如何利用Python调用一些搜索引擎网站?
Posted 卓晴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何利用Python调用一些搜索引擎网站?相关的知识,希望对你有一定的参考价值。

简 介: 利用 urllib.request 可以调用一些搜索引擎 BING 的搜索引擎结果。但是通过测试发现尚无法对中文进行传递函数进行搜索。具体解决方法现在尚未得知。
关键词: bing,python,搜索引擎
§01 百度搜索
为了对博客中所引用的专业名词给出确切定义,在中文环境下,调用 百度百科 可以对博文专业名词限定准确的含义。那么问题是,如何在不手工打开百度百科的情况下,对于希望名词给出百科词语届时网页链接呢?
下面是根据 Python打开百度并搜索某内容的方法 给出的方法进行测试。
1.1 测试过程
1.1.1 测试代码
#!/usr/local/bin/python
# -*- coding: gbk -*-
#============================================================
# TEST1.PY -- by Dr. ZhuoQing 2022-02-27
#
# Note:
#============================================================
from head import *
import time
from selenium import webdriver
driver = webdriver.Chrome()
#driver.get('https://baike.baidu.com/')
driver.get('https://www.baidu.com')
driver.find_element_by_id('dw').send_keys('木炭')
driver.find_element_by_id('su').click()
time.sleep(5)
driver.find_element_by_id('1').find_element_by_tag_name('a').click()
#------------------------------------------------------------
# END OF FILE : TEST1.PY
#============================================================
1.1.2 测试结果
经过测试可以看到,其中所使用到的 webdriver 对于Chrome浏览器的调用出现异常。也就是当前的 selenium.webdriver 对于Chrome的调用只支持 Chrome version 79。
Traceback (most recent call last):
File "D:\\Temp\\TEMP0002\\test1.PY", line 13, in <module>
driver = webdriver.Chrome()
File "C:\\Users\\zhuoqing\\Anaconda3\\lib\\site-packages\\selenium\\webdriver\\chrome\\webdriver.py", line 81, in __init__
desired_capabilities=desired_capabilities)
File "C:\\Users\\zhuoqing\\Anaconda3\\lib\\site-packages\\selenium\\webdriver\\remote\\webdriver.py", line 157, in __init__
self.start_session(capabilities, browser_profile)
File "C:\\Users\\zhuoqing\\Anaconda3\\lib\\site-packages\\selenium\\webdriver\\remote\\webdriver.py", line 252, in start_session
response = self.execute(Command.NEW_SESSION, parameters)
File "C:\\Users\\zhuoqing\\Anaconda3\\lib\\site-packages\\selenium\\webdriver\\remote\\webdriver.py", line 321, in execute
self.error_handler.check_response(response)
File "C:\\Users\\zhuoqing\\Anaconda3\\lib\\site-packages\\selenium\\webdriver\\remote\\errorhandler.py", line 242, in check_response
raise exception_class(message, screen, stacktrace)
selenium.common.exceptions.SessionNotCreatedException: Message: session not created: This version of ChromeDriver only supports Chrome version 79
但现在所使用的浏览器的Chrome版本为 97,因此出现了异常。
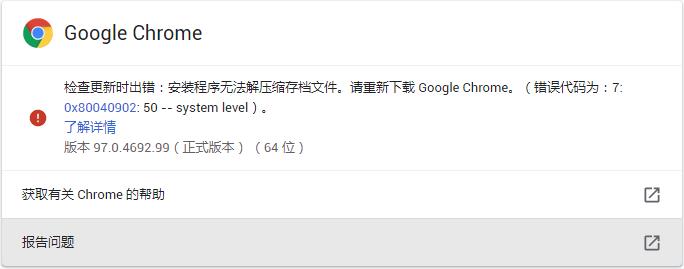
▲ 图1.1.1 所使用到的Chrome的版本
§02 BING搜索
下面是根据 Get Bing search results in Python 博文介绍的方法,直接获得通过BING搜索的结果。
2.1 测试代码
from head import *
from urllib.parse import urlencode, urlunparse
from urllib.request import urlopen, Request
from bs4 import BeautifulSoup
import urllib.request
query = "coal"
page = urllib.request.urlopen('https://www.bing.com/search?q=%s'%query)
soup = BeautifulSoup(page.read())
links = soup.findAll("a")
for link in links:
printf(link["href"])
2.2 测试结果
2.2.1 结果内容
https://www.nationalgeographic.org/encyclopedia/coal/
https://www.nationalgeographic.org/encyclopedia/coal/
https://www.nationalgeographic.org/encyclopedia/coal/
https://www.nationalgeographic.org/encyclopedia/coal/
javascript:void(0)
javascript:void(0)
javascript:void(0)
https://baike.baidu.com/item/coal/19651012
https://baike.baidu.com/item/coal/19651012
---------- [PYTHON INFOR] ----------
D:\\Temp\\TEMP0002\\test1.PY:27: UserWarning: No parser was explicitly specified, so I'm using the best available html parser for this system ("lxml"). This usually isn't a problem, but if you run this code on another system, or in a different virtual environment, it may use a different parser and behave differently.
The code that caused this warning is on line 27 of the file D:\\Temp\\TEMP0002\\test1.PY. To get rid of this warning, pass the additional argument 'features="lxml"' to the BeautifulSoup constructor.
soup = BeautifulSoup(page.read())
https://baike.baidu.com/item/coal/19651012
https://www.usgs.gov/faqs/what-coal
https://www.usgs.gov/faqs/what-coal
https://www.usgs.gov/faqs/what-coal
/dict/search?q=coal&FORM=BDVSP2&qpvt=coal
javascript:void(0);
javascript:void(0);
/dict/search?q=large%20coal&FORM=BDVSP2
/dict/search?q=burn%20coal&FORM=BDVSP2
/dict/search?q=clean%20coal&FORM=BDVSP2
/dict/search?q=buy%20coal&FORM=BDVSP2
/dict/search?q=underground%20coal&FORM=BDVSP2
/dict/search?q=coal&FORM=BDVSP2
https://bingdict.chinacloudsites.cn/download?tag=BDPAN
https://www.britannica.com/science/coal-fossil-fuel
https://www.britannica.com/science/coal-fossil-fuel
https://www.britannica.com/science/coal-fossil-fuel
https://www.britannica.com/science/coal-fossil-fuel
https://www.britannica.com/science/coal-fossil-fuel
https://www.britannica.com/science/coal-fossil-fuel
https://www.britannica.com/science/coal-fossil-fuel
https://www.vedantu.com/chemistry/coal
https://www.vedantu.com/chemistry/coal
https://www.vedantu.com/chemistry/coal
https://www.vedantu.com/chemistry/coal
https://www.vedantu.com/chemistry/coal
https://www.vedantu.com/chemistry/coal
https://simple.wikipedia.org/wiki/Coal
https://simple.wikipedia.org/wiki/Coal
https://simple.wikipedia.org/wiki/Coal
https://simple.wikipedia.org/wiki/Coal
https://www.thefreedictionary.com/coal
https://www.thefreedictionary.com/coal
https://www.merriam-webster.com/dictionary/coal
https://www.merriam-webster.com/dictionary/coal
https://www.iea.org/fuels-and-technologies/coal
https://www.iea.org/fuels-and-technologies/coal
https://www.iea.org/fuels-and-technologies/coal
http://www.cqcoal.com/
http://www.cqcoal.com/
https://www.usgs.gov/faqs/what-coal
/search?q=What%20is%20coal%3F
https://www.nationalgeographic.org/encyclopedia/coal/
/search?q=What%20is%20the%20main%20source%20of%20energy%20in%20coal%3F
https://www.nationalgeographic.org/encyclopedia/coal/
/search?q=What%20is%20the%20lowest%20rank%20of%20coal%3F
https://simple.wikipedia.org/wiki/Coal
/search?q=What%20is%20the%20difference%20between%20coal%20and%20charcoal%3F
javascript:void(0)
/search?q=coal+definition&FORM=QSRE1
/search?q=coal%e6%80%8e%e4%b9%88%e8%af%bb&FORM=QSRE2
/search?q=coal+plant&FORM=QSRE3
/search?q=coal%e6%80%8e%e4%b9%88%e8%af%bb%e8%8b%b1%e8%af%ad&FORM=QSRE4
/search?q=coal%e7%bf%bb%e8%af%91&FORM=QSRE5
/search?q=coal+gasification&FORM=QSRE6
/search?q=coal%e4%bb%80%e4%b9%88%e6%84%8f%e6%80%9d%e4%b8%ad%e6%96%87&FORM=QSRE7
/search?q=china+coal&FORM=QSRE8
http://go.microsoft.com/fwlink/?LinkID=617350
Traceback (most recent call last):
File "D:\\Temp\\TEMP0002\\test1.PY", line 31, in <module>
printf(link["href"])
File "C:\\Users\\zhuoqing\\Anaconda3\\lib\\site-packages\\bs4\\element.py", line 1016, in __getitem__
return self.attrs[key]
KeyError: 'href'
2.2.2 结果分析
在搜索的结果中存在多个连接,它们是给定的多个搜索网页结果。
注意:上面搜索的部分,可以改成一下的网络连接。
page = urllib.request.urlopen('https://cn.bing.com/search?q=%s'%query)
(1)第一个搜索链接
https://www.nationalgeographic.org/encyclopedia/coal/
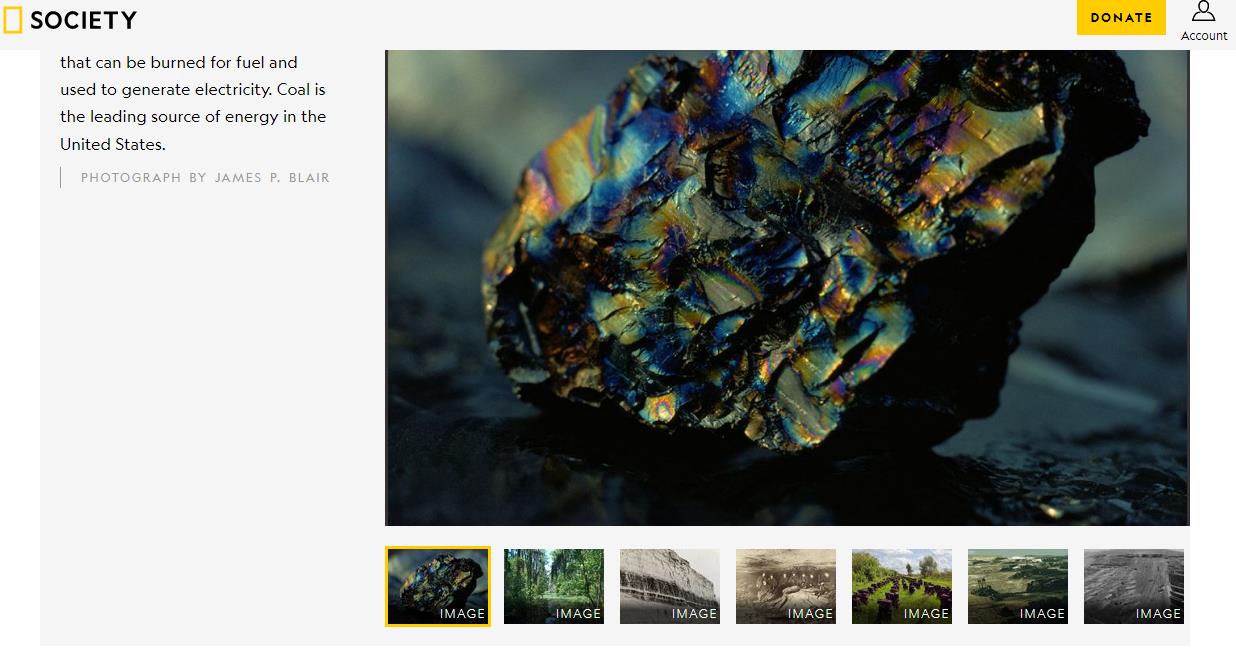
▲ 图2.2.1 第一个搜索结果
(2)第二个搜索结果
百度搜索链接 : https://baike.baidu.com/item/coal/19651012
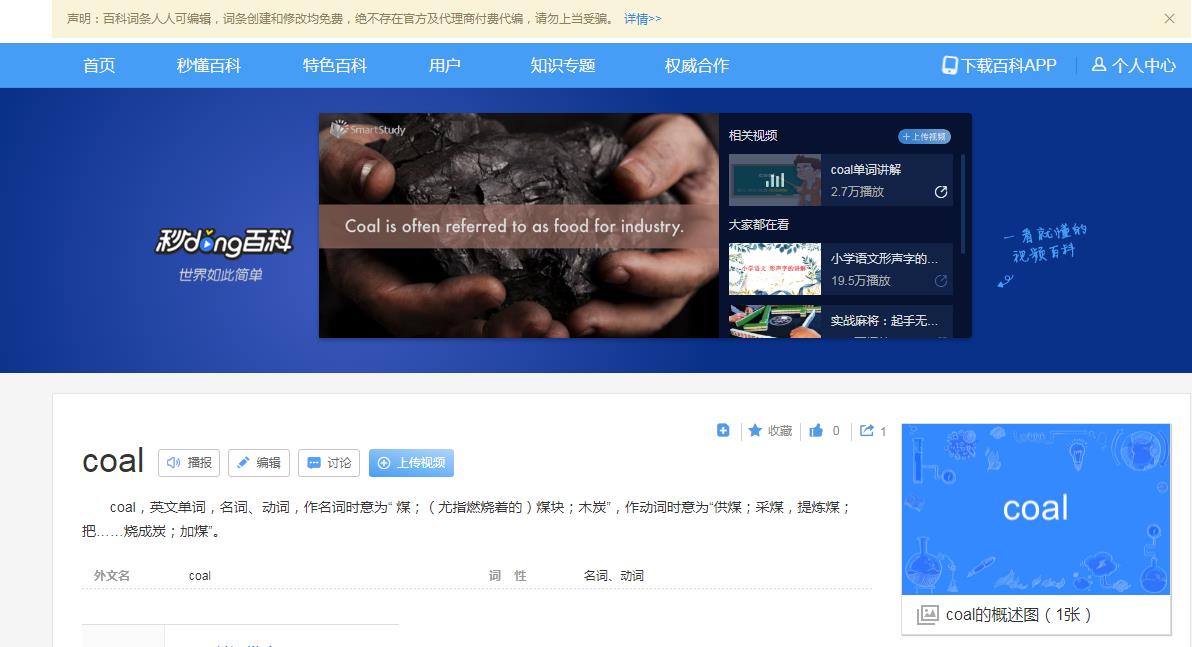
▲ 图2.2.2 第二个是百度搜索链接
(3)第三个搜索链接
USGS搜索链接 相关的内容。
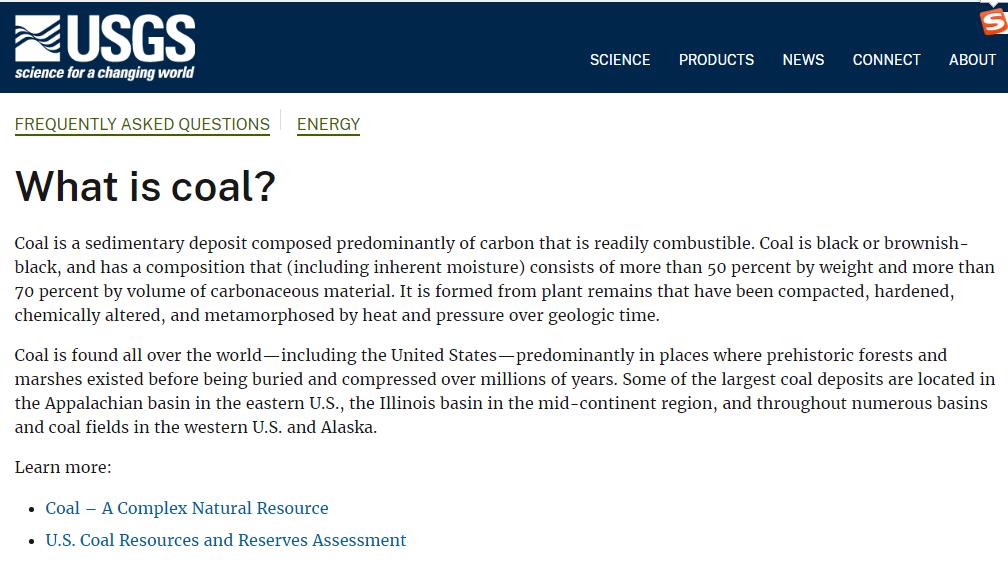
▲ 图2.2.3 第三个搜索链接
Coal | Uses, Types, Pollution, & Facts | Britannica
2.2.3 搜索结论
通过以上结果来看,利用BING搜索可以获得很好的搜索结果。但是,如果吧query 的字符修改成“中文”,则会出现编码错误。
Traceback (most recent call last):
File "D:\\Temp\\TEMP0002\\test1.PY", line 24, in <module>
page = urllib.request.urlopen('https://www.bing.com/search?q=%s'%query)
File "C:\\Users\\zhuoqing\\Anaconda3\\lib\\urllib\\request.py", line 222, in urlopen
return opener.open(url, data, timeout)
.....
File "C:\\Users\\zhuoqing\\Anaconda3\\lib\\http\\client.py", line 1107, in putrequest
self._output(request.encode('ascii'))
UnicodeEncodeError: 'ascii' codec can't encode characters in position 14-15: ordinal not in range(128)
(1)更换编码
利用下面对中文更换编码,可以输出结果,但是对于中文十六进制编码搜索的结果,而不是汉字搜索的结果。
query = bytes('煤炭', encoding='utf-8')
query = "煤炭".encode('utf-8')
※ 总 结 ※
利用 urllib.request 可以调用一些搜索引擎 BING 的搜索引擎结果。但是通过测试发现尚无法对中文进行传递函数进行搜索。具体解决方法现在尚未得知。
3.1 测试程序
#!/usr/local/bin/python
# -*- coding: gbk -*-
#============================================================
# TEST1.PY -- by Dr. ZhuoQing 2022-02-27
#
# Note:
#============================================================
from head import *
from urllib.parse import urlencode, urlunparse
from urllib.request import urlopen, Request
from bs4 import BeautifulSoup
import urllib.request
query = "煤炭"
query = 'coal'
#page = urllib.request.urlopen('https://www.bing.com/search?q=%s'%query)
#page = urllib.request.urlopen('https://cn.bing.com/search?q=%s'%query)
#page = urllib.request.urlopen('https://www.baidu.com/s?wd=%s'%query)
#page = urllib.request.urlopen('https://www.csdn.net/search?q=%s'%query)
# Further code I've left unmodified
soup = BeautifulSoup(page.read())
links = soup.findAll("a")
for link in links:
printf(link["href"])
#------------------------------------------------------------
# END OF FILE : TEST1.PY
#============================================================
■ 相关文献链接:
- 百度百科
- Python打开百度并搜索某内容的方法
- Get Bing search results in Python
- 百度搜索链接
- USGS搜索链接
- Coal | Uses, Types, Pollution, & Facts | Britannica
● 相关图表链接:
以上是关于如何利用Python调用一些搜索引擎网站?的主要内容,如果未能解决你的问题,请参考以下文章