决策树(Decision Tree)--ID3算法
Posted 挂科难
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了决策树(Decision Tree)--ID3算法相关的知识,希望对你有一定的参考价值。
决策树的主要算法
构建决策树的关键:按照什么样的次序来选择变量(属性/特征)作为分类依据。
根据不同的目标函数,建立决策树主要有以下三种算法
- ID3(J.Ross Quinlan-1975) 核心:信息熵,信息增益
- C4.5——ID3的改进,核心:信息增益比/增益率
- CART(Breiman-1984),核心:基尼系数
ID3算法
由Ross Quinlan在1986年提出,ID3决策树可以有多个分支,但是不能处理特征值为连续的情况,根据“最大信息熵增益”选取当前最佳的特征来分割数据。
香农熵(Shannon Entropy)
熵用来表示事件的不确定性,熵越小代表事件发生的概率就越大。若熵为0,表示事件百分百发生。
对于常见分类系统来说,假设类别D是变量,D可能取值D1,D2…Dn,每个类别出现的概率为P(D1),P(D2)…P(Dn),共n类。
分类系统的熵为:
当我们的概率是由数据统计得到时,此时的熵称为经验熵(empirical entropy)。
举个例子:
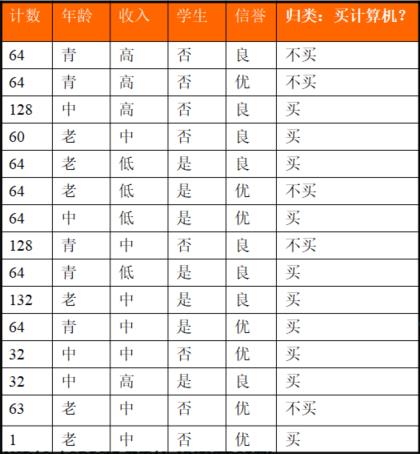
我们先不考虑特征,该样本最终分为结果只有买与不买两类,根据统计可知在1024个样本中有641个数据结果为买,383个数据结果为不买。显然买的概率为(641/1024),不买的概率为(383/1024)。显然这两个概率是我们统计得到的,通过这两个统计得到的概率计算的熵称为经验熵,为:
这就是我们第一步要做的,计算决策属性的熵。
该列中买与不买就是决策属性。
条件熵
条件熵H(Y|X)表示在已知随机变量X的条件下随机变量Y的不确定性。
同样的,如果公式中的概率是由统计估计出来的话,这时的条件熵称为经验条件熵。
我们用H(D|A)表示在给定的特征A的条件下D的经验条件熵。假设特征A将D划分为v个子集D1,D2,…Dv,例:年龄特征(A),将我们的数据集分成了三份青年,中年,老年.
此时条件熵为:
信息增益(information gain)
计算完决策属性的熵以后,我们要根据信息增益来排序特征,那什么是信息增益呢?
信息增益是相对于特征而言的,表示得知特征A的信息而使得类Y的信息的不确定性减少的程度。信息增益越大,特征对最终的分类结果影响也就越大,因此此特征就被选上作为我们的分类特征。
简单地将,可以理解为一个特征对最终结果相关程度,信息增益大说明该特征与分类结果的关联性很强。特征的信息增益小,则说明该特征对分类的结果影响很小。
特征A信息增益( g(D,A) ) = 决策属性的熵 - 特征A的平均信息期望
定义为:
上述已经计算了决策属性的熵,现在我们计算某个特征的平均熵期望.
年龄(A1)将数据集为三个组:
青年(D1),中年(D2),老年(D3)
我们把年龄为青年(D1)的样本全都提取出来:
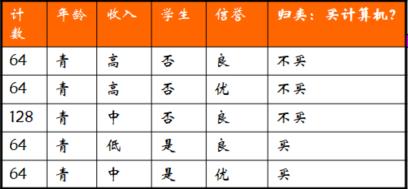
总共D1=(64*4+128)384个样本,做以下定义
D11(买)=128
D12(不买)=256
青年中买与不买的概率:
P(D11) = 128/384
P(D12) = 256/384
根据分类熵的定义得:
同理得到中年H(D2)=0,老年H(D3)=0.9175
青年组所占全部数据集比例(D1) = 384/1024 = 0.375
中年组所占全部数据集比例(D2) = 256/1024 = 0.25
老年组所占全部数据集比例(D3) = 384/1024 = 0.375
得到年龄(A1)的平均熵期望:
年龄信息增益为
上述讲过,信息增益为一个特征对最终分类结果的影响情况,信息增益越大代表该特征对最终分类结果的影响越大.所以我们还需要计算出收入,学生,信誉三个特征的信息增益信息增益越大的特征就要在决策树的前面
经过相同计算原理的我们得到
年龄特征的信息增益=0.2660
收入特征的信息增益=0.0176
学生特征的信息增益=0.1726
信誉特征的信息增益=0.0453
(年龄)>(学生)>(信誉)>(收入)
综上所述,应把年龄作为根节点.
持续更新ing
以上是关于决策树(Decision Tree)--ID3算法的主要内容,如果未能解决你的问题,请参考以下文章