Linux(基于CentOS7)单机版Spark环境搭建
Posted 小董的代码之路
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Linux(基于CentOS7)单机版Spark环境搭建相关的知识,希望对你有一定的参考价值。
目录
1.安装Python3.7版本
1.首先安装gcc编译器,gcc有些系统版本已经默认安装,通过 gcc --version 查看,没安装的先安装gcc,
yum -y install gcch2.安装其它依赖包,此步为必要性操作。
yum -y install zlib-devel bzip2-devel openssl-devel ncurses-devel sqlite-devel readline-devel tk-devel gdbm-devel db4-devel libpcap-devel xz-devel libffi-devel或者使用
yum -y groupinstall "Development tools命令把所有开发环境的依赖包安装好
3.下载python3.7.x源码,根据需求下载,到官网https://www.python.org/downloads/source/上进行下载,下载taz格式的压缩包文件,然后对压缩包上传至linux服务器
也可以使用
wget https://www.python.org/ftp/python/3.7.3/Python-3.7.3.tgz 直接进行安装,注意看自己所处的目录,如果想安装到其他目录也可以例如,我的下载地址为 /opt/software/
wget https://www.python.org/ftp/python/3.7.3/Python-3.7.3.tgz/opt/software/如若此处下载过慢,可以使用国内镜像源
ll一下发现我们的python压缩包已经下载好了
4.解压python3.7.3 解压命令为: tar -zxvf Pyhon-3.7.3.tgz -C /opt/moudule 这是我的解压路径 -C参数表示指定安装路径
5.建立一个空文件夹,用于存放python3程序 mkdir /usr/local/python3
6.执行配置文件,编译,编译安装cd Python-3.7.3 ./configure --prefix=/usr/local/python3 make && make install7.建立软连接(因为Centos7已经自带python2版本,所以我们要下载python3并建立软连接并进行区别)
ln -s /usr/local/python3/bin/python3.7 /usr/bin/python3 ln -s /usr/local/python3/bin/pip3.7 /usr/bin/pip38.测试一下python3是否已经安装好并可用

此时出现版本信息,OK安装完成

2.安装Spark与JDK
1.下载Spark与JDK安装包并解压,方法同上,这里我不再赘述
这里我使用的是jdk1.8.0与spark3.2
2.配置JDK环境变量,这里我的安装目录为/opt/module
新建/etc/profile.d/my_env.sh文件(注:my_env.sh,关键是.sh后缀,名称任取)
vim /etc/profile.d/my_env.sh添加如下内容
#JAVA_HOME export JAVA_HOME=/opt/module/jdk1.8.0_212 export PATH=$PATH:$JAVA_HOME/bin保存并退出,然后我们 source /etc/profile 一下,让新的环境变量PATH生效
最后我们 java -version一下看看是否环境配置成功
入股
如果此时未出现java版本信息可以reboot一下
2.配置SPARK环境变量,这里我的安装目录为/opt/module
首先,我们进入spark安装目录下的conf子目录
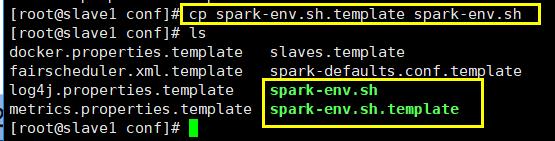
修改配置文件spark-env.sh,注意,这个文件默认不存在,这里有spark-env.sh.template,复制一份并命名新文件为spark-env.sh
cp spark-vev.sh.template spark-env.sh
查看之前的JAVA_HOME路径,在下一步中使用
修改文件spark-env.sh,在文件末尾添加如下内容:
#export SCALA_HOME=/opt/scala-2.13.0 export JAVA_HOME=/opt/moudle/jdk1.8.0_115 #这里是你jdk的安装路径 export SPARK_HOME=/opt/moudle/spark-2.3.1 #这里是你spark的安装路径 export SPARK_MASTER_IP=XXX.XX.XX.XXX #将这里的xxx改为自己的Linux的ip地址 #export SPARK_EXECUTOR_MEMORY=512M #export SPARK_WORKER_MEMORY=1G #export master=spark://XXX.XX.XX.XXX:7070新建workers配置文件(子节点配置文件):
进入spark的conf目录下:cd /opt/module/spark-3.2.0-bin-hadoop2.7/conf
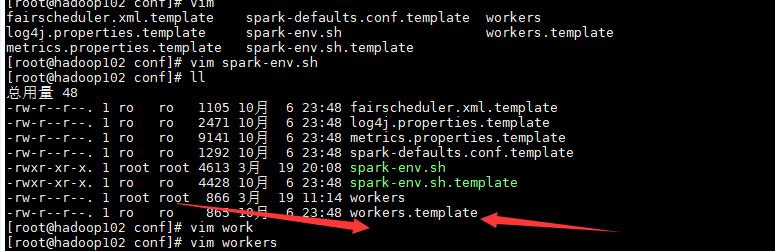
copy一份slaves:cp workers.template workers
然后进入vim编辑模式:vim workers,会提示文件已存在,输入“e”进入编辑模式即可。
在文件的最后加上如下配置:localhost
如果已有则不需要添加



3.启动SPARK
1.进入spark的sbin目录:cd sbin/
2.启动spark集群(单机版): ./start-all.sh
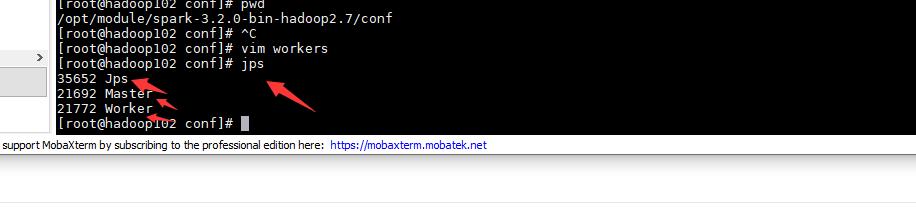
然后等待,如果没有报错,然后我们jps一下
发送JPS与Mster 与Worker都成功启动,说明SPARK配置成功
接下来我们就可以用Windows的pycharm连接linux进行编程作业啦!
以上是关于Linux(基于CentOS7)单机版Spark环境搭建的主要内容,如果未能解决你的问题,请参考以下文章