[机器学习与scikit-learn-26]:算法-聚类-KMeans寻找最佳轮廓系数
Posted 文火冰糖的硅基工坊
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[机器学习与scikit-learn-26]:算法-聚类-KMeans寻找最佳轮廓系数相关的知识,希望对你有一定的参考价值。
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址:https://blog.csdn.net/HiWangWenBing/article/details/123515923
目录
前言:
不同的聚类类别,其轮廓系数的分布是不相同,聚类的方式也是不同的,本文就是展示不同聚类类别情形其平均轮廓系数以及素有样本的轮廓系数的分布情况。
第1章 指定聚类情况系的轮廓系数
1.1 非排序的轮廓系数
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
# 构建模型并进行学习
n_clusters = 4
clusterer = KMeans(n_clusters=n_clusters, random_state=10)
clusterer = clusterer.fit(X)
# 获得所有预测标签
cluster_labels = clusterer.labels_
# 获得所有样本的平均轮廓分数
silhouette_avg = silhouette_score(X, cluster_labels)
print("For n_clusters =", n_clusters)
print("The average silhouette_score is :", silhouette_avg)
# 获得每个样本的所有轮廓分数
sample_silhouette_values = silhouette_samples(X, cluster_labels)
print("The sample silhouette_score is :", sample_silhouette_values.shape)
# 可视化所有的样本的轮廓系数分布
x_data = np.linspace(0, 500, 500)
y_data = sample_silhouette_values
plt.scatter(x_data, y_data)
#fill_betweenx(y, x1, x2=0, where=None, step=None, interpolate=False, *, data=None, **kwargs)[source]
plt.fill_between(x_data, 0, y_data, facecolor='green', alpha=0.3)For n_clusters = 4
The average silhouette_score is : 0.6505186632729437
The sample silhouette_score is : (500,)

1.2 轮廓系数排序后的展示--横向展示
# 可视化所有的样本的轮廓系数分布(排序后结果)
x_data = np.linspace(0, 500, 500)
y_data = sample_silhouette_values
y_data.sort()
plt.scatter(x_data,y_data)
plt.fill_between(x_data, 0, y_data, facecolor='green', alpha=0.3)
1.3 轮廓系数排序后的展示--纵向展示
# 可视化所有的样本的轮廓系数分布(排序后结果)
x_data = np.linspace(0, 500, 500)
y_data = sample_silhouette_values
y_data.sort()
plt.scatter(y_data,x_data)
plt.fill_between(y_data,0, x_data, facecolor='green', alpha=0.3)
第2章 cluster=4时候的轮廓系数(排序)
#1. 生成画布
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_size_inches(9+9, 7)
# 横坐标是轮廓系数,[-1, 1] ,实际在[0,1]
ax1.set_xlim([-0.1, 1])
# 纵坐标范围
print("样本个数:", X.shape[0])
ax1.set_ylim([0, X.shape[0] + (n_clusters + 1) * 10])
#2. 分别画出每个聚类类别的轮廓系数
# 基线,防止每个轮廓系数贴着X轴
y_lower = 10
#
for i in range(n_clusters):
# 获取i个聚类类别对应的轮廓系数
ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels == i]
# 获取i个聚类类别对应的轮廓系数进行排序,以免乱序显示,
ith_cluster_silhouette_values.sort()
# 获取某一个聚类类别对应的样本数
size_cluster_i = ith_cluster_silhouette_values.shape[0]
print(size_cluster_i)
# 设置样本的上线:lower + 某个聚类类别的样本数就是它的上线
y_upper = y_lower + size_cluster_i
# 把族的类别映射成某一种颜色
color = cm.nipy_spectral(float(i)/n_clusters)
# 在y轴的[y_lower, y_upper] 之间填充ith_cluster_silhouette_values
ax1.fill_betweenx(np.arange(y_lower, y_upper) # Y轴的数值
,ith_cluster_silhouette_values # X轴的数值
,facecolor=color
,alpha=0.7
)
# 设置Y轴每个聚类块的标签名称
ax1.text(-0.05 , y_lower + 0.5 * size_cluster_i , str(i))
y_lower = y_upper + 10
# 可视化运行结果
ax1.set_title("The silhouette plot for the various clusters.")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
#画出平均值线
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
# 设置y轴坐标
ax1.set_yticks([])
# 设置x轴坐标
ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
#3. 画出每个样本的实际分布
colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters)
ax2.scatter(X[:, 0], X[:, 1] ,marker='o' ,s=8 ,c=colors)
centers = clusterer.cluster_centers_
# Draw white circles at cluster centers
ax2.scatter(centers[:, 0], centers[:, 1], marker='x', c="red", alpha=1, s=200)
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data ""with n_clusters = %d" % n_clusters),
fontsize=14, fontweight='bold')
plt.show()样本个数: 500 123 125 124 128

第3章 不同聚类数情形下的轮廓系数展示
3.1 代码
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_samples, silhouette_score
import matplotlib.pyplot as plt
import matplotlib.cm as cm
import numpy as np
# 显示不同聚类分类数的情形下的轮廓系数分布情况
for n_clusters in [2,3,4,5,6,7]:
# 聚类类别数
n_clusters = n_clusters
# 准备画布
fig, (ax1, ax2) = plt.subplots(1, 2)
fig.set_size_inches(18, 7)
ax1.set_xlim([-0.1, 1])
ax1.set_ylim([0, X.shape[0] + (n_clusters + 1) * 10])
# 模型训练
clusterer = KMeans(n_clusters=n_clusters, random_state=10).fit(X)
#模型标签
cluster_labels = clusterer.labels_
# 轮廓系数均值
silhouette_avg = silhouette_score(X, cluster_labels)
print("For n_clusters =", n_clusters, "The average silhouette_score is :", silhouette_avg)
# 在指定类别下,每个样本的轮廓系数
sample_silhouette_values = silhouette_samples(X, cluster_labels)
# 可视化轮廓系数
y_lower = 10
for i in range(n_clusters):
ith_cluster_silhouette_values = sample_silhouette_values[cluster_labels == i]
ith_cluster_silhouette_values.sort()
size_cluster_i = ith_cluster_silhouette_values.shape[0]
y_upper = y_lower + size_cluster_i
color = cm.nipy_spectral(float(i)/n_clusters)
ax1.fill_betweenx(np.arange(y_lower, y_upper)
,ith_cluster_silhouette_values
,facecolor=color
,alpha=0.7
)
ax1.text(-0.05
, y_lower + 0.5 * size_cluster_i
, str(i))
y_lower = y_upper + 10
# 设置轮廓系数坐标值参数
ax1.set_title("The silhouette plot for the various clusters.")
ax1.set_xlabel("The silhouette coefficient values")
ax1.set_ylabel("Cluster label")
# 绘制中轴线
ax1.axvline(x=silhouette_avg, color="red", linestyle="--")
ax1.set_yticks([])
ax1.set_xticks([-0.1, 0, 0.2, 0.4, 0.6, 0.8, 1])
colors = cm.nipy_spectral(cluster_labels.astype(float) / n_clusters)
# 绘制不同聚类族的情形的样本分布图
ax2.scatter(X[:, 0], X[:, 1]
,marker='o'
,s=8
,c=colors
)
centers = clusterer.cluster_centers_
# raw white circles at cluster centers
ax2.scatter(centers[:, 0], centers[:, 1], marker='x',
c="red", alpha=1, s=200)
ax2.set_title("The visualization of the clustered data.")
ax2.set_xlabel("Feature space for the 1st feature")
ax2.set_ylabel("Feature space for the 2nd feature")
plt.suptitle(("Silhouette analysis for KMeans clustering on sample data "
"with n_clusters = %d" % n_clusters),
fontsize=14, fontweight='bold')
plt.show()3.2 n_cluser=2
For n_clusters = 2 The average silhouette_score is : 0.7049787496083262

3.3 n_cluser=3
For n_clusters = 3 The average silhouette_score is : 0.5882004012129721

3.4 n_cluser=4
For n_clusters = 4 The average silhouette_score is : 0.6505186632729437

3.5 n_cluser=5
For n_clusters = 5 The average silhouette_score is : 0.56376469026194
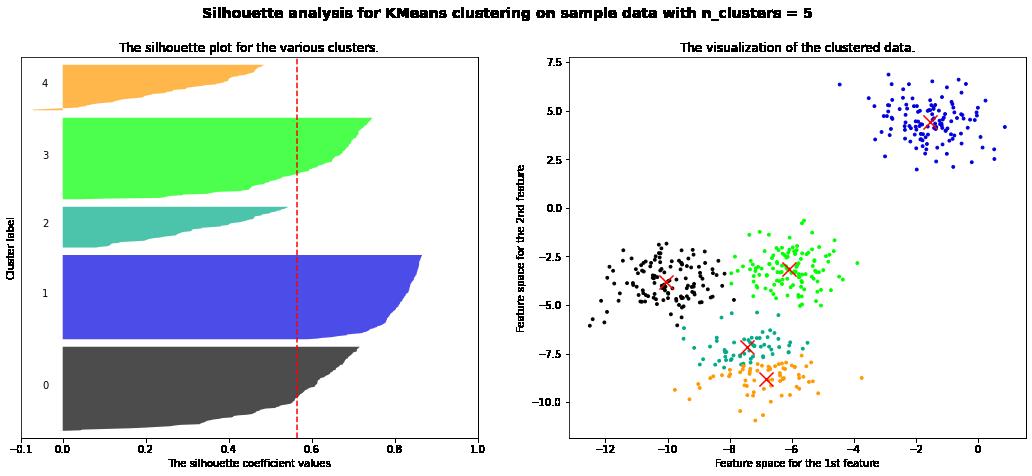
3.6 n_cluser=6
For n_clusters = 6 The average silhouette_score is : 0.4504666294372765

3.7 n_cluser=7
For n_clusters = 7 The average silhouette_score is : 0.39092211029930857
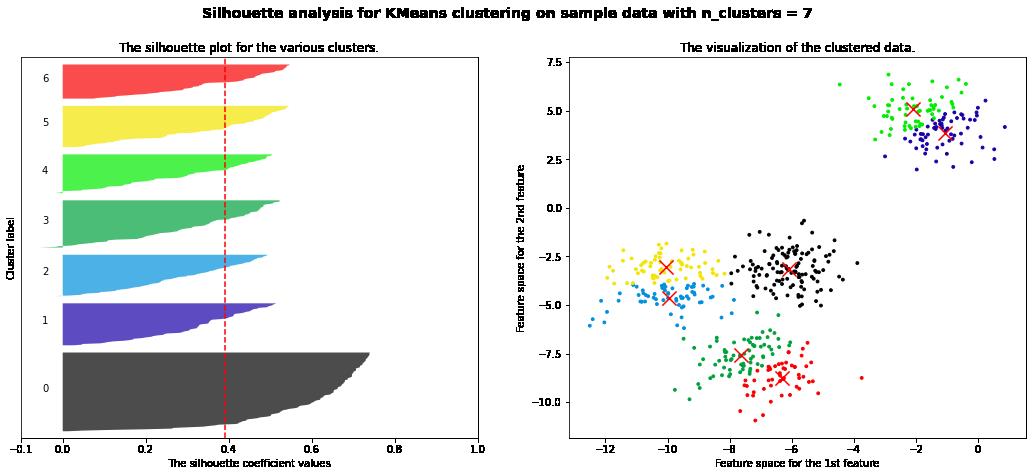
作者主页(文火冰糖的硅基工坊):文火冰糖(王文兵)的博客_文火冰糖的硅基工坊_CSDN博客
本文网址: https://blog.csdn.net/HiWangWenBing/article/details/123515923
以上是关于[机器学习与scikit-learn-26]:算法-聚类-KMeans寻找最佳轮廓系数的主要内容,如果未能解决你的问题,请参考以下文章