深度学习网络模型介绍及实战
Posted GoAI
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习网络模型介绍及实战相关的知识,希望对你有一定的参考价值。
学习资料总结:
经典网络介绍:
白话系列:
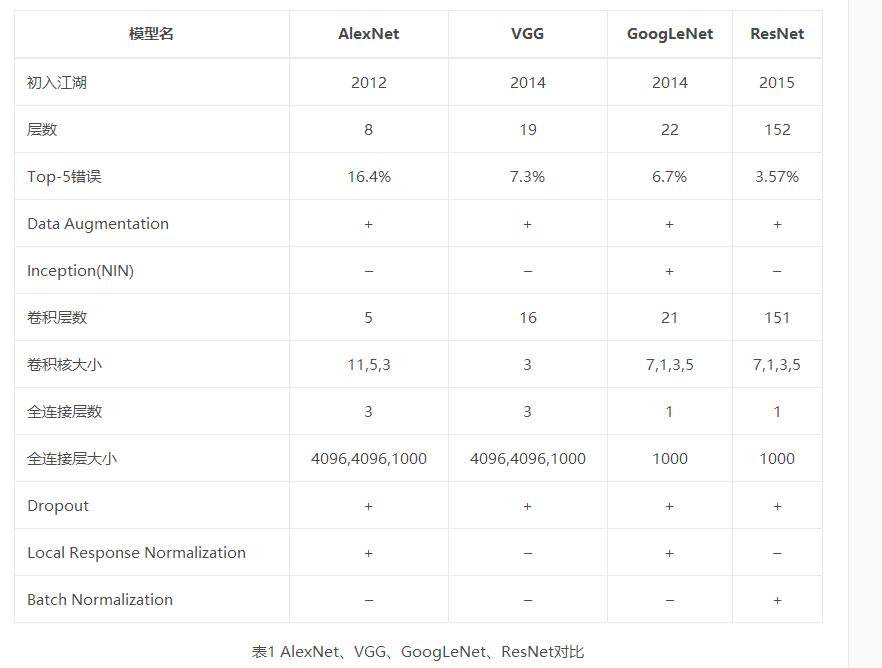
1.LeNet-5



神经元个数=卷积核数量X输出特征图宽度X输出特征图高度
卷积层可训练参数数量=卷积核数量X(卷积核宽度X卷积核高度+1)(1表示偏置)
汇聚层可训练参数数量=卷积核数量X(1+1)(两个1分别表示相加后的系数和偏置,有的汇聚层无参数)
连接数=卷积核数量X(卷积核宽度X卷积核高度+1)X输出特征图宽度X输出特征图高度(1表示偏置)
全连接层连接数=卷积核数量X(输入特征图数量X卷积核宽度X卷积核高度+1)(输出特征图尺寸为1X1)
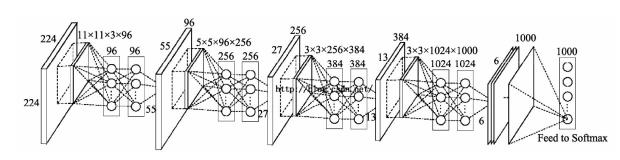
2.AlexNet
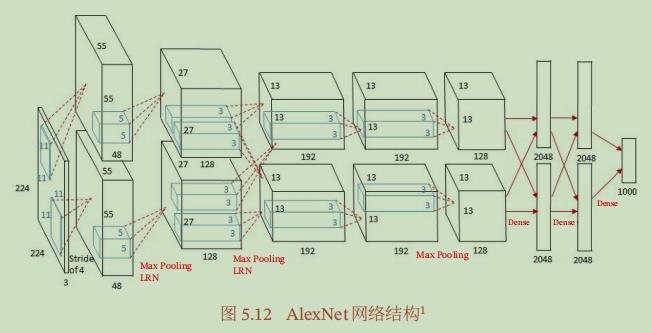


3.Inception网络
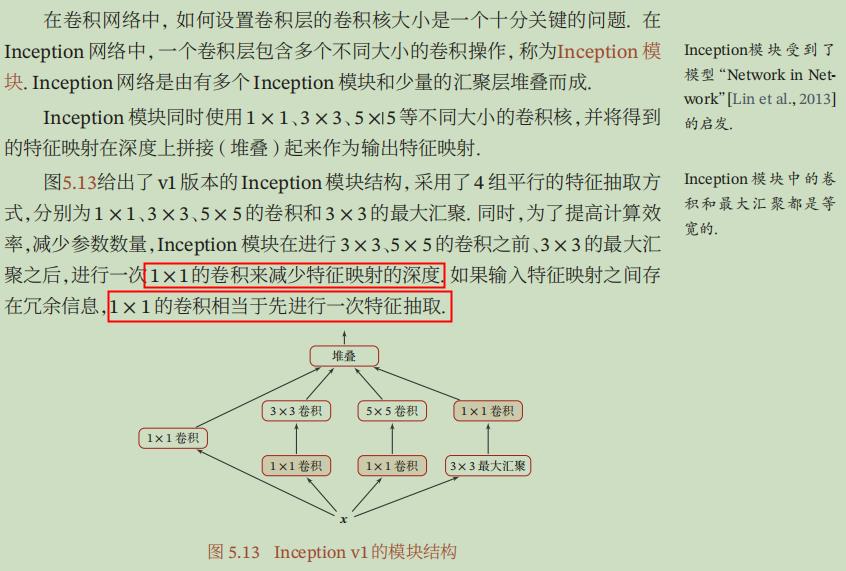
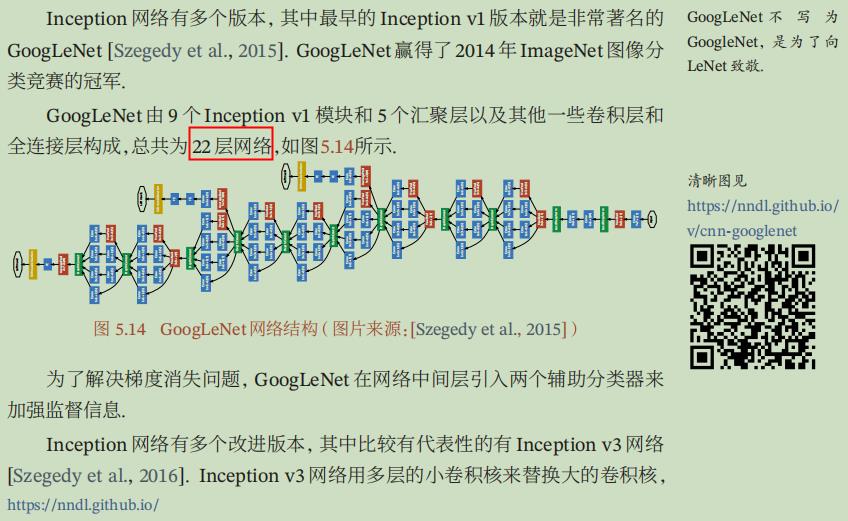

GoogleNet模型详细解读:
去除全连接层,使得模型训练更快并且减轻了过拟合。
Inception的核心思想是通过增加网络深度和宽度的同时减少参数的方法来解决问题。Inception v1由22层,比AlexNet的8层或VGGNet的19层更深。但其计算量只有15亿次浮点运算,同时只有500万的参数量,仅为AlexNet的1/12,却有着更高的准确率。
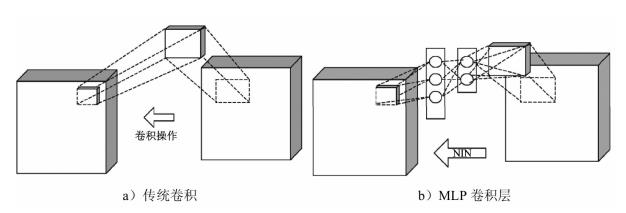
Inception的前身为MLP卷积层。
卷积层要提升表达能力,主要依靠增加输出通道数,每个输出通道对应一个滤波器,同一滤波器共享参数只能提取一类特征,因此一个输出通道只能做一种特征处理。所以在传统的CNN中会使用尽量多的滤波器,把原样本中尽可能多的潜在的特征提取出来,然后再通过池化和大量的线性变化在其中筛选出需要的特征。这样的代价就是参数太多,运算太满,而且很容易引起过拟合。
MLP卷积层的思想是将CNN高维度特征转成低维度特征,将神经网络的思想融合在具体的卷积操作当中。直白的理解就是在网络中再放一个网络,即使每个卷积的通道中包含一个微型的多层网络,用一个网络来代替原来具体的卷积运算过程(卷积核的每个值与样本对应的像素点相乘,再将相乘后的所有结果加在一起生成新的像素点的过程)
全局均值池化是在平均池化层中使用同等大小的过滤器将其特征保存下来。这种结构用来代替深层网络结构最后的全连接输出层。具体用法是在卷积处理之后,对每个特征图的整张图片进行全局均值池化,生成一个值,即每张特征图相当于一个输出特征,这个特征就表示了我们输出类的特征。如图输出1000个特征图
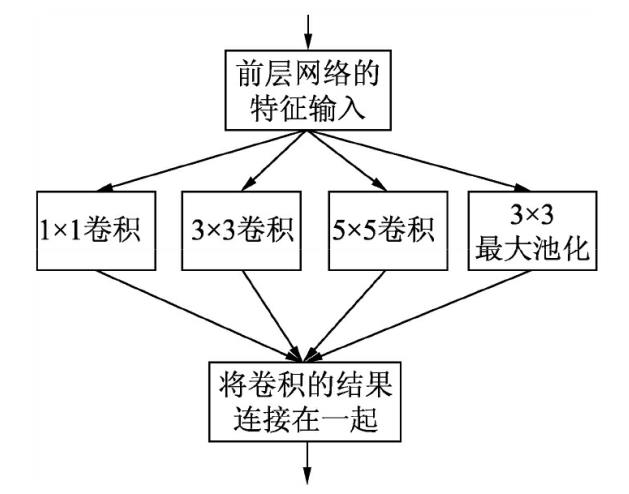
Inception的原始模型是相当于MLP卷积层更为稀疏,它采用了MLP卷积层的思想,将中间的全连接层换成了多通道卷积层。Inception与MLP卷积在网络中的作用一样,把封装好的Inception作为一个卷积单元,堆积起来形成了原始的GoogleNet网络。
其结构是将1x1、3x3、5x5的卷积核对应的卷积操作和3x3的滤波器对应的池化操作堆叠在一起,一方面增加了网络的宽度,另一方面增加了网络对尺度的适应性。增加了网络对不同尺度的适应性。
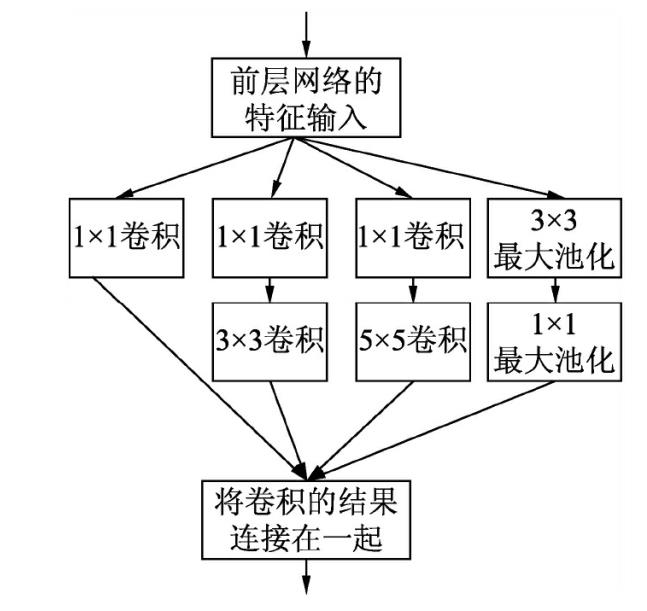
Inception v1模型在原有的Inception模型基础上做了一些改进,原因是由于Inception的原始模型是将所有的卷积核都在上一层的所有输出上来做,那么5x5的卷积核所需的计算量就比较大,造成了特征图厚度很大。为了避免这一现象,在3x3前、5x5前、最大池化层后分别加上了1x1的卷积核,起到了降低特征图厚度的作用(其中1x1卷积主要用来降维)
Inception v2模型在v1模型基础上应用当时的主流技术,在卷积后加入BN层,使每一层的输出都归一化处理,减少了内变协变量的移动问题;同时还使用了梯度截断技术,增加了训练的稳定性。另外,Inception学习了VGG,用2个3x3的conv替代5x5,这既降低了参数数量,也提升了计算速度。
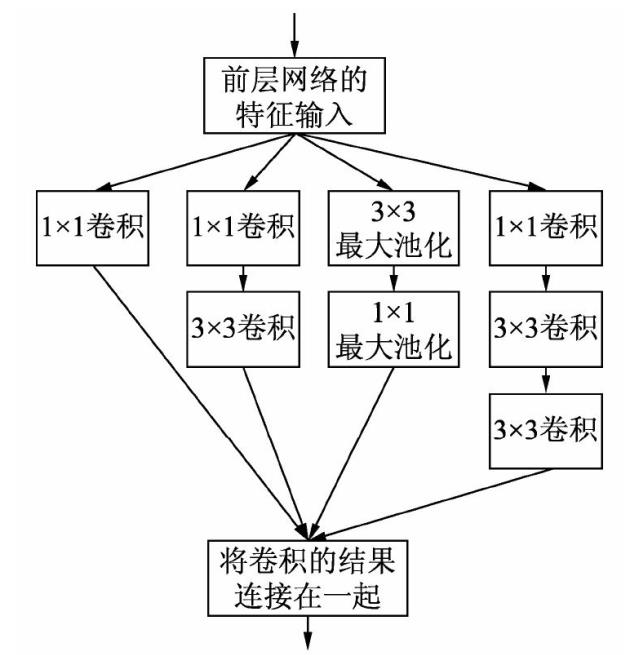
Inception v3没有再加入其他的技术,只是将原来的结构进行了调整,其最重要的一个改进是分解。
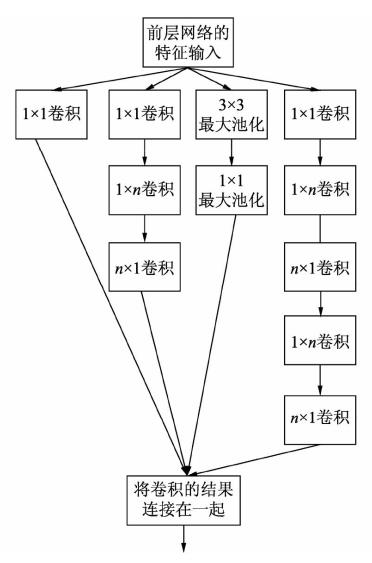
Inception v4结合残差连接技术的特点进行结构的优化调整。
4.残差网络(ResNet)

残差网络详细解读:

该框架能够大大简化模型网络的训练时间,使得再可接受时间内,模型能更深。所谓的残差连接就是在标准的前馈卷积网络上加一个跳跃,从而绕过一些层的连接方式。解决梯度消失的问题
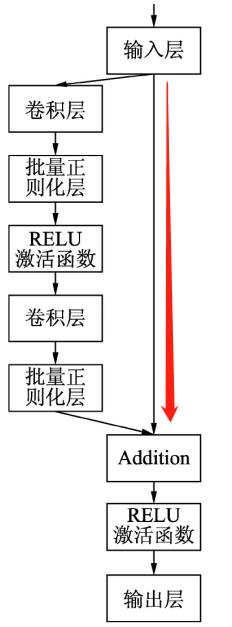
在ResNet中,输入层与Addition之间存在着两个连接,左侧的连接是输入层通过若干神经层之后连接到Addition,右侧的连接是输入层直接传到Addition,在反向传播的过程中误差传到Input时会得到两个误差的相加和,一个是左侧一堆网络的误差,一个右侧直接的原始误差。左侧的误差会随着层数变深而梯度越来越小,右侧则是由Addition直接连接到Input,所以还会保留着Addition的梯度。这样Input得到的相加和后的梯度就没有那么小了,可以保证接着将误差往下传。
3、实物检测领域的相关模型
RCNN(regions with CNN)模型增加特征的穷举范围,然后在其中发现有价值的特征。大概步骤如下:
(1)对于一副输入的图片,通过选择性搜索,找出2000个候选窗口。
(2)利用CNN对它们提取特征向量,即将这2000个子图统一缩放到227x227,然后进行卷积操作。
(3)利用SVM算法对特征向量进行分类识别。
RCNN中对每一类都进行SVM训练,根据输出的特征类为每一个区打分,最终决定保留或拒绝该区域特征。
SPP-Net:基于空间金字塔池化的优化RCNN方法。空间金字塔池化(Spatial Pyramid Pooling, SPP)最大的特点是,不再关心输入图片的尺寸,而是根据最后的输出类别个数,通过算法来生成多个不同范围的池化层,由它们对输入进行并行池化处理,使最终的输出特征个数与生成类别个数相等,接着再进行类别的比较和判定。
Fast-R-CNN在SPP-Net基础上进行了改进,并将它嫁接到VGG16上所形成的网络,实现了整个网络端到端的训练。
YOLO:能够一次性预测多个位置和类别的模型。先将图片分为SxS个网络,每个网络相当于一个任务,负责检测内部是否有物体的中心点落入该区域,一旦有的话,则启动该任务来检测n个bounding boxes对象。
SSD:比YOLO更快更准的模型,融合了RPN的思想
以上是关于深度学习网络模型介绍及实战的主要内容,如果未能解决你的问题,请参考以下文章