Spark RDD算子案例:两种方式计算学生总分
Posted howard2005
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Spark RDD算子案例:两种方式计算学生总分相关的知识,希望对你有一定的参考价值。
文章目录
一、提出任务
- 针对成绩表,计算每个学生总分
| 姓名 | 语文 | 数学 | 英语 |
|---|---|---|---|
| 张钦林 | 78 | 90 | 76 |
| 陈燕文 | 95 | 88 | 98 |
| 卢志刚 | 78 | 80 | 60 |
二、准备工作
(一)启动HDFS服务
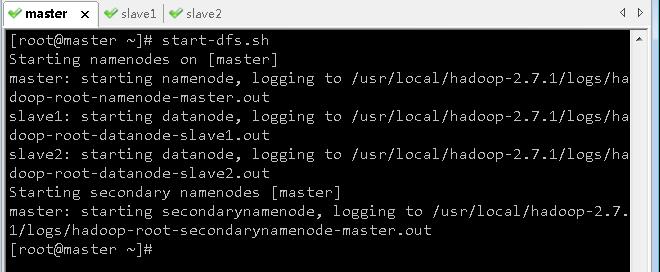
- 执行命令:
start-dfs.sh
(二)启动Spark服务
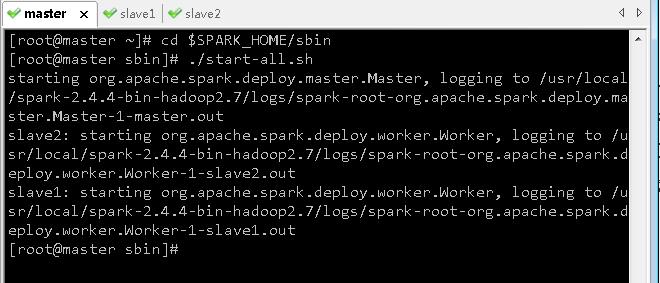
- 进入Spark的
sbin目录执行命令:./start-all.sh
三、实现步骤
(一)在Spark Shell里完成任务
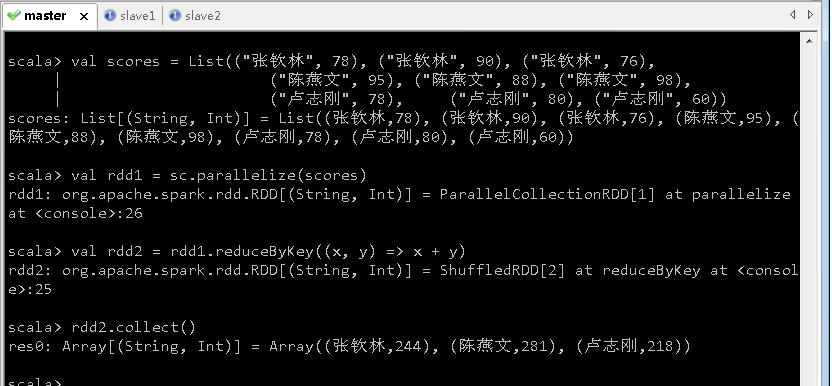
- 创建成绩列表
scores,基于成绩列表创建rdd1,对rdd1按键归约得到rdd2,然后查看rdd2内容
(二)编写Scala程序完成任务
1、创建Maven项目 - RDDDemo
- 设置
GroupId与ArtifactId
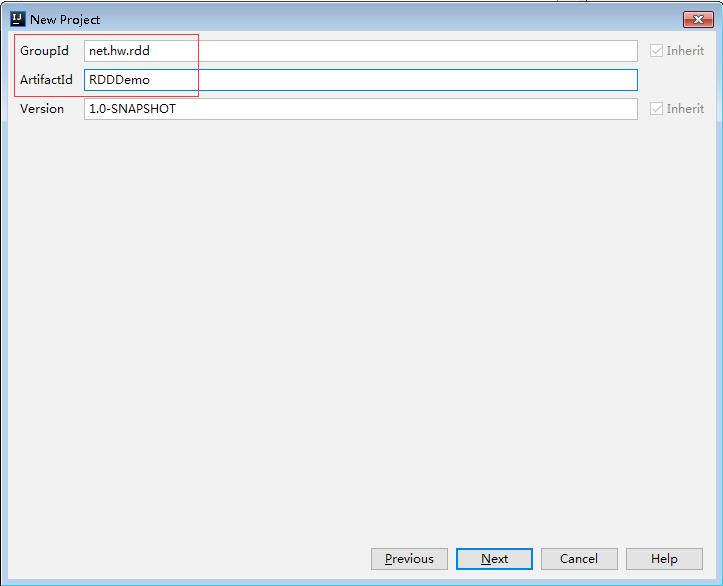
- 设置项目名称与项目保存位置

- 单击【Finish】按钮
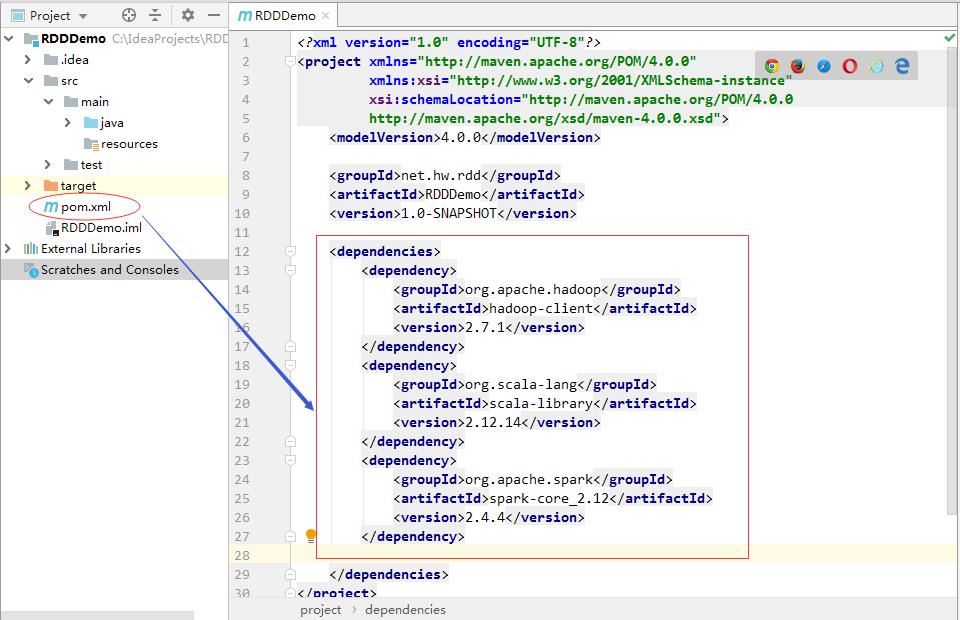
2、添加对hadoop、scala和spark的依赖
- 在pom.xml文件里添加对hadoop、scala和spark的依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>net.hw.rdd</groupId>
<artifactId>RDDDemo</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.1</version>
</dependency>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.14</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>2.4.4</version>
</dependency>
</dependencies>
</project>
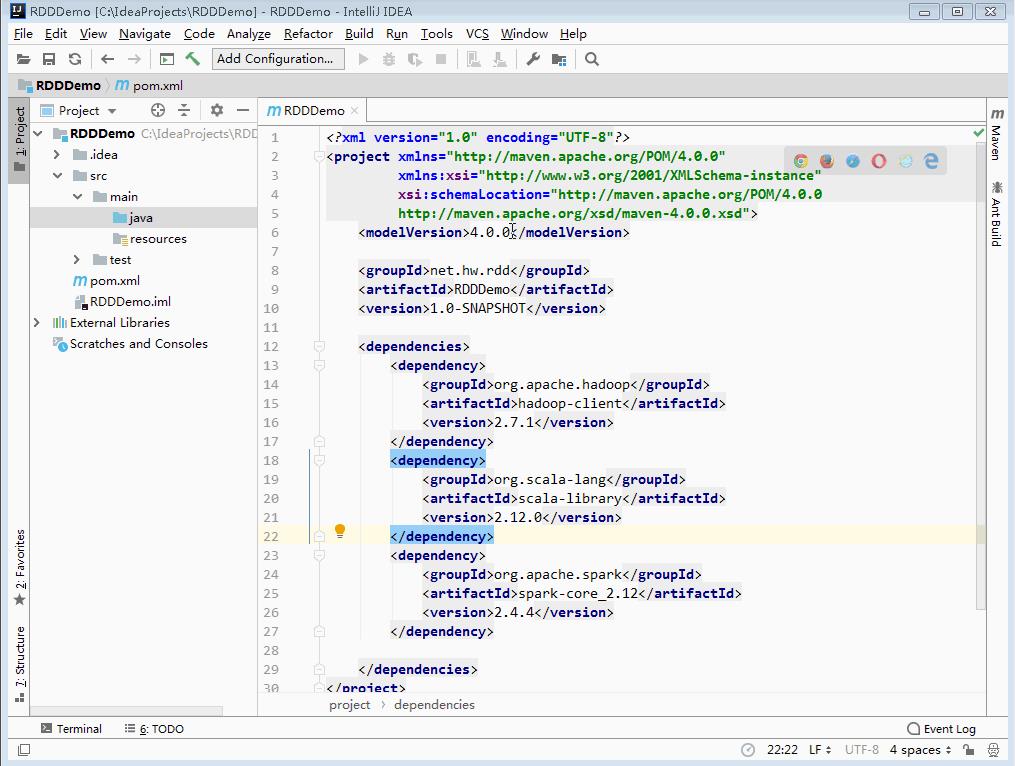
3、给Maven项目配置Scala SDK
- 我们已经安装了
scala-sdk_2.13.8
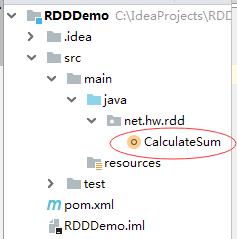
4、创建CalculateSum单例对象
- 创建
net.hw.rdd包,在包里创建CalculateSum单例对象
package net.hw.rdd
import org.apache.spark.SparkConf, SparkContext
/**
* 功能:计算学生总分
* 作者:华卫
* 日期:2022年03月13日
*/
object CalculateSum
def main(args: Array[String]): Unit =
// 创建Spark配置对象
val conf = new SparkConf()
conf.setAppName("CalculateSum")
conf.setMaster("spark://master:7077")
conf.set("spark.testing.memory", "2147480000")
// 基于配置创建Spark上下文
val sc = new SparkContext(conf)
// 创建成绩列表
val scores = List(("张钦林", 78), ("张钦林", 90), ("张钦林", 76),
("陈燕文", 95), ("陈燕文", 88), ("陈燕文", 98),
("卢志刚", 78), ("卢志刚", 80), ("卢志刚", 60))
// 基于成绩列表创建rdd1
val rdd1 = sc.parallelize(scores)
// 对rdd1按键归约得到rdd2,统计学生总分
val rdd2 = rdd1.reduceByKey((x, y) => x + y)
// 将rdd2内容保存到HDFS
rdd2.saveAsTextFile("hdfs://master:9000/park/result")
5、运行程序,查看结果
- 运行程序
CalculateSum,结果报错了
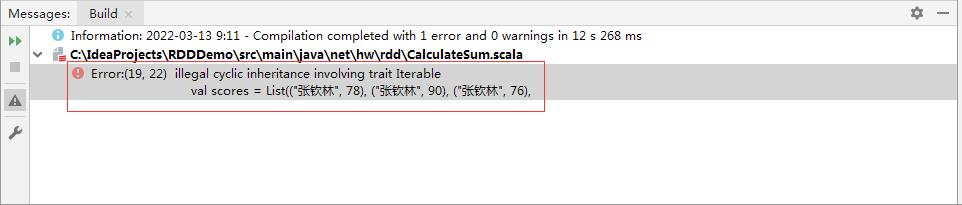
- 出错的原因在于spark-2.4.4的内核是
spark-core_2.12,不支持我们安装的Scala版本scala-2.13.8 - 下载https://downloads.lightbend.com/scala/2.12.14/scala-2.12.14.zip
6、安装配置scala-2.12.14
2.4.x的spark ⟹ \\Longrightarrow ⟹ 选择2.12.x的scala

- 解压到指定位置,比如C盘根目录
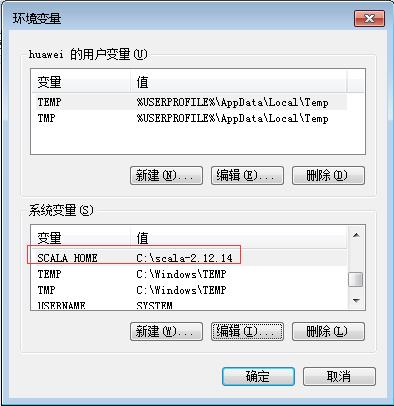
- 修改Scala环境变量
SCALA_HOME的值
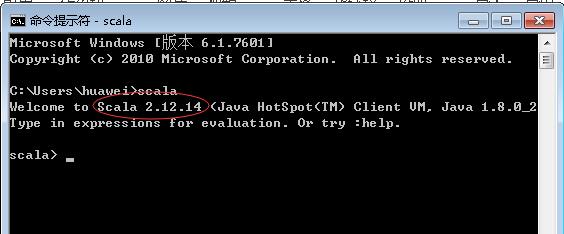
- 在命令行启动Scala,查看其版本
7、更改项目使用的Scala SDK
- 打开项目结构窗口,将项目使用的Scala SDK改成
scala-sdk-2.12.14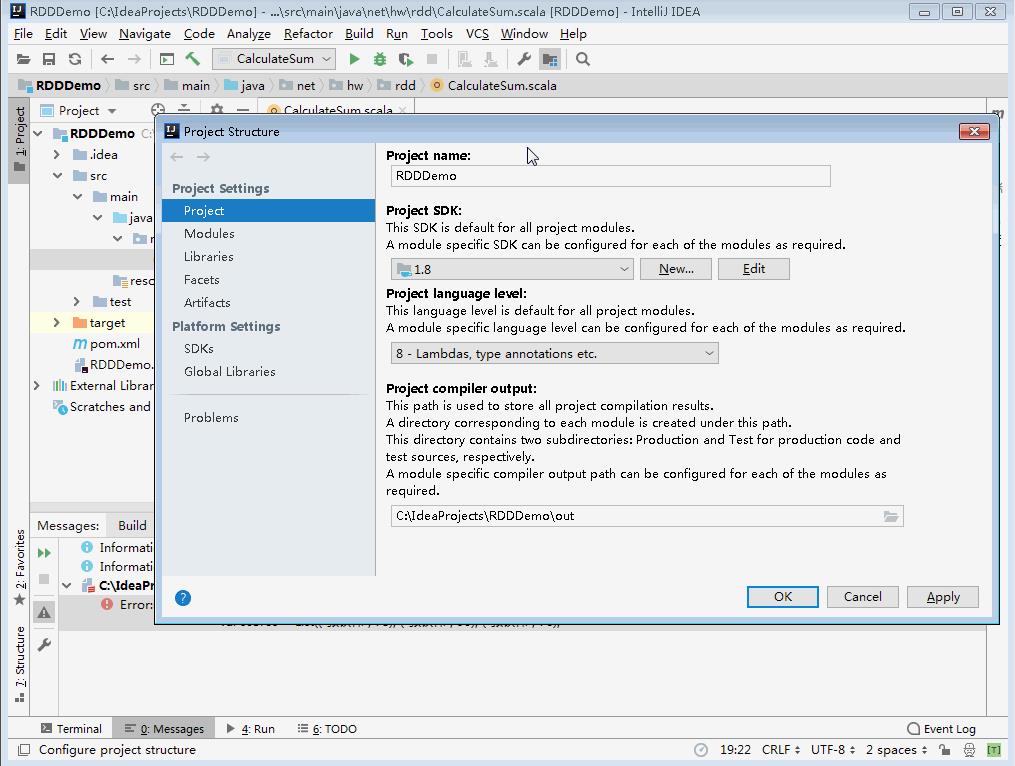
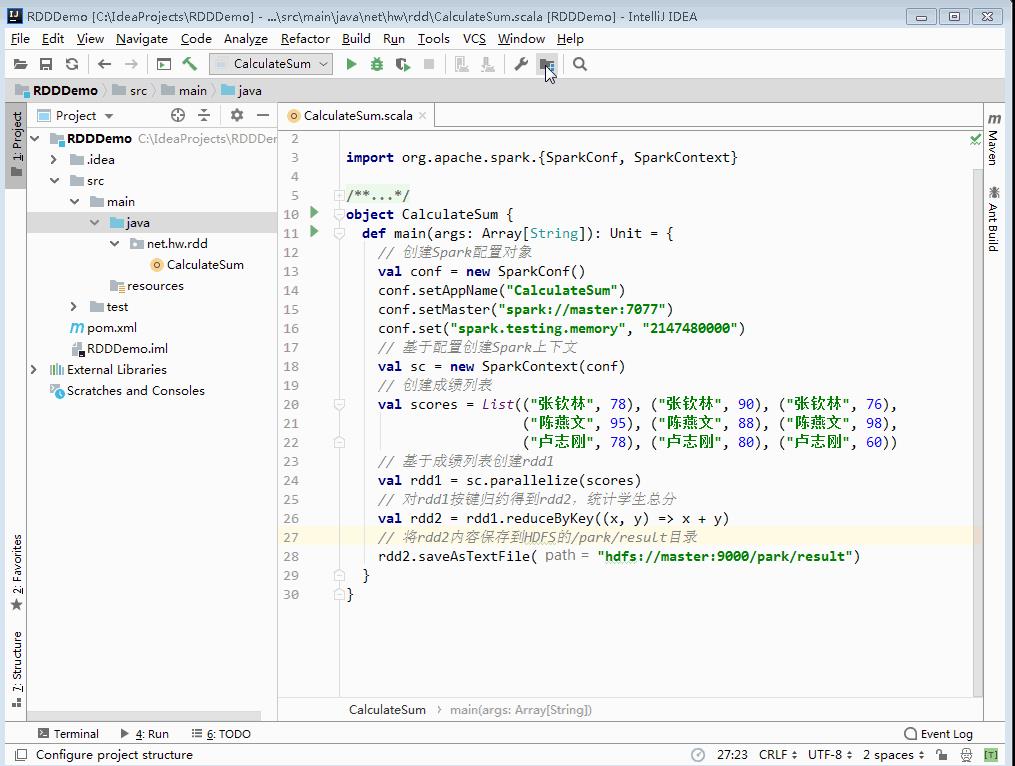
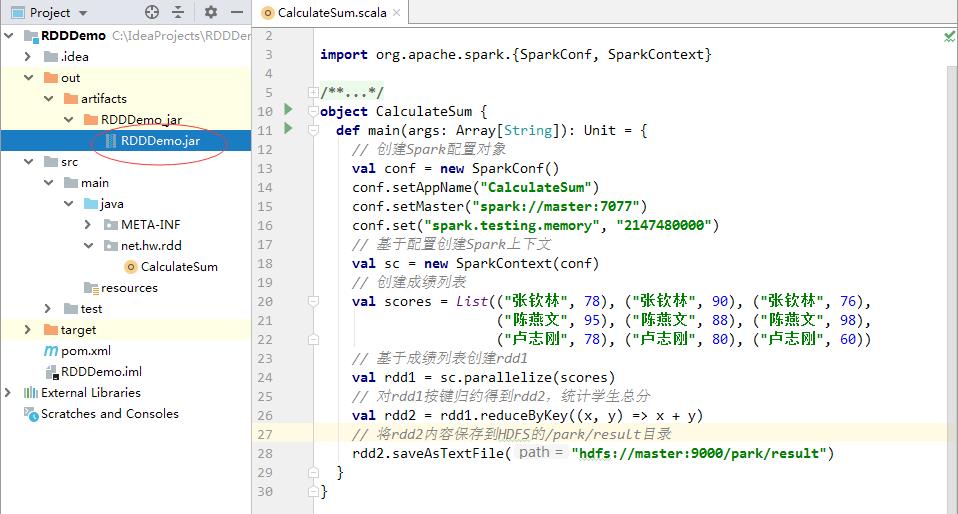
8、将项目打成jar包 - RDDDemo.jar
- 利用IDEA将项目RDDDemo打成jar包
9、将RDDDemo.jar包上传到虚拟机
- 将RDDDemo.jar包上传到master虚拟机
10、将jar包提交到Spark服务器运行
- 执行命令:
spark-submit --class net.hw.rdd.CalculateSum ./RDDDemo.jar

11、在HDFS上查看程序运行结果
- 利用Hadoop的WebUI查看
/park/result目录
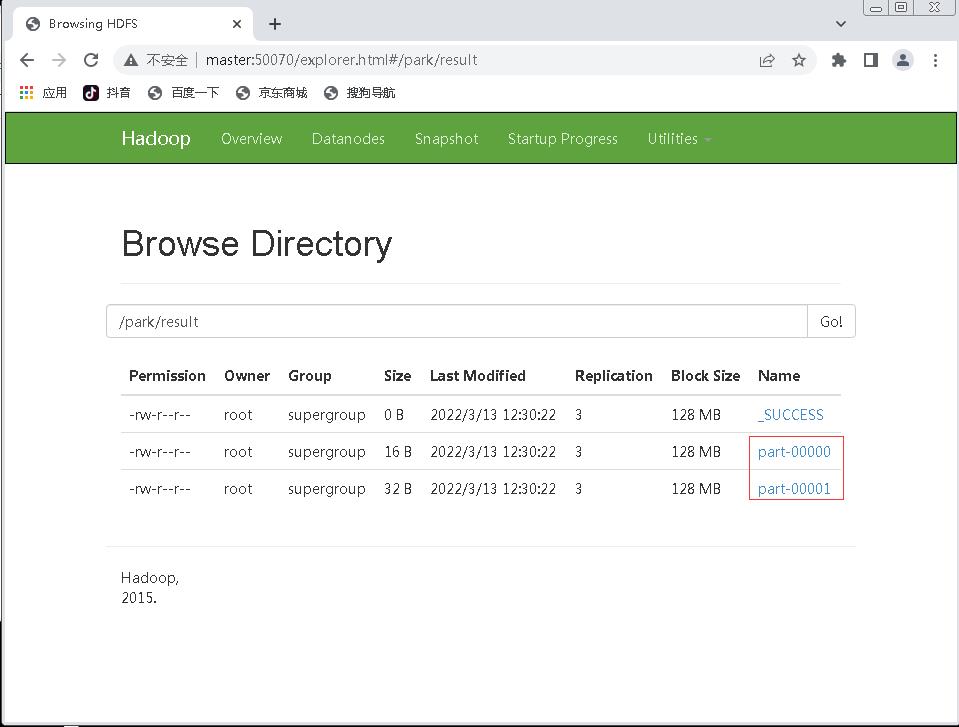
_SUCCESS表明程序运行成功- 有两个结果文件:
part-00000和part-00001 - 执行命令:
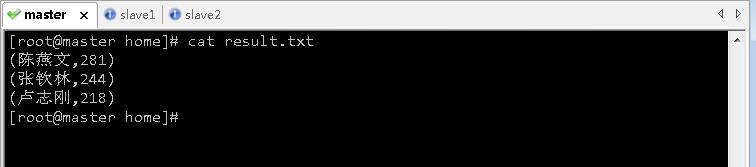
hdfs dfs -getmerge /park/result /home/result.txt,将两个结果文件合并下载到本地/home/result.txt

- 查看本地结果文件
/home/result.txt
以上是关于Spark RDD算子案例:两种方式计算学生总分的主要内容,如果未能解决你的问题,请参考以下文章