Hadoop学习之路,YARN的配置与安装
Posted MC柱柱
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Hadoop学习之路,YARN的配置与安装相关的知识,希望对你有一定的参考价值。
Hadoop中YARN的配置
etc/hadoop/mapred-site.xml文件编辑
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
etc/hadoop/yarn-site.xml文件编辑
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
启动yarn
[vagary@vagary ~]$ jps
21049 DataNode
2187 Jps
21275 SecondaryNameNode
20926 NameNode
[vagary@vagary ~]$ start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[vagary@vagary ~]$ jps
21049 DataNode
2842 Jps
21275 SecondaryNameNode
2493 NodeManager
2366 ResourceManager
20926 NameNode
然后查看对应端口号
[root@vagary ~]# netstat -nlp | grep 2366
tcp 0 0 0.0.0.0:8088 0.0.0.0:* LISTEN 2366/java
tcp 0 0 0.0.0.0:8030 0.0.0.0:* LISTEN 2366/java
tcp 0 0 0.0.0.0:8031 0.0.0.0:* LISTEN 2366/java
tcp 0 0 0.0.0.0:8032 0.0.0.0:* LISTEN 2366/java
tcp 0 0 0.0.0.0:8033 0.0.0.0:* LISTEN 2366/java
然后web界面查看,这样子我们就算安装成功了,如果访问不成功,证明安全组没打开,打开该端口安全组就行
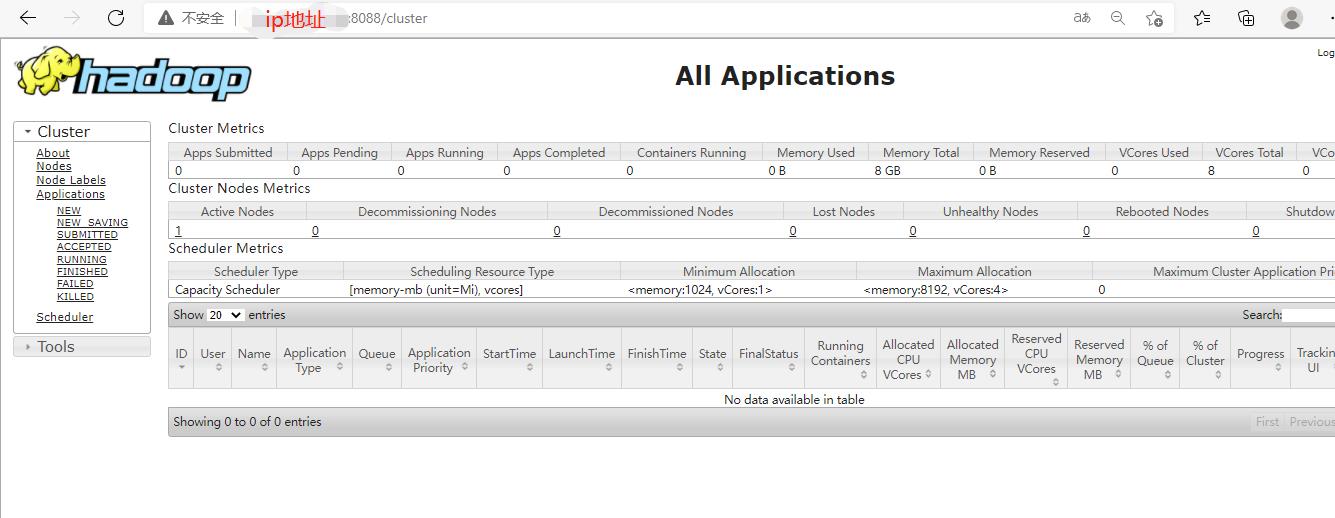
然后因为8088端口经常会成为挖矿的一个点,所以需要再进行一些配置,伪装端口,再打开yarn-site.xml文件,再加一条设置,这里我修改为9527了,只要改成不常用的都可以
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>$yarn.resourcemanager.hostname:9527</value>
</property>
设置完成,再重新启动yarn,查看端口,已经修改为9527了
[vagary@vagary hadoop]$ jps
17990 ResourceManager
18119 NodeManager
21049 DataNode
18521 Jps
21275 SecondaryNameNode
20926 NameNode
[root@vagary ~]# netstat -nlp | grep 17990
tcp 0 0 0.0.0.0:9527 0.0.0.0:* LISTEN 17990/java
tcp 0 0 0.0.0.0:8030 0.0.0.0:* LISTEN 17990/java
tcp 0 0 0.0.0.0:8031 0.0.0.0:* LISTEN 17990/java
tcp 0 0 0.0.0.0:8032 0.0.0.0:* LISTEN 17990/java
tcp 0 0 0.0.0.0:8033 0.0.0.0:* LISTEN 17990/java
将Hadoop的pid临时路径改到本地,编辑 hadoop-env.sh文件,加入一下配置
[vagary@vagary hadoop]$ vi hadoop-env.sh
export HADOOP_PID_DIR=/home/vagary/tmp
export HADOOP_SECURE_PID_DIR=/home/vagary/tmp
运行一个mapreduce实例,现在本地创建一个txt文件
[vagary@vagary data]$ vi wordcount.txt
文件内容:
hadoop hdfs hdfs hive
hdfs sqoop flume java
Java Hadoop hadoop
在Hadoop上创建文件夹,这里我们选择创建级联文件夹(-p)
[vagary@vagary data]$ hdfs dfs -mkdir -p /wordcount/input
将文件上传到刚刚创建好的Hadoop文件目录中
[vagary@vagary data]$ hdfs dfs -put wordcount.txt /wordcount/input
运行个mapreduce任务,调用jar+任务名+输入路径+输出路径,具体用法:
[vagary@vagary hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wordcount/input /wordcount/output
会报以下错误:
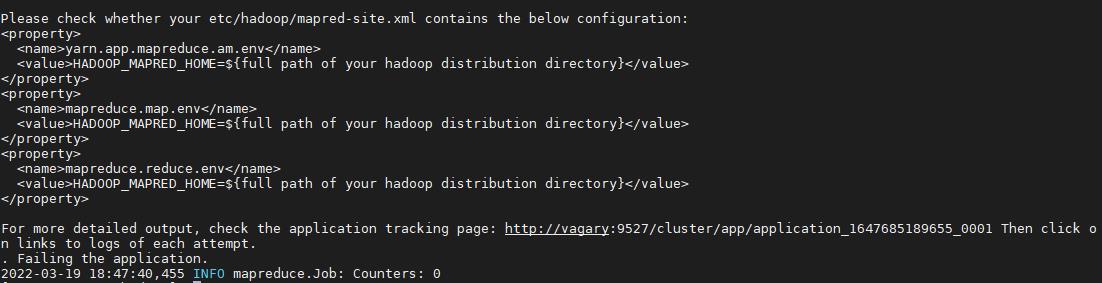
需要在etc/hadoop/mapred-site.xml文件下再加入一下配置:
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
yarn.app.mapreduce.am.env含义:
用户为MR应用程序主进程添加了环境变量,指定为逗号分隔的列表
mapreduce.map.env:为map添加环境变量
mapreduce.reduce.env:为reduce添加环境变量
现在再重新运行任务:
[vagary@vagary hadoop]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount /wordcount/input /wordcount/output
出现以下结果,就成功了:
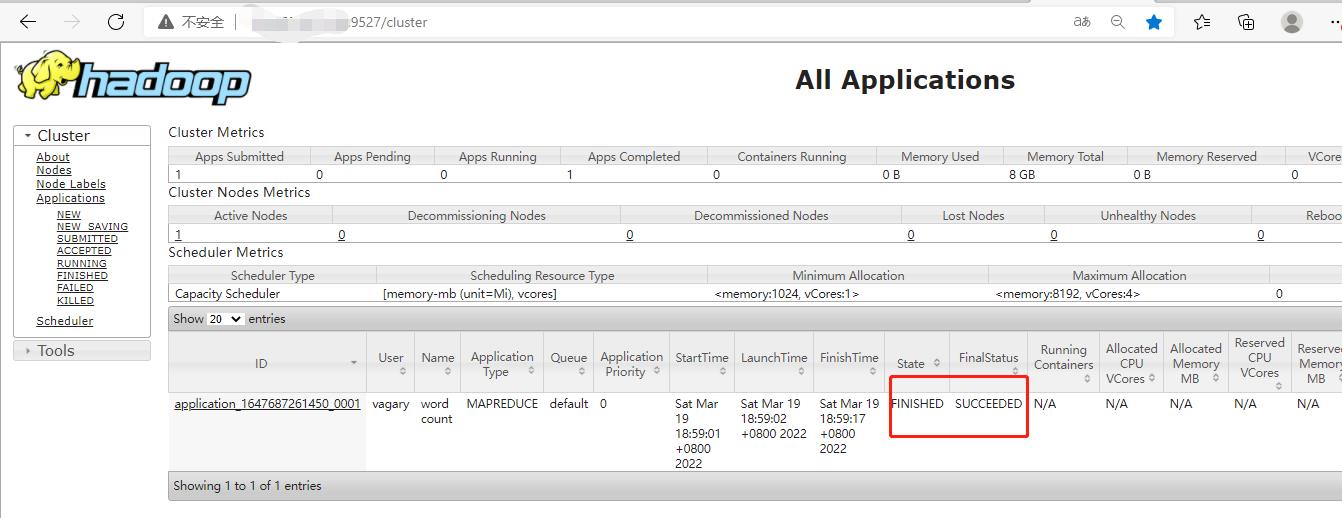
查看结果显示:
[vagary@vagary hadoop]$ hdfs dfs -cat /wordcount/output/*
2022-03-19 19:02:59,158 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
Hadoop 1
Java 1
flume 1
hadoop 2
hdfs 3
hive 1
java 1
sqoop 1
以上是关于Hadoop学习之路,YARN的配置与安装的主要内容,如果未能解决你的问题,请参考以下文章