Python每日学习笔记之Dictionary
Posted 超凡脫俗
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python每日学习笔记之Dictionary相关的知识,希望对你有一定的参考价值。
字典概念
字典是python中的内置数据结构,它非常适合表达结构化数据(人:姓名,性别,身高等这种就是结构化数据)
字典采用键(key):值(value)形式表达数据,key不允许重复,value允许重复,字典可修改,运行时动态存储空间
创建方式两种:使用创建 ,或使用dict函数来创建;
散列值(Hash)
字典也被称为’哈希‘,对应散列值;
散列值是从任何一种数据中创建数字“指纹”,唯一标识
python提供了hash()函数生成了散列值
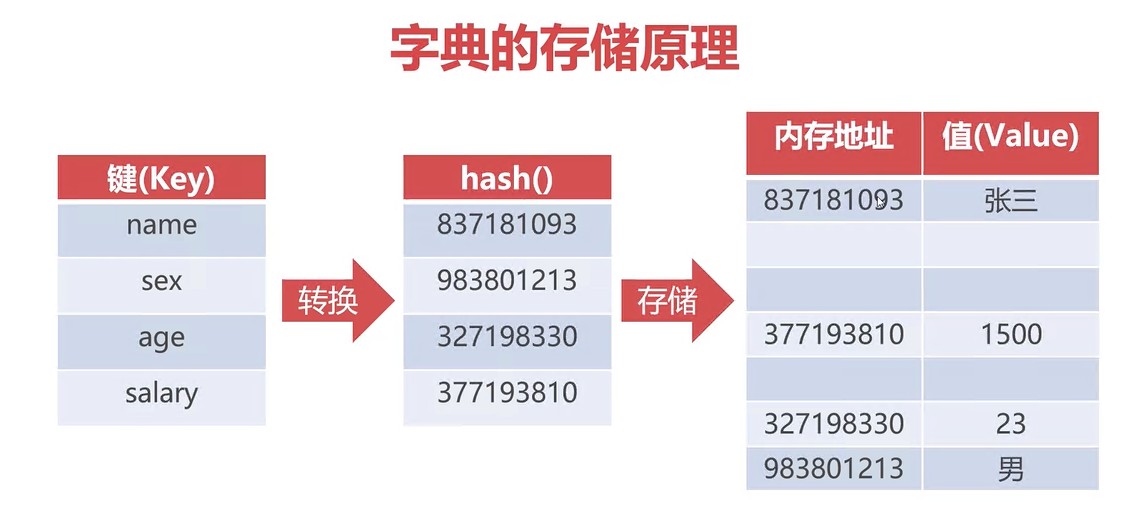
字典存储原理
在一个字典中,python中字典要保存时,会先将key转换成对应的散列值,根据散列值在内存中开辟一段空间,对于这块会预留空闲空间,同时将哈希值经过换算以后,找到对应的内存地址,再将数据保存在内存地址中。
1、根据哈希散列值进行分散存储;
2、并不按key顺序排列,无序排列;
3、数据提取速度非常快,每个key在内存中保存的都是一个具体的散列值,而这个散列值对应了唯一的内存地址,对字典数据提取要比列表高效,对于结构化数据,建议作为存储结构来使用;
1.字典的创建
# -*- codeing = utf-8 -*-
# @Time :2022/3/9 22:02
# @Author :Josh
# @Email :980521387@qq.com
# @Version :1.0
# @Descriptioon :
# @File : sample1.py
#1.1使用
dict1 = #空的字典
print(type(dict1))
dict2 = 'name':'王峰',
'sex':'男',
'hiredate':'1997-10-20',
'grade':'A',
'job':'销售',
'welfare':'100'
print(dict2)
#1.2使用dict函数创建字典
dict3 = dict(name ='王峰',
sex='男',
hiredate ='1997-10-20',
)
print(dict3)
dict4 = dict.fromkeys(['name','sex','hiredate','grade'],'N/A') #N/A是设置的默认值
print(dict4)
2.字典的取值操作
2.字典的取值操作
2.1 get函数可以为不存在的key赋予默认值
2.2 items()包含每一个键值对
'''
employee = 'name':'王峰',
'sex':'男',
'hiredate':'1997-10-20',
'grade':'A',
'job':'销售',
'salary':1000,
'welfare':100
#2.1 字典的取值
name = employee['name']
print(name)
salary = employee['salary']
print(salary)
print(employee.get('job'))
print(employee.get('dept')) #对于不存在列表的‘dept’,使用get可以让返回值为none,而不是报错
print(employee.get('dept','其他部门')) #get函数可以为不存在的key赋予默认值
#2.2 如果要判断在产品中,某一个key是否存在,如何判断
# in 成员运算符
print('name' in employee) #返回ture
print('dept' in employee) #返回false
#2.3 或使用 not in,与in结果相反
print('name' not in employee)
print('dept' not in employee)
#2.4 遍历字典
for key in employee:
v = employee[key] #[]中括号会返回key的值
print(v)
for k,v in employee.items(): #对于employee.items(),它会返回字典中的每一个键值对
print(k,v)
3.字典的更新操作
'''
3.字典的更新操作
3.1 字典单个k:v更新
3.2 字典多个k:v更新使用update
3.3 字典的新增操作与更新操作完全相同,秉承有则更新,无则新增的原则
3.4 删除字典三种方法:pop函数、popitem函数、clear函数,pop使用最广泛
'''
employee = 'name':'王峰',
'sex':'男',
'hiredate':'1997-10-20',
'grade':'A',
'job':'销售',
'salary':1000,
'welfare':100
#3.1 对单个key:value更新,字典中,王峰评级从A变至B
print(employee)
employee['grade'] = 'B'
print(employee)
#3.2 对多个k:v进行更新,使用update()方法
employee.update(salary = 1200,welfare = 150)
print(employee)
#3.3 字典的新增操作与更新操作完全相同,秉承有则更新,无则新增的原则
employee['dept'] = '研发部'
print(employee)
employee['dept'] = '市场部'
print(employee)
employee.update(weight=80,dept='财务部')
print(employee)
#3.4 删除操作
#3.4.1 pop函数,删除指定的kv
employee.pop('weight')
print(employee)
#3.4.2 popitem函数,删除最后一个kv
kv = employee.popitem() #删除最后1个 一次
kv = employee.popitem() #删除最后1个 两次
print(kv)
print(employee)
#3.4.3 clear 清空字典
employee.clear()
print(employee)
4.字典的常用操作
# -*- codeing = utf-8 -*-
# @Time :2022/3/9 23:10
# @Author :Josh
# @Email :980521387@qq.com
# @Version :1.0
# @Descriptioon :
# @File : sample4.py
'''
4.字典的常用操作
4.1 setdefault()函数为字典设置默认值
4.2 字典的视图
4.3 字典格式化字符串
'''
emp1 = 'name':'Jacky','grade':'B'
emp2 = 'name':'Lily'
emp21 = 'name':'josh'
#4.1 为字典设置默认值,
#4.1.1 新员工当月默认考评为c,使用if判断效率较低,可实现
if 'grade' not in emp2:
emp2['grade'] = 'C'
print(emp2)
print('\\n')
#4.1.2 setdefault为字典设置默认值,如果某个key已存在则忽略,不存在则设置
print('setdefault为字典设置默认值')
emp1.setdefault('grade','c') #设置emp1
emp21.setdefault('grade','c') #设置emp21
print(emp21)
print('\\n')
#4.2 获取字典的视图
'''
(1)keys 代表获取所有的键
(2)values 代表获取所有的值
(3)items代表获取所有的键值对
'''
# 4.2.1 keys 获取所有的键
print('keys 获取所有的键')
ks = emp1.keys()
print(ks)
print(type(ks))
#4.2.2 values 获取所有的值
print('kvalues 获取所有的值')
vs = emp1.values()
print(vs)
print(type(vs))
#4.2.3 items获取所有键值对,获取后打印出的kv都是元组方式保存
print('items获取所有键值对')
its = emp1.items()
print(its)
print(type(its))
print('\\n')
#4.2.4视图用意:
# 例如下面emp1新增 hiredate会,视图随着原始数据变化进行联动,如下列便在其末尾新增上hiredate的数据,
print('视图用意')
emp1 ['hiredate'] = '1984-05-30'
print(ks)
print(vs)
print(its)
print('\\n')
#4.3 利用字典格式化字符串
#4.3.1 老版本的字符串格式化
print('老版本的字符串格式化:')
emp_str = "姓名:%(name)s,评级:%(grade)s,入职时间:%(hiredate)s"%emp1
print(emp_str)
print('\\n')
#4.3.2 新版字符串格式化,
# 新版优点:简单,可读性更好
print('新版字符串格式化')
emp_str1 = "姓名:name,评级:grade,入职时间:hiredate".format_map(emp1)
print(emp_str1)
5. 散列值
# -*- codeing = utf-8 -*-
# @Time :2022/3/9 23:50
# @Author :Josh
# @Email :980521387@qq.com
# @Version :1.0
# @Descriptioon :
# @File : sample5.py
'''
5.散列值(Hash)
字典也被称为’哈希‘,对应散列值;
散列值是从任何一种数据中创建数字“指纹”,唯一标识
python提供了hash()函数生成了散列值
5.1
整数的hash值就是它自己
散列值无论调用多次,abc生成的散列值都是相同的
每次运行的数据都不相同,但同一次运行中,hash的数据都是相同的额
hash是字典应用的最底层实现
5.2 字典的存储原理
在一个字典中,python中字典要保存时,会先将key转换成对应的散列值,根据散列值在内存中开辟一段空间,对于这块会预留空闲空间,
同时将哈希值经过换算以后,找到对应的内存地址,再将数据保存在内存地址中。
1、根据哈希散列值进行分散存储
2、并不按key顺序排列,无序排列
3、数据提取速度非常快,每个key在内存中保存的都是一个具体的散列值,而这个散列值对应了唯一的内存地址,对字典数据提取要比列表高效,
对于结构化数据,建议作为存储结构来使用;
'''
h1 = hash('abc')
print(h1)
h2 = hash('bcd')
print(h2)
h3 = hash(8838183) #整数的hash值就是它自己
print(h3)
h4 = hash('abc') #散列值无论调用多次,abc生成的散列值都是相同的
print(h4)
h5 = hash('def') #每次运行的数据都不相同,但同一次运行中,hash的数据都是相同的数额
print(h5)
#6.1 财务系统 -处理员工数据
source = "7782,CLARK,MANAGER,SALES,5000$7934,MILLER,SALESMAN,SALEES,3000$7369,SMITH,ANALYST,RESEARCH,2000"
employee_list = source.split("$") #解析成字符串
print(employee_list)
#保存所有解析后的员工信息,key是员工编号,value则是包含完整员工信息的字典
all_emp =
for i in range(0,len(employee_list)): #从第一个元素开始,到emp_list最后一个元素结束,取出索引值
#print(i)
e = employee_list[i].split(",") #通过split 使用,进行切割
print(e)
#创建员工字典
employee = "no":e[0],"name":e[1],"job":e[2],"departent":e[3],"salary":e[4]
print(employee)
all_emp[employee["no"]]=employee
print(all_emp)
empno = input("请输入员工编号:")
emp = all_emp.get(empno)
if empno in all_emp:
print("工号:no,姓名:name,岗位:job,部门:departent,工资:salary".format_map(emp))
else:
print("工号不存在")
以上是关于Python每日学习笔记之Dictionary的主要内容,如果未能解决你的问题,请参考以下文章