Python 可视化近 90 天的百度搜索指数 + 词云图
Posted AI科技大本营
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Python 可视化近 90 天的百度搜索指数 + 词云图相关的知识,希望对你有一定的参考价值。

作者 | 叶庭云
来源 | AI庭云君
一、简介
在实际业务中我们可能会使用爬虫根据关键词获取百度搜索指数历史数据,然后进行对应的数据分析。
百度指数,体验大数据之美。但要获取百度指数相关的数据,困难如下:
不是静态网页,并且百度指数的 URL 请求地址返回的数据,不能直接利用 json 解析提取的数据,而是加密之后的数据和uniqid,需要通过 uniqid 再次请求对应的 URL 以获取用于解密的密钥,然后在前端页面进行解密,然后再渲染到折线图中。
必须要在百度指数页面登录百度账号(获取Cookie)。
需要将前端解密代码转化为 Python 后端代码,或者直接利用 execjs 直接执行 javascript 代码也可以。
本文以获取关键词(北京冬奥会、冬奥会开幕式):近 天的百度搜索指数数据为例,讲解利用 爬虫根据关键词获取百度搜索指数历史数据的过程(以冬奥会为例),然后对冬奥会近 90 天的搜索指数可视化,以及采集媒体报道的材料做词云图。
环境:Anaconda + Pycharm
主要用到的库:requests、execjs、datetime、pandas、matplotlib、stylecloud
二、网页分析
没有百度账号的话需要先注册,然后进入百度指数官网:
https://www.baidu.com/s?wd=百度指数

搜索冬奥会,选择近 90 天,即可看到近 90 天冬奥会搜索指数的折线图:
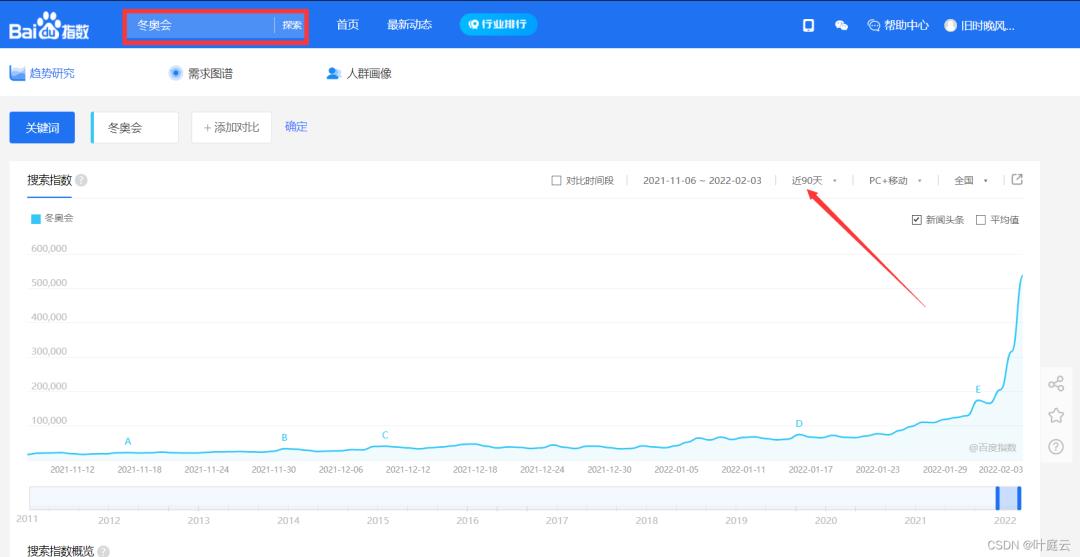
最终要做的就是获取这些搜索指数数据,保存到本地Excel。
首先要获取你登录之后的Cookie(必须要有,否则无法获取到数据),具体的 Cookie 获取如下图:
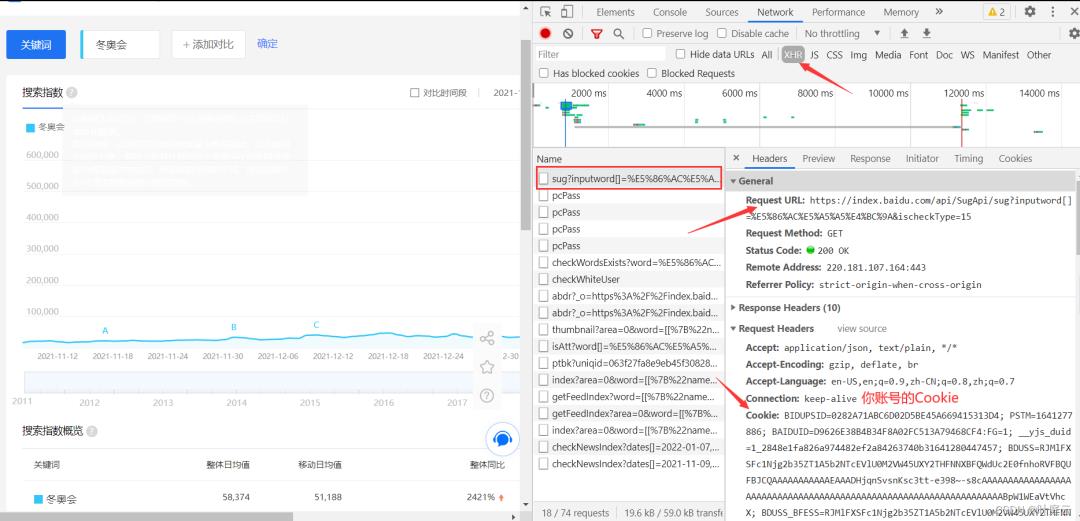
分析可以找到 json 数据的接口,如下所示:

Request URL 里,word参数后是搜索的关键词(只是汉字被编码了),days=90,代表近 90 天的数据,从当前日期的前一天往前推一个月,可以根据需要修改 days 获取更多的数据或者更少的数据。将 Request URL 贴到浏览器中访问查看(查看 JSON 数据网页,这时有个 JSON Handle 这样的插件会很方便)
https://index.baidu.com/api/SearchApi/index?area=0&word[[%7B%22name%22:%22%E5%86%AC%E5%A5%A5%E4%BC%9A%22,%22wordType%22:1%7D]]&days=90

可以看到以下数据:
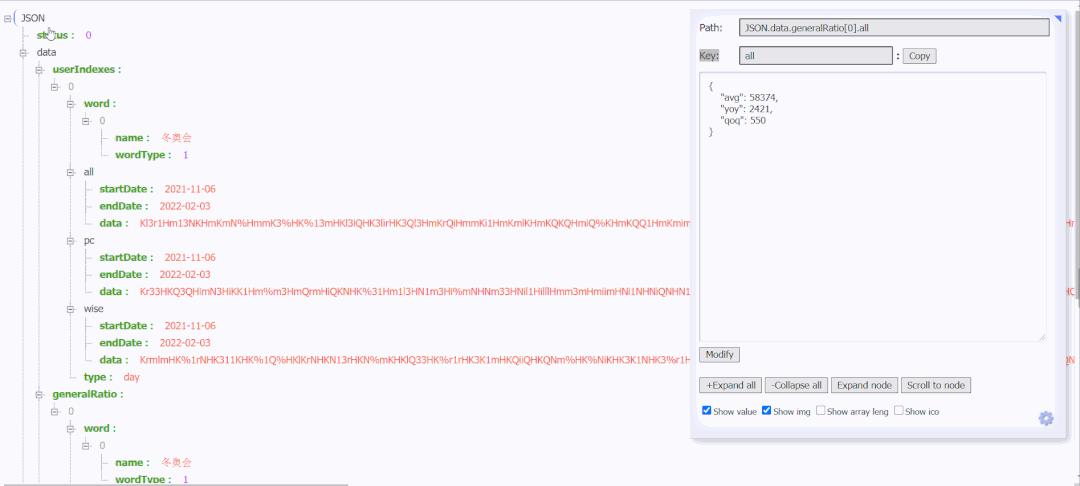
经过对 all,pc,wise 对应的数据进行解密,和搜索指数的折线图显示的数据对比,发现 all 部分的数据就是搜索指数的数据。本次请求返回的数据都在这里了,还可以看到uniqid,而且每次刷新加密的数据和 uniqid 都会变。
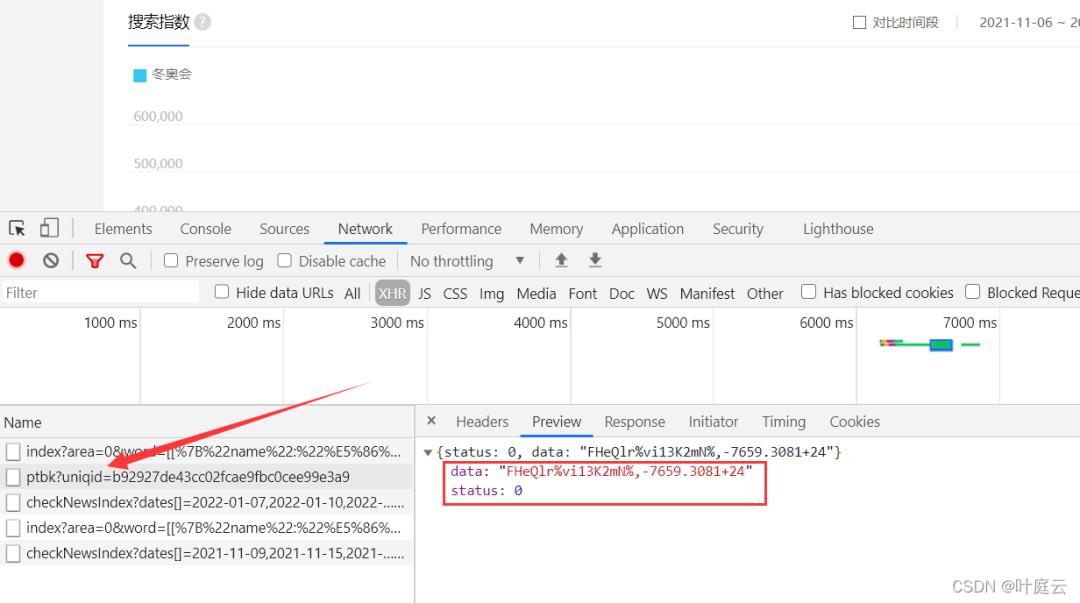
经过多次分析,发现请求数据的 url 下面的 uniqid 出现在了这个 url 中,如上所示。
因此需要先对请求数据对应的 url 进行数据获取,解析出搜索指数对应的加密数据和uniqid,然后拼接 url 获取密钥,最后调用解密方法解密即可获取到搜索指数的数据。
https://index.baidu.com/Interface/ptbk?uniqid=b92927de43cc02fcae9fbc0cee99e3a9找到了对应的url,爬虫基本思路还是那样:发送请求、获取响应、解析数据、然后对数据进行解密、保存数据。
三、数据获取
Python代码:
# -*- coding: UTF-8 -*-
"""
@Author :叶庭云
@公众号 :AI庭云君
@CSDN :https://yetingyun.blog.csdn.net/
"""
import execjs
import requests
import datetime
import pandas as pd
from colorama import Fore, init
init()
# 搜索指数数据解密的Python代码
def decryption(keys, data):
dec_dict =
for j in range(len(keys) // 2):
dec_dict[keys[j]] = keys[len(keys) // 2 + j]
dec_data = ''
for k in range(len(data)):
dec_data += dec_dict[data[k]]
return dec_data
if __name__ == "__main__":
# 北京冬奥会 冬奥会开幕式
keyword = '北京冬奥会' # 百度搜索收录的关键词
period = 90 # 时间 近90天
start_str = 'https://index.baidu.com/api/SearchApi/index?area=0&word=[[%7B%22name%22:%22'
end_str = '%22,%22wordType%22:1%7D]]&days='.format(period)
dataUrl = start_str + keyword + end_str
keyUrl = 'https://index.baidu.com/Interface/ptbk?uniqid='
# 请求头
header =
'Accept': 'application/json, text/plain, */*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Connection': 'keep-alive',
'Cookie': '注意:换成你的Cookie',
'Host': 'index.baidu.com',
'Referer': 'https://index.baidu.com/v2/main/index.html',
'sec-ch-ua': '" Not;A Brand";v="99", "Google Chrome";v="91", "Chromium";v="91"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.77 Safari/537.36'
# 设置请求超时时间为16秒
resData = requests.get(dataUrl,
timeout=16, headers=header)
uniqid = resData.json()['data']['uniqid']
print(Fore.RED + "uniqid:".format(uniqid))
keyData = requests.get(keyUrl + uniqid,
timeout=16, headers=header)
keyData.raise_for_status()
keyData.encoding = resData.apparent_encoding
# 解析json数据
startDate = resData.json()['data']['userIndexes'][0]['all']['startDate']
print(Fore.RED + "startDate:".format(startDate))
endDate = resData.json()['data']['userIndexes'][0]['all']['endDate']
print(Fore.RED + "endDate:".format(endDate))
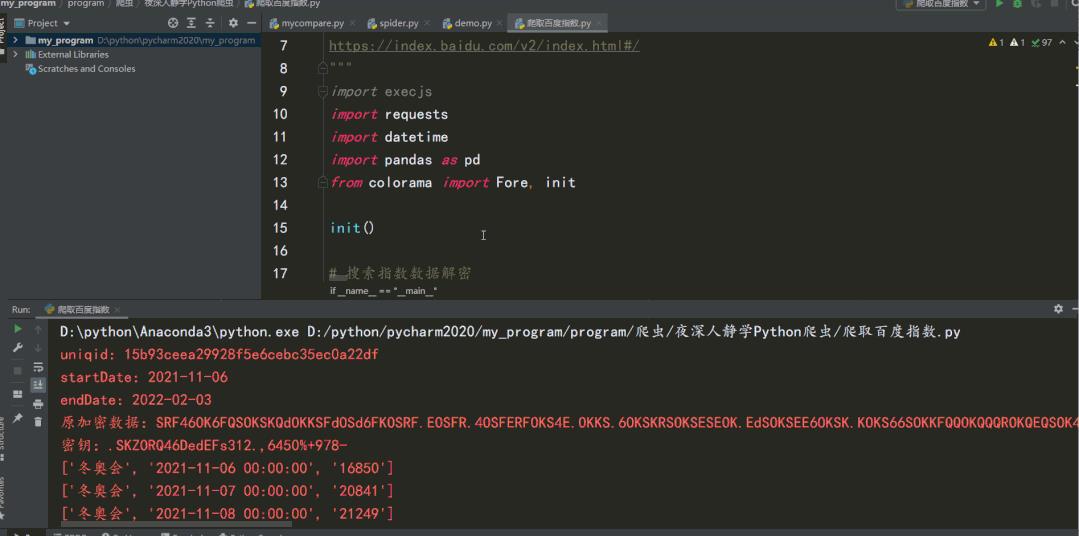
source = (resData.json()['data']['userIndexes'][0]['all']['data']) # 原加密数据
print(Fore.RED + "原加密数据:".format(source))
key = keyData.json()['data'] # 密钥
print(Fore.RED + "密钥:".format(key))
res = decryption(key, source)
# print(type(res))
resArr = res.split(",")
# 生成datetime
dateStart = datetime.datetime.strptime(startDate, '%Y-%m-%d')
dateEnd = datetime.datetime.strptime(endDate, '%Y-%m-%d')
dataLs = []
# 起始日期到结束日期每一天
while dateStart <= dateEnd:
dataLs.append(str(dateStart))
dateStart += datetime.timedelta(days=1)
# print(dateStart.strftime('%Y-%m-%d'))
ls = []
# 组织数据和遍历打印查看
for i in range(len(dataLs)):
ls.append([keyword, dataLs[i], resArr[i]])
for i in range(len(ls)):
print(Fore.RED + str(ls[i]))
# 保存数据到Excel 设置列名
df = pd.DataFrame(ls)
df.columns = ["关键词", "日期", "百度搜索指数"]
df.to_excel("北京冬奥会搜索指数数据 90天.xlsx", index=False)结果如下:
解密部分也可以直接利用 execjs 执行 JavaScript 代码实现,如下所示:
# Python的强大之处就在于,拥有很强大的第三方库,可以直接执行js代码,即对解密算法不熟悉,你无法写Python代码时,直接执行js代码即可
js = execjs.compile('''
function decryption(t, e)
for(var a=t.split(""),i=e.split(""),n=,s=[],o=0;o<a.length/2;o++)
n[a[o]]=a[a.length/2+o]
for(var r=0;r<e.length;r++)
s.push(n[i[r]])
return s.join("")
''')
res = js.call('decryption', key, source) # 调用此方式解密
res = decryption(key, source)Python爬虫成功运行,数据保存为冬奥会搜索指数数据 90 天.xlsx。
四、搜索指数可视化
import numpy as np
import pandas as pd
import matplotlib as mpl
import matplotlib.pyplot as plt
import math
import warnings
warnings.filterwarnings("ignore")
df1 = pd.read_excel("冬奥会开幕式搜索指数数据 90天.xlsx")
df2 = pd.read_excel("北京冬奥会搜索指数数据 90天.xlsx")
mpl.rcParams['font.family'] = 'SimHei'
# 生成x轴数据 列表推导式
# x_data = [i for i in range(1, len(df1) + 1)]
x_data = [i for i in range(1, len(df1) - 1)]
y_data1 = df1["百度搜索指数"][:-2]
y_data2 = df2["百度搜索指数"][:-2]
# 设置figure大小 像素
fig, ax = plt.subplots(figsize=(6, 4), dpi=500)
# 绘制三条折线 点的形状 颜色 标签:用于图例显示
plt.plot(x_data, y_data1,
color="#FF1493", label="冬奥会开幕式")
plt.plot(x_data, y_data2,
color="#00BFFF", label="北京冬奥会")
# x y 轴标签 字体大小
plt.xlabel("时间顺序",
fontdict="size": 15, "weight": "bold", "color": "black")
plt.ylabel("百度搜索指数",
fontdict="size": 15, "weight": "bold", "color": "black"
)
# 设置坐标轴刻度标签的大小
plt.tick_params(axis='x', direction='out',
labelsize=12, length=4.6)
plt.tick_params(axis='y', direction='out',
labelsize=12, length=4.6)
# 显示图例
plt.legend(fontsize=15, frameon=False)
labels = ax.get_xticklabels() + ax.get_yticklabels()
[label.set_fontname('Times New Roman') for label in labels]
[label.set_color('black') for label in labels]
plt.grid(alpha=0.7, ls=":")
# 展示show
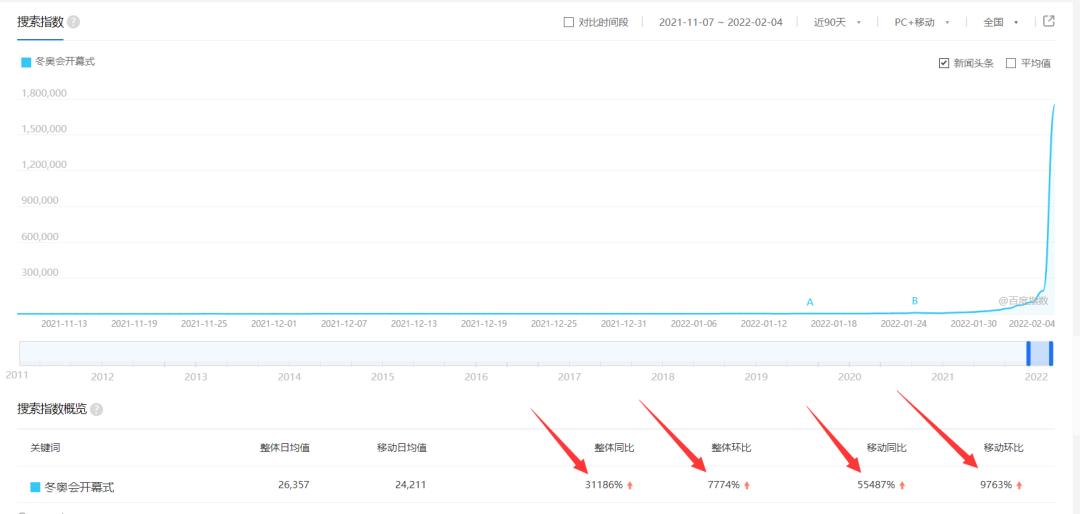
plt.show()结果如下:

冬奥会开幕式、北京冬奥会搜索指数近几天近似直线飙升。说明大家都非常关注啊。


五、词云图
这里采集一些文本材料,再做个词云图看看。
with open("冬奥会开幕式.txt", encoding="utf-8") as f:
data = f.read()
# 文本预处理 去除一些无用的字符 只提取出中文出来
new_data = re.findall('[\\u4e00-\\u9fa5]+', data, re.S)
new_data = "/".join(new_data)
# 文本分词 精确模式
seg_list_exact = jieba.cut(new_data, cut_all=False)
# 加载停用词
with open('stop_words.txt', encoding='utf-8') as f:
# 获取每一行的停用词 添加进集合
con = f.read().split('\\n')
stop_words = set()
for i in con:
stop_words.add(i)
# 列表解析式 去除停用词和单个词
result_list = [word for word in seg_list_exact if word not in stop_words and len(word) > 1]
print(result_list)
# https://fontawesome.com/license/free
# 个人推荐使用的palette配色方案 效果挺好看 其他测试过 感觉一般~~
# colorbrewer.qualitative.Dark2_7
# cartocolors.qualitative.Bold_5
# colorbrewer.qualitative.Set1_8
gen_stylecloud(
text=' '.join(result_list), # 文本数据
size=600, # 词云图大小
font_path='./font/猫啃网糖圆体.ttf', # 中文词云 显示需要设置字体
icon_name = "fas fa-grin-beam", # 图标
output_name='冬奥会开幕式.png', # 输出词云图名称
palette='colorbrewer.qualitative.Set1_8', # 选取配色方案
)如果说 年的奥运会,中国向世界展现的是传统的文化之美!那么这一次冬奥会,中国完美地向世界展现了什么叫科技的日新月异与腾飞!

六、总结
今年冬奥会开幕式真的太好看啦,惊艳全球!
总结:
Python爬虫:根据关键词获取百度搜索指数历史数据
解析 JSON 数据,加密数据的解密,数据保存到Excel
matplotlib:百度搜索指数的可视化
stylecloud:绘制词云图


往
期
回
顾
资讯
技术
技术

分享

点收藏

点点赞

点在看
以上是关于Python 可视化近 90 天的百度搜索指数 + 词云图的主要内容,如果未能解决你的问题,请参考以下文章
❤️1024,我一直都在~❤️数据可视化+爬虫:基于 Echarts + Python 实现的动态实时大屏范例 - 行业搜索指数排行榜17