英文文本分类实战之二——数据集挑选与划分
Posted 征途黯然.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了英文文本分类实战之二——数据集挑选与划分相关的知识,希望对你有一定的参考价值。
·请参考本系列目录:【英文文本分类实战】之一——实战项目总览
·下载本实战项目资源:神经网络实现英文文本分类.zip(pytorch)
[1] 数据集平台
在阅读了大量的论文之后,由于每一篇论文都会提出一个模型,十分想复现每个模型。但是受制于苦苦无法寻觅到合适的数据集,且下载下来一个数据集后,由于格式的不同,没有很好的数据集预处理方案,这对我们复现论文有很大阻力。
下面的网址列表不仅包含用于实验的大型数据集,还包含描述、使用示例等,在某些情况下还包含用于解决与该数据集相关的机器学习问题的算法代码。
1-Kaggle数据集
网址:http://www.kaggle.com/datasets
强烈推荐这个数据集社区! 每个数据集都有对应的一个小型社区,可以在其中讨论数据、查找公共代码或在内核中创建自己的项目。该网站包含大量形状、大小、格式各异的真实数据集。还可以看到与每个数据集相关的“内核”,其中许多不同的数据科学家提供了笔记来分析数据集。有时在某些特定的数据集中,可以从笔记中找到相应的算法,解决预测问题。
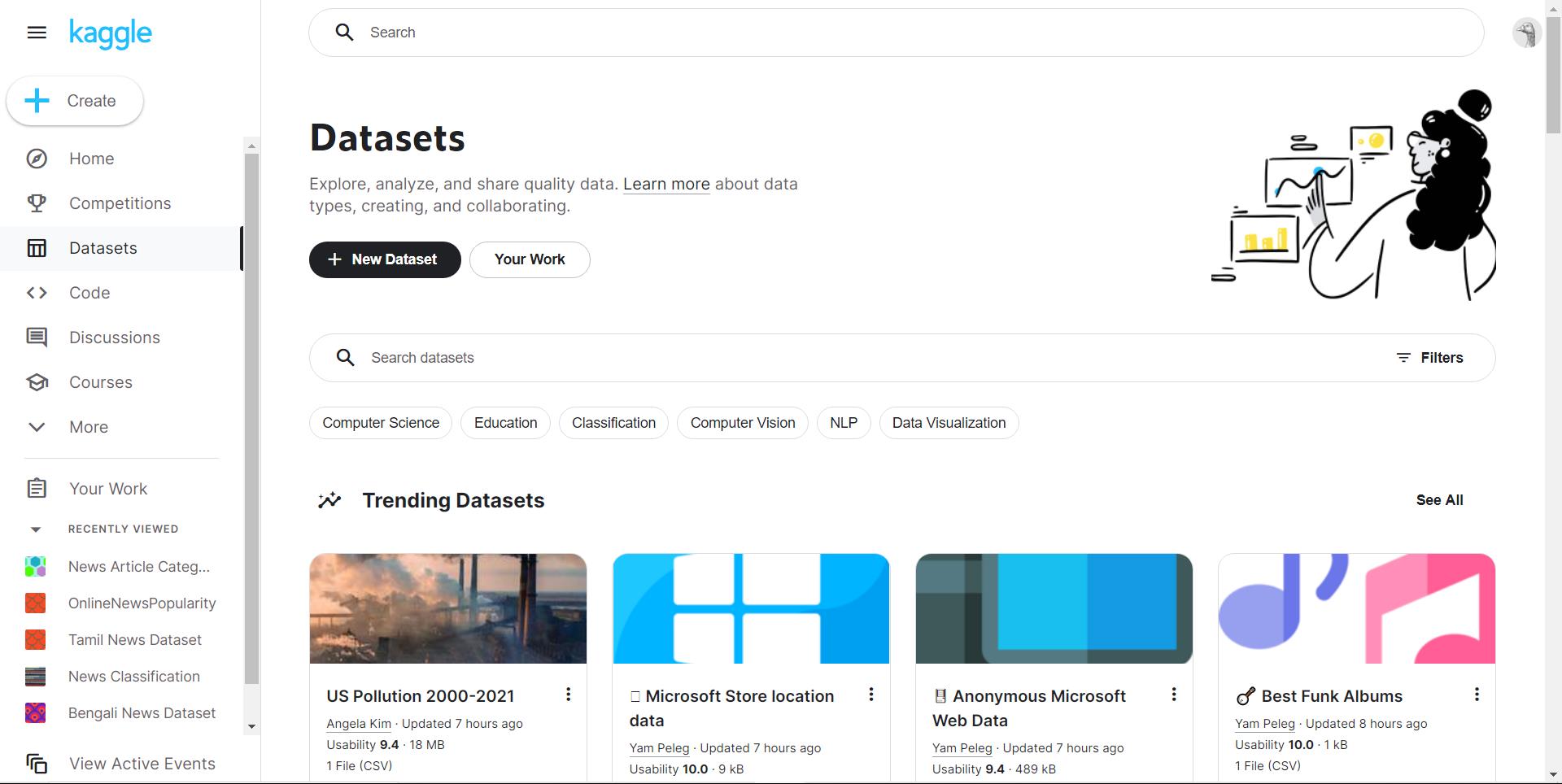
【注】:后续讲解代码时,数据集将从Kaggle网站下载。
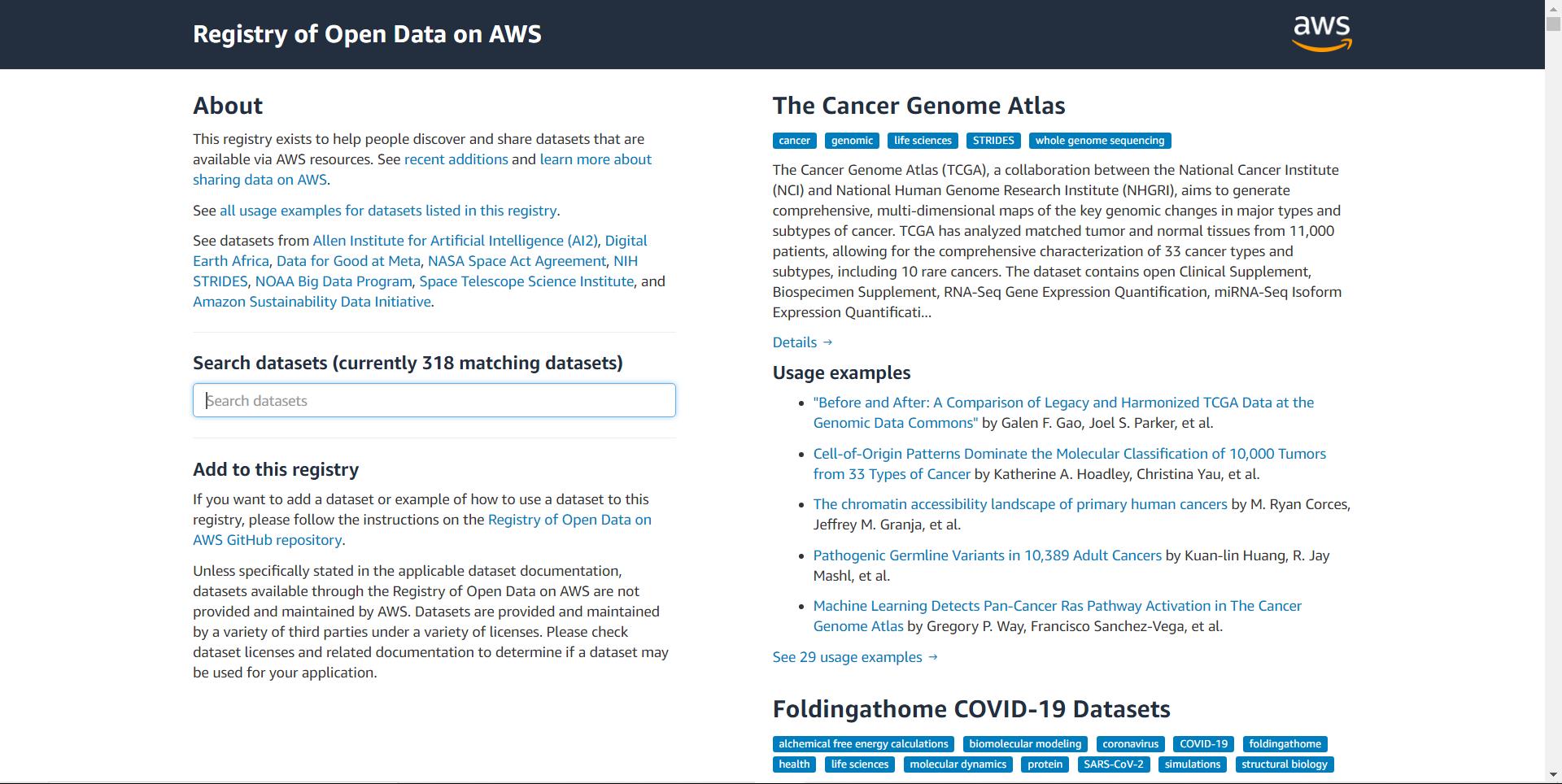
2-亚马逊数据集
网址:https://registry.opendata.aws
该数据源包含多个不同领域的数据集,如:公共交通、生态资源、卫星图像等。它也有一个搜索框来帮助你找到你正在寻找的数据集,另外它还有数据集描述和使用示例,这是非常简单、实用的!
3-微软研究开放数据
2018年7月,微软与外部研究社区共同宣布推出“微软研究开放数据”。
它在公共云中包含一个数据存储库,用于促进全球研究社区之间的协作。另外它还提供了一组在已发表的研究中使用的、经过整理的数据集。
[2] 下载数据集
我们的项目的主题为 “英文文本分类”。
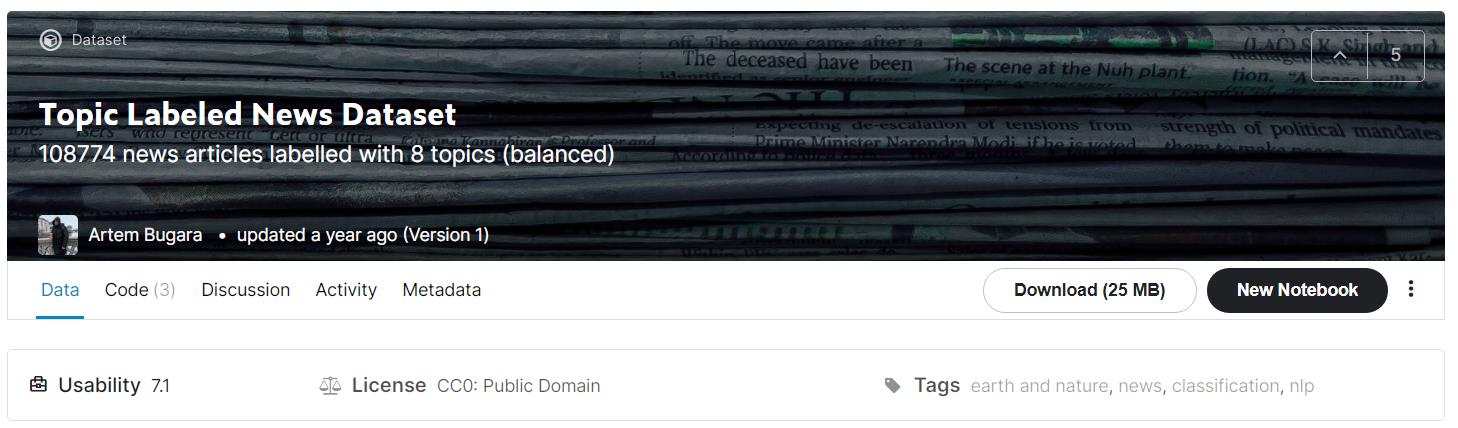
我们从Kaggle数据集平台上任意找一个文本数据集,如下图,名为 “Topic Labeled News Dataset”。
【注】:这里突出“任意找一个”数据集,具有普遍性。这样大家用自己的数据集,按照本博客的方法一样可行。但是,最好是现成的数据集,自己去爬取的数据可能会有格式不正确等各种问题。
这样下载下来的数据集,有许多问题,并不能直接就应用于文本分类任务,其缺点有:
1、下载的数据集是一个csv文件,需要人为分成训练集、验证集、测试集;
2、文本数据有大小写问题、特殊字符问题、缩写问题等等,我们不能拿过来就直接用,需要经过一定的预处理;
3、在文本分类任务中,还会使用预训练的词向量,需要考虑到词向量的词与数据集中词的覆盖程度。
下面我们来一一解决这些问题。
[3] 划分数据集
刚才我们下载的数据集如下图:
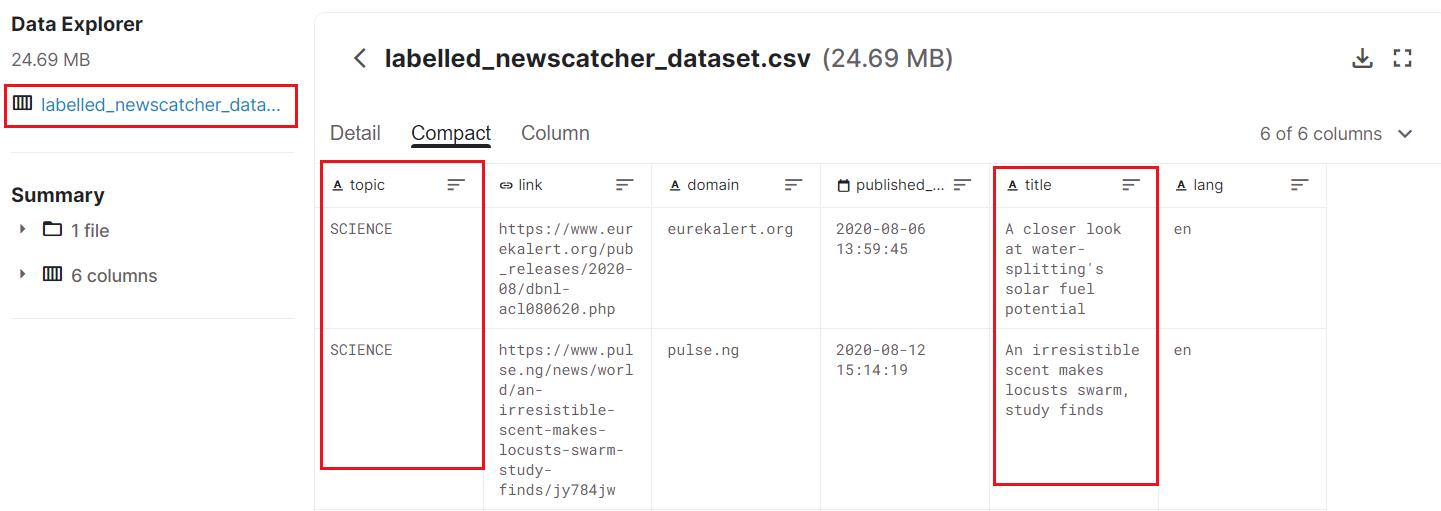
分析数据集: 如上图,我们下载的数据集是一个名为labelled_newscatcher_dataset.csv的文件,其中的topic列为数据标签,title列为数据文本。
需要把一个文件labelled_newscatcher_dataset.csv,拆分为训练集train.csv、验证集dev.csv、测试集test.csv。
读取数据集,先统计一下每个标签对应的文本数,代码如下:
df = pd.read_csv("../@_数据集/TLND/data/labelled_newscatcher_dataset.csv", encoding='utf-8', sep=';')
labels = set(df['topic'])
contents = df['title']
count =
cal =
for p in df['topic']:
cal[p] = 0
try:
count[p] += 1
except KeyError:
count[p] = 1
print(count)
"""输出如下
'SCIENCE': 3774, 'TECHNOLOGY': 15000,
'HEALTH': 15000, 'WORLD': 15000,
'ENTERTAINMENT': 15000, 'SPORTS': 15000,
'BUSINESS': 15000, 'NATION': 15000
"""
【注】:在使用pandas读取csv文件时,要注意分隔符不一定都是逗号。
之后,按照70:15:15的比例来均分数据集为训练集train.csv、验证集dev.csv、测试集test.csv。尤其需要注意的是,应当在每个标签下,按照70:15:15的比例来均分数据集,保证在每个训练集、验证集、测试集中每个类别的标签都有,代码如下:
train, val, test = [], [], []
for i, label in enumerate(df['category']):
if cal[label] < count[label] * 0.7:
train.append('label': label, 'content': contents[i])
elif cal[label] < count[label] * 0.85:
val.append('label': label, 'content': contents[i])
else:
test.append('label': label, 'content': contents[i])
cal[label] += 1
这样,就分配好了每个集中应有的数据,数据格式为'label':… , 'content': …,方便之后转存为csv文件。
然后,我们编写代码,把变量中的数据转存为csv文件:训练集train.csv、验证集dev.csv、测试集test.csv,代码如下:
with open('../@_数据集/TLND/data/train.csv', 'a', newline='', encoding='utf-8') as f:
xieru = csv.DictWriter(f, ['label','content'],delimiter=';')
xieru.writerows(train) # writerows方法是一下子写入多行内容
with open('../@_数据集/TLND/data/dev.csv', 'a', newline='', encoding='utf-8') as f:
xieru = csv.DictWriter(f, ['label','content'],delimiter=';')
xieru.writerows(val) # writerows方法是一下子写入多行内容
with open('../@_数据集/TLND/data/test.csv', 'a', newline='', encoding='utf-8') as f:
xieru = csv.DictWriter(f, ['label','content'],delimiter=';')
xieru.writerows(test) # writerows方法是一下子写入多行内容
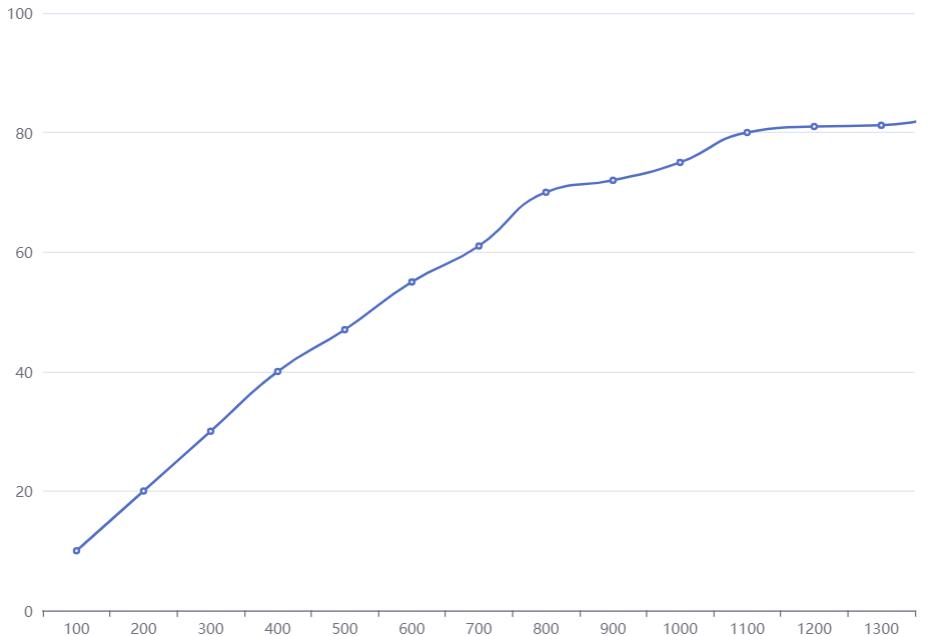
理论上,这样就完成数据集分割的任务了。但是在模型运行过程中,发现模型的准确率图如下。每过一个epoch,准确率总是会先下降许多,然后再上升,如此反复。

网上冲浪一番之后,发现是数据集分割时,把每个类别集中分在一起了,每一类文本应该随机分布,所以需要在转存为csv文件时,先使得变量中的数据随机分布,代码如下:
random.shuffle(train)
random.shuffle(val)
random.shuffle(test)
再跑模型的时候,准确率就呈缓慢上升的趋势了,而不是上升——下降——上升——下降,随机数据分布之后,准确率如下图:
[4] 进行下一篇实战:
以上是关于英文文本分类实战之二——数据集挑选与划分的主要内容,如果未能解决你的问题,请参考以下文章