浅尝视频编码原理
Posted 易水南风
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了浅尝视频编码原理相关的知识,希望对你有一定的参考价值。
更多博文,请看音视频系统学习的浪漫马车之总目录
视频理论基础:
视频基础知识扫盲
音视频开发基础知识之YUV颜色编码
浅尝视频编码原理
上一篇 音视频入门之YUV颜色编码,介绍了视频的基本颜色编码方式,有了颜色编码的铺垫,那么就可以很自然地进入视频开发的主题地带了~
今天开始讲下视频编码技术,这里的编码可以理解为压缩,当然由于笔者不才,对视频具体压缩算法只是略知一二,自然不能写出来误人子弟,所以这里标题用的是“浅尝”,确实是浅尝,今天只打算将视频编码技术的思路讲一下,当然,虽然是浅尝,不代表对以后的开发没用,编码思路是基础,只有熟悉编码的思路,才能做好开发,不清楚编码过程的思路,是无法做好视频方面的开发的。
上一篇音视频开发基础知识之YUV颜色编码 我们已经知道在视频中的像素是如何表示的,那么我们假设有一个电影视频,分辨率是 1080P,帧率是 25fps,并且时长是 2 小时,如果是yuv420的格式的话,一个像素为1.5字节,那么如果不做视频压缩的话,它的大小是 1920 x 1080 x 1.5 x 25 x 2 x 3600 = 521.4G,一台电脑能存放几部电影呢?如果在网络传输,那么对流量和带宽的消耗可是非常大的(你要知道,在同个时间点,你们小区在看片的人就已经很多了),所以,为了满足广大群众的需求,对视频进行压缩就显示非常有必要,于是视频压缩技术就应运而生。
H.264简介
说的视频编码技术,就不得不提到大名鼎鼎的H.264编码。目前市面常见的编码标准有H264、H265、VP8、VP9 和 AV1,而其中用的最普遍的视频编码就是H.264。
H264和H265都是国际标准化组织(ISO)和国际电信联盟(ITU)开发的编码标准,而VP8、VP9 和 AV1是谷歌开发的编码标准,H264 和 H265 是需要专利费的,所以VP8、VP9 和 AV1(都是免费)也是谷歌为了对抗他们高昂专利费而开发出来的。
由于H.264是目前最常用的编码标准,所以主要就来介绍它。H.264是国际标准化组织(ISO)和国际电信联盟(ITU)共同提出的继MPEG4之后的新一代数字视频压缩格式,也可以看做是国际电信联盟(ITU)提出的h26x系列和国际电信联盟(ITU)提出的MPEG系列斗争多年最后决定化干戈为玉帛,为共同造福人类而努力的产物。
这是2家组织的一个斗争转合作的大致历史,各位了解以下即可。
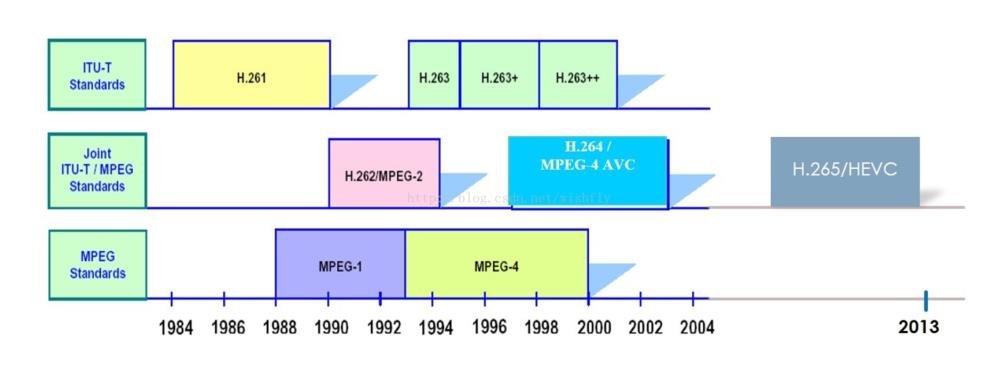
接下来,就是介绍H264的正题部分了。
视频编码基本原理
编码总体思路
H264压缩技术主要采用了以下几种方法对视频数据进行压缩。最主要的步骤包括:
- 帧内预测压缩,解决的是空域数据冗余问题。
- 帧间预测压缩(运动估计与补偿),解决的是时域数据冗徐问题。
- 整数离散余弦变换(DCT),将空间上的相关性变为频域上无关的数据然后进行量化。
- 熵编码。
详细请继续阅读之后部分:
帧内预测
空间冗余
一幅图像中相邻像素的亮度和色度信息是比较接近的,并且亮度和色度信息也是逐渐变化的,不太会出现突变。也就是说,图像具有空间相关性。 利用这种相关性,视频压缩就可以去除空间冗余信息。
比如我很喜欢的电影《假如爱有天意》中很喜欢的开头那段孙艺珍的画面:

随手圈出几个区域都是亮度和色度信息是比较接近的,那么这些区域,是不是就可以不用完整数据记录,而只要使用一小部分数据记录就可以表达全部呢?

比如android开发中的渐变色,我们并不需要指定整个图像全部像素数据,而只是记录开头和结束以及中间变化的颜色,加上渐变位置以及渐变方向。
而视频也是利用了类似的方法去除冗余信息,叫做帧内预测,即帧内预测通过利用已经编码的相邻像素的值来预测待编码的像素值,最后达到减少空间冗余的目的。
具体预测方法
整体思路是利用一帧图像中已经编码部分来预测尚未编码部分图像,实际值和预测值之间的差别叫做残差。实际上真正编码的是残差数据,因为残差一般比较小,所以对残差编码比对实际数据编码会小很多。
为了可以利用编码部分来预测尚未编码部分图像,所以需要根据具体情况对一帧图像划分为若干个部分, 每个部分叫做块,其中某些块可以预测另外一些块。H264中对一帧图像划分为宏块的方式来区分不同像素使用的预测模式的,即同个宏块的像素就使用一种预测模式。那么何为宏块呢?
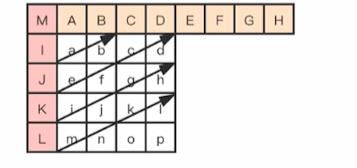
一张图片
比如一帧图像如下:

H264默认是使用 16X16像素大小的区域作为一个宏块(其中亮度块为 16 x 16,色度块为 8 x 8,帧内预测中亮度块和色度块是分开独立进行预测的),比如左上角区域:

H264对比较平坦的图像使用 16X16 大小的宏块。但为了更高的压缩率,在细节复杂的地方,还可以在 16X16 的宏块上更划分出更小的子块。子块的大小可以是 8X16、 16X8、 8X8、 4X8、 8X4、 4X4非常的灵活。
还是孙艺珍,红色块就是16*16的宏块,绿色剪头指的就是进一步划分的子块:

帧内预测模式总共有 9 个。其中有 8 种方向模式和一种 DC 模式,接下来简单介绍下各种帧内预测模式:
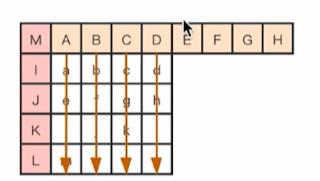
1.Vertical 模式
Vertical 模式就是指,当前编码亮度块的每一列的像素值,都是复制上边已经编码块的最下面那一行的对应位置的像素值。
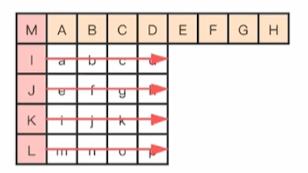
2.Horizontal 模式
Horizontal 模式就是指,当前编码亮度块的每一行的像素值,都是复制左边已经编码块的最右边那一列的对应位置的像素值(
3.DC 模式
DC 模式就是指,当前编码亮度块的每一个像素值,是上边已经编码块的最下面那一行和左边已编码块右边最后一列的所有像素值的平均值,所以DC 模式预测得到的块中每一个像素值都是一样的。

4.Diagonal Down-Left 模式
Diagonal Down-Left 模式是上边块和右上块的像素通过插值得到。如果上边块和右上块不存在则该模式无效。

5.Diagonal Down-Right 模式
Diagonal Down-Right 模式需要通过上边块、左边块和左上角对角的像素通过插值得到。如果这三个有一个不存在则该模式无效。
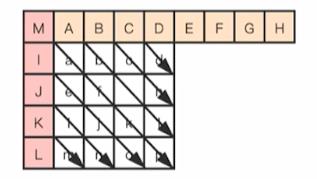
6.Vertical-Right 模式
Vertical-Right 模式是需要通过上边块、左边块以及左上角对角的像素插值得到的。
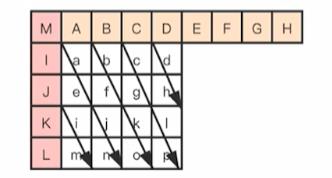
7.Horizontal-Down 模式
Horizontal-Down 模式需要通过上边块、左边块以及左上角对角的像素插值得到。必须要这三个都有效才能使用,否则该模式无效。
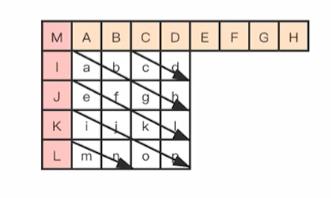
8.Vertical-Left 模式
Vertical-Left 模式是需要通过上边块和右上块最下面一行的像素通过插值得到。
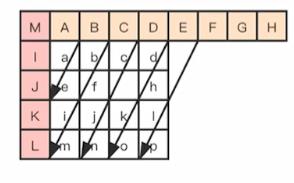
9.Horizontal-Up 模式
Horizontal-Up 模式是需要通过左边块的像素通过插值得到的。
每一个宏块只能用一种预测模式,那如何选择呢?具体算法很复杂(我也不懂),大概思路就是对于每一个块或者子块,我们可以得到预测块,再用实际待编码的块减去预测块就可以得到残差块。然后在不同场景下根据不同的算法对残差块进行计算得到最优的预测模式。
帧间预测
时间冗余
在一个视频中,一般前后两帧图像往往变化比较小,这就是视频的时间相关性。
而视频一般往往一秒会播放20-30帧,所以存在大量重复的图像数据,所以会有巨大的压缩空间。
还是孙艺珍在这部电影中的连续5帧画面:





很明显,5帧画面差别非常小,那么很容易想到,能不能只记录第一帧画面数据,然后后面几帧只记录差别数据呢?
视频编码中,就是通过在已经编码的帧里面找到一个块来预测待编码块的像素,从而达到减少时间冗余的目的,官方名称为:帧间预测。
具体来说,就是在前面某一帧找到一个内容很接近的块,那么只要再加上运动矢量,就可以表示当前的块。
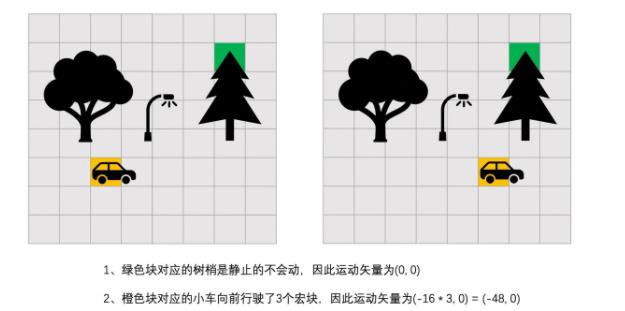
比如这是前后两帧(图来源于:帧间预测:如何减少时间冗余),背景的树木都是静止的,只有汽车是移动的,对整个图片建立坐标系,那么汽车的移动就可以用运动矢量表示:
回到现实视频例子,比如前面一帧孙艺珍的左手是一个块:

到了后面若干帧之后,这个块的位置发生了移动,但是内容基本一致(存在较小的残差数据)

所以后面的这一帧就不必记录左手这一个块的图像信息了,只要记录运动矢量和残差数据即可,这样比直接把后面一帧的左手的图像数据编码进入码流要小很多。前面一帧也就是后面一帧的参考帧。
类似加上下图的绿色剪头:

用专业分析软件打开看看运动矢量分析图:

可以看到大量密密麻麻让人犯密集恐惧症的细线,表示运动矢量,而我们关注的孙艺珍左手的块(绿色框),上面的红色线方向大体和移动方向一致。
运动估计
帧间预测一个重要概念就是运动估计,就是寻找当前编码的块在已编码图像中的最佳对应块。
如图,假设P为当前编码帧,Pr为参考帧,当前编码块为B,则运动估计要做的就是在Pr中寻找与B相减残差最小的块Br,Br就叫做B的最佳匹配块。

放到孙艺珍视频例子中,运动估计就是寻找上面第二幅图中孙艺珍左手在第一张图中对应的最佳图像块。当然我们人眼可以很快找到后面一帧左手和前面一帧左手是最佳匹配,但是计算机可就不好找了,所以帧间预测这里的难点在于如何找到最佳的参考块来预测当前块,这里涉及很多复杂的运动搜索算法,主要有这两种算法:
(1)全局搜索算法。该方法是把搜索区域内所有的像素块逐个与当前宏块进行比较,查找具有最小匹配误差的一个像素块为匹配块。这一方法的好处是可以找到最佳的匹配块,坏处是速度太慢。目前全局搜索算法极少使用。
(2)快速搜索算法。该方法按照一定的数学规则进行匹配块的搜索。这一方法的好处是速度快,坏处是可能只能得到次最佳的匹配块。
具体可以看下帧间预测:如何减少时间冗余,这里重点是要知道I帧,P帧和B帧这几个概念。
I帧,P帧和B帧
前面已经介绍了帧内预测和帧间预测2种压缩技术,结合具体视频内容,为了得到更好的压缩率,我们可以对不同的帧使用不同的预测压缩方式。我们知道一个视频会有若干个场景,即在一个内容为相似的背景或者空间内有着相似的人物或者物体,而每个场景会由若干帧组成,而这些帧往往是强相关的,最适合进行帧间预测,这里一个场景的帧的组合,就叫做GOP。
比如刚才孙艺珍是在屋子的窗前,坐着打开收藏盒:
这个场景持续了几十秒,播放了好多好多帧,然后切到孙艺珍接电话的场景:

这里就是2个视频场景GOP,根据场景内帧的强相关性和帧预测理论,所以可以对一个场景的首帧进行帧内预测去除空间冗余,然后后面的帧来参考首帧,再后面的帧再来参考前面已经预测出来的帧,为了更好地降低压缩率,还可以不止一个参考帧,比如一帧可以参考前后2帧,于是就出现了I帧,P帧和B帧。
经过压缩后的帧被人为划分为分为:I帧,P帧和B帧:
I帧:关键帧,采用帧内压缩技术。
P帧:向前参考帧,在压缩时,只参考前面已经处理的帧。采用帧间压缩技术。
B帧:双向参考帧,在压缩时,它即参考前而的帧,又参考它后面的帧。采用帧间压缩技术。
那么GOP究竟是什么呢?
GOP是一个图像序列,一般可以理解为一个场景的若干个帧,比如一段电影片段在主角在公园里,因为整体画面差别不大,所以可以放入一个gop中,接下来切到主角在室内了,那么此时就重新开始另一个gop了。在一个图像序列中只有一个I帧。如下图所示:
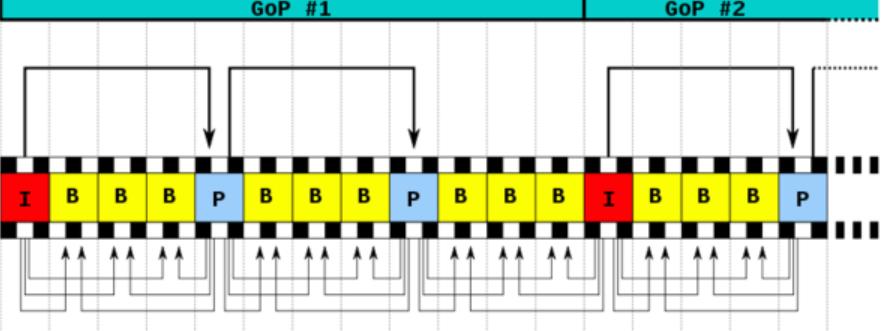
每个GOP首帧就是I帧,它采用帧内预测,是一个全帧压缩编码帧,描述了图像背景和运动主体的详情,不需要考虑运动矢量,解码时仅用I 帧的数据就可重构完整图像,是P帧和B帧的参考帧。
后面的帧会使用帧间预测技术参考I帧或之后编码出来的P帧,P帧表示的是这一帧跟之前的一个关键帧(或P帧)的差别,P帧没有完整画面数据,只有与前一帧的画面差别的数据。P帧是以 I 帧或前面的P帧为参考帧,在 参考帧中找出P帧“某点”的预测值和运动矢量,取预测差值和运动矢量一起传送。在接收端根据运行矢量从 I 帧找出P帧“某点”的预测值并与差值相加以得到P帧“某点”样值,从而可得到完整的P帧。
B帧是双向差别帧,和P帧的主要区别在于它是参考前后2帧,也就是B帧记录的是本帧与前后帧的差别。 B帧以前面的 I 或P帧和后面的P帧为参考帧,“找出”B帧“某点”的预测值和两个运动矢量,并取预测差值和运动矢量传送。
打个比方,就比如有一排人,每人说一句话,他们每个人要说的东西比较接近,但是要求说话字数尽量少。为了使得说话的数量尽量少,第一个人说了完整的一句话(尽量概括),后面的人只说了相对第一个人说的话有区别的部分,而还有的人说了和前后2个人区别的部分,使得需要说的话更少。这样子只要推导一下就能推导出他们每个人完整的话的内容。
显然I帧压缩率最低,其次是P帧,B帧压缩率最高。
这里还要提到一种特殊的I帧,叫做IDR帧,因为帧间预测技术总是不断参考前面已经编码成功的帧,那如果其中一帧编码出错,那可能造成后面帧的错误传递,比如第一个人说话说错了一个字,那么后面参考他的人基于他的话说了区别部分,那么推导出的原话必然会出错。所以IDR帧的作用就是用来阻断错误传递的,它就限制后面同个GOP的帧不能参考前面的GOP的帧,这样一旦某一帧出错,错误也仅限于一个GOP内,不会传入下一个GOP。
变换量化
DCT变换
首先说说图像频率是什么。图像可以看做是一个定义为二维平面上的信号,该信号的幅值对应于像素的灰度值(对于彩色图像则是RGB三个分量),如果我们仅仅考虑图像上某一行像素,则可以将之视为一个定义在一维空间上的信号,这个信号在形式上与传统的信号处理领域的时变信号是相似的,时变信号是有一定频率成分的,图像的频率又称为空间频率,它反映了图像的像素灰度在空间中变化的情况。
一般图片的高频信息多但是幅值比较小。高频信息主要描述图片的边缘信息,对于快速空间变化的图像来说,比如充满沟壑的山脉,其高频成分会相对较强,低频则较弱。由于人眼的视觉敏感度是有限的,有的时候我们去除了一部分高频信息之后,人眼看上去感觉区别并不大。这就是去除视觉冗余。
因此,我们可以先将图片 DCT 变换到频域,然后再去除一些高频信息。这样我们就可以减少信息量,从而达到压缩的目的。
如何转变到频域呢?还记得傅里叶变换么,任何”周期信号都可以用一系列成谐波关系的正弦曲线来表示。由于本文不准备探讨算法部分,所以不打算深入数学部分,一张图就可以让你有总体的理解:
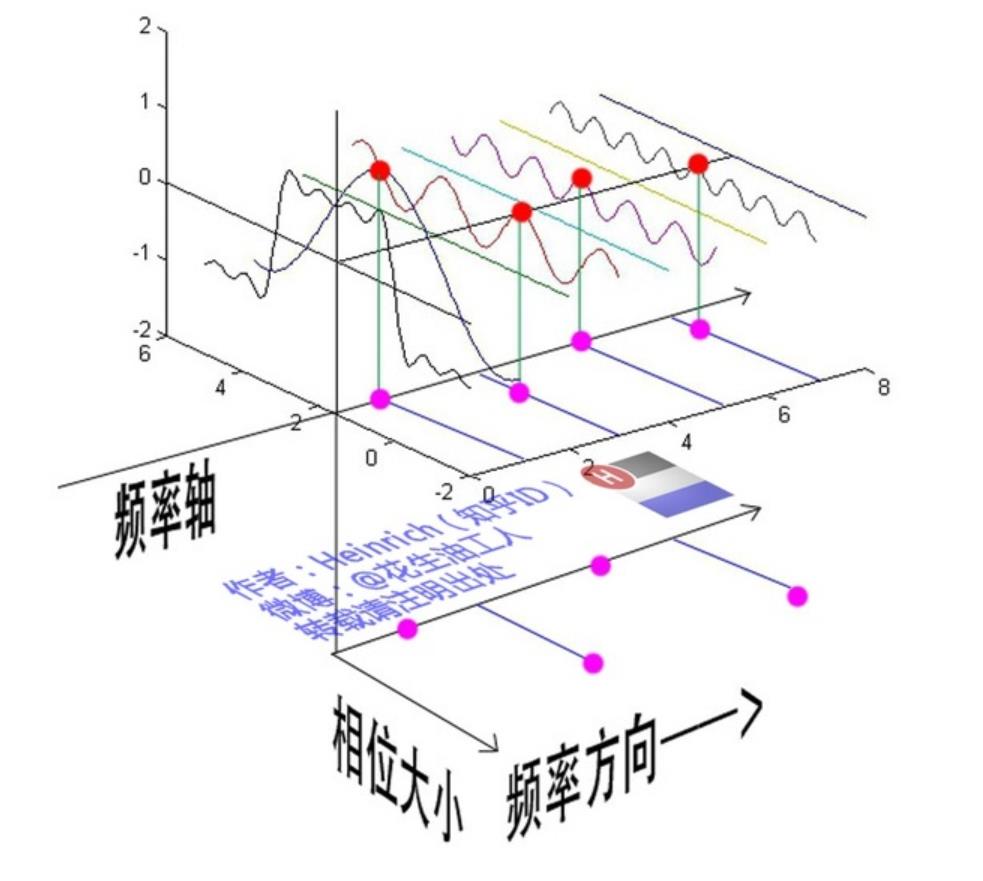
而DCT变换后,往往会进行量化。量化其实就是一个除法操作。通过除法操作就可以将幅值变小,而高频信息幅值比较小,就比较容易被量化成 0,这样就能够达到压缩的目的。
熵编码
视频编码中真正实现“压缩”的步骤,主要去除信息熵冗余。而前面说的去除空间、时间、视觉冗余,其实都是为这一步做准备的。
我们应该见过一道压缩字符串的编程题目,就是将 “aaaabbbccccc” 压缩成 “4a3b5c”,字符串由 13 个字符压缩到 7 个字符,这个叫做行程编码。熵编码中使用了类似行程编码的思想处理图像扫描出来的像素数据,但是使用行程编码不一定能够压缩数据,如果刚才编程题的字符串是 “abcdabcdabcd” 的话,那么编码之后就会是 “1a1b1c1d1a1b1c1d1a1b1c1d”。字符串的大小从 13 字符变成了 25 字符,还反而变大了。如何使得变小呢,答案就是尽量使得其为连续的字符,最好是连续的‘0’,因为0可以用最少的位数存储(比如指数哥伦布编码,它就可以做到 0 只占用一个位。)。
总结
今天主要就是梳理了以下视频编码原理总体流程,以H264作为主要的编码方式来说明:
整体流程如下:
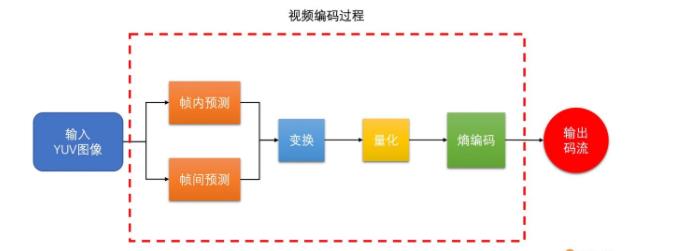
个人也将上述内容做成一个脑图便于理解:
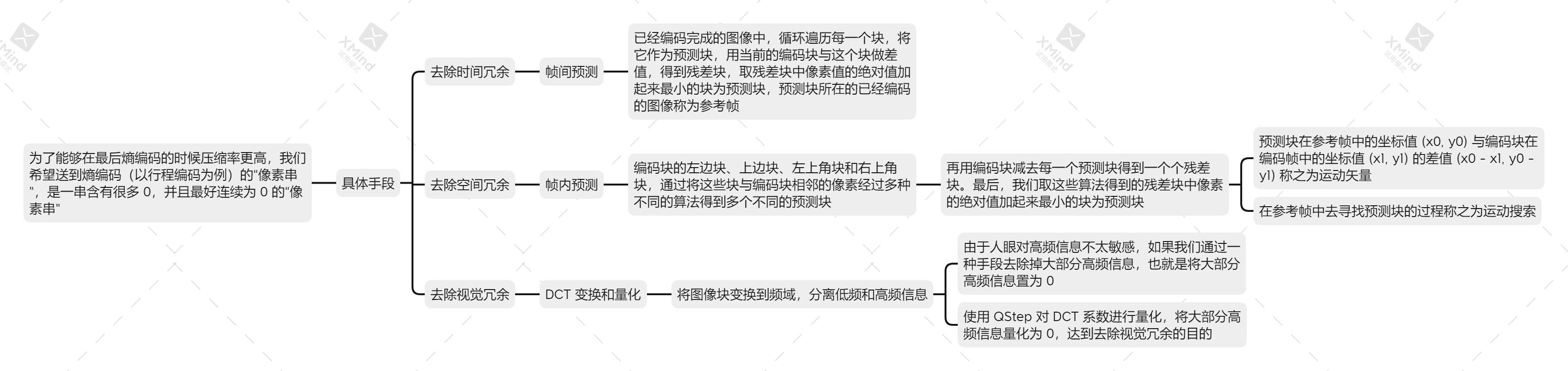
希望大家看过本文能够对视频编码流程有所体会。
参考文章:
编码原理:视频究竟是怎么编码压缩的?
帧内预测:如何减少空间冗余?
帧间预测:如何减少时间冗余?
变换量化:如何减少视觉冗余?
H264 I帧 P帧 B帧
《深入理解视频编解码技术》
以上是关于浅尝视频编码原理的主要内容,如果未能解决你的问题,请参考以下文章