R 笔记 prophet
Posted UQI-LIUWJ
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了R 笔记 prophet相关的知识,希望对你有一定的参考价值。
0 理论部分
论文笔记:Forecasting at Scale(Prophet)_UQI-LIUWJ的博客-CSDN博客
Prophet 是一种基于加法模型预测时间序列数据的程序,其中非线性趋势、季节性以及假日效应相匹配。
它最适用于具有强烈季节性和有几个季节历史数据的时间序列。
Prophet 对缺失数据和趋势变化具有鲁棒性,并且通常可以很好地处理异常值。
1 基本流程
在 R 中,我们使用正常的模型拟合 API。 我们提供了一个执行拟合并返回模型对象的Prophet函数。 然后,您可以在此模型对象上调用 predict 和 plot。
library(prophet)
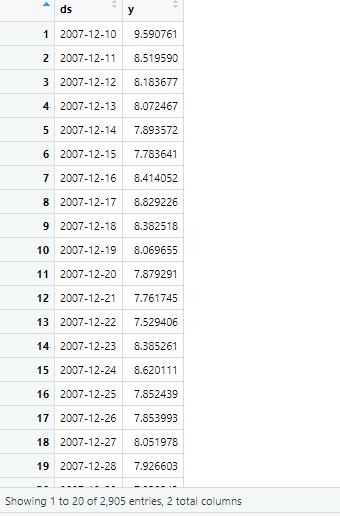
1.1 读入数据
首先,我们读入数据并创建结果变量。 与 Python 中的dataframe一样,这是一个包含 ds 和 y 列的数据框,分别包含日期和数值。
ds 列对于日期应该是 YYYY-MM-DD,对于时刻应该是 YYYY-MM-DD HH:MM:SS。
df<-read.csv('C:/Users/16000/example_wp_log_peyton_manning.csv')
1.2 调用prophet函数
调用prophet函数来拟合模型(对之前部分进行时间序列分解)
m<-prophet(df)
1.3 生成future dataframe
预测是在dataframe上进行的,其中 ds 列包含要进行预测的日期。
make_future_dataframe 函数使用 模型对象和 预测区间长度 进行预测并生成相应的dataframe。
future <- make_future_dataframe(m, periods = 365)默认情况下,它还将包括历史日期,因此我们可以评估样本内拟合。
相比于df,多了365个数据,即预测区间

1.4 获得预测结果
与 R 中的大多数预测任务一样,我们使用通用 predict 函数来获得我们的预测。
forecast <- predict(m, future)预测结果是一个dataframe,其中包含预测的列 yhat。 它具有用于不确定性区间和季节性成分的附加列。
tail(forecast)
ds trend additive_terms
3265 2017-01-14 7.188345 0.6353367
3266 2017-01-15 7.187317 1.0181583
3267 2017-01-16 7.186289 1.3441746
3268 2017-01-17 7.185261 1.1326084
3269 2017-01-18 7.184232 0.9662578
3270 2017-01-19 7.183204 0.9791888
additive_terms_lower additive_terms_upper
3265 0.6353367 0.6353367
3266 1.0181583 1.0181583
3267 1.3441746 1.3441746
3268 1.1326084 1.1326084
3269 0.9662578 0.9662578
3270 0.9791888 0.9791888
weekly weekly_lower weekly_upper yearly
3265 -0.31171456 -0.31171456 -0.31171456 0.9470512
3266 0.04829728 0.04829728 0.04829728 0.9698610
3267 0.35228502 0.35228502 0.35228502 0.9918896
3268 0.11963367 0.11963367 0.11963367 1.0129747
3269 -0.06665548 -0.06665548 -0.06665548 1.0329133
3270 -0.07227149 -0.07227149 -0.07227149 1.0514603
yearly_lower yearly_upper multiplicative_terms
3265 0.9470512 0.9470512 0
3266 0.9698610 0.9698610 0
3267 0.9918896 0.9918896 0
3268 1.0129747 1.0129747 0
3269 1.0329133 1.0329133 0
3270 1.0514603 1.0514603 0
multiplicative_terms_lower
3265 0
3266 0
3267 0
3268 0
3269 0
3270 0
multiplicative_terms_upper yhat_lower yhat_upper
3265 0 7.054971 8.545286
3266 0 7.443115 8.954531
3267 0 7.791419 9.265397
3268 0 7.664162 9.071099
3269 0 7.391583 8.871629
3270 0 7.428541 8.869961
trend_lower trend_upper yhat
3265 6.826222 7.538852 7.823682
3266 6.823645 7.538624 8.205475
3267 6.821068 7.538397 8.530463
3268 6.818564 7.538169 8.317869
3269 6.816108 7.537942 8.150490
3270 6.813651 7.537714 8.162393选择特定列的话,可以
tail(forecast[c('ds', 'yhat', 'yhat_lower', 'yhat_upper')])
ds yhat yhat_lower yhat_upper
3265 2017-01-14 7.823682 7.054971 8.545286
3266 2017-01-15 8.205475 7.443115 8.954531
3267 2017-01-16 8.530463 7.791419 9.265397
3268 2017-01-17 8.317869 7.664162 9.071099
3269 2017-01-18 8.150490 7.391583 8.871629
3270 2017-01-19 8.162393 7.428541 8.8699611.5 绘制图像
1.5.1 plot
可以使用plot函数,通过传入模型和预测数据框来绘制预测。
plot(m, forecast)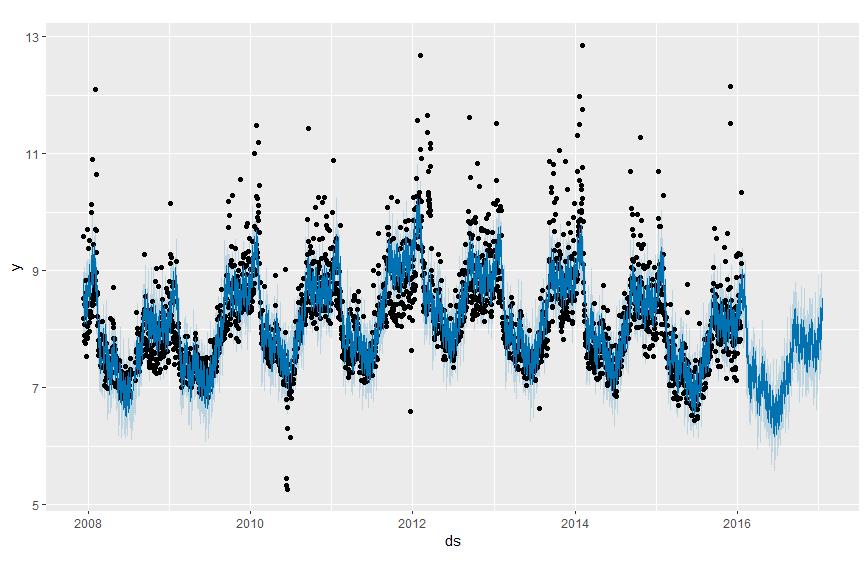
1.5.2 prophet_plot_components函数
prophet_plot_components(m,forecast) 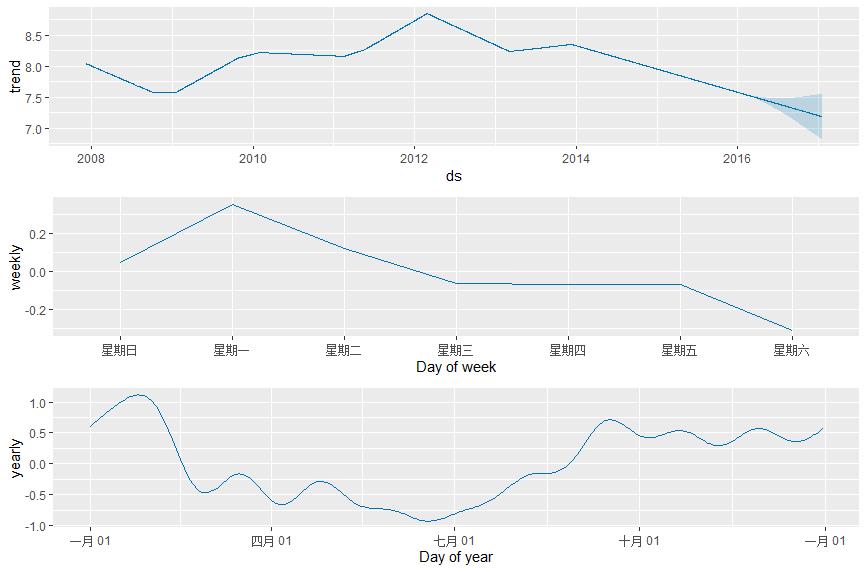
2 趋势为饱和增长模型
大体框架和之间是一样的,有几个小地方有区别
载入包和读入数据是一样的
library(prophet) df<-read.csv('C:/Users/16000/example_wp_log_peyton_manning.csv')
我们这里要给数据集增加一列:承载能力C
论文笔记:Forecasting at Scale(Prophet)_UQI-LIUWJ的博客-CSDN博客
df['cap']=8
调用prophet的时候,需要声明饱和增长模型
m<-prophet(df,growth='logistic')
生成future_dataframe的时候,也需要增加承载能力这一列
future<-make_future_dataframe(m,period=365) future['cap']=8
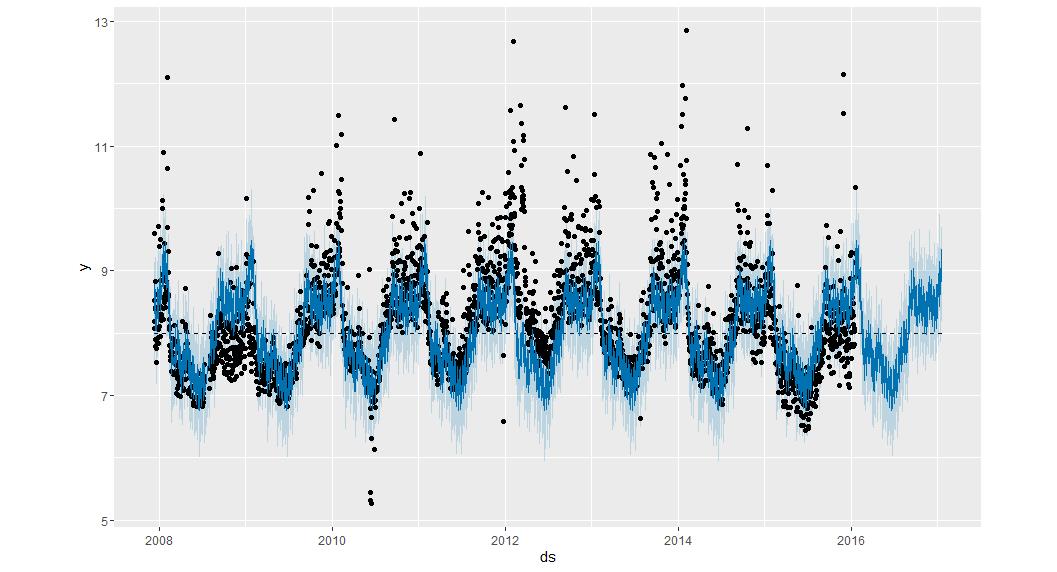
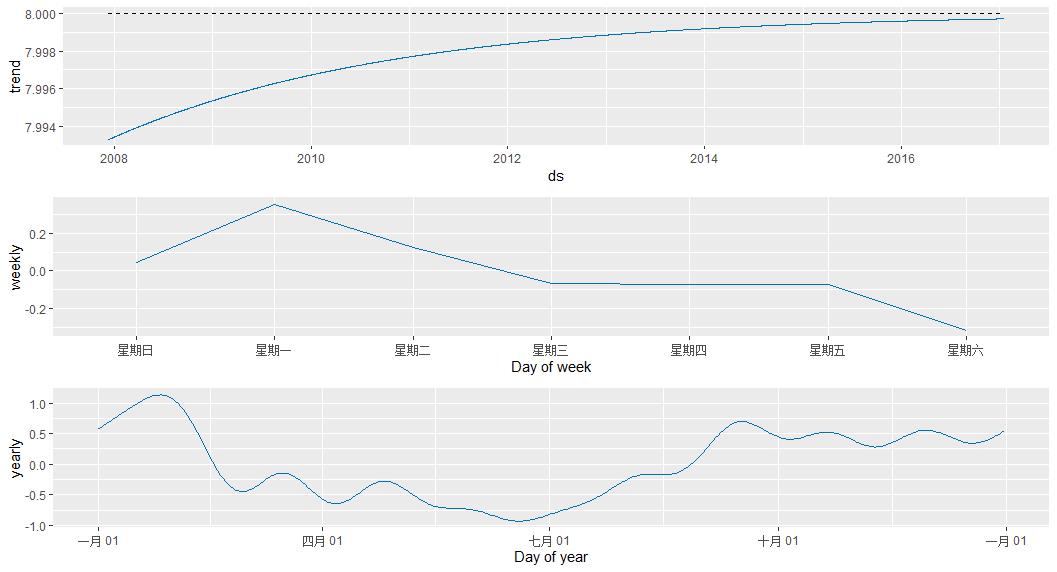
之后的预测和画图是一样的
f<-predict(m,future) plot(m,f) prophet_plot_components(m,f)
2.1 设置承载能力下限
除了cap之外,我们还可以设置承载能力的下限:使用floor即可
df['floor']=6
future['floor']=63 趋势的变化点
默认情况下,Prophet 会自动检测趋势变化点,并允许趋势进行适当的调整。 但是,如果您希望更好地控制此过程(例如,Prophet 错过了速率变化,或者在历史中过拟合速率变化),那么可以使用如下几个输入参数
3.1 prophet中变化点的自动检测
Prophet 通过首先指定大量潜在趋势变化点来检测变化点。 然后它对速率变化的幅度进行稀疏先验(相当于 L1 正则化)——这实质上意味着 Prophet 有大量可能的地方可以改变速率,但会尽可能少地使用它们。
以下图为例。 默认情况下,Prophet 指定了 25 个潜在的变化点,它们均匀地放置在时间序列的前 80% 中。 此图中的垂直线表示放置潜在变化点的位置:
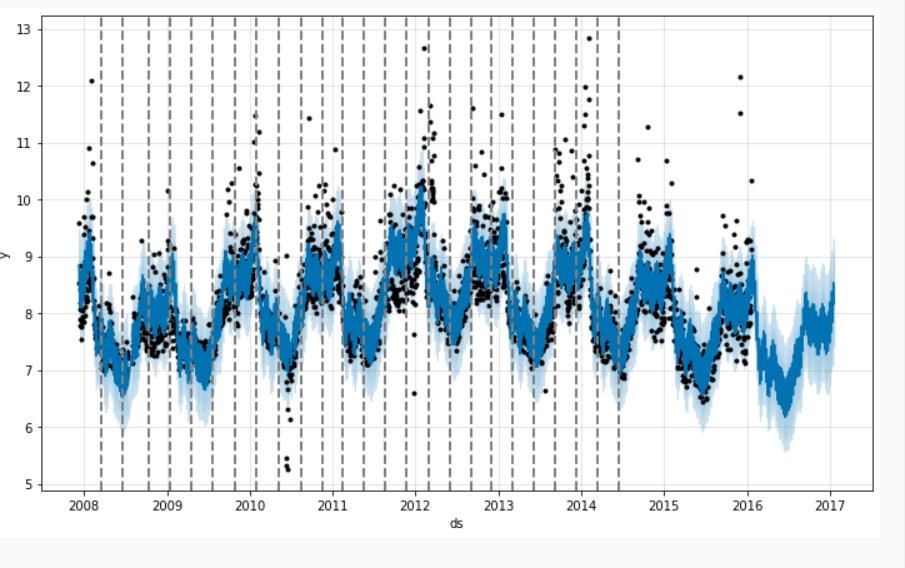
尽管我们有很多地方可能会更改趋势,但由于先验稀疏,这些更改点中的大多数都未使用。 我们可以通过绘制每个变化点的速率变化幅度来看到这一点:
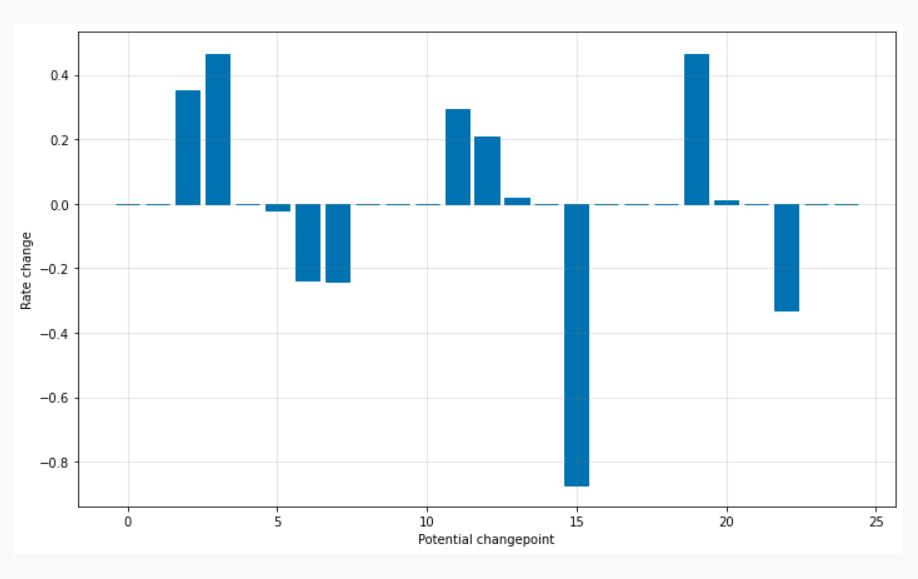
显著变化点的位置可以通过以下方式可视化:(这里是线性趋势的prophet)
plot(m,forecast)+add_changepoints_to_plot(m)

默认情况下,仅为时间序列的前 80% 推断变化点,以便有足够的时间片段来预测未来趋势并避免在时间序列结束时过拟合波动。
此默认值适用于许多情况,但不是全部。可以使用 changepoint_range 参数进行更改。
m <- prophet(changepoint.range = 0.9)
3.2 调整趋势变动的灵活性
如果趋势变化过拟合(灵活性太大)或欠拟合(灵活性不够),可以使用输入参数 changepoint_prior_scale 调整稀疏先验的强度。
默认情况下,此参数设置为 0.05
增加它将使趋势更加灵活
m <- prophet(df, changepoint.prior.scale = 0.5)
可以发现,相比于上一个情况,这里变化点变多了,同时幅度也变大了

减少之将会变得不灵活
m <- prophet(df, changepoint.prior.scale = 0.001)
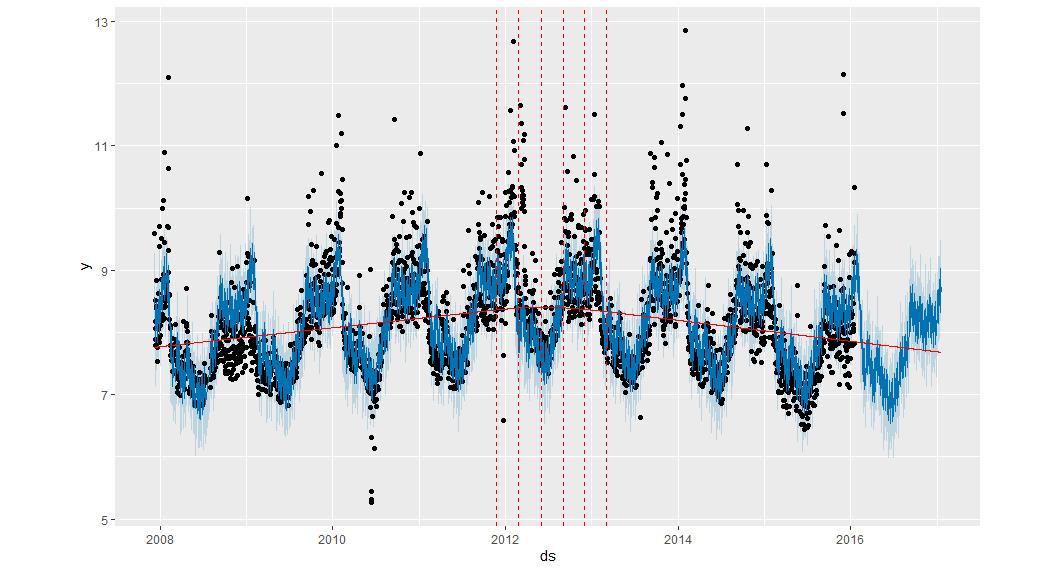
3.3 手动指定变更点的位置
可以使用 changepoints 参数手动指定潜在变更点的位置,而不是使用自动变更点检测。 然后将只允许在这些点处更改斜率,并使用与以前相同的稀疏正则化。
m <- prophet(df,changepoints = c('2014-01-01','2010-02-03')) 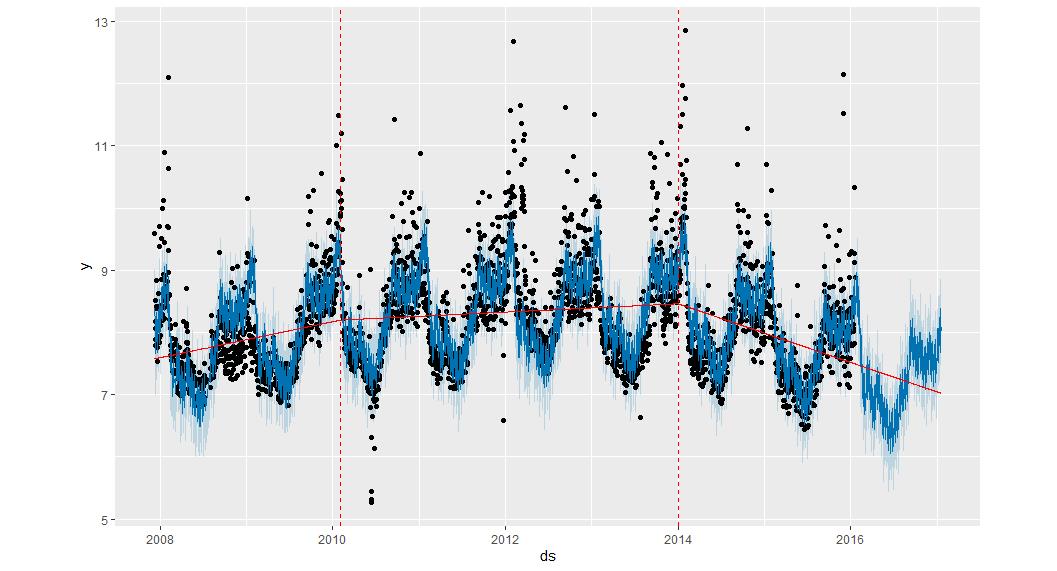
4 节假日
4.1 手动提供节假日
如果您有想要建模的假期或其他特殊事件,则必须为它们创建一个数据框。 它有两列(holiday 和 ds),每出现一个节假日就有一行。
必须包括假期的所有事件,包括过去(就历史数据而言)和未来(就预测而言)。
如果它们将来不会重复,Prophet 将对它们进行建模,然后不将它们包括在预测中。
还可以包含列 lower_window 和 upper_window ,它们将假期延长到日期前后的 [lower_window, upper_window] 天。
library(dplyr) playoffs <- data_frame( holiday = 'playoff', ds = as.Date(c('2008-01-13', '2009-01-03', '2010-01-16', '2010-01-24', '2010-02-07', '2011-01-08', '2013-01-12', '2014-01-12', '2014-01-19', '2014-02-02', '2015-01-11', '2016-01-17', '2016-01-24', '2016-02-07')), lower_window = 0, upper_window = 1 ) #假期延长到日期后的一天 superbowls <- data_frame( holiday = 'superbowl', ds = as.Date(c('2010-02-07', '2014-02-02', '2016-02-07')), lower_window = 1, upper_window = 0 ) #假期延长到日期前的一天 holidays <- bind_rows(playoffs, superbowls)
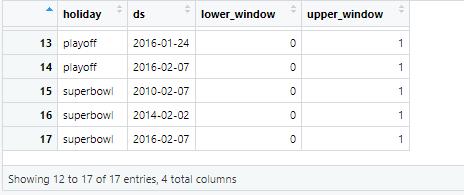
创建holiday表后,通过使用holidays 参数将假期影响包含在预测中。
m <- prophet(df,holidays = holidays) forecast <- predict(m, future) prophet_plot_components(m,forecast)
相比于之前,这边多出了holiday 的影响
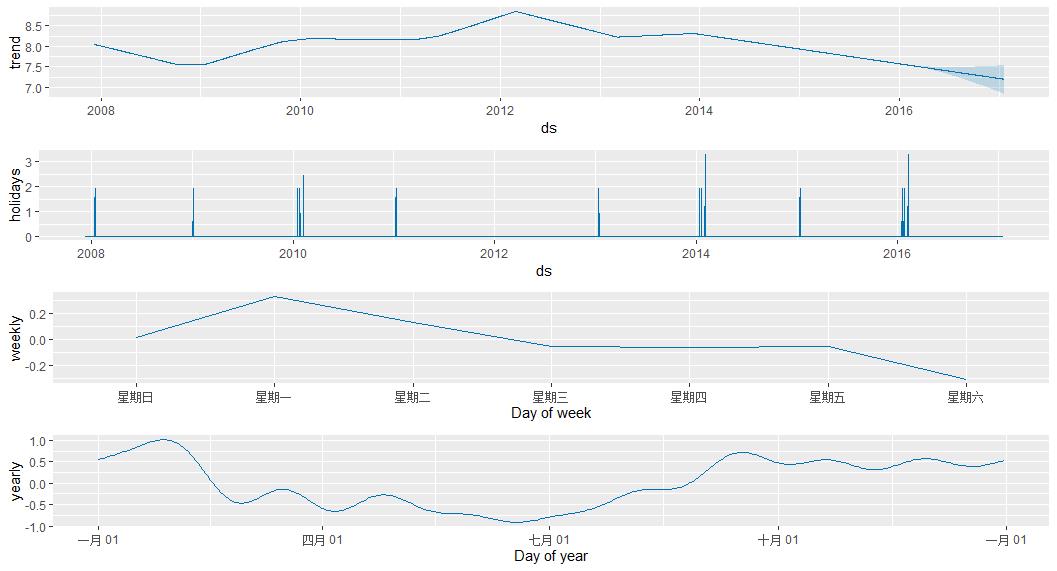
可以用一种类似于sql的方式 查看 holiday的影响
forecast %>% select(ds, playoff, superbowl) %>% filter(abs(playoff + superbowl) > 0) ds playoff superbowl 1 2008-01-13 1.220577 0.000000 2 2008-01-14 1.909146 0.000000 3 2009-01-03 1.220577 0.000000 4 2009-01-04 1.909146 0.000000 5 2010-01-16 1.220577 0.000000 6 2010-01-17 1.909146 0.000000 7 2010-01-25 1.909146 0.000000 8 2010-02-07 1.220577 1.215571 9 2011-01-08 1.220577 0.000000 10 2011-01-09 1.909146 0.000000 11 2013-01-12 1.220577 0.000000 12 2013-01-13 1.909146 0.000000 13 2014-01-12 1.220577 0.000000 14 2014-01-13 1.909146 0.000000 15 2014-01-19 1.220577 0.000000 16 2014-01-20 1.909146 0.000000 17 2014-02-02 1.220577 1.215571 18 2014-02-03 1.909146 1.384333 19 2015-01-11 1.220577 0.000000 20 2015-01-12 1.909146 0.000000 21 2016-01-17 1.220577 0.000000 22 2016-01-18 1.909146 0.000000 23 2016-01-24 1.220577 0.000000 24 2016-01-25 1.909146 0.000000 25 2016-02-07 1.220577 1.215571 26 2016-02-08 1.909146 1.384333
4.2 提供国家节假日
您可以使用 add_country_holidays 方法使用内置的特定国家/地区假期集合。
指定国家/地区的名称,然后除了通过4.1指定的任何假期外,还将包括该国家/地区的主要假期:
但是这里有一点需要说明,在add_country_holidays之前,不能fit model,比如下述代码,就会报错
m <- prophet(df,holidays = holidays) m<-add_country_holidays(m,'US') #Error in add_country_holidays(m, "China") : # Country holidays must be added prior to model fitting.
m <- prophet(holidays = holidays)
m<-add_country_holidays(m,'CN')
m<-fit.prophet(m,df)
forecast <- predict(m, future)
prophet_plot_components(m,forecast)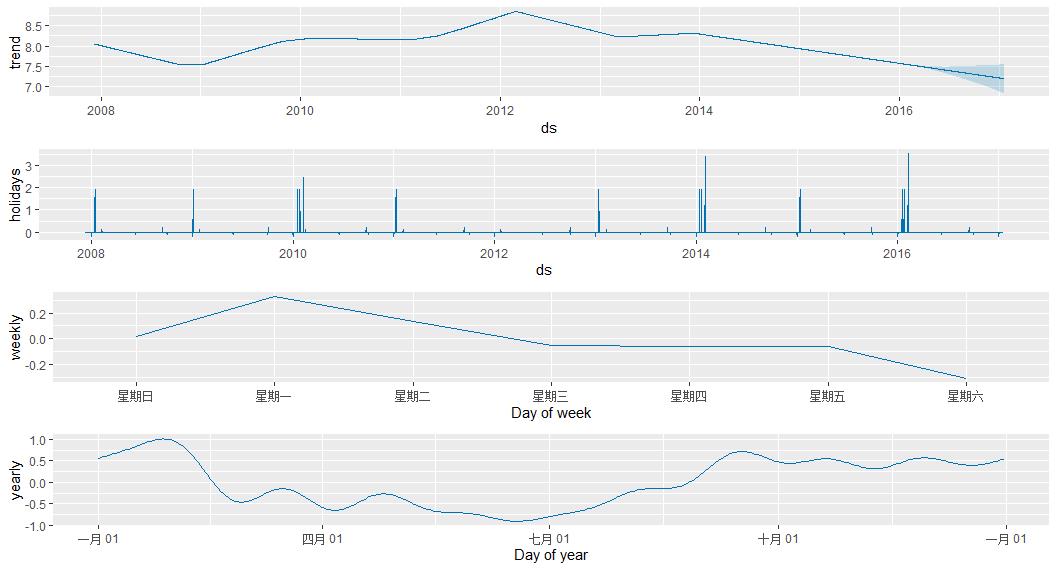
4.2.1 查看目前设置的节假日
加observed表示只有在观察集里面有
m$train.holiday.names
[1] "playoff" "superbowl" "New Year's Day" "Chinese New Year"
[5] "Tomb-Sweeping Day" "Labor Day" "Dragon Boat Festival" "Mid-Autumn Festival"
[9] "National Day" 4.2.2 可以提供的国家假日
可用国家/地区列表和要使用的国家/地区名称可在其页面上找到:https://github.com/dr-prodigy/python-holidays。
除了这些国家/地区,Prophet 还包括以下国家/地区的假期:巴西 (BR)、印度尼西亚 (ID)、印度 (IN)、马来西亚 (MY)、越南 (VN)、泰国 (TH)、菲律宾 (PH)、巴基斯坦 ( PK)、孟加拉国 (BD)、埃及 (EG)、中国 (CN)、俄罗斯 (RU)、韩国 (KR)、白俄罗斯 (BY) 和阿拉伯联合酋长国 (AE)。
在 R 中,假日日期是从 1995 年到 2044 年计算的,并作为 data-raw/generated_holidays.csv 存储在包中。
4.3 节假日尺度
如果您发现假期过拟合,您可以使用参数holiday_prior_scale 调整其先验比例以使其平滑。
默认情况下,此参数为 10,它提供的正则化非常少。 减少这个参数会减弱假日效应,增大则会强调节假日的作用:
m <- prophet(df, holidays = holidays, holidays.prior.scale = 1000)5 季节性
5.1 季节性的傅里叶级数
使用部分傅里叶级数和来估计季节性
部分总和(顺序)中的项数是决定季节性变化速度的参数。
年度季节性的默认傅里叶顺序为 10
m <- prophet(df) prophet:::plot_yearly(m)

默认值通常是合适的,但是当季节性需要适应更高频率的变化时可以增加它们,并且通常不太平滑。 在实例化模型时,可以为每个内置的季节性指定傅里叶阶数,这里增加到 20:
增加傅立叶项的数量可以使季节性适应更快的变化周期,但也可能导致过度拟合:N 个傅立叶项对应于用于对周期进行建模的 2N 个变量
m <- prophet(df, yearly.seasonality = 20) prophet:::plot_yearly(m)

5.2 指定自定义季节性
如果时间序列的长度超过两个周期,Prophet 将默认拟合每周和每年的季节性。
可以使用 add_seasonality 方法、添加其他季节性(每月、每季度、每小时)。
此函数的输入是名称、季节性周期(以天为单位)以及季节性的傅里叶阶。 作为参考,Prophet 默认使用3阶 傅里叶阶数 表示每周季节性,10 表示年度季节性。
这里和add_country_holidays一样,不能先拟合
m<-prophet()
m<-add_seasonality(m, name='monthly', period=30.5, fourier.order=5)
m<-fit.prophet(m,df)
forecast <- predict(m, future)
prophet_plot_components(m, forecast) 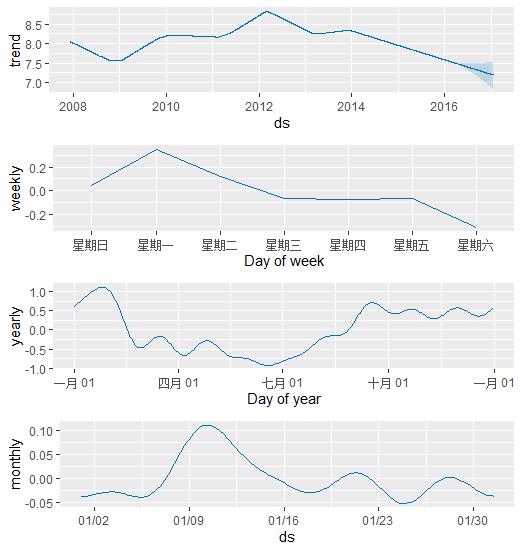
5.3 取消某一个的季节性
m<-prophet(df,weekly.seasonality = FALSE)
forecast <- predict(m, future)
prophet_plot_components(m, forecast)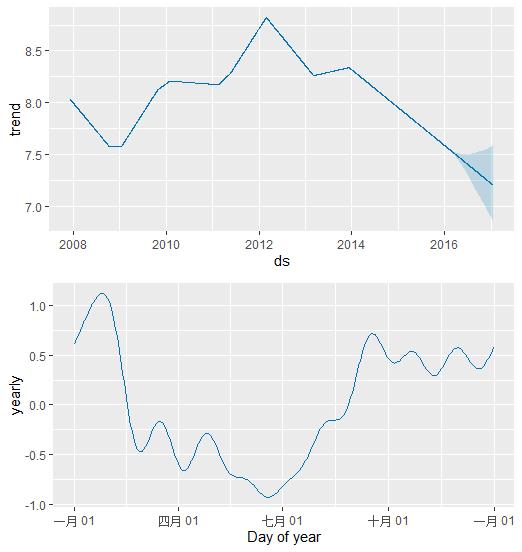
5.4 取决于其他因素的季节性
在某些情况下,季节性可能取决于其他因素,例如夏季与一年中其他时间不同的每周季节性模式,或周末与工作日不同的每日季节性模式。 这些类型的季节性可以使用条件季节性进行建模。
默认的每周季节性假设全年每周季节性的模式是相同的,但我们预计每周季节性的模式在旺季、和淡季是不同的。 我们可以使用条件季节性来构建单独的旺季和淡季每周季节性。
首先,我们在数据框中添加一个布尔列,指示每个日期是在旺季还是淡季:
is_nfl_season <- function(ds) dates <- as.Date(ds) # 每一个元素类似于"2016-01-15" month <- as.numeric(format(dates, '%m')) # format(dates, '%m')返回字符类型的月份 # as.numeric转换成数字 return(month > 8 | month < 2) #声明一个函数,如果在8月后,两月前,那就是True,否则是Falsedf$on_season <- is_nfl_season(df$ds) df$off_season <- !is_nfl_season(df$ds)

然后我们禁用内置的每周季节性,并将其替换为两个将这些列指定为条件的每周季节性。
这意味着季节性仅适用于 condition_name 列为 True 的日期。
我们还必须将该列添加到我们正在对其进行预测的未来数据帧中。
m <- prophet(weekly.seasonality=FALSE) m <- add_seasonality(m, name='weekly_on_season', period=7, fourier.order=3, condition.name='on_season') m <- add_seasonality(m, name='weekly_off_season', period=7, fourier.order=3, condition.name='off_season') m <- fit.prophet(m, df) future$on_season <- is_nfl_season(future$ds) future$off_season <- !is_nfl_season(future$ds) forecast <- predict(m, future) prophet_plot_components(m, forecast)

现在,这两种季节性都显示在上面的分量图中。 我们可以看到,旺季期间,周日和周一都有大幅增加,而在淡季则完全没有。
5.5 指定季节性尺度
和节假日一样,季节性也有一个尺度 seasonality_prior_scale
m <- add_seasonality(
m,
name='weekly',
period=7,
fourier.order=3,
prior.scale=0.1)
6 乘法季节性
默认情况下,Prophet 拟合加法季节性,这意味着将季节性的影响添加到趋势中以获得预测
我们看一种情况,如下图所示,这个时间序列有一个明显的年周期,但是预测的季节性在时间序列开始时太大而结束时太小。 在这个时间序列中,季节性并不是 Prophet 假设的恒定加法因子,而是随趋势增长。 这是乘法季节性。

Prophet 可以通过在输入参数中设置seasonality_mode='multiplicative'来拟合乘法季节性:
m <- prophet(df, seasonality.mode = 'multiplicative')使用seasonality_mode='multiplicative',假日效应也将被建模为乘法。
默认情况下,任何添加的季节性将设置为seasonality_mode,但可以通过在添加季节性时指定 mode='additive' 或 mode='multiplicative' 作为参数来覆盖
m <- prophet(seasonality.mode = 'multiplicative') m <- add_seasonality(m, 'quarterly', period = 91.25, fourier.order = 8, mode = 'additive')
7 不确定区间
默认情况下,Prophet 将返回预测 yhat 的不确定区间。
预测中存在三个不确定性区间:趋势的不确定性、季节性估计的不确定性和额外的观测噪声。
7.1 趋势的不确定性
预测中最大的不确定性来源是未来趋势变化的可能性。我们假设未来会看到与历史相似的趋势变化。 特别是,我们假设未来趋势变化的平均频率和幅度将与我们在历史上观察到的相同。 我们向前预测这些趋势变化,并通过计算它们的分布,我们获得不确定区间。
这种测量不确定性的方式的一个特性是,通过增加 changepoint_prior_scale 来允许预测具有更大的可取区间,增加预测的不确定性。
可以使用参数 interval_width 设置不确定区间的宽度(默认为 80%):
m <- prophet(df, interval.width = 0.95)
forecast <- predict(m, future)
plot(m,forecast)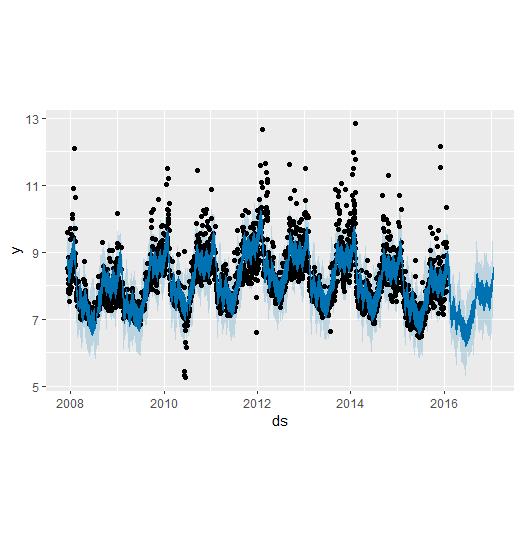
相比于之前,不确定区间更大了
7.2 季节性的不确定性
默认情况下,Prophet 只会返回趋势和观察噪声的不确定性。 要获得季节性的不确定性,必须进行完整的贝叶斯抽样。 这是使用参数 mcmc.samples(默认为 0)完成的。
m <- prophet(df, mcmc.samples = 300)
forecast <- predict(m, future)这用 MCMC 采样代替了典型的 MAP 估计,并且可能需要更长的时间,具体取决于有多少观察 - 预计几分钟而不是几秒钟。
当绘制季节性分量时,就会看到它们的不确定性:
prophet_plot_components(m,forecast)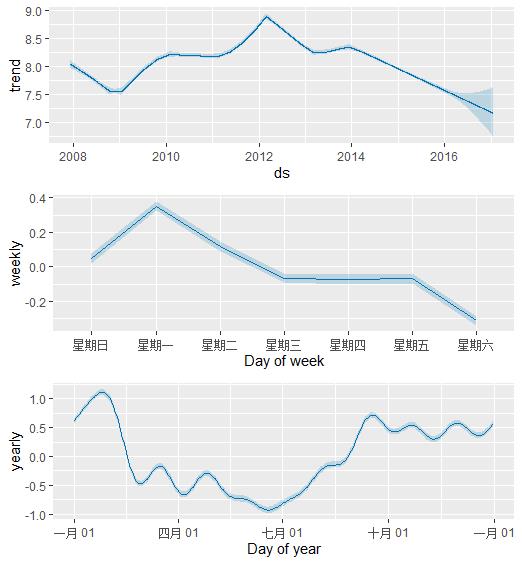
8 异常值
异常值可以通过两种主要方式影响 Prophet 的预测。 在这里,我们对之前记录的对 R 页面的 Wikipedia 访问进行了预测,但有一个坏数据块:
df<-read.csv('C:/Users/16000/example_wp_log_R_outliers1.csv')
m <- prophet(df)
future <- make_future_dataframe(m, periods = 1096)
forecast <- predict(m, future)
plot(m, forecast) 
趋势预测似乎合理,但不确定性区间似乎太宽了。 Prophet 能够处理历史中的异常值,但只能通过将它们与趋势变化相匹配。 然后,不确定性模型预计类似幅度的未来趋势变化。
处理异常值的最佳方法是删除它们——Prophet 对丢失数据没有任何问题。 如果您在历史记录中将它们的值设置为 NA 但将日期保留在未来,那么 Prophet 将为您提供对它们值的预测。
outliers <- (as.Date(df$ds) > as.Date('2010-01-01')
& as.Date(df$ds) < as.Date('2011-01-01'))
df$y[outliers] = NA
m <- prophet(df)
forecast <- predict(m, future)
plot(m, forecast)
去掉异常值后,趋势还是之前没去掉异常值时差不多的趋势,但是不确定区间小了很多
9 非每日数据
Prophet 可以通过在 ds 列中传入带有时间戳的数据框来对非每日数据的时间序列进行预测。 时间戳的格式应为 YYYY-MM-DD HH:MM:SS 。

在这里,我们将 Prophet 拟合到 5 分钟为频率的数据:
df<-read.csv('C:/Users/16000/example_yosemite_temps.csv')
m <- prophet(df)
future <- make_future_dataframe(m, periods = 300, freq = 60 * 60)
#第一个60表示几分钟,第二个60表示秒 (乘积表示预测区间每两个之间间隔多少秒)
fcst <- predict(m, future)
plot(m, fcst)
(freq=这里也可以是字符串比如“month”这种)
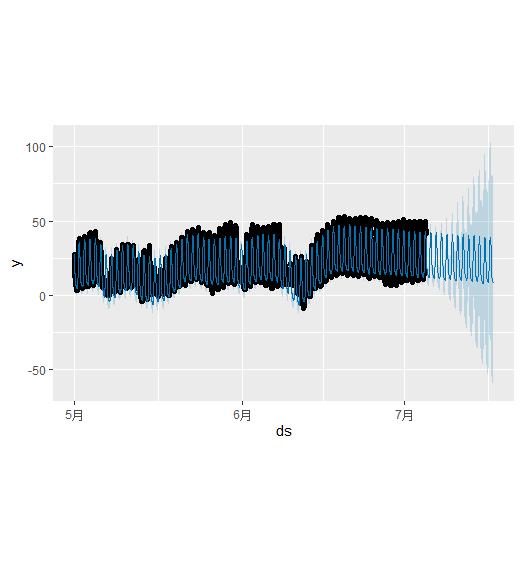
此时我们画出时间序列分解之后的图,daily seasonality已经被成了不同时刻的季节性了
prophet_plot_components(m,fcst)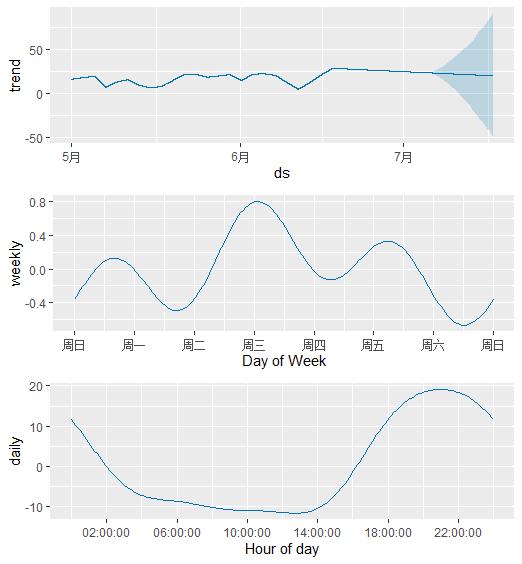
以上是关于R 笔记 prophet的主要内容,如果未能解决你的问题,请参考以下文章
时间序列预测初探:Kats,SARIMA,Prophet,deepAR 等
时间序列预测初探:Kats,SARIMA,Prophet,deepAR 等