海豚调度在 Kubernetes 体系中的技术实战
Posted CSDN云计算
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了海豚调度在 Kubernetes 体系中的技术实战相关的知识,希望对你有一定的参考价值。


作者 | 杨滇
编辑 | warrior_
✎ 编者按
Kubernetes 是一个基于容器技术、实现容器编排、提供微服务和总线的集群系统,涉及到大量的知识体系。
本文从作者的实际工作经历出发,向我们展示了海豚调度在实际场景种的使用与技术分享,希望这篇文章能够给有着相同经历的人一些启发。
我们为什么使用海豚调度,
带来了什么价值,遇到了什么问题
海豚调度是当前非常优秀的分布式易扩展的可视化工作流任务调度平台。
从笔者的行业出发,海豚调度的应用快速解决了企业对数据开发方面十大痛点:
多源数据连接和接入,技术领域绝大多数常见的数据源都可以接入,加入新的数据源也无需太多的改动;
多元化+专业化+海量数据任务管理,真正地围绕大数据(hadoop family,flink 等)的任务调度,与传统调度器有显著的不同;
图形化任务编排,超级的用户体验,可以和商用产品直接对标,并且多数国外的开源产品并不能直接拖拉拽生成数据任务;
任务明细,原子任务丰富的查看、日志查看,时间运行轴显示,满足开发人员对数据任务的精细化管理,快速定位慢sql,性能瓶颈;
多种分布式文件系统的支持,丰富用户对非结构化数据的选择;
天然的多租户管理,满足大型组织下数据任务管理和隔离要求;
全自动的分布式调度算法,均衡所有调度任务;
自带集群监控功能,监控 cpu,内存,连接数,zookeeper 状态,适合中小企业一站式运维;
自带任务告警功能,最大程度减少了任务运行风险;
强大的社区化运营,倾听客户真正的声音,不断新增功能,持续优化客户体验;
在笔者上线各类海豚调度参与的项目中,也遇到了很多新的挑战:
如何用更少的人力资源去部署海豚调度,是否可以实现全自动的集群化安装部署模式?
如何标准化技术组件实施规范?
是否可以进行无人监管,系统自愈?
网络安全管控要求下,如何实现air-gap模式的安装和更新?
能否无感的自动扩容?
监控体系如何搭建和融合?
基于以上的挑战,我们将海豚调度重复融入现有的 kubernetes 云原生体系,解决痛点,让海豚技术变的更加强大。
Kubernetes 技术体系
给海豚调度带来的技术新特性
在使用 kubernetes 管理海豚后,整体技术方案很快具备了丰富高效的技术特性,也解决了上述实际的挑战:
各类独立部署项目,快速建立开发环境和生产环境,全部实现了一键部署,一键升级的实施模式;
全面支持无互联网的离线安装,切安装速度更快;
尽可能统一的安装配置的信息,减少多个项目配置的异常,所有的配置项,可以基于不同的项目通过企业内部git管理;
与对象存储技术的结合,统一非结构化数据的技术;
便捷的监控体系,与现有 prometheus 监控体系集成;
多种调度器的混合使用;
全自动的资源调整能力;
快速的自愈能力,自动异常重启,以及基于探针模式的重启;
本文的案例都是基于海豚调度1.3.9版本为基础。
基于 Helm 工具的自动化高效部署方式
首先,我们介绍基于官网提供的 helm 的安装方式。helm 是查找、分享和使用软件构建 kubernetes 的最优方式。也是云原生cncf的毕业项目之一。

海豚的官网和 github 上有非常详细的配置文件和案例。这里我们重点介绍一些社区中经常出现的咨询和问题。
官网文档地址
https://dolphinscheduler.apache.org/zh-cn/docs/1.3.9/user_doc/kubernetes-deployment.html
github文件夹地址
https://github.com/apache/dolphinscheduler/tree/1.3.9-release/docker/kubernetes/dolphinscheduler
在 value.yaml 文件中修改镜像,以实现离线安装(air-gap install);
image:
repository: "apache/dolphinscheduler"
tag: "1.3.9"
pullPolicy: "IfNotPresent"针对公司内部安装好的 harbor,或者其他公有云的私仓,进行 pull,tag,以及push。这里我们假定私仓地址是 harbor.abc.com,所在构建镜像的主机已经进行了 docker login harbor.abc.com, 且已经建立和授权私仓下面新建 apache项目。
执行 shell 命令
docker pull apache/dolphinscheduler:1.3.9
dock tag apache/dolphinscheduler:1.3.9 harbor.abc.com/apache/dolphinscheduler:1.3.9
docker push apache/dolphinscheduler:1.3.9再替换 value 文件中的镜像信息,这里我们推荐使用 Always 的方式拉取镜像,生产环境中尽量每次去检查是否是最新的镜像内容,保证软件制品的正确性。此外,很多同学会把 tag 写成 latest,制作镜像不写 tag 信息,这样在生产环境非常危险,任何人 push 了镜像,就相当于改变了 latest 的镜像,而且也无法判断latest 是什么版本,所以建议要明确每次发版的 tag,并且使用 Always。
image:
repository: "harbor.abc.com/apache/dolphinscheduler"
tag: "1.3.9"
pullPolicy: "Always"把 https://github.com/apache/dolphinscheduler/tree/1.3.9-release/docker/kubernetes/dolphinscheduler 整个目录 copy 到可以执行 helm 命令的主机,然后按照官网执行
kubectl create ns ds139
helm install dolphinscheduler . -n ds139即可实现离线安装。
集成 datax、mysql、oracle 客户端组件,首先下载以下组件
https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.49/mysql-connector-java-5.1.49.jar
https://repo1.maven.org/maven2/com/oracle/database/jdbc/ojdbc8/
https://github.com/alibaba/DataX/blob/master/userGuid.md
根据提示进行编译构建,文件包位于
DataX_source_code_home/target/datax/datax/
基于以上 plugin 组件新建 dockerfile,基础镜像可以使用已经 push 到私仓的镜像。
FROM harbor.abc.com/apache/dolphinscheduler:1.3.9
COPY *.jar /opt/dolphinscheduler/lib/
RUN mkdir -p /opt/soft/datax
COPY datax /opt/soft/datax保存 dockerfile,执行 shell 命令
docker build -t harbor.abc.com/apache/dolphinscheduler:1.3.9-mysql-oracle-datax . #不要忘记最后一个点
docker push harbor.abc.com/apache/dolphinscheduler:1.3.9-mysql-oracle-datax修改 value 文件
image:
repository: "harbor.abc.com/apache/dolphinscheduler"
tag: "1.3.9-mysql-oracle-datax"
pullPolicy: "Always"执行 helm install dolphinscheduler . -n ds139,或者执行 helm upgrade dolphinscheduler -n ds139,也可以先 helm uninstall dolphinscheduler -n ds139,再执行 helm install dolphinscheduler . -n ds139。
通常生产环境建议使用独立外置 postgresql 作为管理数据库,并且使用独立安装的 zookeeper 环境(本案例使用了zookeeper operator https://github.com/pravega/zookeeper-operator,与海豚调度在同一个 kubernetes 集群中)。我们发现,使用外置数据库后,对海豚调度在 kubernetes 中进行完全删除操作,然后重新部署海豚调度后,任务数据、租户数据、用户数据等等都有保留,这再次验证了系统的高可用性和数据完整性。(如果删除了 pvc ,会丢失历史的作业日志)
## If not exists external database, by default, Dolphinscheduler's database will use it.
postgresql:
enabled: false
postgresqlUsername: "root"
postgresqlPassword: "root"
postgresqlDatabase: "dolphinscheduler"
persistence:
enabled: false
size: "20Gi"
storageClass: "-"
## If exists external database, and set postgresql.enable value to false.
## external database will be used, otherwise Dolphinscheduler's database will be used.
externalDatabase:
type: "postgresql"
driver: "org.postgresql.Driver"
host: "192.168.1.100"
port: "5432"
username: "admin"
password: "password"
database: "dolphinscheduler"
params: "characterEncoding=utf8"
## If not exists external zookeeper, by default, Dolphinscheduler's zookeeper will use it.
zookeeper:
enabled: false
fourlwCommandsWhitelist: "srvr,ruok,wchs,cons"
persistence:
enabled: false
size: "20Gi"
storageClass: "storage-nfs"
zookeeperRoot: "/dolphinscheduler"
## If exists external zookeeper, and set zookeeper.enable value to false.
## If zookeeper.enable is false, Dolphinscheduler's zookeeper will use it.
externalZookeeper:
zookeeperQuorum: "zookeeper-0.zookeeper-headless.zookeeper.svc.cluster.local:2181,zookeeper-1.zookeeper-headless.zookeeper.svc.cluster.local:2181,zookeeper-2.zookeeper-headless.zookeeper.svc.cluster.local:2181"
zookeeperRoot: "/dolphinscheduler"基于 argo-cd 的 gitops 部署方式
argo-cd 是基于 Kubernetes 的声明式 gitops 持续交付工具。argo-cd 是 cncf的孵化项目,gitops 的最佳实践工具。关于 gitops 的解释可以参考https://about.gitlab.com/topics/gitops/

gitops 可以为海豚调度的实施带来以下优点。
图形化安装集群化的软件,一键安装;
git 记录全发版流程,一键回滚;
便捷的海豚工具日志查看;
使用argo-cd的实施安装步骤:
从github 上下载海豚调度源码,修改 value 文件,参考上个章节 helm 安装需要修改的内容;
把修改后的源码目录新建git项目,并且 push 到公司内部的 gitlab 中,github源码的目录名为docker/kubernetes/dolphinscheduler;
在 argo-cd 中配置 gitlab 信息,我们使用 https 的模式;
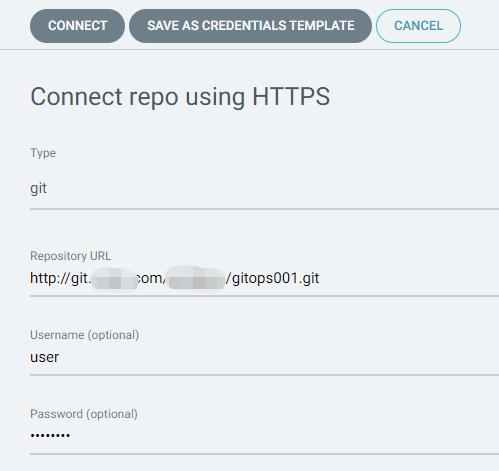
argo-cd 新建部署工程,填写相关信息
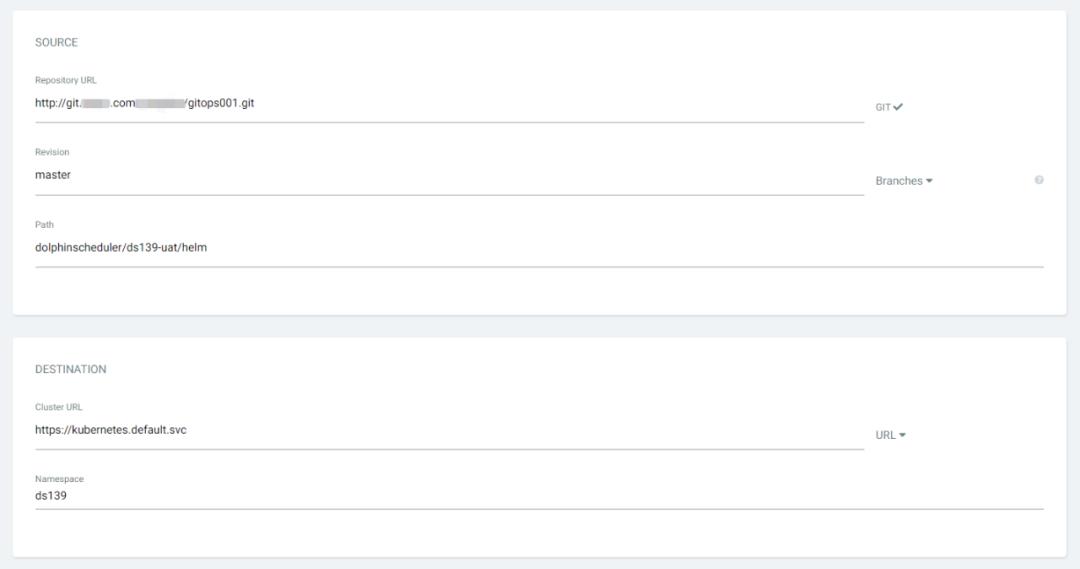
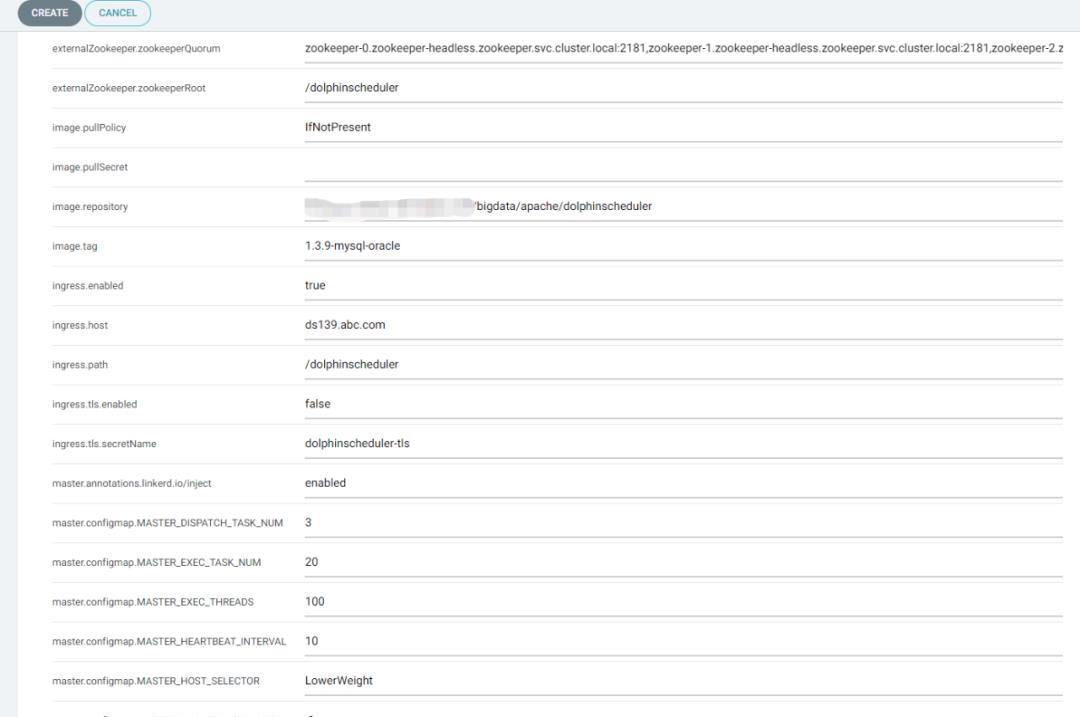
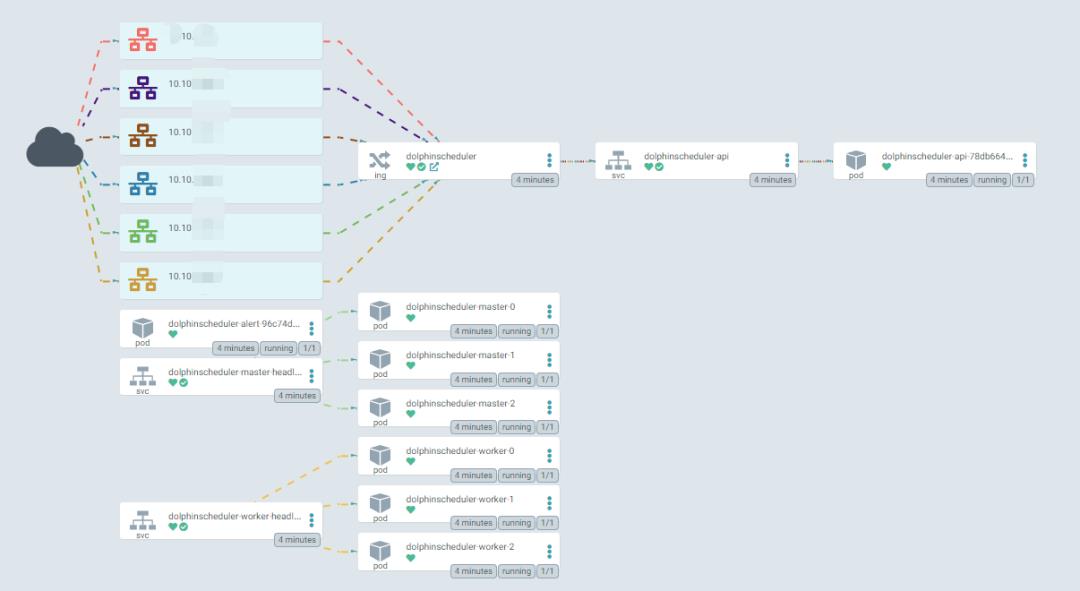
对git中的部署信息进行刷新和拉取,实现最后的部署工作。可以看到 pod,configmap,secret,service,ingress 等等资源全自动拉起,并且 argo-cd 显示了之前 git push 使用的 commit 信息和提交人用户名,这样就完整记录了所有的发版事件信息。同时也可以一键回滚到历史版本。
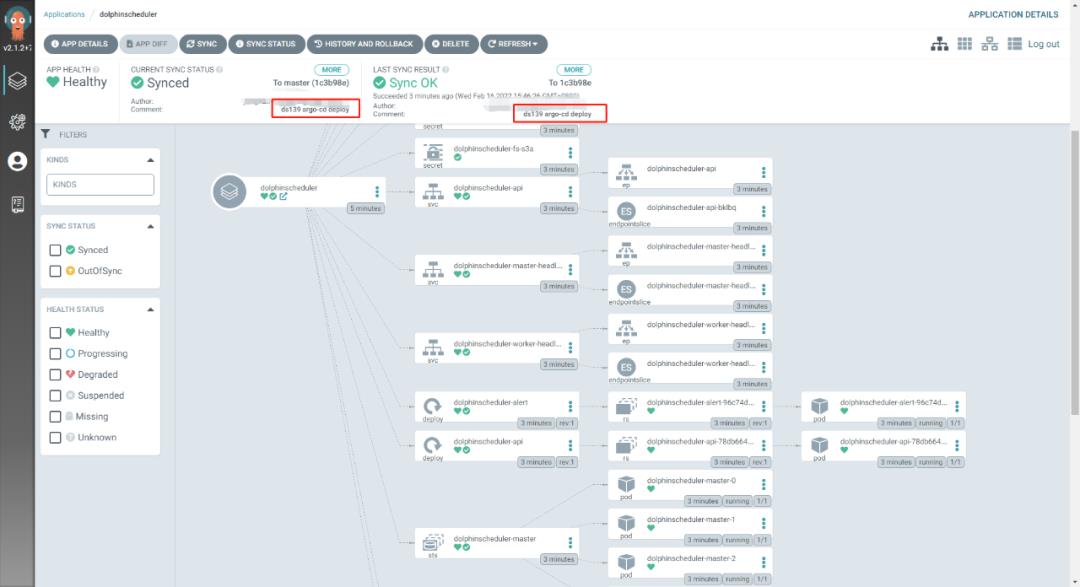
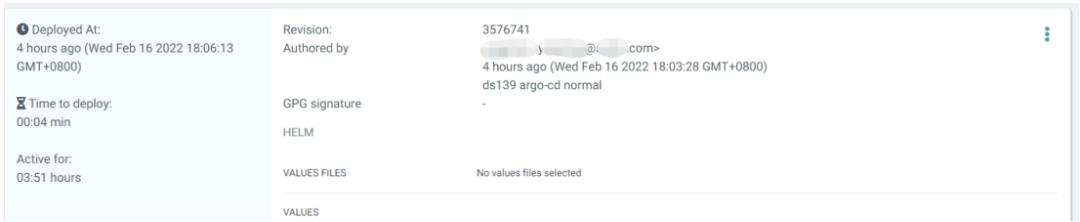
通过 kubectl 命令可以看到相关资源信息;
[root@tpk8s-master01 ~]# kubectl get po -n ds139
NAME READY STATUS RESTARTS AGE
dolphinscheduler-alert-96c74dc84-72cc9 1/1 Running 0 22m
dolphinscheduler-api-78db664b7b-gsltq 1/1 Running 0 22m
dolphinscheduler-master-0 1/1 Running 0 22m
dolphinscheduler-master-1 1/1 Running 0 22m
dolphinscheduler-master-2 1/1 Running 0 22m
dolphinscheduler-worker-0 1/1 Running 0 22m
dolphinscheduler-worker-1 1/1 Running 0 22m
dolphinscheduler-worker-2 1/1 Running 0 22m
[root@tpk8s-master01 ~]# kubectl get statefulset -n ds139
NAME READY AGE
dolphinscheduler-master 3/3 22m
dolphinscheduler-worker 3/3 22m
[root@tpk8s-master01 ~]# kubectl get cm -n ds139
NAME DATA AGE
dolphinscheduler-alert 15 23m
dolphinscheduler-api 1 23m
dolphinscheduler-common 29 23m
dolphinscheduler-master 10 23m
dolphinscheduler-worker 7 23m
[root@tpk8s-master01 ~]# kubectl get service -n ds139
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
dolphinscheduler-api ClusterIP 10.43.238.5 <none> 12345/TCP 23m
dolphinscheduler-master-headless ClusterIP None <none> 5678/TCP 23m
dolphinscheduler-worker-headless ClusterIP None <none> 1234/TCP,50051/TCP 23m
[root@tpk8s-master01 ~]# kubectl get ingress -n ds139
NAME CLASS HOSTS ADDRESS
dolphinscheduler <none> ds139.abc.com可以看到所有的 pod 都分散在 kubernetes 集群中不同的 host 上,例如worker 1 和 2 都在不同的节点上。
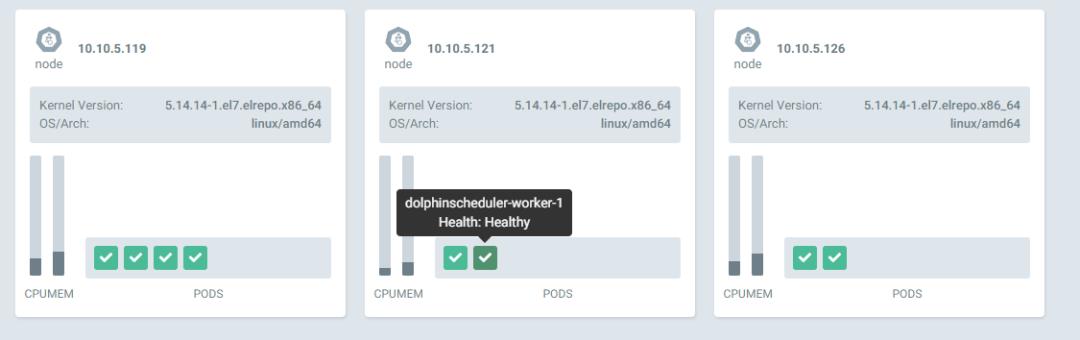
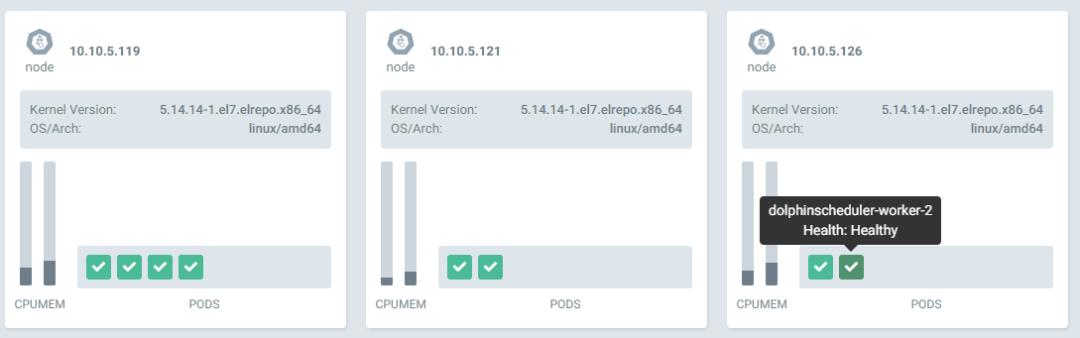
我们配置了 ingress,公司内部配置了泛域名就可以方便的使用域名进行访问;
可以登录域名进行访问。
具体配置可以修改 value 文件中的内容:
ingress:
enabled: true
host: "ds139.abc.com"
path: "/dolphinscheduler"
tls:
enabled: false
secretName: "dolphinscheduler-tls"方便查看海豚调度各个组件的内部日志:
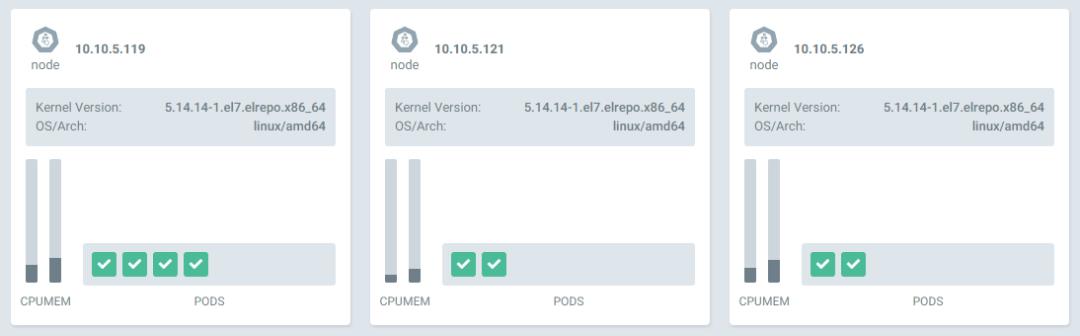
对部署好的系统进行检查,3个 master,3个 worker,zookeeper 都配置正常;
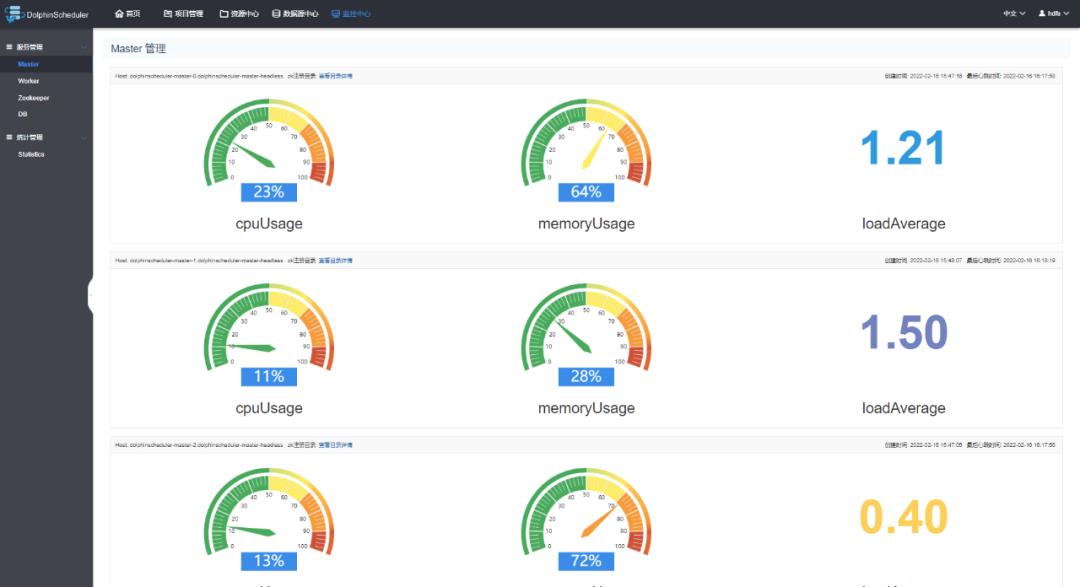
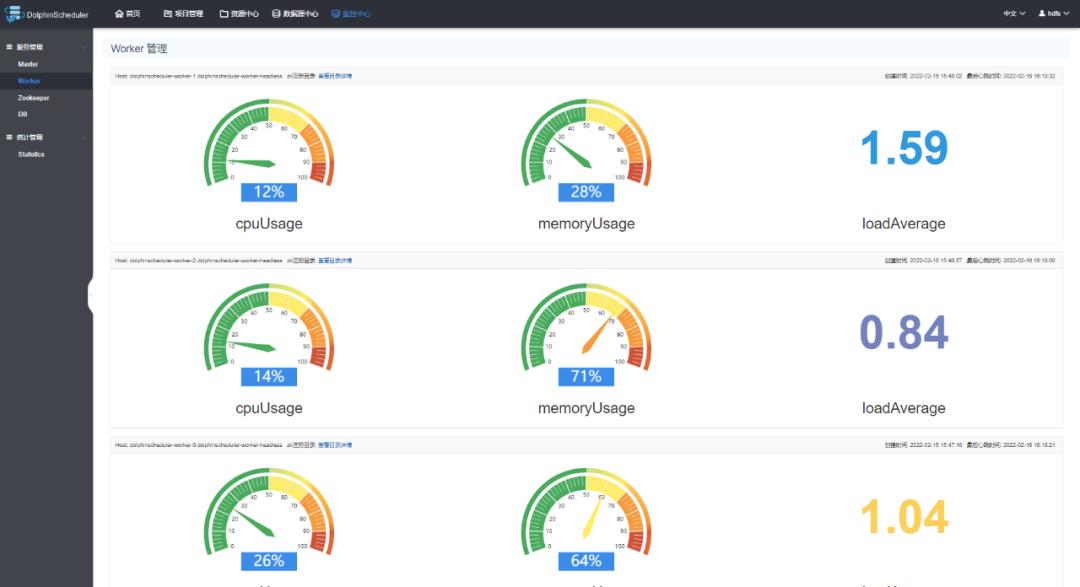

使用 argo-cd 可以非常方便的进行修改 master,worker,api,alert 等组件的副本数量,海豚的 helm 配置也预留了 cpu 和内存的设置信息。这里我们修改 value 中的副本值。修改后,git pish 到公司内部 gitlab。
master:
## PodManagementPolicy controls how pods are created during initial scale up, when replacing pods on nodes, or when scaling down.
podManagementPolicy: "Parallel"
## Replicas is the desired number of replicas of the given Template.
replicas: "5"
worker:
## PodManagementPolicy controls how pods are created during initial scale up, when replacing pods on nodes, or when scaling down.
podManagementPolicy: "Parallel"
## Replicas is the desired number of replicas of the given Template.
replicas: "5"
alert:
## Number of desired pods. This is a pointer to distinguish between explicit zero and not specified. Defaults to 1.
replicas: "3"
api:
## Number of desired pods. This is a pointer to distinguish between explicit zero and not specified. Defaults to 1.
replicas: "3"只需要在 argo-cd 点击 sync 同步,对应的 pods 都按照需求进行了增加
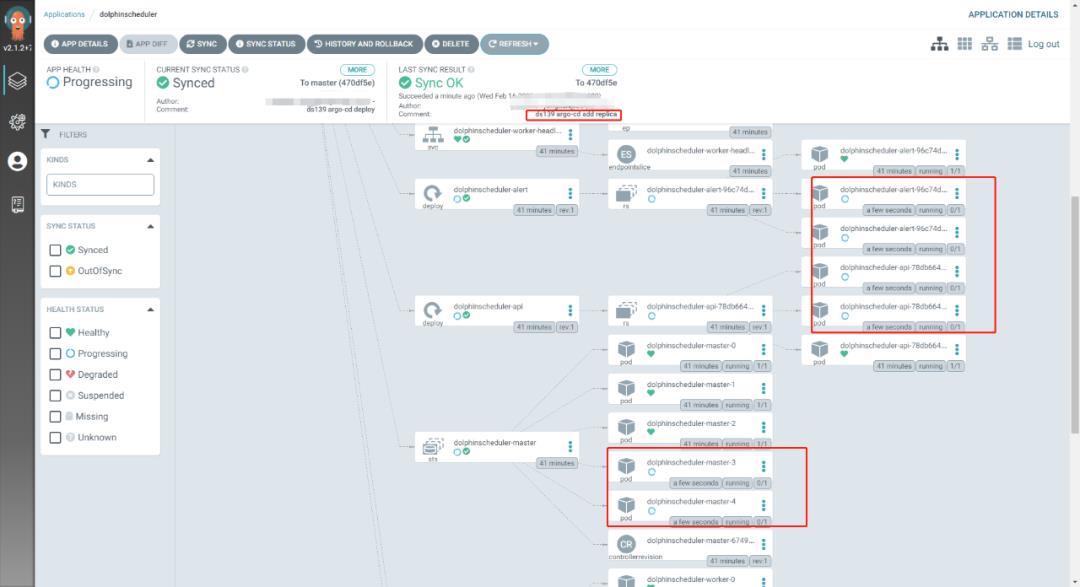
[root@tpk8s-master01 ~]# kubectl get po -n ds139
NAME READY STATUS RESTARTS AGE
dolphinscheduler-alert-96c74dc84-72cc9 1/1 Running 0 43m
dolphinscheduler-alert-96c74dc84-j6zdh 1/1 Running 0 2m27s
dolphinscheduler-alert-96c74dc84-rn9wb 1/1 Running 0 2m27s
dolphinscheduler-api-78db664b7b-6j8rj 1/1 Running 0 2m27s
dolphinscheduler-api-78db664b7b-bsdgv 1/1 Running 0 2m27s
dolphinscheduler-api-78db664b7b-gsltq 1/1 Running 0 43m
dolphinscheduler-master-0 1/1 Running 0 43m
dolphinscheduler-master-1 1/1 Running 0 43m
dolphinscheduler-master-2 1/1 Running 0 43m
dolphinscheduler-master-3 1/1 Running 0 2m27s
dolphinscheduler-master-4 1/1 Running 0 2m27s
dolphinscheduler-worker-0 1/1 Running 0 43m
dolphinscheduler-worker-1 1/1 Running 0 43m
dolphinscheduler-worker-2 1/1 Running 0 43m
dolphinscheduler-worker-3 1/1 Running 0 2m27s
dolphinscheduler-worker-4 1/1 Running 0 2m27s海豚调度与 S3 对象存储技术集成
许多同学在海豚的社区中提问,如何配置 s3 minio 的集成。这里给出基于kubernetes 的 helm 配置。
修改 value 中 s3 的部分,建议使用 ip+端口指向 minio 服务器。
common: ## Configmap configmap: DOLPHINSCHEDULER_OPTS: "" DATA_BASEDIR_PATH: "/tmp/dolphinscheduler" RESOURCE_STORAGE_TYPE: "S3" RESOURCE_UPLOAD_PATH: "/dolphinscheduler" FS_DEFAULT_FS: "s3a://dfs" FS_S3A_ENDPOINT: "http://192.168.1.100:9000" FS_S3A_ACCESS_KEY: "admin" FS_S3A_SECRET_KEY: "password"minio 中存放海豚文件的 bucket 名字是 dolphinscheduler,这里新建文件夹和文件进行测试。minio 的目录在上传操作的租户下。


海豚调度与 Kube-prometheus 的技术集成
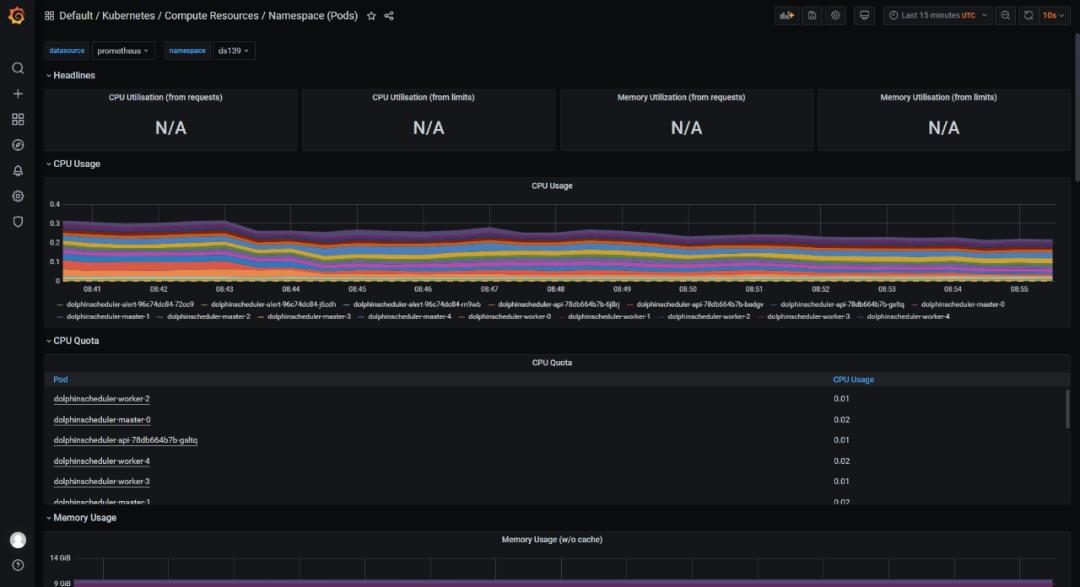
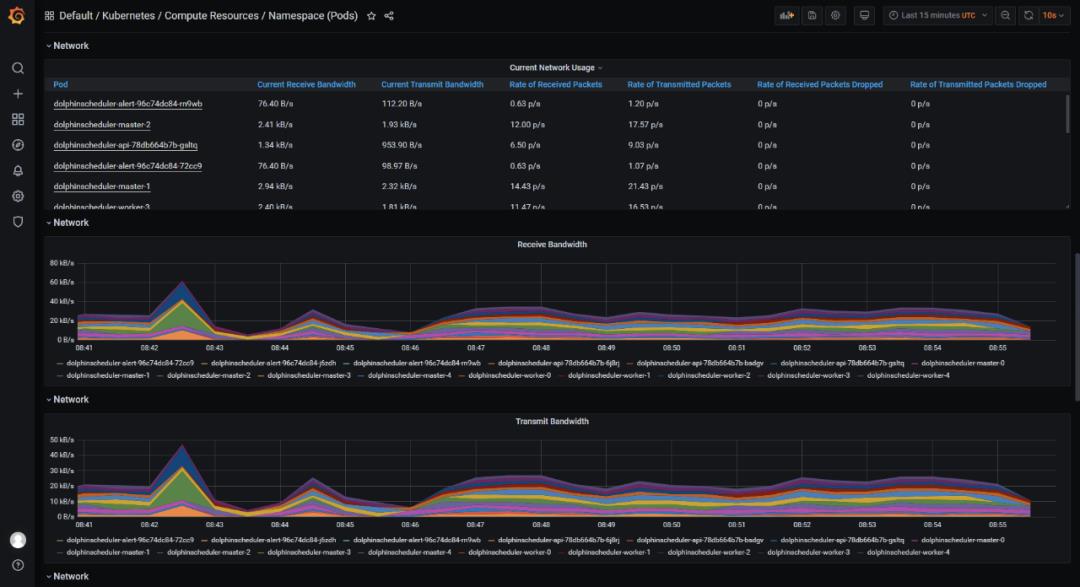
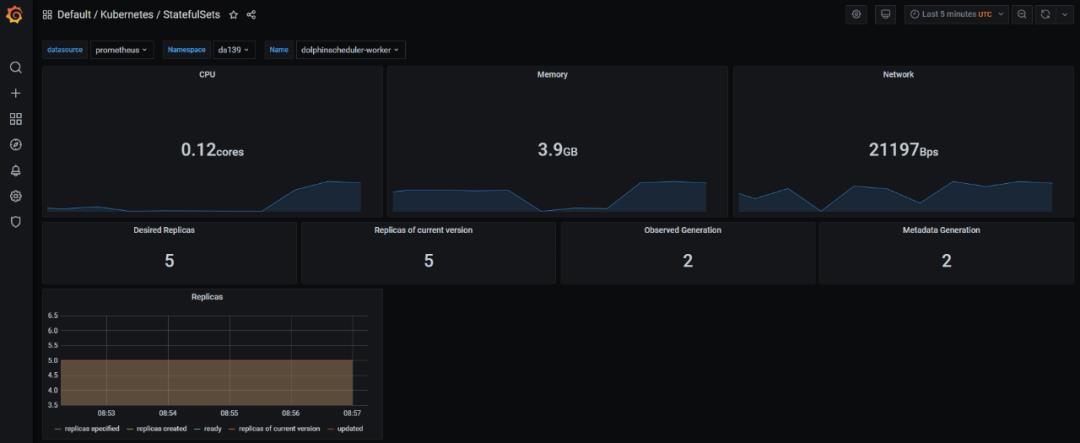
我们在 kubernetes 使用 kube-prometheus operator技术,在部署海豚后,自动实现了对海豚各个组件的资源监控。
请注意 kube-prometheus 的版本,需要对应 kubernetes 主版本。https://github.com/prometheus-operator/kube-prometheus
海豚调度与 Service Mesh 的技术集成
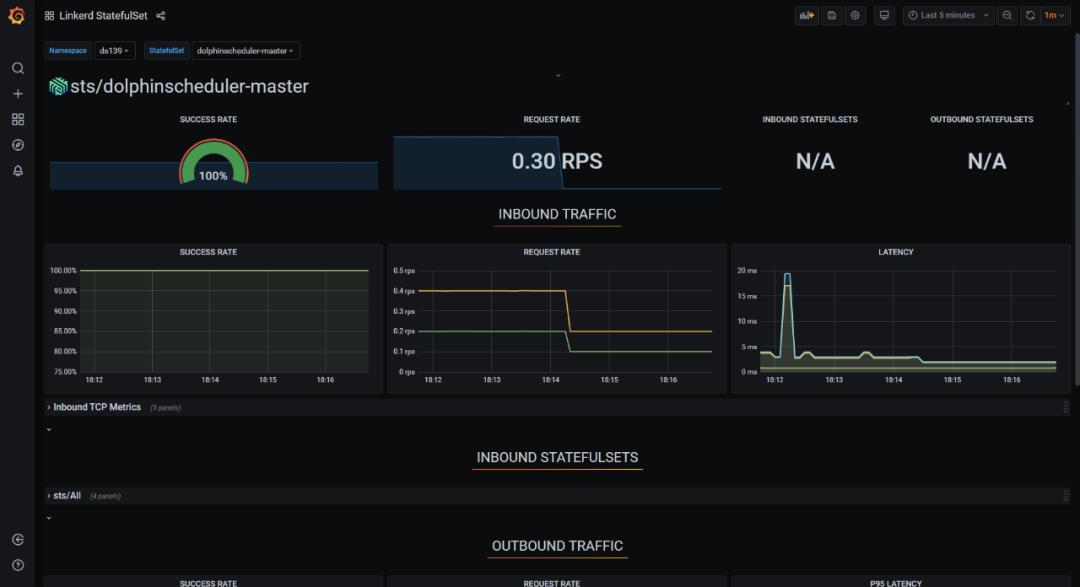
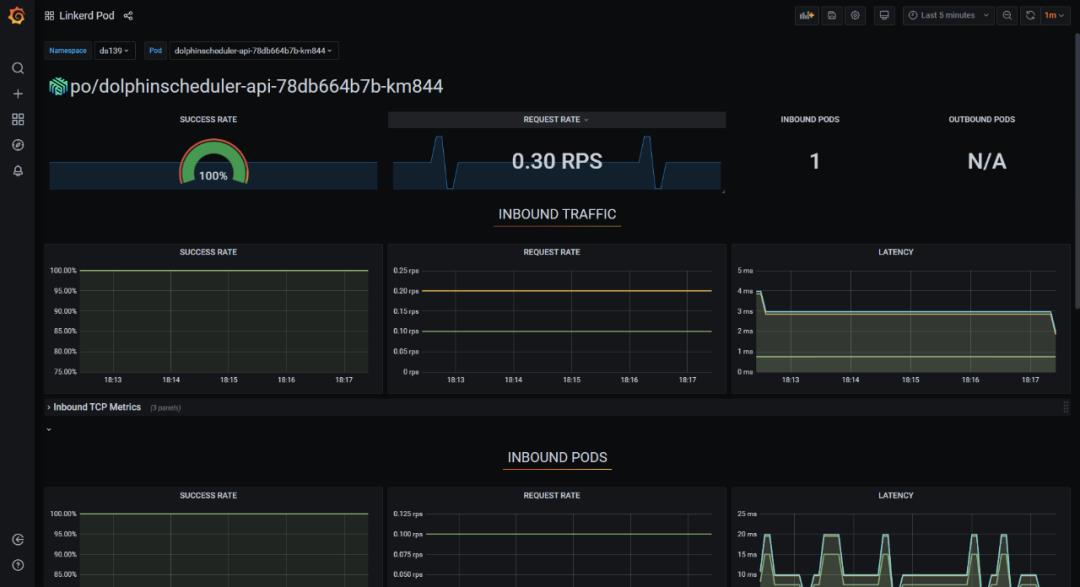
通过 service mesh 技术可以实现对海豚内部的服务调用,以及海豚 api 外部调用的可观测性分析,以实现海豚调度产品的自身服务优化。
我们使用 linkerd 作为 service mesh 的产品进行集成,linkerd 也是 cncf 优秀的毕业项目之一。

只需要在海豚 helm 的 value 文件中修改 annotations,重新部署,就可以快速实现 mesh proxy sidecar 的注入。可以对 master,worker,api,alert 等组件都注入。
annotations: #
linkerd.io/inject: enabled可以观察组件之间的服务通信质量,每秒请求的次数等等。
未来海豚调度基于云原生技术的展望
海豚调度作为面向新一代云原生大数据工具,未来可以在 kubernetes 生态集成更多的优秀工具和特性,满足更多的用户群体和场景。
和 argo-workflow 的集成,可以通过 api,cli 等方式在海豚调度中调用argo-workflow 单个作业,dag 作业,以及周期性作业;
使用 hpa 的方式,自动扩缩容 worker,实现无人干预的水平扩展方式;
集成 kubernetes 的 spark operator 和 flink operator 工具,全面的云原生化;
实现多云和多集群的分布式作业调度,强化 serverless+faas 类的架构属性;
采用 sidecar 实现定期删除 worker 作业日志,进一步实现无忧运维;

往期推荐
从 40% 跌至 4%,“糊”了的 Firefox 还能重回巅峰吗?

点分享

点收藏

点点赞

点在看
以上是关于海豚调度在 Kubernetes 体系中的技术实战的主要内容,如果未能解决你的问题,请参考以下文章