基于Pytorch的强化学习(DQN)之价值学习
Posted ZDDWLIG
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于Pytorch的强化学习(DQN)之价值学习相关的知识,希望对你有一定的参考价值。
目录
1. 引言
我们上次 最后提到了动作价值函数  ,它是与状态(state)、动作(action)和策略函数
,它是与状态(state)、动作(action)和策略函数 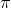 有关的概率分布函数,其中我们提到的它取最优策略后得到的最优动作价值函数
有关的概率分布函数,其中我们提到的它取最优策略后得到的最优动作价值函数 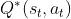 ,其中 的影响已经被消除,所以在给定状态下我们想要最优化
,其中 的影响已经被消除,所以在给定状态下我们想要最优化 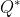 就是寻找最好的
就是寻找最好的 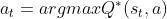 , 所谓价值学习就是使用神经网络DQN来拟合函数
, 所谓价值学习就是使用神经网络DQN来拟合函数 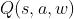 ,其中
,其中  是观测到的状态是网络的输入,
是观测到的状态是网络的输入,  是agent需要做出的动作,是网络的输出值,
是agent需要做出的动作,是网络的输出值,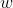 表示网络的参数,下面我们来介绍强化学习(DQN)。
表示网络的参数,下面我们来介绍强化学习(DQN)。
2. DQN
我们刚刚提到我们需要状态作为输入值,在许多情况下当前状态是以图片的形式出现,我们之前讲过:CNN是一种很好的处理图片信息的网络,所以我们将state输入卷积层(Conv)提取特征信息(feature),再通过全连接层(Dense)计算不同动作下的得分得到reward,输出一个奖励向量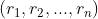 , agent只需要选取这个向量中的最大的分量对应的action就可以做出决策了。如下图:
, agent只需要选取这个向量中的最大的分量对应的action就可以做出决策了。如下图:
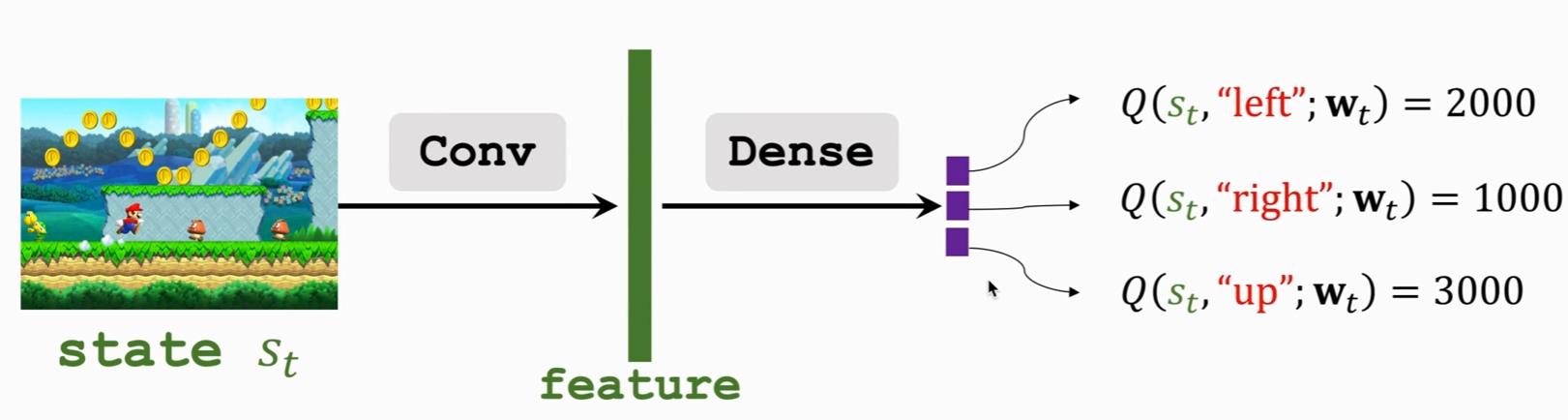
3. TD算法
3.1 算法原理
那么DQN是怎么训练的呢,我们使用的算法是时序差分(Temporal Difference)算法,我们考虑一辆从A点向B点行驶的汽车,如果我们想要利用TD算法预测所需的总时间,TD会先随机猜测一个时间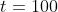 ,经过一段时间
,经过一段时间 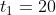 行驶后到达了C点此时TD预测还需要
行驶后到达了C点此时TD预测还需要 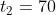 就可以到达B点,我们发现这相当于现在TD预测所需的总时间是
就可以到达B点,我们发现这相当于现在TD预测所需的总时间是 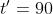 这与一开始的预测有差距,我们知道后面预测的时间更加可靠,因为其中含有真实的信息,而一开始的预测完全是随机的,我们令一开始的预测为
这与一开始的预测有差距,我们知道后面预测的时间更加可靠,因为其中含有真实的信息,而一开始的预测完全是随机的,我们令一开始的预测为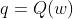 ,后面的预测值为
,后面的预测值为 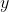 ,我们称之为TD target,因为它是我们的优化的目标,我们想通过改变 ,来使这两者之间的误差
,我们称之为TD target,因为它是我们的优化的目标,我们想通过改变 ,来使这两者之间的误差 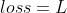 ,
,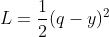 ,减小,这样预测值就会更加接近真实值,于是我们需要用到之前讲过的优化算法来减小误差,比如说SGD,我们就得到了参数更新的迭代式:
,减小,这样预测值就会更加接近真实值,于是我们需要用到之前讲过的优化算法来减小误差,比如说SGD,我们就得到了参数更新的迭代式:
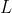 中的1/2出现是因为我们需要计算导数,刚好可以把前面的系数消成1(没错只是为了好看)。
中的1/2出现是因为我们需要计算导数,刚好可以把前面的系数消成1(没错只是为了好看)。
3.2 在DQN中的TD
我们知道return的表达式是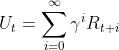 ,简单变形就得到
,简单变形就得到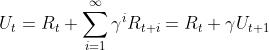 ,于是我们得到了关于价值函数的递推关系式,由于
,于是我们得到了关于价值函数的递推关系式,由于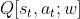 是对
是对 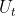 的期望,所以我们可以使用其对 近似,于是有
的期望,所以我们可以使用其对 近似,于是有  ,左侧是预测右侧是TD target。于是就可以使用上述算法了。
,左侧是预测右侧是TD target。于是就可以使用上述算法了。
以上是关于基于Pytorch的强化学习(DQN)之价值学习的主要内容,如果未能解决你的问题,请参考以下文章