如何打造一款极速数据湖分析引擎
Posted 阿里云云栖号
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何打造一款极速数据湖分析引擎相关的知识,希望对你有一定的参考价值。
简介:本文向读者详细揭秘了数据湖分析引擎的关键技术,并通过 StarRocks 来帮助用户进一步理解系统的架构。
作者:
阿里云 EMR 开源大数据 OLAP 团队
StarRocks 社区数据湖分析团队
前言
随着数字产业化和产业数字化成为经济驱动的重要动力,企业的数据分析场景越来越丰富,对数据分析架构的要求也越来越高。新的数据分析场景催生了新的需求,主要包括三个方面:
- 用户希望用更加低廉的成本,更加实时的方式导入并存储任何数量的关系数据数据(例如,来自业务线应用程序的运营数据库和数据)和非关系数据(例如,来自移动应用程序、IoT 设备和社交媒体的运营数据库和数据)
- 用户希望自己的数据资产受到严密的保护
- 用户希望数据分析的速度变得更快、更灵活、更实时
数据湖的出现很好的满足了用户的前两个需求,它允许用户导入任何数量的实时获得的数据。用户可以从多个来源收集数据,并以其原始形式存储到数据湖中。数据湖拥有极高的水平扩展能力,使得用户能够存储任何规模的数据。同时其底层通常使用廉价的存储方案,使得用户存储数据的成本大大降低。数据湖通过敏感数据识别、分级分类、隐私保护、资源权限控制、数据加密传输、加密存储、数据风险识别以及合规审计等措施,帮助用户建立安全预警机制,增强整体安全防护能力,让数据可用不可得和安全合规。
为了进一步满足用户对于数据湖分析的要求,我们需要一套适用于数据湖的分析引擎,能够在更短的时间内从更多来源利用更多数据,并使用户能够以不同方式协同处理和分析数据,从而做出更好、更快的决策。本篇文章将向读者详细揭秘这样一套数据湖分析引擎的关键技术,并通过 StarRocks 来帮助用户进一步理解系统的架构。
之后我们会继续发表两篇文章,来更详细地介绍极速数据湖分析引擎的内核和使用案例:
- 代码走读篇:通过走读 StarRocks 这个开源分析型数据库内核的关键数据结构和算法,帮助读者进一步理解极速数据湖分析引擎的原理和具体实现 。
- Case Study 篇:介绍大型企业如何使用 StarRocks 在数据湖上实时且灵活的洞察数据的价值,从而帮助业务进行更好的决策,帮助读者进一步理解理论是如何在实际场景落地的 。
什么是数据湖?
什么是数据湖,根据 Wikipedia 的定义,“A data lake is a system or repository of data stored in its natural/raw format, usually object blobs or files”。通俗来说可以将数据湖理解为在廉价的对象存储或分布式文件系统之上包了一层,使这些存储系统中离散的 object 或者 file 结合在一起对外展现出一个统一的语义,例如关系型数据库常见的“表”语义等。
了解完数据湖的定义之后,我们自然而然地想知道数据湖能为我们提供什么独特的能力,我们为什么要使用数据湖?
在数据湖这个概念出来之前,已经有很多企业或组织大量使用 HDFS 或者 S3 来存放业务日常运作中产生的各式各样的数据(例如一个制作 APP 的公司可能会希望将用户所产生的点击事件事无巨细的记录)。因为这些数据的价值不一定能够在短时间内被发现,所以找一个廉价的存储系统将它们暂存,期待在将来的一天这些数据能派上用场的时候再从中将有价值的信息提取出来。然而 HDFS 和 S3 对外提供的语义毕竟比较单一(HDFS 对外提供文件的语义,S3 对外提供对象的语义),随着时间的推移工程师们可能都无法回答他们到底在这里面存储了些什么数据。为了防止后续使用数据的时候必须将数据一一解析才能理解数据的含义,聪明的工程师想到将定义一致的数据组织在一起,然后再用额外的数据来描述这些数据,这些额外的数据被称之为“元”数据,因为他们是描述数据的数据。这样后续通过解析元数据就能够回答这些数据的具体含义。这就是数据湖最原始的作用。
随着用户对于数据质量的要求越来越高,数据湖开始丰富其他能力。例如为用户提供类似数据库的 ACID 语义,帮助用户在持续写入数据的过程中能够拿到 point-in-time 的视图,防止读取数据过程中出现各种错误。或者是提供用户更高性能的数据导入能力等,发展到现在,数据湖已经从单纯的元数据管理变成现在拥有更加丰富,更加类似数据库的语义了。
用一句不太准确的话描述数据湖,就是一个存储成本更廉价的“AP 数据库”。但是数据湖仅仅提供数据存储和组织的能力,一个完整的数据库不仅要有数据存储的能力,还需要有数据分析能力。因此怎么为数据湖打造一款高效的分析引擎,为用户提供洞察数据的能力,将是本文所要重点阐述的部分。下面通过如下几个章节一起逐步拆解一款现代的 OLAP 分析引擎的内部构造和实现:
- 怎么在数据湖上进行极速分析
- 现代数据湖分析引擎的架构
怎么在数据湖上进行极速分析?
从这一节开始,让我们开始回到数据库课程,一个用于数据湖的分析引擎和一个用于数据库的分析引擎在架构上别无二致,通常我们认为都会分为下面几个部分:
- Parser:将用户输入的查询语句解析成一棵抽象语法树
- Analyzer:分析查询语句的语法和语义是否正确,符合定义
- Optimizer:为查询生成性能更高、代价更低的物理查询计划
- Execution Engine:执行物理查询计划,收集并返回查询结果
对于一个数据湖分析引擎而言,Optimizer 和 Execution Engine 是影响其性能两个核心模块,下面我们将从三个维度入手,逐一拆解这两个模块的核心技术原理,并通过不同技术方案的对比,帮助读者理解一个现代的数据湖分析引擎的始末。
RBO vs CBO
基本上来讲,优化器的工作就是对给定的一个查询,生成查询代价最低(或者相对较低)的执行计划。不同的执行计划性能会有成千上万倍的差距,查询越复杂,数据量越大,查询优化越重要。
Rule Based Optimization (RBO) 是传统分析引擎常用的优化策略。RBO 的本质是核心是基于关系代数的等价变换,通过一套预先制定好的规则来变换查询,从而获得代价更低的执行计划。常见的 RBO 规则谓词下推、Limit 下推、常量折叠等。在 RBO 中,有着一套严格的使用规则,只要你按照规则去写查询语句,无论数据表中的内容怎样,生成的执行计划都是固定的。但是在实际的业务环境中,数据的量级会严重影响查询的性能,而 RBO 是没法通过这些信息来获取更优的执行计划。
为了解决 RBO 的局限性,Cost Based Optimization (CBO) 的优化策略应运而生。CBO 通过收集数据的统计信息来估算执行计划的代价,这些统计信息包括数据集的大小,列的数量和列的基数等信息。举个例子,假设我们现在有三张表 A,B 和 C,在进行 A join B join C 的查询时如果没有对应的统计信息我们是无法判断不同 join 的执行顺序代价上的差异。如果我们收集到这三张表的统计信息,发现 A 表和 B 表的数据量都是 1M 行,但是 C 表的 数据量仅为 10 行,那么通过先执行 B join C 可以大大减少中间结果的数据量,这在没有统计信息的情况下基本不可能判断。
随着查询复杂度的增加,执行计划的状态空间会变的非常巨大。刷过算法题的小伙伴都知道,一旦状态空间非常大,通过暴力搜索的方式是不可能 AC 的,这时候一个好的搜索算法格外重要。通常 CBO 使用动态规划算法来得到最优解,并且减少重复计算子空间的代价。当状态空间达到一定程度之后,我们只能选择贪心算法或者其他一些启发式算法来得到局部最优。本质上搜索算法是一种在搜索时间和结果质量做 trade-off 的方法。

(常见 CBO 实现架构)
Record Oriented vs Block Oriented
执行计划可以认为是一串 operator(关系代数的运算符)首尾相连串起来的执行流,前一个 operator 的 output 是下一个 operator 的 input。传统的分析引擎是 Row Oriented 的,也就是说 operator 的 output 和 input 是一行一行的数据。
举一个简单的例子,假设我们有下面一个表和查询:
CREATE TABLE t (n int, m int, o int, p int); SELECT o FROM t WHERE m < n + 1;
例子来源: GitHub - jordanlewis/exectoy
上述查询语句展开为执行计划的时候大致如下图所示:

通常情况下,在 Row Oriented 的模型中,执行计划的执行过程可以用如下伪码表示:
next:
for:
row = source.next()
if filterExpr.Eval(row):
// return a new row containing just column o
returnedRow row
for col in selectedCols:
returnedRow.append(row[col])
return returnedRow
根据 DBMSs On A Modern Processor: Where Does Time Go? 的评估,这种执行方式存在大量的 L2 data stalls 和 L1 I-cache stalls、分支预测的效率低等问题。
随着磁盘等硬件技术的蓬勃发展,各种通过 CPU 换 IO 的压缩算法、Encoding 算法和存储技术的广泛使用,CPU 的性能逐渐成为成为分析引擎的瓶颈。为了解决 Row Oriented 执行所存在的问题,学术界开始思考解决方案,Block oriented processing of Relational Database operations in modern Computer Architectures 这篇论文提出使用按 block 的方式在 operator 之间传递数据,能够平摊条件检查和分支预测的工作的耗时,MonetDB/X100: Hyper-Pipelining Query Execution 在此基础上更进一步,提出将通过将数据从原来的 Row Oriented,改变成 Column Oriented,进一步提升 CPU Cache 的效率,也更有利于编译器进行优化。在 Column Oriented 的模型中,执行计划的执行过程可以用如下伪码表示:
// first create an n + 1 result, for all values in the n column
projPlusIntIntConst.Next():
batch = source.Next()
for i < batch.n:
outCol[i] = intCol[i] + constArg
return batch
// then, compare the new column to the m column, putting the result into
// a selection vector: a list of the selected indexes in the column batch
selectLTIntInt.Next():
batch = source.Next()
for i < batch.n:
if int1Col < int2Col:
selectionVector.append(i)
return batch with selectionVector
// finally, we materialize the batch, returning actual rows to the user,
// containing just the columns requested:
materialize.Next():
batch = source.Next()
for s < batch.n:
i = selectionVector[i]
returnedRow row
for col in selectedCols:
returnedRow.append(cols[col][i])
yield returnedRow
可以看到,Column Oriented 拥有更好的数据局部性和指令局部性,有利于提高 CPU Cache 的命中率,并且编译器更容易执行 SIMD 优化等。
Pull Based vs Push Based
数据库系统中,通常是将输入的 SQL 语句转化为一系列的算子,然后生成物理执行计划用于实际的计算并返回结果。在生成的物理执行计划中,通常会对算子进行 pipeline。常见的 pipeline 方式通常有两种:
- 基于数据驱动的 Push Based 模式,上游算子推送数据到下游算子
- 基于需求的 Pull Based 模式,下游算子主动从上游算子拉取数据。经典的火山模型就是 Pull Based 模式。
Push Based 的执行模式提高了缓存效率,能够更好地提升查询性能。
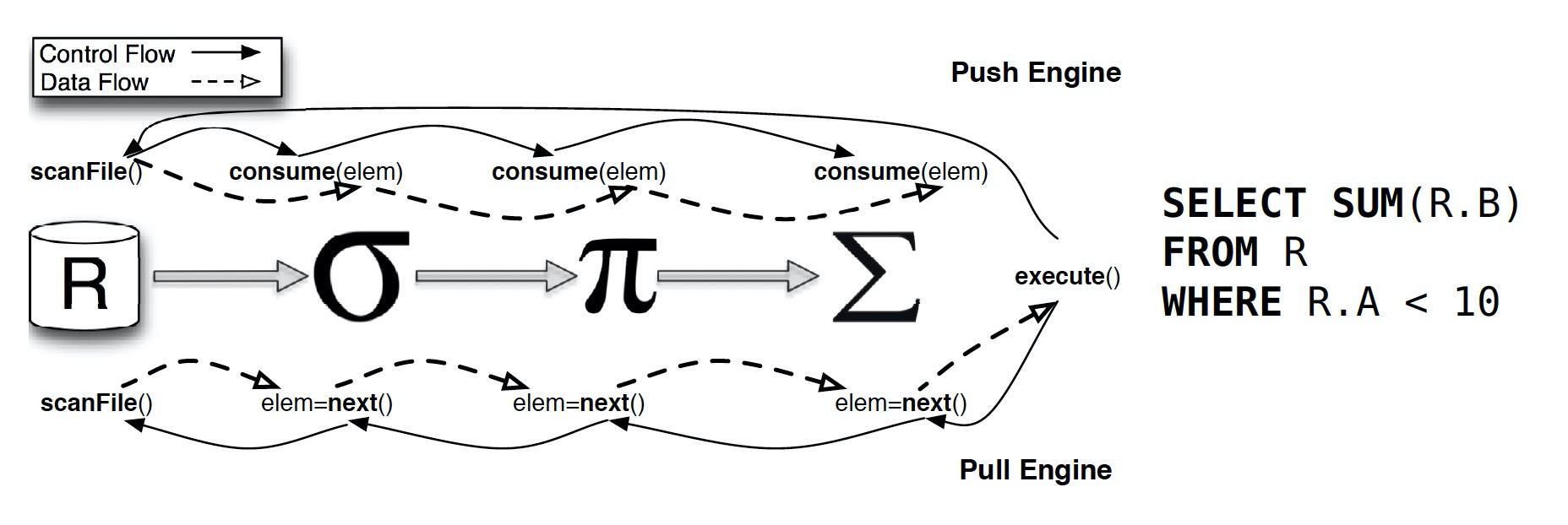
参考:Push vs. Pull-Based Loop Fusion in Query Engines
现代数据湖分析引擎的架构
通过上一节的介绍,相信读者已经对数据湖分析引擎的前沿理论有了相应了解。在本节中,我们以 StarRocks 为例,进一步介绍数据湖分析引擎是怎么有机的结合上述先进理论,并且通过优雅的系统架构将其呈现给用户。

如上图所示,StarRocks 的架构非常简洁,整个系统的核心只有 Frontend (FE)、Backend (BE) 两类进程,不依赖任何外部组件,方便部署与维护。其中 FE 主要负责解析查询语句(SQL),优化查询以及查询的调度,而 BE 则主要负责从数据湖中读取数据,并完成一系列的 Filter 和 Aggregate 等操作。
Frontend
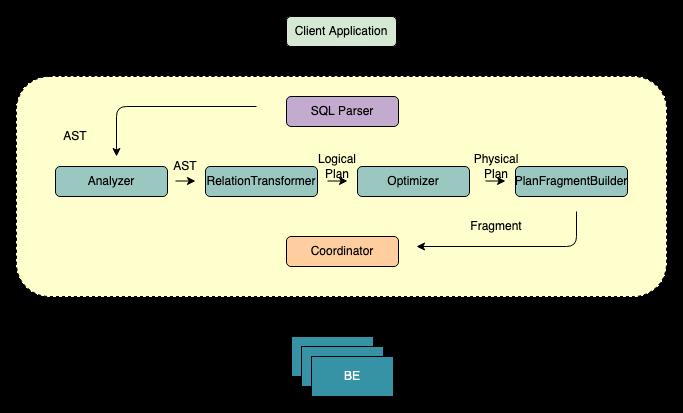
FE 的主要作用将 SQL 语句通过一系列转化和优化,最终转换成 BE 能够认识的一个个 Fragment。一个不那么准确但易于理解的比喻,如果把 BE 集群当成一个分布式的线程池的话,那么 Fragment 就是线程池中的 Task。从 SQL 文本到 Fragment,FE 的主要工作包含以下几个步骤:
- SQL Parse:将 SQL 文本转换成一个 AST(抽象语法树)
- Analyze:基于 AST 进行语法和语义分析
- Logical Plan:将 AST 转换成逻辑计划
- Optimize:基于关系代数,统计信息,Cost 模型对逻辑计划进行重写,转换,选择出 Cost “最低” 的物理执行计划
- 生成 Fragment:将 Optimizer 选择的物理执行计划转换为 BE 可以直接执行的 Fragment
- Coordinate:将 Fragment 调度到合适的 BE 上执行
Backend
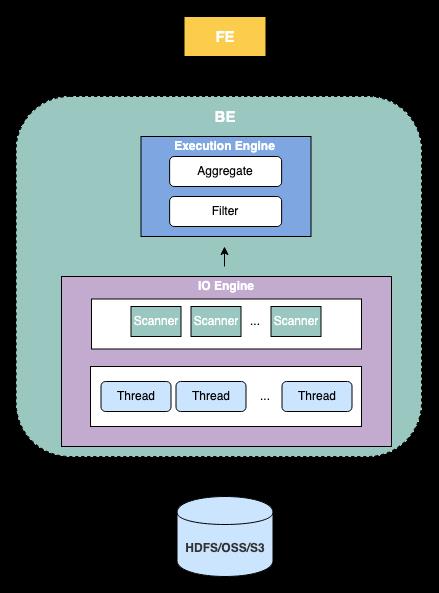
BE 是 StarRocks 的后端节点,负责接收 FE 传下来的 Fragment 执行并返回结果给 FE。StarRocks 的 BE 节点都是完全对等的,FE 按照一定策略将数据分配到对应的 BE 节点。常见的 Fragment 工作流程是读取数据湖中的部分文件,并调用对应的 Reader (例如,适配 Parquet 文件的 Parquet Reader 和适配 ORC 文件的 ORC Reader等)解析这些文件中的数据,使用向量化执行引擎进一步过滤和聚合解析后的数据后,返回给其他 BE 或 FE。
总结
本篇文章主要介绍了极速数据湖分析引擎的核心技术原理,从多个维度对比了不同技术实现方案。为方便接下来的深入探讨,进一步介绍了开源数据湖分析引擎 StarRocks 的系统架构设计。希望和各位同仁共同探讨、交流。
附录
基准测试
本次测试采用的 TPCH 100G 的标准测试集,分别对比测试了 StarRocks 本地表,StarRocks On Hive 和 Trino(PrestoSQL) On Hive 三者之间的性能差距。
在TPCH 100G规模的数据集上进行对比测试,共22个查询,结果如下:

StarRocks 使用本地存储查询和 Hive 外表查询两种方式进行测试。其中,StarRocks On Hive 和 Trino On Hive 查询的是同一份数据,数据采用 ORC 格式存储,采用 zlib 格式压缩。测试环境使用 阿里云 EMR 进行构建。
最终,StarRocks 本地存储查询总耗时为21s,StarRocks Hive 外表查询总耗时92s。Trino 查询总耗时307s。可以看到 StarRocks On Hive 在查询性能方面远远超过 Trino,但是对比本地存储查询还有不小的距离,主要的原因是访问远端存储增加了网络开销,以及远端存储的延时和 IOPS 通常都不如本地存储,后面的计划是通过 Cache 等机制弥补问题,进一步缩短 StarRocks 本地表和 StarRocks On Hive 的差距。
参考资料
[1] GitHub - jordanlewis/exectoy
[2] DBMSs On A Modern Processor: Where Does Time Go?
[3] Block oriented processing of Relational Database operations in modern Computer Architectures
[4] MonetDB/X100: Hyper-Pipelining Query Execution
[5] StarRocks - 开源大数据平台E-MapReduce - 阿里云
本文为阿里云原创内容,未经允许不得转载。
以上是关于如何打造一款极速数据湖分析引擎的主要内容,如果未能解决你的问题,请参考以下文章