TensorRT-Profiling and 16-bit Inference
Posted 浩瀚之水_csdn
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorRT-Profiling and 16-bit Inference相关的知识,希望对你有一定的参考价值。
前面几节以 LeNet 为例主要介绍了 tensorRT 的简单使用流程。包括,使用 tensorRT 的 NvCaffeParser 工具以及底层 C++ API 来 模型 caffe 解析,构建 tensorRT 模型并部署等。
本节以 GooLeNet 为例,来展示 tensorRT 的优化方法。
例程位于 /usr/src/tensorrt/samples/sampleGoogleNet
这个例程展示的是 TensorRT的layer-based profiling和 half2mode 和 FP16 使用方法。
1 Key Concepts
首先了解几个概念:
-
Profiling a network :就是测量网络每一层的运行时间,可以很方便的看出:使用了TensorRT和没使用TensorRT在时间上的差别。
-
FP16 :FP32 是指 Full Precise Float 32 ,FP 16 就是 float 16。更省内存空间,更节约推理时间。
-
Half2Mode :tensorRT 的一种执行模式(execution mode ),这种模式下 图片上相邻区域的 tensor 是 以16位 交叉存储的方式 存在的。而且在 batchsize 大于 1的情况下,这种模式的运行速度是最快的。(Half2Mode is an execution mode where internal tensors interleave 16-bits from
adjacent pairs of images, and is the fastest mode of operation for batch sizes greater
than one. )这是计算机组成原理中涉及到存储方式的选择,不是很懂。大概是下图这样的:
以下分别是 2D和3D情况:
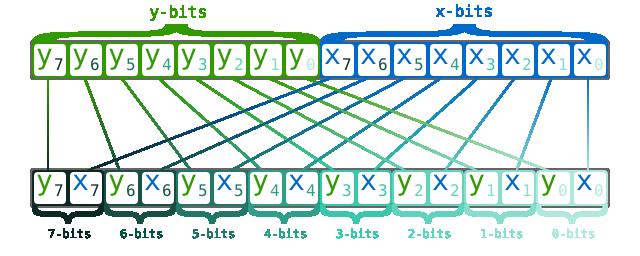
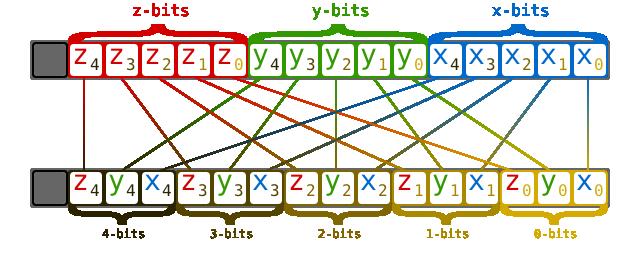
参考这个 顺序存储和交叉存储 ,这样做可以提升存储器带宽。更多详细内容参考文末参考资料。
2 具体做法
2.1 配置 builder
TensorRT3.0的官方文档上说,如果只是使用 float 16 的数据精度代替 float-32 , 实际上并不会有多大的性能提升。真正提升性能的是 half2mode ,也就是上述使用了交叉存存储方式的模式。
如何使用half2mode ?
-
首先 使用float 16 精度的数据 来初始化 network 对象,主要做法就是 在调用NvCaffeParser 工具解析 caffe模型时,使用 DataType::kHALF 参数,如下:
1
2
3
4
5
const IBlobNameToTensor *blobNameToTensor =
parser->parse(locateFile(deployFile).c_str(),
locateFile(modelFile).c_str(),
*network,
DataType::kHALF);
-
配置builder 使用 half2mode ,这个很简单,就一个语句就完成了:
1
builder->setFp16Mode(true);
2.2 Profiling
profiling 一个网络 ,要创建一个 IProfiler 接口并且添加 profiler 到 execution context 中:
| 1 | context.profiler = &gProfiler; |
然后执行时,Profiling不支持异步方式,只支持同步方式,因此要使用 tensorRT的同步执行函数 execute() :
| 1 2 | for (int i = 0; i < TIMING_ITERATIONS;i++) engine->execute(context, buffers); |
执行过程中,每一层都会调用 profiler 回调函数,存储执行时间。
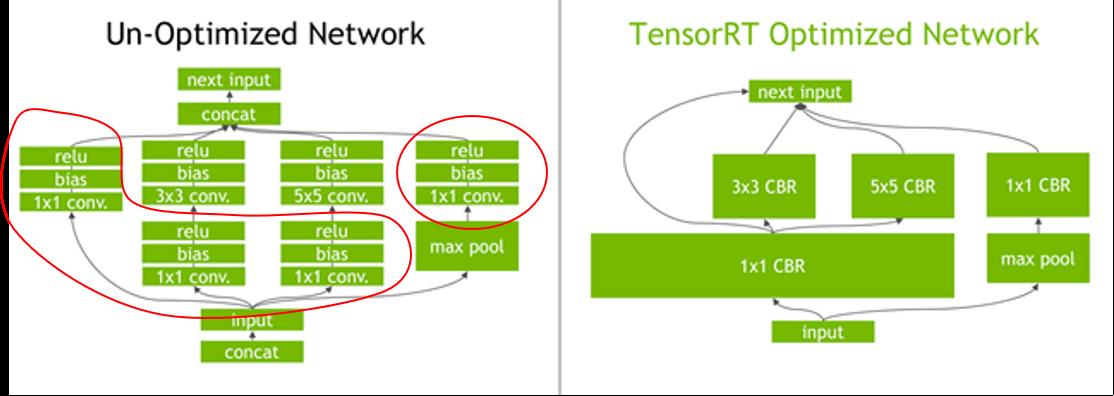
因为TensorRT进行了层间融合和张量融合的优化方式,一些层在 TensorRT 中会被合并,如上图。
比如原来网络中的 inception_5a/3x3 和 inception_5a/ relu_3x3 等这样的层会被合并成 inception_5a/3x3 + inception_5a/relu_3x3 ,因此输出 每一层的时间时,也是按照合并之后的输出。因此TensorRT优化之后的网络结构是跟原来的网络结构不是一一对应的。
3 官方例程
例程位于 /usr/src/tensorrt/samples/sampleGoogleNet
这个例程展示的是 TensorRT的layer-based profiling和 half2mode 和 FP16 使用方法。相比于前面说过的mnist的例程只添加了一些借口和修改了一部分参数,还是贴个完整代码吧,虽然比较占篇幅。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 | #include <assert.h> #include <fstream> #include <sstream> #include <iostream> #include <cmath> #include <algorithm> #include <sys/stat.h> #include <cmath> #include <time.h> #include <cuda_runtime_api.h> #include "NvInfer.h" #include "NvCaffeParser.h" #include "common.h" static Logger gLogger; using namespace nvinfer1; using namespace nvcaffeparser1; // stuff we know about the network and the caffe input/output blobs static const int BATCH_SIZE = 4; static const int TIMING_ITERATIONS = 1000; const char* INPUT_BLOB_NAME = "data"; const char* OUTPUT_BLOB_NAME = "prob"; std::string locateFile(const std::string& input) std::vector<std::string> dirs"data/samples/googlenet/", "data/googlenet/"; return locateFile(input, dirs); // profile类,继承自 IProfiler struct Profiler : public IProfiler typedef std::pair<std::string, float> Record; std::vector<Record> mProfile; // 将每一层的运行时间存放到 vector中 virtual void reportLayerTime(const char* layerName, float ms) // find_if找到第一个 r.first 与 layerName 相同的层,返回一个迭代器 auto record = std::find_if(mProfile.begin(), mProfile.end(), [&](const Record& r) return r.first == layerName; ); // 如果是新的层就push_back进vector if (record == mProfile.end()) mProfile.push_back(std::make_pair(layerName, ms)); // 如果是vector中已有的层就直接累加时间,因为他是迭代1000次的,肯定会重复,所以要累加时间 else record->second += ms; // 打印各层的运行时间,打印时要除掉 总的迭代次数 void printLayerTimes() float totalTime = 0; for (size_t i = 0; i < mProfile.size(); i++) printf("%-40.40s %4.3fms\\n", mProfile[i].first.c_str(), mProfile[i].second / TIMING_ITERATIONS); totalTime += mProfile[i].second; printf("Time over all layers: %4.3f\\n", totalTime / TIMING_ITERATIONS); gProfiler; void caffeToTRTModel(const std::string& deployFile, // name for caffe prototxt const std::string& modelFile, // name for model const std::vector<std::string>& outputs, // network outputs unsigned int maxBatchSize, // batch size - NB must be at least as large as the batch we want to run with) IHostMemory *&trtModelStream) // create API root class - must span the lifetime of the engine usage IBuilder* builder = createInferBuilder(gLogger); INetworkDefinition* network = builder->createNetwork(); // parse the caffe model to populate the network, then set the outputs ICaffeParser* parser = createCaffeParser(); bool useFp16 = builder->platformHasFastFp16(); // 判断当前的GPU设备是否支持 FP16的精度 DataType modelDataType = useFp16 ? DataType::kHALF : DataType::kFLOAT; // create a 16-bit model if it's natively supported const IBlobNameToTensor *blobNameToTensor = parser->parse(locateFile(deployFile).c_str(), // caffe deploy file locateFile(modelFile).c_str(), // caffe model file *network, // network definition that the parser will populate modelDataType); assert(blobNameToTensor != nullptr); // the caffe file has no notion of outputs, so we need to manually say which tensors the engine should generate for (auto& s : outputs) network->markOutput(*blobNameToTensor->find(s.c_str())); // Build the engine builder->setMaxBatchSize(maxBatchSize); builder->setMaxWorkspaceSize(16 << 20); // 设置half2mode // set up the network for paired-fp16 format if available if(useFp16) builder->setFp16Mode(true); ICudaEngine* engine = builder->buildCudaEngine(*network); assert(engine); // we don't need the network any more, and we can destroy the parser network->destroy(); parser->destroy(); // serialize the engine, then close everything down trtModelStream = engine->serialize(); engine->destroy(); builder->destroy(); shutdownProtobufLibrary(); void timeInference(ICudaEngine* engine, int batchSize) // input and output buffer pointers that we pass to the engine - the engine requires exactly ICudaEngine::getNbBindings(), // of these, but in this case we know that there is exactly one input and one output. assert(engine->getNbBindings() == 2); void* buffers[2]; // In order to bind the buffers, we need to know the names of the input and output tensors. // note that indices are guaranteed to be less than ICudaEngine::getNbBindings() int inputIndex = engine->getBindingIndex(INPUT_BLOB_NAME), outputIndex = engine->getBindingIndex(OUTPUT_BLOB_NAME); // allocate GPU buffers // 自动获取输入输出的维度 Dims3 inputDims = static_cast<Dims3&&>(engine->getBindingDimensions(inputIndex)), outputDims = static_cast<Dims3&&>(engine->getBindingDimensions(outputIndex)); size_t inputSize = batchSize * inputDims.d[0] * inputDims.d[1] * inputDims.d[2] * sizeof(float); size_t outputSize = batchSize * outputDims.d[0] * outputDims.d[1] * outputDims.d[2] * sizeof(float); CHECK(cudaMalloc(&buffers[inputIndex], inputSize)); CHECK(cudaMalloc(&buffers[outputIndex], outputSize)); IExecutionContext* context = engine->createExecutionContext(); // 设置profiler context->setProfiler(&gProfiler); // zero the input buffer CHECK(cudaMemset(buffers[inputIndex], 0, inputSize)); for (int i = 0; i < TIMING_ITERATIONS;i++) context->execute(batchSize, buffers); // release the context and buffers context->destroy(); CHECK(cudaFree(buffers[inputIndex])); CHECK(cudaFree(buffers[outputIndex])); int main(int argc, char** argv) std::cout << "Building and running a GPU inference engine for GoogleNet, N=4..." << std::endl; // parse the caffe model and the mean file IHostMemory *trtModelStreamnullptr; caffeToTRTModel("googlenet.prototxt", "googlenet.caffemodel", std::vector < std::string > OUTPUT_BLOB_NAME , BATCH_SIZE, trtModelStream); assert(trtModelStream != nullptr); // create an engine IRuntime* infer = createInferRuntime(gLogger); assert(infer != nullptr); ICudaEngine* engine = infer->deserializeCudaEngine(trtModelStream->data(), trtModelStream->size(), nullptr); assert(engine != nullptr); printf("Bindings after deserializing:\\n"); for (int bi = 0; bi < engine->getNbBindings(); bi++) if (engine->bindingIsInput(bi) == true) printf("Binding %d (%s): Input.\\n", bi, engine->getBindingName(bi)); else printf("Binding %d (%s): Output.\\n", bi, engine->getBindingName(bi)); // run inference with null data to time network performance timeInference(engine, BATCH_SIZE); engine->destroy(); infer->destroy(); trtModelStream->destroy(); // 打印profing 结果 gProfiler.printLayerTimes(); std::cout << "Done." << std::endl; return 0; |
4 结果分析
TensorRT 的profiling执行结果:
batch=4, iterations=1000, GPU=1080 ti
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 | myself@admin:~/workspace/study/tensorrt/bin$ ./sample_googlenet Building and running a GPU inference engine for GoogleNet, N=4... Bindings after deserializing: Binding 0 (data): Input. Binding 1 (prob): Output. conv1/7x7_s2 + conv1/relu_7x7 0.128ms pool1/3x3_s2 0.054ms pool1/norm1 0.031ms conv2/3x3_reduce + conv2/relu_3x3_reduce 0.029ms conv2/3x3 + conv2/relu_3x3 0.193ms conv2/norm2 0.084ms pool2/3x3_s2 0.045ms inception_3a/1x1 + inception_3a/relu_1x1 0.040ms inception_3a/3x3 + inception_3a/relu_3x3 0.062ms inception_3a/5x5 + inception_3a/relu_5x5 0.044ms inception_3a/pool 0.020ms inception_3a/pool_proj + inception_3a/re 0.031ms inception_3a/1x1 copy 0.008ms inception_3b/1x1 + inception_3b/relu_1x1 0.075ms inception_3b/3x3 + inception_3b/relu_3x3 0.109ms inception_3b/5x5 + inception_3b/relu_5x5 0.086ms inception_3b/pool 0.026ms inception_3b/pool_proj + inception_3b/re 0.040ms inception_3b/1x1 copy 0.012ms pool3/3x3_s2 0.032ms inception_4a/1x1 + inception_4a/relu_1x1 0.056ms inception_4a/3x3 + inception_4a/relu_3x3 0.034ms inception_4a/5x5 + inception_4a/relu_5x5 0.044ms inception_4a/pool 0.014ms inception_4a/pool_proj + inception_4a/re 0.048ms inception_4a/1x1 copy 0.007ms inception_4b/1x1 + inception_4b/relu_1x1 0.059ms inception_4b/3x3 + inception_4b/relu_3x3 0.037ms inception_4b/5x5 + inception_4b/relu_5x5 0.059ms inception_4b/pool 0.014ms inception_4b/pool_proj + inception_4b/re 0.051ms inception_4b/1x1 copy 0.006ms inception_4c/1x1 + inception_4c/relu_1x1 0.059ms inception_4c/3x3 + inception_4c/relu_3x3 0.052ms inception_4c/5x5 + inception_4c/relu_5x5 0.061ms inception_4c/pool 0.014ms inception_4c/pool_proj + inception_4c/re 0.051ms inception_4c/1x1 copy 0.006ms inception_4d/1x1 + inception_4d/relu_1x1 0.059ms inception_4d/3x3 + inception_4d/relu_3x3 0.057ms inception_4d/5x5 + inception_4d/relu_5x5 0.072ms inception_4d/pool 0.014ms inception_4d/pool_proj + inception_4d/re 0.051ms inception_4d/1x1 copy 0.005ms inception_4e/1x1 + inception_4e/relu_1x1 0.063ms inception_4e/3x3 + inception_4e/relu_3x3 0.063ms inception_4e/5x5 + inception_4e/relu_5x5 0.071ms inception_4e/pool 0.014ms inception_4e/pool_proj + inception_4e/re 0.052ms inception_4e/1x1 copy 0.008ms pool4/3x3_s2 0.014ms inception_5a/1x1 + inception_5a/relu_1x1 0.079ms inception_5a/3x3 + inception_5a/relu_3x3 0.040ms inception_5a/5x5 + inception_5a/relu_5x5 0.071ms inception_5a/pool 0.009ms inception_5a/pool_proj + inception_5a/re 0.072ms inception_5a/1x1 copy 0.004ms inception_5b/1x1 + inception_5b/relu_1x1 0.075ms inception_5b/3x3 + inception_5b/relu_3x3 0.046ms inception_5b/5x5 + inception_5b/relu_5x5 0.097ms inception_5b/pool 0.009ms inception_5b/pool_proj + inception_5b/re 0.072ms inception_5b/1x1 copy 0.005ms pool5/7x7_s1 0.012ms loss3/classifier 0.019ms prob 0.007ms Time over all layers: 2.978 Done. |
这个速度很快的整个网络一次前向过程只有3ms左右。
我们再来看看不用TensorRT的googlenet的profiling结果,这个googlenet使用的是caffe代码中自带的模型文件,profiling用的是caffe 自己的time命令。
将deploy.prototxt 中的batch改为4,迭代次数的话因为这个没有使用TensorRT优化,所以比较费时间,就跑50个iterations,不过也能说明问题了。 同样因为没有使用TensorRT优化,原来的网络结构中是没有进行层间融合的,而且caffe的time命令是把forward和backward都测了时间的,因此输出比较多,所以下面删除了一部分,只保留了inception_5*。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 | myself@admin:~/caffe$ ./build/tools/caffe time --model=models/bvlc_googlenet/deploy.prototxt --iterations=50 Average time per layer: data forward: 0.00454 ms. data backward: 0.00204 ms. ………………太长了省略一部分 inception_5a/1x1 forward: 4.43762 ms. inception_5a/1x1 backward: 1.5149 ms. inception_5a/relu_1x1 forward: 0.10942 ms. inception_5a/relu_1x1 backward: 0.00126 ms. inception_5a/3x3_reduce forward: 2.88932 ms. inception_5a/3x3_reduce backward: 1.17394 ms. inception_5a/relu_3x3_reduce forward: 0.0859 ms. inception_5a/relu_3x3_reduce backward: 0.0012 ms. inception_5a/3x3 forward: 9.88662 ms. inception_5a/3x3 backward: 3.98626 ms. inception_5a/relu_3x3 forward: 0.22092 ms. inception_5a/relu_3x3 backward: 0.00116 ms. inception_5a/5x5_reduce forward: 0.90482 ms. inception_5a/5x5_reduce backward: 0.66332 ms. inception_5a/relu_5x5_reduce forward: 0.01554 ms. inception_5a/relu_5x5_reduce backward: 0.00128 ms. inception_5a/5x5 forward: 2.50424 ms. inception_5a/5x5 backward: 1.49614 ms. inception_5a/relu_5x5 forward: 0.05624 ms. inception_5a/relu_5x5 backward: 0.00108 ms. inception_5a/pool forward: 10.9052 ms. inception_5a/pool backward: 0.00168 ms. inception_5a/pool_proj forward: 2.41494 ms. inception_5a/pool_proj backward: 1.23424 ms. inception_5a/relu_pool_proj forward: 0.05614 ms. inception_5a/relu_pool_proj backward: 0.00124 ms. inception_5a/output forward: 0.20292 ms. inception_5a/output backward: 0.01312 ms. inception_5a/output_inception_5a/output_0_split forward: 0.00384 ms. inception_5a/output_inception_5a/output_0_split backward: 0.00156 ms. inception_5b/1x1 forward: 6.4108 ms. inception_5b/1x1 backward: 2.19984 ms. inception_5b/relu_1x1 forward: 0.16204 ms. inception_5b/relu_1x1 backward: 0.00146 ms. inception_5b/3x3_reduce forward: 3.16198 ms. inception_5b/3x3_reduce backward: 1.70668 ms. inception_5b/relu_3x3_reduce forward: 0.08388 ms. inception_5b/relu_3x3_reduce backward: 0.00146 ms. inception_5b/3x3 forward: 13.2323 ms. inception_5b/3x3 backward: 5.93336 ms. inception_5b/relu_3x3 forward: 0.16636 ms. inception_5b/relu_3x3 backward: 0.00118 ms. inception_5b/5x5_reduce forward: 1.01018 ms. inception_5b/5x5_reduce backward: 0.82398 ms. inception_5b/relu_5x5_reduce forward: 0.02294 ms. inception_5b/relu_5x5_reduce backward: 0.00118 ms. inception_5b/5x5 forward: 4.08472 ms. inception_5b/5x5 backward: 2.8564 ms. inception_5b/relu_5x5 forward: 0.05658 ms. inception_5b/relu_5x5 backward: 0.0011 ms. inception_5b/pool forward: 10.9437 ms. inception_5b/pool backward: 0.00116 ms. inception_5b/pool_proj forward: 2.21102 ms. inception_5b/pool_proj backward: 2.23458 ms. inception_5b/relu_pool_proj forward: 0.05634 ms. inception_5b/relu_pool_proj backward: 0.00124 ms. inception_5b/output forward: 0.26758 ms. inception_5b/output backward: 0.01492 ms. pool5/7x7_s1 forward: 2.37076 ms. pool5/7x7_s1 backward: 0.00188 ms. pool5/drop_7x7_s1 forward: 0.06108 ms. pool5/drop_7x7_s1 backward: 0.00134 ms. loss3/classifier forward: 2.74434 ms. loss3/classifier backward: 2.75442 ms. prob forward: 0.28054 ms. prob backward: 0.06392 ms. Average Forward pass: 1046.79 ms. Average Backward pass: 676.121 ms. Average Forward-Backward: 1723.54 ms. Total Time: 86177 ms. *** Benchmark ends *** |
首先是一次前向的总耗时:
没有使用TensorRT优化的googlenet 是 1046.79ms,使用TensorRT优化的是2.98ms
其次可以看其中的某一层的对比:
-
inception_5b/1x1 + inception_5b/relu_1x1
优化前:
1
2
inception_5b/1x1 forward: 6.4108 ms.
inception_5b/relu_1x1 forward: 0.16204 ms.
总耗时:6.57ms
优化后:
1
inception_5b/1x1 + inception_5b/relu_1x1 0.075ms
总耗时:0.075ms
-
inception_5b/3x3 + inception_5b/relu_3x3:
优化前:
1
2
inception_5b/3x3 forward: 13.2323 ms.
inception_5b/relu_3x3 forward: 0.16636 ms.
总耗时:13.40ms
优化后:
1
inception_5b/3x3 + inception_5b/relu_3x3 0.046ms
总耗时:0.046ms
-
inception_5b/5x5 + inception_5b/relu_5x5
优化前:
1
2
inception_5b/5x5 forward: 4.08472 ms.
inception_5b/relu_5x5 forward: 0.05658 ms.
总耗时:4.14ms
优化后:
1
inception_5b/5x5 + inception_5b/relu_5x5 0.097ms
总耗时:0.079ms
-
此外还有这些层:
优化前:
1
2
3
4
5
inception_5b/pool forward: 10.9437 ms.
inception_5b/pool_proj forward: 2.21102 ms.
inception_5b/relu_pool_proj forward: 0.05634 ms.
inception_5b/output forward: 0.26758 ms.
pool5/7x7_s1 forward: 2.37076 ms.
优化后:
1
2
3
4
inception_5b/pool 0.009ms
inception_5b/pool_proj + inception_5b/re 0.072ms
inception_5b/1x1 copy 0.005ms
pool5/7x7_s1 0.012ms
前面 3×3 卷积比 5×5 卷积还耗时间是因为 3×3 卷积的channel比 5×5 卷积的channel多很多,但是经过TensorRT优化之后二者差别就不是很大了,甚至 5×5 卷积比 3×3 卷积 耗时间。
TensorRT确实极大的降低了前向传播时间,一次前向传播时间只有优化之前的 0.2%,不过这只是分类问题,并且网络也都是传统卷积堆起来的。对于那些复杂结构的网络,比如用于检测的网络或者使用了非经典卷积的比如 dilated conv 或者 deformable conv 的,应该就不会有这么大幅度的提升效果了。不过从英伟达公布的测试数据来看,提升幅度还是蛮大的。
参考
- Morton Coding Overview:Ash C++ Template Library (AshTL) Documentation
- Interleaving Explained:::. Kitz - Interleaving .::
- interleave bits the obvious way:c - Bit Twiddling Hacks: interleave bits the obvious way - Stack Overflow
- Bitwise operation:https://en.wikipedia.org/wiki/Bitwise_operation
- 计算机组成原理
- 顺序存储和交叉存储:顺序存储和交叉存储 - 百度文库
- 执行时间计算: https://devtalk.nvidia.com/default/topic/1027443/print-time-unit-is-not-ms-in-samplegooglenet-cpp-of-tensorrt-3-0-sdk-/
- tensorRT API : TensorRT: nvinfer1::IProfiler Class Reference
- tensorRT 用户手册:Developer Guide :: NVIDIA Deep Learning TensorRT Documentation
以上是关于TensorRT-Profiling and 16-bit Inference的主要内容,如果未能解决你的问题,请参考以下文章