问题
最常见的错误之一是我们有冲突,默认情况下,如果存在冲突,reindex API 将中止。
现在我们有两个选择:
- 将设置 “conflicts” 设置为 “proceed”,这将允许 reindex API 忽略无法索引的文档并索引其他文档。
- 或者我们可以选择修复冲突(conflicts),以便我们可以 reindex 所有文档。
带有冲突设置的第一个选项将如下所示:
POST _reindex
"conflicts": "proceed",
"source":
"index": "<source-index-name>"
,
"dest":
"index": "<dest-index-name>"
或者在第二个选项中,我们将搜索并修复产生冲突的错误:
- 让你避免此问题的最佳实践是定义一个 mapping 或者模板
- 如果即使在定义映射或模板之后问题仍然存在,则表示某些文档无法被索引并且错误
PUT /_cluster/settings
"transient":
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":"DEBUG"
- 启用 logger 后,我们需要再执行一次 reindex API,如果可能的话,使用设置 “conflicts” 为 “proceed”,因为你有多个字段在源索引和目标索引之间存在冲突。
- 现在重新索引 API 正在运行,我们将 grep/search “failed to execute bulk item” 或 “MapperParsingException”
failed to execute bulk item (index) index [my-dest-index-00001][_doc][11], source[
"test-field": "ABC"
或者:
"org.elasticsearch.index.mapper.MapperParsingException: failed to parse field [test-field] of type [long] in document with id '11'. Preview of field's value: 'ABC'",
"at org.elasticsearch.index.mapper.FieldMapper.parse(FieldMapper.java:216) ~[elasticsearch-7.13.4.jar:7.13.4]",有了这个堆栈跟踪,我们已经有足够的信息来理解冲突是什么,在我的 reindex API 中,目标索引有一个名为 [test-field] 的字段,类型为 [long],并且 reindex API 尝试将此字段设置为字符串 ' ABC'('ABC' 将替换为你自己的内容字段)。
在 Elasticsearch 中, 你可以定义字段数据类型,你可以在索引创建期间或使用 templates 进行设置。 创建索引后,你将无法更改类型,你需要先删除目标索引,然后使用之前提供的选项设置新的固定映射。
- 修复错误后,请记住将 logger 移动到不太详细的模式:
PUT /_cluster/settings
"transient":
"logger.org.elasticsearch.action.bulk.TransportShardBulkAction":NULL
解决方案 #2 - You have no conflict errors, but the reindex continues failing
如果在 reindex 执行期间,你在 Elasticsearch 日志中找到此跟踪:
'search_phase_execution_exception', 'No search context found for id [....]')可能是不同的原因:
- 集群存在一些不稳定问题,并且在 reindex 执行期间某些数据节点已重新启动或已经变成不可用。
如果这是原因,在运行 reindex 之前,请确保你的集群稳定并且所有数据节点都运行良好。
- 如果您正在远程执行重新索引操作,并且你知道节点之间的网络不可靠:
快照 API 是一个不错的选择(如本文结尾所述)。
- 我们可以尝试手动对 reindex API 进行切片,此操作将允许你将请求过程分成更小的部分(此选项是当我们在同一集群中使用 reindex API 时)。
- 如果你的 Elasticsearch 集群存在过度分片问题、高资源利用率或垃圾收集问题,我们可能会在滚动搜索查询期间出现超时。 默认滚动超时值为 5 分钟,因此你可以尝试使用更高值的 reindex API 上的滚动设置。
POST _reindex?scroll=2h
"source":
"index": "<source-index-name>"
,
"dest":
"index": "<dest-index-name>"
症状:在 Elasticsearch 日志中出现 "Node not connected"
我们始终建议在集群稳定且状态为绿色的情况下运行重新索引 API,并且集群将需要足够的容量来运行搜索和索引操作。
问题
NodeNotConnectedException[[node-name][inet[ip:9300]] Node not connected]; ]如果你的日志中出现此错误,则意味着你的集群存在稳定性和连接性问题,而且失败的不仅仅是重新索引 API。
但是让我们假设你知道连接问题,但你需要运行 reindex API。
解决方案
修复连接问题。
但是让我们想象一下,我们知道连接问题,但是你需要运行 reindex API,我们可以减少失败的可能性,但这不是修复方法,它不会在所有不同的情况下工作。
- 将源索引或目标索引(主索引或副本)的分片移出存在连接问题的节点。 使用分配过滤 API 移动分片。
- 你还可以删除目标索引上的副本(仅在目标索引上),这将加快重新索引 API,如果 reindex 运行得更快,则面临失败的可能性更小。
PUT /<dest-index-name>/_settings
"index" :
"number_of_replicas" : 0
如果这两个操作都不允许你使 reindex API 成功,你需要先解决稳定性问题。
症状:日志中没有错误,但两个索引的文档数不匹配
有时重新索引 API 已完成,但源中的文档数与目标不匹配。
问题
如果我们尝试从一个目的地的多个来源 reindex(将多个索引合并为一个),问题可能出在你为这些文档分配的 _id 上。
假设我们有 2 个源索引:
- 索引 A,_id: 1 和消息:“Hello A”
- 索引 B,_id: 1 和消息:“Hello B”
C 中两个索引的合并,它将是:
- 索引 C,_id: 1 和消息:“Hello B”
两个文档都有相同的_id,所以最后一个索引它的文档将覆盖前一个。
解决方案
你有不同的选项作为摄取管道或在你的 reindex API 中使用 painless 脚本。 对于这篇博文,我们将在请求正文中使用带有 “painless” 的脚本选项。
这真的很简单,我们将只使用原始 _id 并添加源索引名称:
POST _reindex
"source":
"index": "<source-index-name>"
,
"dest":
"index": "<dest-index-name>"
,
"script":
"source": "ctx._id = ctx._id + '-' + ctx._index;"
如果我们以前面的例子为例:
- 索引 A,_id: 1 和消息:“Hello A”
- 索引 B,_id: 1 和消息:“Hello B”
C 中两个索引的合并,它将是:
- 索引 C,_id:1-A 和消息:“Hello A”
- 索引 C,_id:1-B 和消息:“Hello B”
结论
当你需要更改某些字段的格式时,Reindex API 是一个很好的选择。在这里,我们将列出一些使重新索引 API 尽可能顺利运行的关键方面:
- 为你的目标索引创建和定义映射(或模板)。
- 调整目标索引,以便 reindex API 可以尽快索引文档。我们有一个文档页面,其中包含允许你调整和加速索引的所有选项。https://www.elastic.co/guide/en/elasticsearch/reference/current/tune-for-indexing-speed.html
- 如果源索引是中型或大型,请定义设置 “wait_for_completion=false”,以便将重新索引 API 结果存储在 _tasks API 中。
- 将索引分成更小的组,你可以使用查询(范围、术语……等)定义不同的组,或者使用切片功能将请求分成更小的部分。
- 运行 reindex API 时稳定性是关键,reindex API 中涉及的索引需要处于绿色状态(最坏的情况是黄色状态),然后确保我们在数据节点中没有长 GarbageCollections,并且 CPU 和磁盘使用率具有正常值。
从 v7.11 开始,我们发布了一项新功能,可以让你避免 reindex 数据的需要,它被称为“运行时字段(runtime field)”。该 API 允许我们修复错误而无需重新索引数据,因为你可以在索引映射或搜索请求中定义运行时字段。这两个选项都允许你在摄取后灵活地更改文档的 schema,并生成仅作为搜索查询的一部分存在的字段。
运行时字段功能的一个很好的例子是能够创建一个与映射中已经存在的字段同名的运行时字段,运行时字段会隐藏映射字段,要对其进行测试,你只需按照提供的步骤进行操作这里。
你可以在我们的文档或入门博客文章中查看有关运行时字段的更多详细信息。
当你尝试将数据从一个集群移动到另一个集群时,你可以使用快照恢复 API。使用快照,你可以更快地移动数据,因为集群不需要搜索,然后重新索引数据。你需要确保两个集群都可以访问同一个快照存储库,有关快照 API的更多详细信息。
我们已经介绍了重新索引常见问题和常见错误解决方案。此时,如果你无法解决问题,请随时与我们联系。我们在这里很乐意为你提供帮助!你可以通过 Elastic Discuss、Elastic Community Slack、咨询、培训和支持联系我们。
以上是关于Elasticsearch:Reindex API 使用和故障排除的 3 个实践的主要内容,如果未能解决你的问题,请参考以下文章
干货 | Elasticsearch Reindex性能提升10倍+实战(转)
java.lang.NoSuchMethodError: 'org.elasticsearch.core.TimeValue org.elasticsearch.index.reindex.BulkB
elasticsearch之解除索引只读问题filtersort解除索引最大查询数的限制reindex迁移数据boost条件权重控制