开源工作流任务调度系统:Apache DolphinScheduler
Posted 东海陈光剑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了开源工作流任务调度系统:Apache DolphinScheduler相关的知识,希望对你有一定的参考价值。

Apache DolphinScheduler: 简介
A distributed and easy-to-extend visual workflow scheduler system
dedicated to solving the complex task dependencies in data processing, making the scheduler system out of the box for data processing.

架构组成
Its main objectives are as follows:

快速开始
https://dolphinscheduler.apache.org/en-us/docs/latest/user_doc/guide/installation/standalone.html
https://dolphinscheduler.apache.org/en-us/docs/latest/user_doc/guide/quick-start.html
System Architecture Design
Before explaining the architecture of the scheduling system, let's first understand the commonly used terms of the scheduling system
1.System Structure
1.1 System architecture diagram
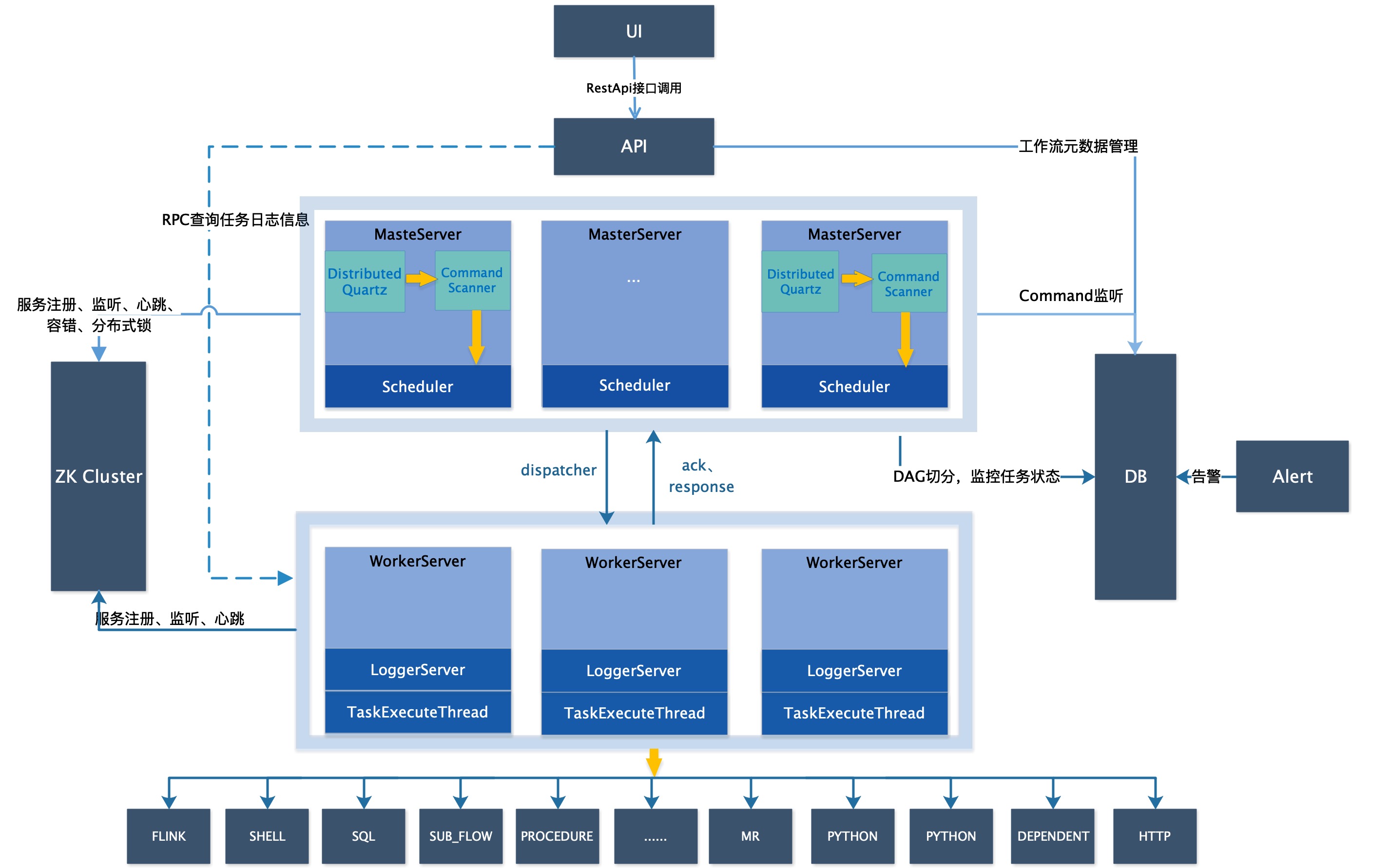 System architecture diagram
System architecture diagram
System architecture diagram
1.2 Start process activity diagram
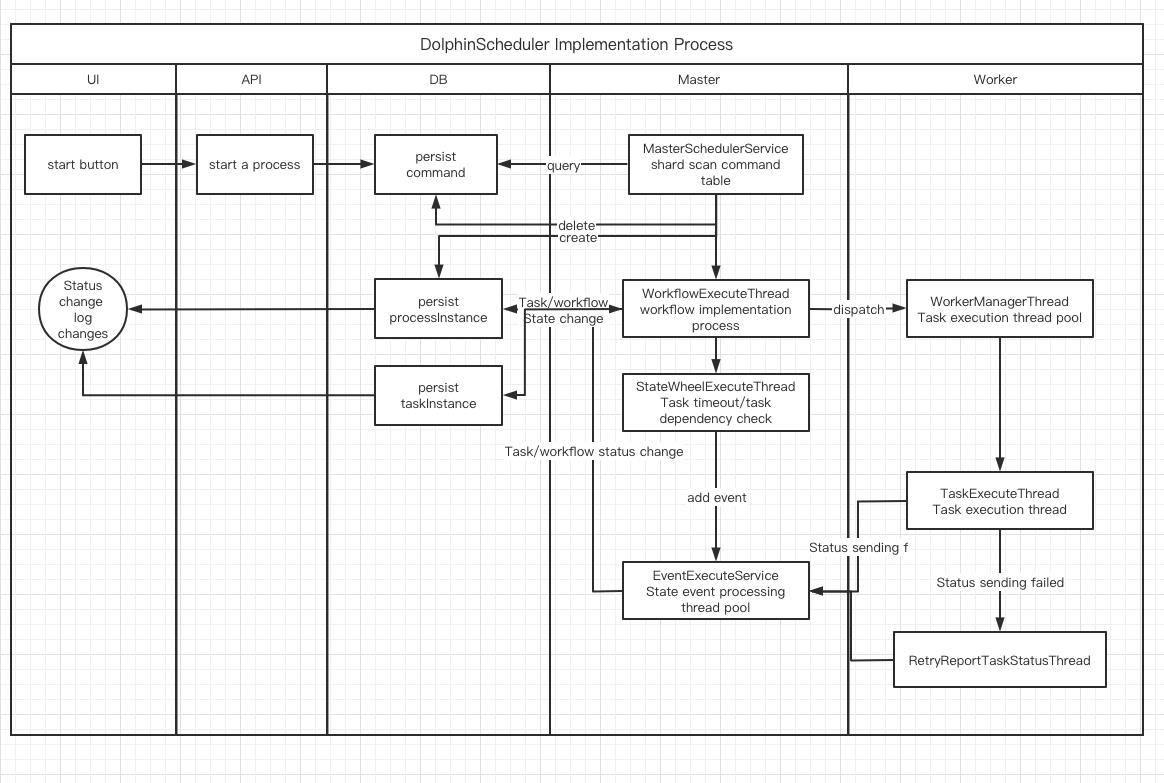 Start process activity diagram
Start process activity diagram
Start process activity diagram
1.3 Architecture description
-
MasterServer
MasterServer adopts a distributed and centerless design concept. MasterServer is mainly responsible for DAG task segmentation, task submission monitoring, and monitoring the health status of other MasterServer and WorkerServer at the same time. When the MasterServer service starts, register a temporary node with Zookeeper, and perform fault tolerance by monitoring changes in the temporary node of Zookeeper. MasterServer provides monitoring services based on netty.
The service mainly includes:
MasterSchedulerService is a scanning thread that scans the command table in the database regularly, generates workflow instances, and performs different business operations according to different command types
WorkflowExecuteThread is mainly responsible for DAG task segmentation, task submission, logical processing of various command types, processing task status and workflow status events
EventExecuteService handles all state change events of the workflow instance that the master is responsible for, and uses the thread pool to process the state events of the workflow
StateWheelExecuteThread handles timing state updates of dependent tasks and timeout tasks
-
WorkerServer
WorkerServer also adopts a distributed centerless design concept, supports custom task plug-ins, and is mainly responsible for task execution and log services. When the WorkerServer service starts, it registers a temporary node with Zookeeper and maintains a heartbeat.
The service mainly includes
- **WorkerManagerThread** mainly receives tasks sent by the master through netty, and calls **TaskExecuteThread** corresponding executors according to different task types.
- **RetryReportTaskStatusThread** mainly reports the task status to the master through netty. If the report fails, the report will always be retried.
- **LoggerServer** is a log service that provides log fragment viewing, refreshing and downloading functions-
Registry
The registry is implemented as a plug-in, and Zookeeper is supported by default. The MasterServer and WorkerServer nodes in the system use the registry for cluster management and fault tolerance. In addition, the system also performs event monitoring and distributed locks based on the registry.
-
Alert
Provide alarm-related functions and only support stand-alone service. Support custom alarm plug-ins.
-
API
The API interface layer is mainly responsible for processing requests from the front-end UI layer. The service uniformly provides RESTful APIs to provide request services to the outside world. Interfaces include workflow creation, definition, query, modification, release, logoff, manual start, stop, pause, resume, start execution from the node and so on.
-
UI
The front-end page of the system provides various visual operation interfaces of the system,See more at Introduction to Functions section。
1.4 Architecture design ideas
One、Decentralization VS centralization
Centralized thinking
The centralized design concept is relatively simple. The nodes in the distributed cluster are divided into roles according to roles, which are roughly divided into two roles:
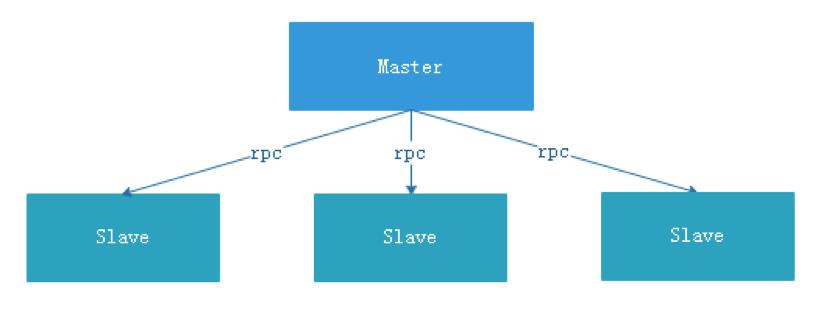 master-slave character
master-slave character
- The role of the master is mainly responsible for task distribution and monitoring the health status of the slave, and can dynamically balance the task to the slave, so that the slave node will not be in a "busy dead" or "idle dead" state.
- The role of Worker is mainly responsible for task execution and maintenance and Master's heartbeat, so that Master can assign tasks to Slave.
Problems in centralized thought design:
- Once there is a problem with the Master, the dragons are headless and the entire cluster will collapse. In order to solve this problem, most of the Master/Slave architecture models adopt the design scheme of active and standby Master, which can be hot standby or cold standby, or automatic switching or manual switching, and more and more new systems are beginning to have The ability to automatically elect and switch Master to improve the availability of the system.
- Another problem is that if the Scheduler is on the Master, although it can support different tasks in a DAG running on different machines, it will cause the Master to be overloaded. If the Scheduler is on the slave, all tasks in a DAG can only submit jobs on a certain machine. When there are more parallel tasks, the pressure on the slave may be greater.
Decentralized
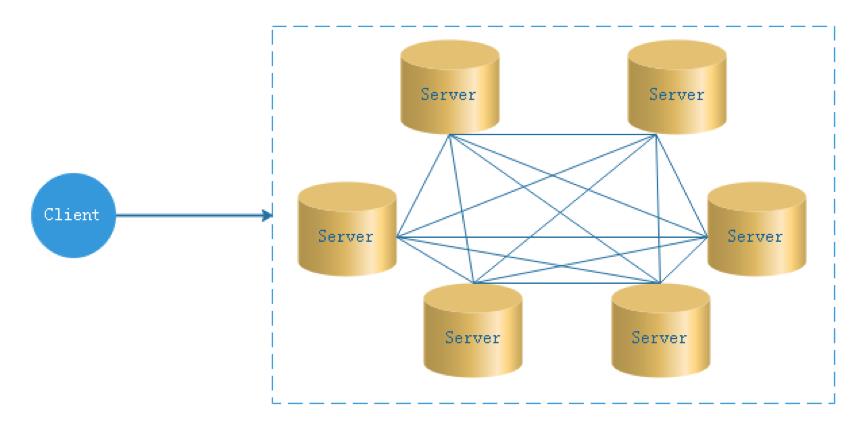 Decentralization
Decentralization
In the decentralized design, there is usually no concept of Master/Slave, all roles are the same, the status is equal, the global Internet is a typical decentralized distributed system, any node equipment connected to the network is down, All will only affect a small range of functions.
The core design of decentralized design is that there is no "manager" different from other nodes in the entire distributed system, so there is no single point of failure. However, because there is no "manager" node, each node needs to communicate with other nodes to obtain the necessary machine information, and the unreliability of distributed system communication greatly increases the difficulty of implementing the above functions.
In fact, truly decentralized distributed systems are rare. Instead, dynamic centralized distributed systems are constantly pouring out. Under this architecture, the managers in the cluster are dynamically selected, rather than preset, and when the cluster fails, the nodes of the cluster will automatically hold "meetings" to elect new " managers" To preside over the work. The most typical case is Etcd implemented by ZooKeeper and Go language.
The decentralization of DolphinScheduler is that the Master/Worker is registered in Zookeeper to realize the non-centralization of the Master cluster and the Worker cluster. The sharding mechanism is used to fairly distribute the workflow for execution on the master, and tasks are sent to the workers for execution through different sending strategies. Specific task
Second, the master execution process
DolphinScheduler uses the sharding algorithm to modulate the command and assigns it according to the sort id of the master. The master converts the received command into a workflow instance, and uses the thread pool to process the workflow instance
DolphinScheduler's process of workflow:
- Start the workflow through UI or API calls, and persist a command to the database
- The Master scans the Command table through the sharding algorithm, generates a workflow instance ProcessInstance, and deletes the Command data at the same time
- The Master uses the thread pool to run WorkflowExecuteThread to execute the process of the workflow instance, including building DAG, creating task instance TaskInstance, and sending TaskInstance to worker through netty
- After the worker receives the task, it modifies the task status and returns the execution information to the Master
- The Master receives the task information, persists it to the database, and stores the state change event in the EventExecuteService event queue
- EventExecuteService calls WorkflowExecuteThread according to the event queue to submit subsequent tasks and modify workflow status
Three、Insufficient thread loop waiting problem
- If there is no sub-process in a DAG, if the number of data in the Command is greater than the threshold set by the thread pool, the process directly waits or fails.
- If many sub-processes are nested in a large DAG, the following figure will produce a "dead" state:
 Insufficient threads waiting loop problem
Insufficient threads waiting loop problem
In the above figure, MainFlowThread waits for the end of SubFlowThread1, SubFlowThread1 waits for the end of SubFlowThread2, SubFlowThread2 waits for the end of SubFlowThread3, and SubFlowThread3 waits for a new thread in the thread pool, then the entire DAG process cannot end, so that the threads cannot be released. In this way, the state of the child-parent process loop waiting is formed. At this time, unless a new Master is started to add threads to break such a "stalemate", the scheduling cluster will no longer be used.
It seems a bit unsatisfactory to start a new Master to break the deadlock, so we proposed the following three solutions to reduce this risk:
- Calculate the sum of all Master threads, and then calculate the number of threads required for each DAG, that is, pre-calculate before the DAG process is executed. Because it is a multi-master thread pool, the total number of threads is unlikely to be obtained in real time.
- Judge the single-master thread pool. If the thread pool is full, let the thread fail directly.
- Add a Command type with insufficient resources. If the thread pool is insufficient, suspend the main process. In this way, there are new threads in the thread pool, which can make the process suspended by insufficient resources wake up to execute again.
note: The Master Scheduler thread is executed by FIFO when acquiring the Command.
So we chose the third way to solve the problem of insufficient threads.
Four、Fault-tolerant design
Fault tolerance is divided into service downtime fault tolerance and task retry, and service downtime fault tolerance is divided into master fault tolerance and worker fault tolerance.
1. Downtime fault tolerance
The service fault-tolerance design relies on ZooKeeper's Watcher mechanism, and the implementation principle is shown in the figure:
 DolphinScheduler fault-tolerant design
DolphinScheduler fault-tolerant design
Among them, the Master monitors the directories of other Masters and Workers. If the remove event is heard, fault tolerance of the process instance or task instance will be performed according to the specific business logic.
- Master fault tolerance:
 failover-master
failover-master
Fault tolerance range: From the perspective of host, the fault tolerance range of Master includes: own host + node host that does not exist in the registry, and the entire process of fault tolerance will be locked;
Fault-tolerant content: Master's fault-tolerant content includes: fault-tolerant process instances and task instances. Before fault-tolerant, it compares the start time of the instance with the server start-up time, and skips fault-tolerance if after the server start time;
Fault-tolerant post-processing: After the fault tolerance of ZooKeeper Master is completed, it is re-scheduled by the Scheduler thread in DolphinScheduler, traverses the DAG to find the "running" and "submit successful" tasks, monitors the status of its task instances for the "running" tasks, and "commits successful" tasks It is necessary to determine whether the task queue already exists. If it exists, the status of the task instance is also monitored. If it does not exist, resubmit the task instance.
- Worker fault tolerance:
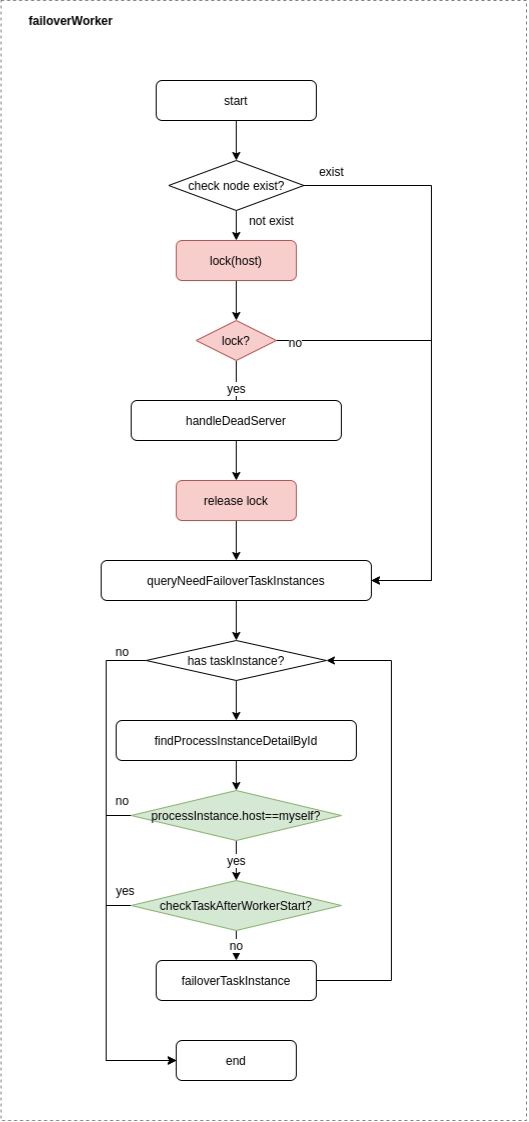 failover-worker
failover-worker
Fault tolerance range: From the perspective of process instance, each Master is only responsible for fault tolerance of its own process instance; it will lock only when handleDeadServer;
Fault-tolerant content: When sending the remove event of the Worker node, the Master only fault-tolerant task instances. Before fault-tolerant, it compares the start time of the instance with the server start-up time, and skips fault-tolerance if after the server start time;
Fault-tolerant post-processing: Once the Master Scheduler thread finds that the task instance is in the "fault-tolerant" state, it takes over the task and resubmits it.
Note: Due to "network jitter", the node may lose its heartbeat with ZooKeeper in a short period of time, and the node's remove event may occur. For this situation, we use the simplest way, that is, once the node and ZooKeeper timeout connection occurs, then directly stop the Master or Worker service.
2.Task failed and try again
Here we must first distinguish the concepts of task failure retry, process failure recovery, and process failure rerun:
- Task failure retry is at the task level and is automatically performed by the scheduling system. For example, if a Shell task is set to retry for 3 times, it will try to run it again up to 3 times after the Shell task fails.
- Process failure recovery is at the process level and is performed manually. Recovery can only be performed from the failed node or from the current node
- Process failure rerun is also at the process level and is performed manually, rerun is performed from the start node
Next to the topic, we divide the task nodes in the workflow into two types.
One is a business node, which corresponds to an actual script or processing statement, such as Shell node, MR node, Spark node, and dependent node.
There is also a logical node, which does not do actual script or statement processing, but only logical processing of the entire process flow, such as sub-process sections.
Each business node can be configured with the number of failed retries. When the task node fails, it will automatically retry until it succeeds or exceeds the configured number of retries. Logical node Failure retry is not supported. But the tasks in the logical node support retry.
If there is a task failure in the workflow that reaches the maximum number of retries, the workflow will fail to stop, and the failed workflow can be manually rerun or process recovery operation
Five、Task priority design
In the early scheduling design, if there is no priority design and the fair scheduling design is used, the task submitted first may be completed at the same time as the task submitted later, and the process or task priority cannot be set, so We have redesigned this, and our current design is as follows:
- According to priority of different process instances priority over priority of the same process instance priority over priority of tasks within the same processpriority over tasks within the same processsubmission order from high to Low task processing.
-
The specific implementation is to parse the priority according to the JSON of the task instance, and then save the process instance priority_process instance id_task priority_task id information in the ZooKeeper task queue, when obtained from the task queue, pass String comparison can get the tasks that need to be executed first
-
The priority of the process definition is to consider that some processes need to be processed before other processes. This can be configured when the process is started or scheduled to start. There are 5 levels in total, which are HIGHEST, HIGH, MEDIUM, LOW, and LOWEST. As shown below
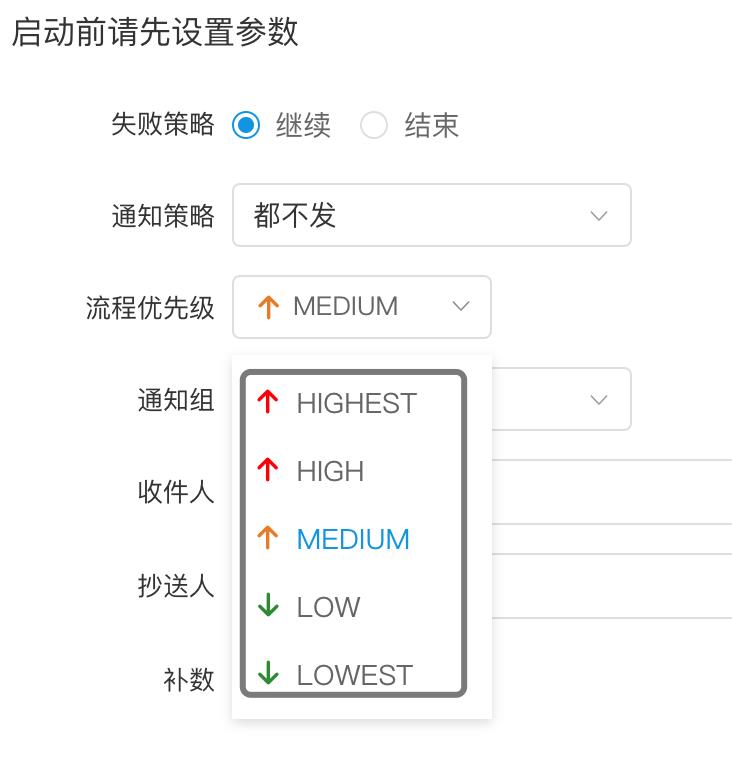 Process priority configuration
Process priority configuration
-
The priority of the task is also divided into 5 levels, followed by HIGHEST, HIGH, MEDIUM, LOW, LOWEST. As shown below
 Task priority configuration
Task priority configuration
-
-
Six、Logback and netty implement log access
Since Web (UI) and Worker are not necessarily on the same machine, viewing the log cannot be like querying a local file. There are two options:
Put logs on the ES search engine
Obtain remote log information through netty communication
In consideration of the lightness of DolphinScheduler as much as possible, so I chose gRPC to achieve remote access to log information.
 grpc remote access
grpc remote access
- We use the FileAppender and Filter functions of the custom Logback to realize that each task instance generates a log file.
- FileAppender is mainly implemented as follows:
/**
* task log appender
*/
public class TaskLogAppender extends FileAppender<ILoggingEvent>
...
@Override
protected void append(ILoggingEvent event)
if (currentlyActiveFile == null)
currentlyActiveFile = getFile();
String activeFile = currentlyActiveFile;
// thread name: taskThreadName-processDefineId_processInstanceId_taskInstanceId
String threadName = event.getThreadName();
String[] threadNameArr = threadName.split("-");
// logId = processDefineId_processInstanceId_taskInstanceId
String logId = threadNameArr[1];
...
super.subAppend(event);
Generate logs in the form of /process definition id/process instance id/task instance id.log
- Filter to match the thread name starting with TaskLogInfo:
- TaskLogFilter is implemented as follows:
```java
/**
* task log filter
*/
public class TaskLogFilter extends Filter<ILoggingEvent>
@Override
public FilterReply decide(ILoggingEvent event)
if (event.getThreadName().startsWith("TaskLogInfo-"))
return FilterReply.ACCEPT;
return FilterReply.DENY;
https://dolphinscheduler.apache.org/en-us/docs/latest/user_doc/architecture/design.html
以上是关于开源工作流任务调度系统:Apache DolphinScheduler的主要内容,如果未能解决你的问题,请参考以下文章