Python高级算法和数据结构:LRU缓存的巧妙设计
Posted tyler_download
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python高级算法和数据结构:LRU缓存的巧妙设计相关的知识,希望对你有一定的参考价值。
在软件设计中有一个原则,那就是任何复杂的操作或计算都不要重复计算两次,于是在软件工程中就有了一种非常重要的设计,那就是缓存。缓存广泛实施在各种应用中用于加快系统效率,提升用户体验,例如CDN就是显著例子。
然而缓存的设计中最为复杂的是缓存清除策略。因为内存有限,而需要缓存的数据往往大于缓存容量,因此当有新数据到来,如果缓存已满,那么我们需要决定如何清除当前缓存以便腾出位置给新的数据,最常用的清除策略叫LRU,也就是清除到目前位置最久没有被访问的数据。现在问题在于如何设计基于LRU的缓存。通常情况下我们使用队列来实现LRU,如何某个数据被访问,那么我们将数据挪到队列头,当要清除缓存时,位于队列尾部的数据就是最久没有被访问,于是直接通过队列尾就能进行清除。
但使用队列有一个问题,那就是数据的查找会很慢。例如当我们需要在缓存中查找给定数据是否已经存在时就得遍历整个队列,于是当队列长度很大时,数据的查找就比较慢,那么有没有办法在保证快速清除最久没访问的数据情况下能大大加快数据的查找速度呢,要满足查找和清除的速度要求,我们需要将队列和哈希表结合起来,基本设计如下:
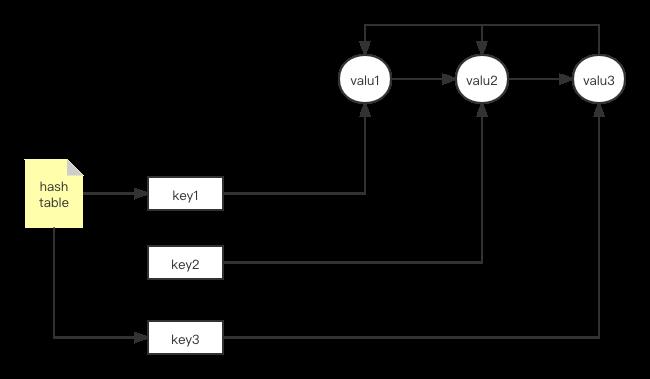
我们用双向队列来存储缓存的数据,也就是数据存储在双向队列的节点中。为了加快查找速度,我们使用哈希表指向对应节点,这样我们能保证一来最久没有访问的数据能保持在队列尾部,于是删除时非常方便,在查找缓存数据时,我们通过数据对应键值,(这个键值可以通过对数据进行哈希运算获得),然后快速找到存储数据的节点从而加快数据的访问速度。由于哈希表指向的是节点,因此当节点中的数据因为被访问而放置到队列头部时,哈希表依然能直接进行访问,于是将哈希表和队列结合在一起,我们就能实现LRU缓存的快速删除和访问,我们看看实现代码:
class LinkListNode:
def __init__(self, value):
self.value = value
self.prev = None
self.next = None
self.key = hashlib.sha256(value) # 将数据的哈希值作为哈希表中的key
class LinkedList:
def __init__(self):
self.head = None
self.tail = None
class LRUCache:
def __init__(self, max_size):
self.max_size = max_size
self.hash_table =
self.elements = LinkedList()
self.elements_tail = None
首先我们定义了双向链表和对应节点,每个节点除了存储数据外,它还有两个指针,分别指向前后节点,在LRUCache类中,我们定义了缓存最大容量,同时特别指定elements_tail,用于指向双向队列的最后一个节点,当我们需要清除缓存时,直接通过它进行数据删除。
我们看看如何将新的数据加入缓存:
class LinkListNode:
def __init__(self, value):
self.value = value
self.prev = None
self.next = None
class LinkedList:
def __init__(self):
self.head = None
self.tail = None
def move_to_front(self, node):
if node is None:
return
if self.head is None:
self.head = node
self.tail = node
node.prev = node.next = None
else:
# 先将节点从队列中取出
prev_node = node.prev
next_node = node.next
prev_node.next = next_node
next_node.prev = prev_node
# 将当前节点挪到队列头部
node.next = self.head
self.head = node
node.prev = None
def add_front(self, value):
node = LinkListNode(value)
node.next = self.head
self.head.prev = node
self.head = node
return node
class LRUCache:
def __init__(self, max_size):
self.max_size = max_size
self.current_size = 0 # 记录缓存的数量
self.hash_table =
self.elements = LinkedList()
self.elements_tail = None
def add(self, key, value):
if key in self.hash_table: #看看数据是否已经存在
node = self.hash_table[key]
node.value = value # 将数据存入节点
self.elements.move_to_front(node)
return False # 没有增加新节点
elif self.current_size >= self.max_size:
self.evict_one_entry() # 缓存不足,执行清除操作
node = self.elements.add_front(value) # 增加一个新节点并挪到队列头部
self.hash_table[key] = node # 让哈希表指向节点以便后面查询时提示查找速度
self.elements_tail = self.elements.tai
return True # 通知调用者有新节点生成
这里我们新增了好几个函数,move_to_front将当前被访问的数据所在节点挪到队列头,这样在清除缓存时就不会被删除掉,add_front是当要访问的数据没有在缓存中,我们需要将其添加到缓存队列的头部。
需要注意的是evict_one_entry,它用于在缓存容量不足时,将最久没有访问的数据从缓存中清除,下面我们看看它的实现:
def evict_one_entry(self):
if not self.hash_table:
return False # 当前哈希表为空,缓存没有数据
node = self.elements_tail
self.elements_tail = node.prev # 修改尾部节点
if self.elements_tail is not None:
self.elements_tail.next = None
del self.hash_table[node.key] # 将节点从哈希表删除
return True
缓存清除逻辑比较简单,我们先取得队列尾部节点,将它从队列中拿出,也就是把该节点前一个节点作为队列的尾部节点,然后获取数据对应在哈希表中的键,然后将其从哈希表删除即可,下面我们看看如何从缓存中读取给定数据:
def get(self, key):
if (key in self.hash_table) is False:
return None
node = self.hash_table[key]
return node.value
从上面代码看到,当我们查询缓存中的数据时,不需要遍历队列,只要直接从哈希表查询一次即可,遍历队列的时间复杂度是O(n),而从哈希表查询为O(1),由此可见我们将哈希表与队列结合起来能大大加快缓存的查询和删除速度。
本节代码没有经过具体数据的测试,有可能存在bug,有兴趣的同学可以尝试用具体数据验证一下代码的准确性,同时代码存在一些问题,那就是没有考虑线程安全,如果多线程执行上面的代码,那么就会出现数据一致性等问题。代码在这里下载:https://github.com/wycl16514/LRU_CACHE.git
以上是关于Python高级算法和数据结构:LRU缓存的巧妙设计的主要内容,如果未能解决你的问题,请参考以下文章