Day536.Selenium自动化浏览器脚本爬虫 -python
Posted 阿昌喜欢吃黄桃
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Day536.Selenium自动化浏览器脚本爬虫 -python相关的知识,希望对你有一定的参考价值。
Selenium
一、Selenium
1、什么是selenium
(1)Selenium是一个用于
Web应用程序测试的工具。
(2)Selenium 测试直接运行在浏览器中,就像真正的用户在操作一样。
(3)支持通过各种driver(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver)驱动真实浏览器完成测试。
(4)selenium也是支持无界面浏览器操作的。
2、为什么使用selenium
*模拟浏览器功能,自动执行网页中的js代码,实现动态加载 *
3、如何安装selenium
- 操作谷歌浏览器驱动下载地址
- 谷歌驱动和谷歌浏览器版本之间的映射表
- 查看谷歌浏览器版本
谷歌浏览器右上角‐‐>帮助‐‐>关于 - pip install selenium
4、selenium的使用步骤

-
基本使用
from selenium import webdriver # 指定浏览器启动地址 path = 'chromedriver.exe' browser = webdriver.Chrome(path) # 访问网址 url = 'http://www.jd.com' browser.get(url) # page_source获取网页源码数据 context = browser.page_source print(context) -
selenium的元素定位
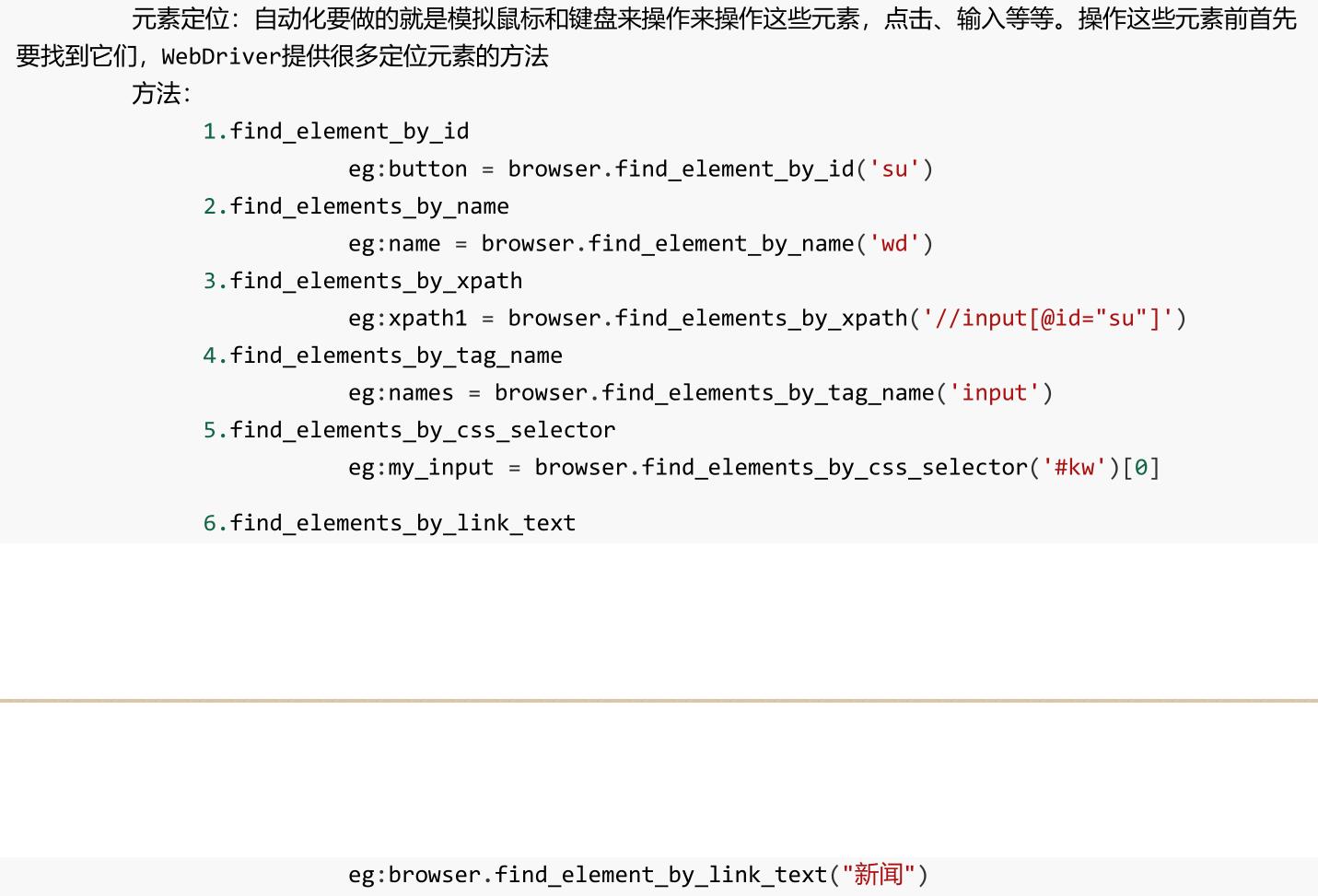
```python
from selenium import webdriver
driver_path = 'chromedriver.exe'
browser = webdriver.Chrome(driver_path)
url = 'http://www.baidu.com'
browser.get(url)
# 元素定位
# button = browser.find_element_by_id('su')
# print(button)
```
- 访问元素信息

from selenium import webdriver
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'http://www.baidu.com'
browser.get(url)
input = browser.find_element_by_id('su')
print(input.get_attribute('class'))
print(input.tag_name)
print(input.text)
- 交互

from selenium import webdriver
import time
path = 'chromedriver.exe'
browser = webdriver.Chrome(path)
url = 'https://www.baidu.com'
browser.get(url)
time.sleep(2)
input = browser.find_element_by_id('kw')
input.send_keys('蝙蝠侠')
time.sleep(2)
button = browser.find_element_by_id('su')
button.click()
time.sleep(2)
js_bottom = 'document.documentElement.scrollTop=100000'
browser.execute_script(js_bottom)
time.sleep(1)
next_button = browser.find_element_by_xpath('//a[@class="n"]')
next_button.click()
time.sleep(1)
browser.back()
time.sleep(2)
browser.forward()
time.sleep(3)
browser.quit()
二、Phantomjs
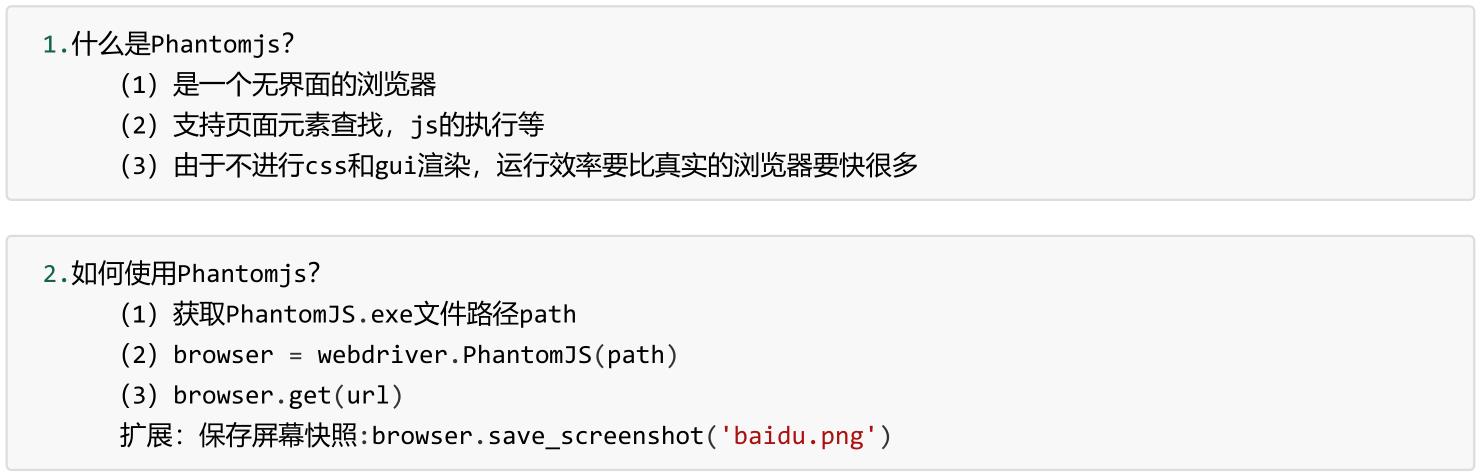
from selenium import webdriver
path = 'phantomjs.exe'
browser = webdriver.PhantomJS(path)
url = 'https://www.baidu.com'
browser.get(url)
# browser.save_screenshot('baidu.jpg')
三、Chrome handless
Chrome-headless 模式, Google 针对 Chrome 浏览器 59版 新增加的一种模式,可以让你不打开UI界面的情况下使用 Chrome 浏览器,所以运行效果与 Chrome 保持完美一致。
- 系统要求

- 基本使用配置
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
chrome_options = Options()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--disable‐gpu')
# 设置为自己chrome浏览器.exe的系统路径
path = r'C:\\Users\\99593\\AppData\\Local\\Google\\Chrome\\Application\\chrome.exe'
chrome_options.binary_location = path
browser = webdriver.Chrome(chrome_options=chrome_options)
browser.get('https://www.baidu.com')
# browser.save_screenshot('baidu.jpg')
以上是关于Day536.Selenium自动化浏览器脚本爬虫 -python的主要内容,如果未能解决你的问题,请参考以下文章