使用 mitmproxy + python 做拦截代理,解放双手,生成自动化测试用例
Posted 七月的小尾巴
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用 mitmproxy + python 做拦截代理,解放双手,生成自动化测试用例相关的知识,希望对你有一定的参考价值。
前言
是不是有很多小伙伴在做接口自动化的时候,大量的测试用例数据,写的即枯燥,有乏味呢?
那么下面你们的福利来啦~本文章会基于 mitmproxy + python 做代理拦截,将我们拦截到的接口请求,转换成 .yaml 格式文件的测试用例,文件格式如下:
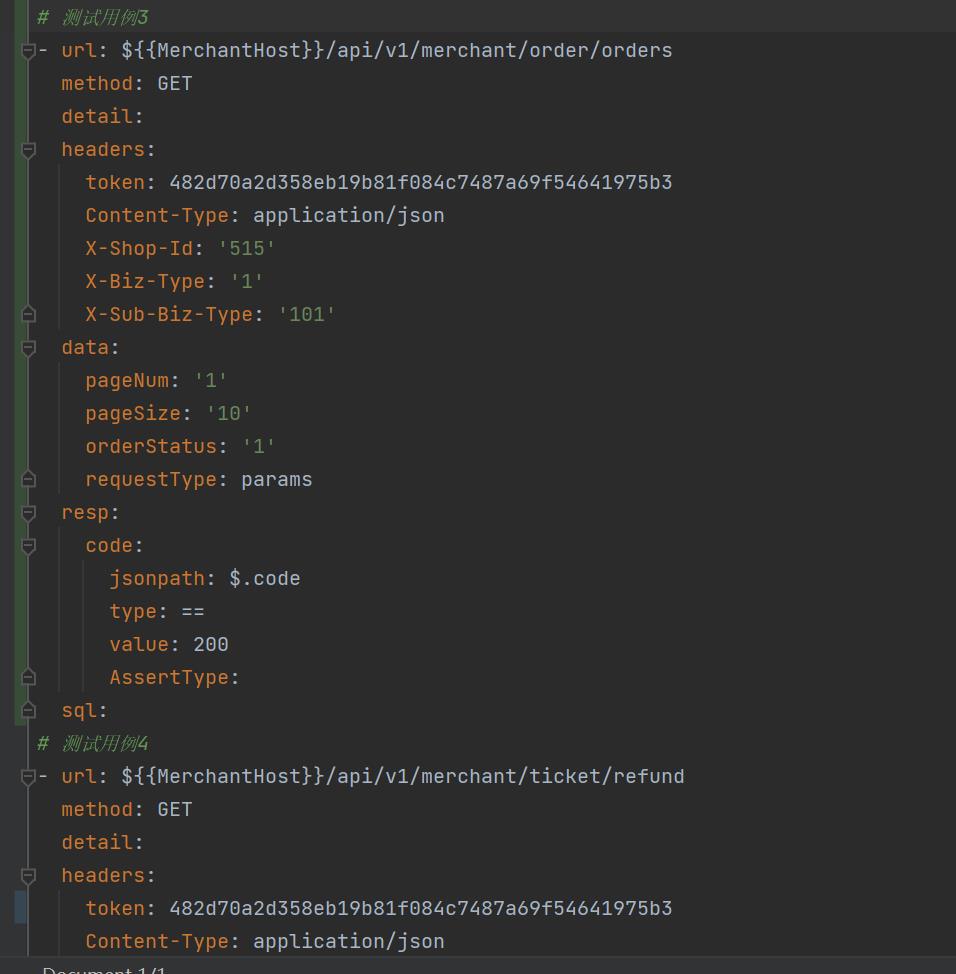
有的小伙伴是不是会担心,你们的yaml用例数据结构和我不同呢?完全不用担心,文章下方我会提供源码,只需要找到下方截图中的代码,更改你们自己的数据结构即可~
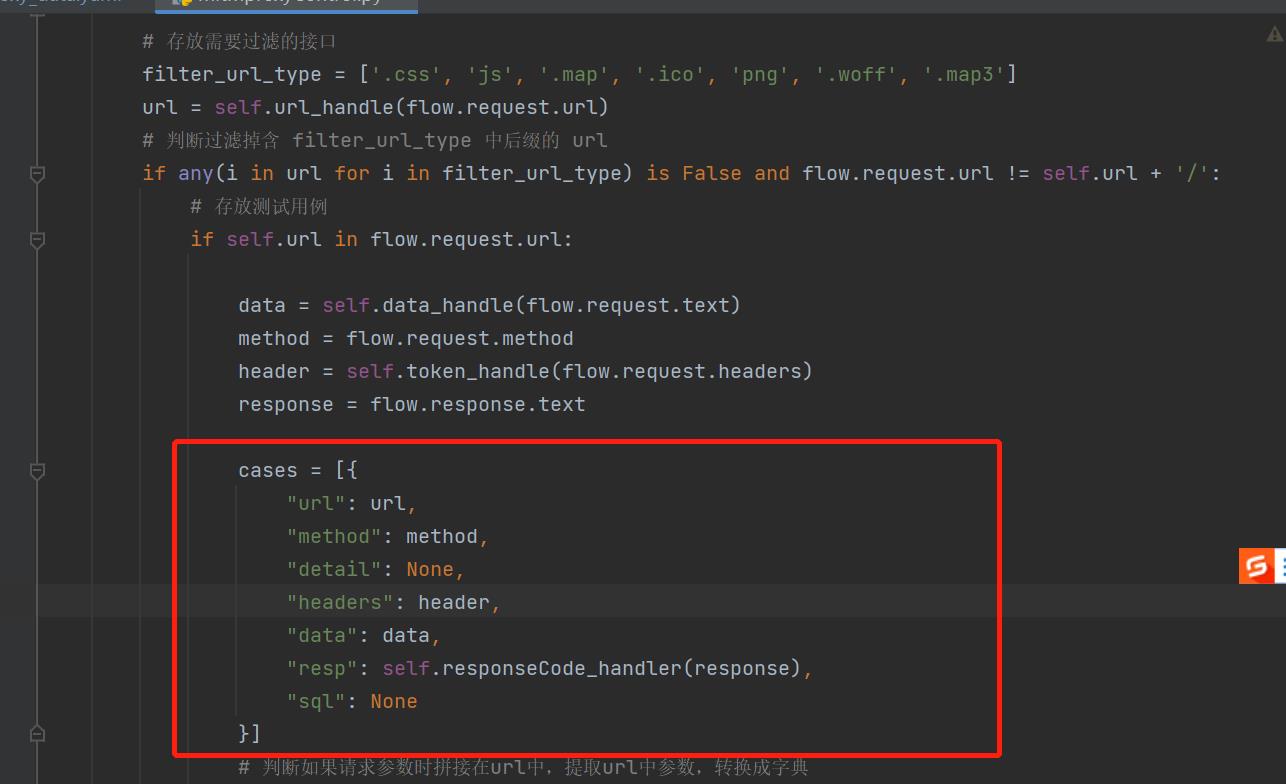
下面话不多说,我们进入正文
什么是 mitmproxy ?
文章地址: https://blog.wolfogre.com/posts/usage-of-mitmproxy/.
非常感谢这位作者,文章中非常详细的介绍整个网络请求的生命周期,以及非常详细的关于 mitmporxy的介绍。
大家在实现自动生成自动化测试用例之前,可以先了解一下 mitmpory的工作原理已经使用方法。
如何生成测试用例:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Time : 2022/1/9 14:16
# @Author : 余少琪
import mitmproxy.http
from mitmproxy import ctx
import json
from ruamel import yaml
import os
from typing import Any, Union
from urllib.parse import parse_qs, urlparse
class Counter:
"""
代理录制,基于 mitmproxy 库拦截获取网络请求
将接口请求数据转换成 yaml 测试用例
参考资料: https://blog.wolfogre.com/posts/usage-of-mitmproxy/
"""
def __init__(self, filter_url: str, filename: str = './data/proxy_data.yaml'):
self.num = 0
self.file = filename
self.counter = 1
# 需要过滤的 url
self.url = filter_url
def response(self, flow: mitmproxy.http.HTTPFlow) -> None:
"""
mitmproxy抓包处理响应,在这里汇总需要数据, 过滤 包含指定url,并且响应格式是 json的
:param flow:
:return:
"""
# 存放需要过滤的接口
filter_url_type = ['.css', 'js', '.map', '.ico', 'png', '.woff', '.map3']
url = self.url_handle(flow.request.url)
# 判断过滤掉含 filter_url_type 中后缀的 url
if any(i in url for i in filter_url_type) is False and flow.request.url != self.url + '/':
# 存放测试用例
if self.url in flow.request.url:
data = self.data_handle(flow.request.text)
method = flow.request.method
header = self.token_handle(flow.request.headers)
response = flow.response.text
cases = [
"url": url,
"method": method,
"detail": None,
"headers": header,
"data": data,
"resp": self.responseCode_handler(response),
"sql": None
]
# 判断如果请求参数时拼接在url中,提取url中参数,转换成字典
if "?" in url:
cases[0]['url'] = self.get_url_handler(url)[1]
cases[0]['data'] = self.get_url_handler(url)[0]
# 处理 request_type
cases = self.request_type_handler(method, cases)
# 处理请求头中需要的数据
self.request_headers(flow.request.headers, cases)
ctx.log.info("=" * 100)
ctx.log.info(cases)
# 判断文件不存在则创建文件
try:
self.yaml_cases(cases, self.counter)
except FileNotFoundError:
os.makedirs(self.file)
self.counter += 1
@classmethod
def responseCode_handler(cls, response) -> Union[dict, None]:
# 处理接口响应,默认断言数据为code码,如果接口没有code码,则返回None
try:
data = cls.data_handle(response)
return "code": "jsonpath": "$.code", "type": "==",
"value": data['code'], "AssertType": None
except KeyError:
return None
except NameError:
return None
@classmethod
def request_type_handler(cls, method: str, cases: list) -> list:
# 处理请求类型,有params、json、file,需要根据公司的业务情况自己调整
if method == 'GET':
# 如我们公司只有get请求是prams,其他都是json的
cases[0]['data']['requestType'] = 'params'
else:
cases[0]['data']['requestType'] = 'json'
return cases
@classmethod
def request_headers(cls, headers, cases: list) -> list:
# 公司业务: 请求头中包含了 X-Shop-Id、X-Sub-Biz-Type, 其他项目可注释此段代码
if 'X-Shop-Id' in headers:
cases[0]['headers']['X-Shop-Id'] = headers['X-Shop-Id']
if 'X-Biz-Type' in headers:
cases[0]['headers']['X-Biz-Type'] = headers['X-Biz-Type']
if 'X-Sub-Biz-Type' in headers:
cases[0]['headers']['X-Sub-Biz-Type'] = headers['X-Sub-Biz-Type']
return cases
@classmethod
def data_handle(cls, dict_str) -> Any:
# 处理接口请求、响应的数据,如null、true格式问题
try:
if dict_str != "":
if 'null' in dict_str:
dict_str = dict_str.replace('null', 'None')
if 'true' in dict_str:
dict_str = dict_str.replace('true', 'True')
if 'false' in dict_str:
dict_str = dict_str.replace('false', 'False')
dict_str = eval(dict_str)
if dict_str == "":
dict_str = None
return dict_str
except Exception:
raise
@classmethod
def token_handle(cls, header) -> dict:
# token 处理
headers =
if 'token' in header:
headers['token'] = header['token']
headers['Content-Type'] = 'application/json'
return headers
def url_handle(self, url: str) -> Union[bool, str]:
"""
解析 url
:param url: https://xxxx.test.xxxx.com/#/goods/listShop
:return: 最终返回 $MerchantHost/#/goods/listShop
"""
url = url.replace(self.url, "$MerchantHost")
_Symbol = "'"
return url
def yaml_cases(self, data: list, counter: int) -> None:
"""
写入 yaml 数据
:param counter:
:param data: 测试用例数据
:return:
"""
with open(self.file, "a", encoding="utf-8") as f:
f.write('# 测试用例' + str(counter) + "\\n")
yaml.dump(data, f, Dumper=yaml.RoundTripDumper, allow_unicode=True)
@classmethod
def get_url_handler(cls, url: str) -> tuple:
"""
将 url 中的参数 转换成字典
:param url: /trade?tradeNo=&outTradeId=11
:return: “outTradeId”: 11
"""
query = urlparse(url).query
# 将字符串转换为字典
params = parse_qs(query)
# 所得的字典的value都是以列表的形式存在,如请求url中的参数值为空,则字典中不会有该参数
result = key: params[key][0] for key in params
url = url[0:url.rfind('?')]
return result, url
@classmethod
def handleForm(cls, data: str):
"""
处理 Content-Type: application/x-www-form-urlencoded
默认生成的数据 username=admin&password=123456
:param data: 获取的data 类似这样 username=admin&password=123456
:return:
"""
data_dict =
if data.startswith('') and data.endswith(''):
return data
try:
for i in data.split('&'):
data_dict[i.split('=')[0]] = i.split('=')[1]
return json.dumps(data_dict)
except IndexError:
return ''
# 1、本机需要设置代理,默认端口为: 8080
# 2、控制台输入 mitmweb -s .\\tools\\mitmproxyControl.py 命令开启代理模式进行录制
addons = [
Counter("http://xxxx.test.xxxx.com")
]
只需要运行如上代理,就可以生成和我一样的测试用例啦~
为了实现代理录制的功能,百度查了很多资料,然后结合自己公司的自动化项目和框架,生成了对应的用例数据,目前已在自动化项目中开展,可以提升很大部门时间,如果觉得有帮助到你,麻烦关注 + 收藏哦~~
如果是正在学习自动化的宝子们,也可以查看 pytest开源自动化框架,框架功能 包含 Python+pytest+allure+log+yaml+mysql+钉钉或企业微信通知 + 代理录制生成测试用例,功能丰富并且易维护
功能也会持续更新,建议收藏哦~
以上是关于使用 mitmproxy + python 做拦截代理,解放双手,生成自动化测试用例的主要内容,如果未能解决你的问题,请参考以下文章