论文 | A Neural Probabilistic Language Model
Posted Caffiny
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文 | A Neural Probabilistic Language Model相关的知识,希望对你有一定的参考价值。
A Neural Probabilistic Language Model
文章目录
- A Neural Probabilistic Language Model
- 1. Top View
- 2. Background
- 3. NNLM (Neural Network Language Model)
- 代码实现
1. Top View
这篇文章第一次用 “词向量” 和 神经网络 来解决(统计)语言模型的问题, 作者通过随机初始化一个词库向量corpus matrix (简称 C C C) 作为神经网络中的迭代更新的主要参数, 输入进神经网络的每一个词语通过这个 C C C 的映射成为词向量来表示这个词语的语义信息. 以 n n n 个词的词向量作为输入, n n n个词后的下一个词的词向量作为输出, 不断训练迭代更新 C C C, 使得 C C C 最终可以成功表达这个训练词库中的每个词.
这样的做法解决的问题包括:
- 在词汇量大的情况下, 以one-hot形式来表达单词会造成很大的开销
- 再者, 以one-hot形式无法有效地表达出词与词之间在语义或语法上的相似程度(e.g. cat & dog; is & was)
- 同时也解决了先前工作中基于统计学习方法的n-gram模型出现的"组合爆炸"问题, 以及训练语料库中存在测试条件下不存在的问题
2. Background
有几个前提背景知识需要了解
-
Language Modeling
如果给你以下一段话,你会在空白处填上什么词语?
“The cat sat on
_____.” 空白处可能是 “mats” / “sofa” / …Language Modeling 的任务就是对语言进行建模, 最终模型可以预测输入句子下一个紧接的词语.
如果从概率的角度对语言建模进行解释, 一个句子每个单词用 x ( 1 ) , ⋯ , x ( T ) x^(1),\\cdots,x^(T) x(1),⋯,x(T) 表示, 组成这个句子的概率就可以表达成
P ( x ( 1 ) , ⋯ , x ( T ) ) = P ( x ( 1 ) ) × P ( x ( 2 ) ∣ x ( 1 ) ) × ⋯ × P ( x ( T ) ∣ x ( T − 1 ) , ⋯ , x ( 1 ) ) = ∏ t = 1 T P ( x ( t ) ∣ x ( t − 1 ) , ⋯ , x 1 ) \\beginaligned P(x^(1),\\cdots,x^(T))&=P(x^(1))\\times P(x^(2)|x^(1))\\times\\cdots\\times P(x^(T)|x^(T-1),\\cdots,x^(1)) \\\\ &=\\prod^T_t=1P(x^(t)|x^(t-1),\\cdots,x^1) \\endaligned P(x(1),⋯,x(T))=P(x(1))×P(x(2)∣x(1))×⋯×P(x(T)∣x(T−1),⋯,x(1))=t=1∏TP(x(t)∣x(t−1),⋯,x1)
( 这里的概率是在给出的词库(数据集)中进行统计得到的概率 )举个例子就是
P(‘The’, ‘cat’, ‘sat’, ‘on’, ‘mats’) =
P(‘The’) x P(‘cat’|‘The’) x P(‘sat’|‘cat’, ‘The’) x P(‘on’|‘sat’, ‘cat’, ‘The’) x P(‘mats’ |‘on’, ‘sat’, ‘cat’, ‘The’)
-
n-gram Language Model
上述例子只是一个很简单的例子,在现实中可能面对的情况往往是很多个单词, 可能是10几个单词, 组成的句子, 这时候进行概率统计的计算量就会非常的大. n-gram作了一个很强的假设, 它利用了1. 词序和2. 词与词之间存在的语义关系 (如 鸟-飞; 猫-跳; 狗-叫), 假设对在一个句子中,如果要对下一个单词进行预测, 只需基于最后 n n n 个词语进行概率预测, 即:
p ^ ( w t ∣ w 1 t − 1 ) ≈ p ^ ( w t ∣ w t − n + 1 t − 1 ) \\hatp(w_t|w_1^t-1)\\approx\\hatp(w_t|w_t-n+1^t-1) p^(wt∣w1t−1)≈p^(wt∣wt−n+1t−1)
3. NNLM (Neural Network Language Model)
1. 输入层
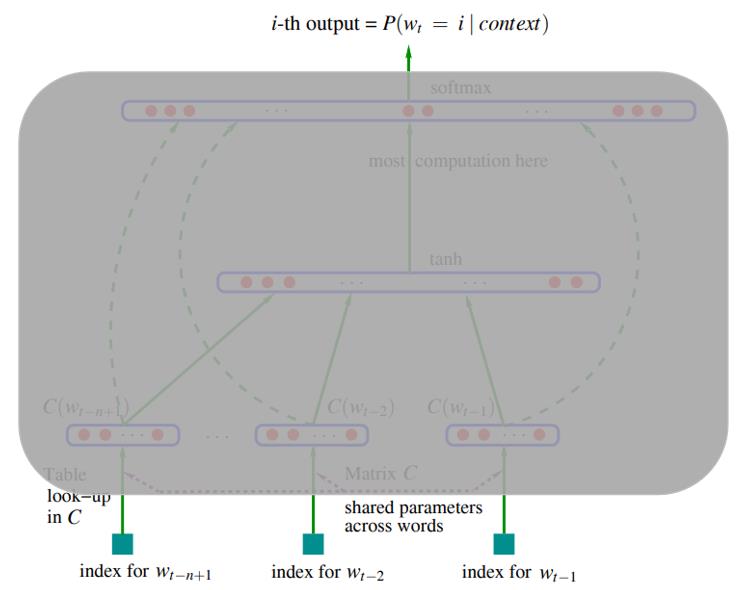
- 首先传进来的是 n − 1 n-1 n−1 个词在词库中的索引, 比方说, 存在一个词库 [‘dog’, ‘cat’, ‘baby’], 那么 ‘dog’ 的索引就是 0
- n − 1 n-1 n−1 个词的索引组成一个索引向量, 传入神经网络
2. 映射层
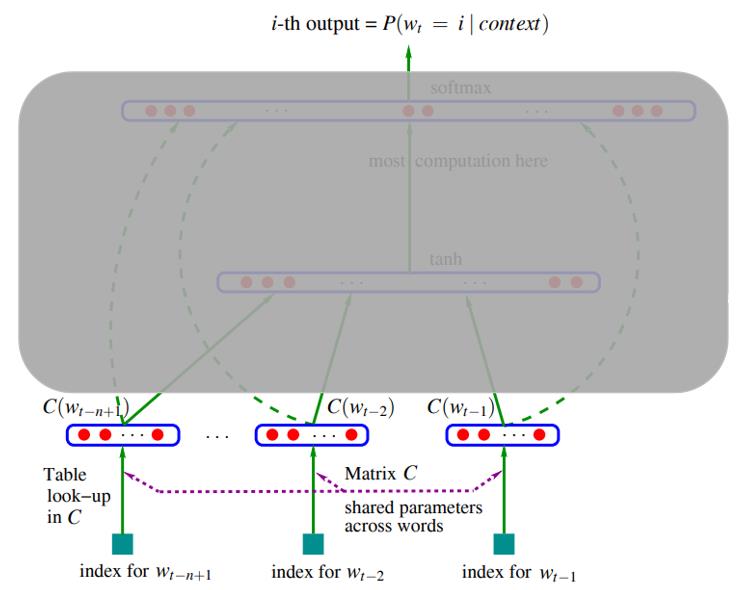
- 根据索引向量中每个词的索引, 在corpus matrix C C C 中提取每个词所对应的词向量
- 其中 C C C 的大小为 ∣ V ∣ × m |V|\\times m ∣V∣×m, ∣ V ∣ |V| ∣V∣ 为词库中词的数量, m m m 为表达一个词的特征的特征数, 文中给出的值是50
- 如果是一个包含1000个单词的词库 [‘dog’, ‘cat’, ‘baby’, … ] , C C C 的大小为 1000 × 50 1000 \\times 50 1000×50
- 而每个单词通过 C C C 映射得到 C ( i ) C(i) C(i), 大小为 1 × m 1 \\times m 1×m
- 注意! 这里的 C C C 是开始的时候随机初始化的参数, 并在后续神经网络训练不断迭代过程中进行更新
3. 隐藏层 ( t a n h tanh tanh 层)
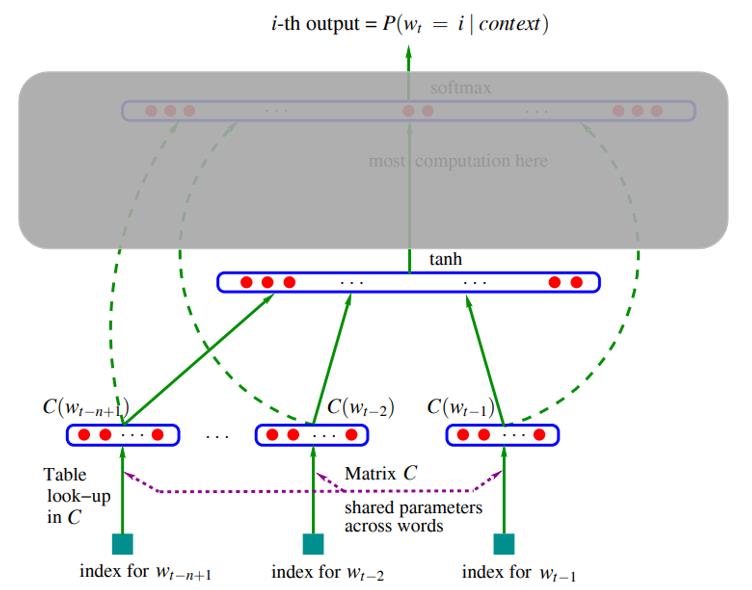
- 得到 n − 1 n-1 n−1 个 C ( i ) C(i) C(i) 后, 将他们全部拼接起来得到 x = ( C ( w t − 1 ) , C ( w t − 2 ) , ⋯ , C ( w − n + 1 ) ) ) x=(C(w_t-1), C(w_t-2),\\cdots, C(_w-n+1))) x=(C(wt−1),C(wt−2),⋯,C(w−n+1))), 大小为 ( n − 1 ) m (n-1)m (n−1)m
- 将拼接后的向量
x
x
x 输入给
t
a
n
h
(
)
tanh()
tanh() 激活函数
- 实际上, 在 x x x 传入到 t a n h ( ) tanh() tanh() 前需要乘以一个隐藏层权重 H H H, 其中 H H H 大小为 h × ( n − 1 ) m h \\times (n-1)m h×(n−1)m
- H x Hx Hx 最后得到的大小为 h h h
- 再加上隐藏层偏差 d d d, 计算 H x + d Hx+d Hx+d 输出大小为 h h h
- 假设 t a n h ( ) tanh() tanh() 隐藏层中神经元数目为 h h h, 那么 隐藏层 t a n h ( ) tanh() tanh() 的输出大小则是 h h h
4. 输出层 ( s o f t m a x softmax softmax 层)
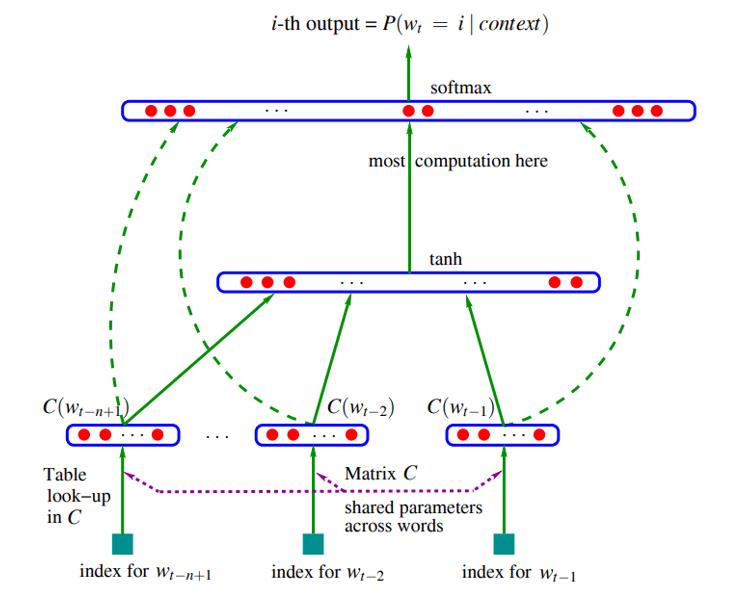
- 隐藏层输出
t
a
n
h
(
)
tanh()
tanh(), 乘上权重加上偏差后得到可以直接传入
s
o
f
t
m
a
x
softmax
softmax 层进行概率计算
- 在传入 s o f t m a x softmax softmax 层之前, 对隐藏层的输出乘以大小为 ∣ V × h ∣ |V \\times h| ∣V×h∣ 权重 U U U
- 再加上大小为
∣
V
∣
|V|
以上是关于论文 | A Neural Probabilistic Language Model的主要内容,如果未能解决你的问题,请参考以下文章