一文读懂CTR预估模型的发展历程
Posted fareise
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一文读懂CTR预估模型的发展历程相关的知识,希望对你有一定的参考价值。
如果觉得我的算法分享对你有帮助,欢迎关注我的微信公众号“ 圆圆的算法笔记”,更多算法笔记和世间万物的学习记录~
1. 背景
CTR预估是搜索、推荐、广告等领域基础且重要的任务,主要目标是预测用户在当前上下文环境下对某一个候选(视频、商品、广告等) 发生点击的概率。CTR预估从最原始的逻辑回归模型,发展到FM、深度学习模型等,经历了一个不断创新的过程,其核心为如何设计、融合不同的特征交叉方式。本文从FM和DNN开始开始,带你梳理CTR预估模型的发展历程,包括FNN、PNN、Wide&Deep、DCN、DeepFM、xDeepFM等一系列CTR预估模型和它们之间发展演进的关系。
2. 从FM和DNN说起
CTR预估问题的核心是特征工程,而特征交叉又是特征工程最重要的一环。不同特征的组合构造而成的交叉特征对于点击率预估十分重要。例如,当存在节日特征和国家特证这两个特征时,能够较差国家特证和节日特征,如中国+春节,能够更好的反映出当前样本的特点,也和label关联更密切。
在传统的逻辑回归模型中,人工构造不同特征的交叉,并对每组交叉特征设定一个权重,可以得到类似于下面的线性方程:
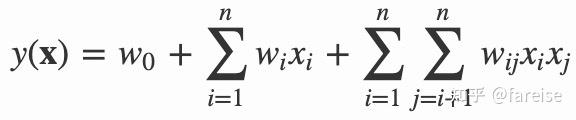
其中xi代表某一个特征,对于离散特征而言,需要通过one-hot编码将一个离散特征变成多个0-1特征。当某些离散特征非常稀疏时,这种交叉导致训练样本中有很多未曾出现过的组合。例如包含500个取值的类目特征和包含10000个取值的用户特征,这两个特征的交叉会生成500*10000的不同组合,这么庞大的特征组合数量,训练样本难以覆盖,因此对应的权重wij也就无法求解。
为了解决这个问题,FM的方法和DNN的方法被提出。FM的方法给每个特征赋予一个可学习的向量,将原来的先行方程转换为如下形式:
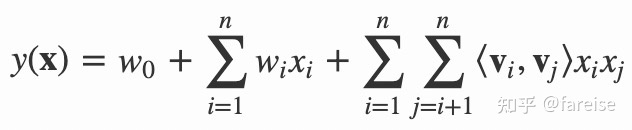
这样我们需要拟合的参数量,从原来的500*10000个缩小为500+10000个,大大缓解了特征稀疏的问题。这里将每个二阶特征组合的权重拆解成了每个特征对应向量的乘积,利用了矩阵分解的思想,也是FM(Factorzation Machine)这一方法名字的由来。FM这种方法采用的是vector-wise特征交叉,即在每个特征向量的维度进行交叉。
另一种解决方法是Embedding+DNN的思路。将每个特征通过Embedding矩阵转换成一个向量,将所有向量拼接到一起,通过多层DNN网络进行预测。DNN这种方法采用的是bit-wise维度,即每个元素值交叉,不管这个值来自哪个特征。
CTR模型的发展历程也在FM和DNN两种方式的基础上进行不断演化。
3. 对于DNN和FM的模型优化
对于DNN和FM模型的优化可以分为两类,一类是将DNN模型和FM模型各自的优点进行融合,另一类是针对DNN模型或FM模型存在的问题进行改进。
3.1 FM和DNN的结合
Deep Learning over Multi-field Categorical Data – A Case Study on User Response Prediction(2016,FNN)将DNN和FM模型的优势进行了结合。该方法首先使用FM进行训练,得到每个特征对应的向量,作为每个特征的向量表示。然后使用这个向量作为每个特征的初始化向量,后面使用DNN进行预测。Product-based Neural Networks for User Response Prediction(2016,PNN)对该方法进行了改进,不再使用FM预训练得到向量,而是对每个特征的向量随机初始化,对DNN模型进行修改。在DNN模型中引入了FM的思想,对每两个embedding pair进行内积或外积运算,相当于FM中的二阶特征交叉这一步,再把一阶和二阶特征拼接到一起,后面使用全连接层进行CTR预测。
FNN和PNN的问题在于,由于采用了DNN结构,模型更倾向于提取高阶特征交叉,对低阶特征交叉提取较少,而后者在CTR预估中也是非常重要的。DeepFM: A Factorization-Machine based Neural Network for CTR Prediction(2017)提出DeepFM模型,通过结合DNN和FM实现二者优势互补。模型分为DNN模块和FM模块,DNN模块和FM模块共享底层embedding。Deep模块和FM模块的输出最终拼接到一起,共同预测点击率。
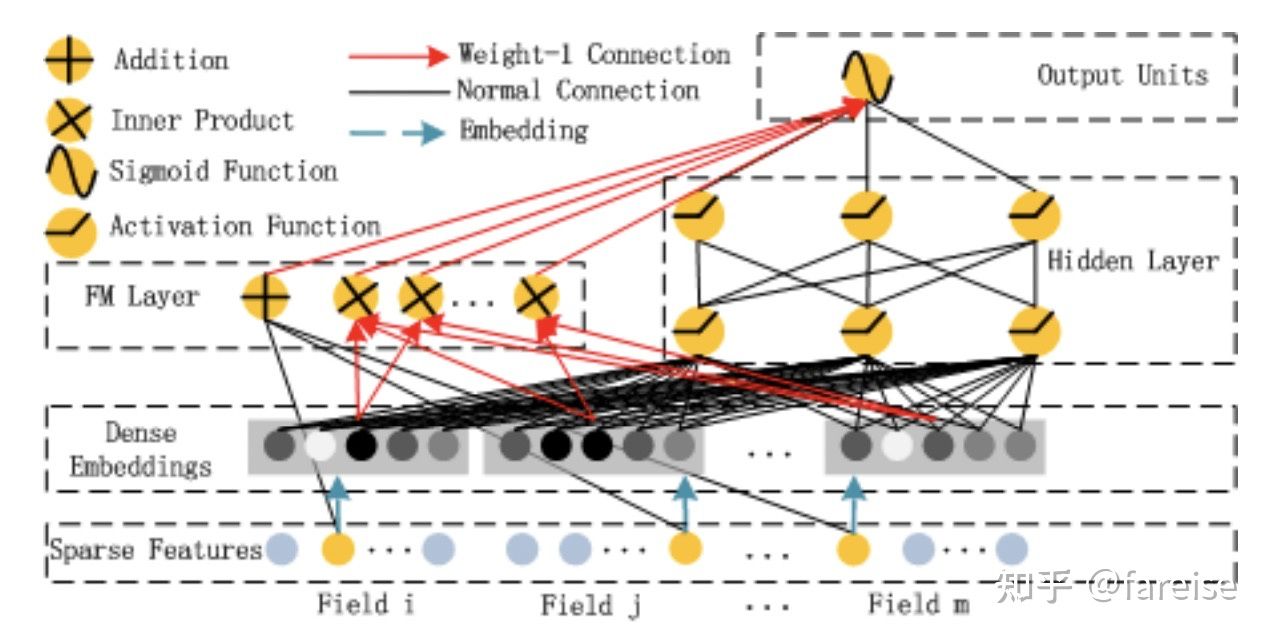
3.2 针对DNN/FM问题的改进
DNN或者FM模型都是基于embedding的,FM中的embedding是每个特征对应的向量,DNN中的embedding是每个特征值对应的向量。基于embedding的方法虽然提升了模型的泛化性(generalization),但是记忆性(memorization)较弱。例如,对于某个user+某个item这种组合特征,一种处理方法是userid+itemid组成新的id,另一种方式是userid的embedding和itemid的embedding做内积。前者是id特征,记忆性要明显强于后者,而前者的泛化性较弱,例如训练样本中没有这个user和这个item的组合。针对DNN或FM的记忆性较差问题,Wide & Deep Learning for Recommender Systems(2016,Wide&Deep)提出了在DNN模型基础上,增加一个并行的Wide网络,DNN部分负责泛化性,而Wide网络负责记忆性。Wide部分采用上一节给出的简单线性模型,即每个特征或每组交叉特征前面用学习一个权重。
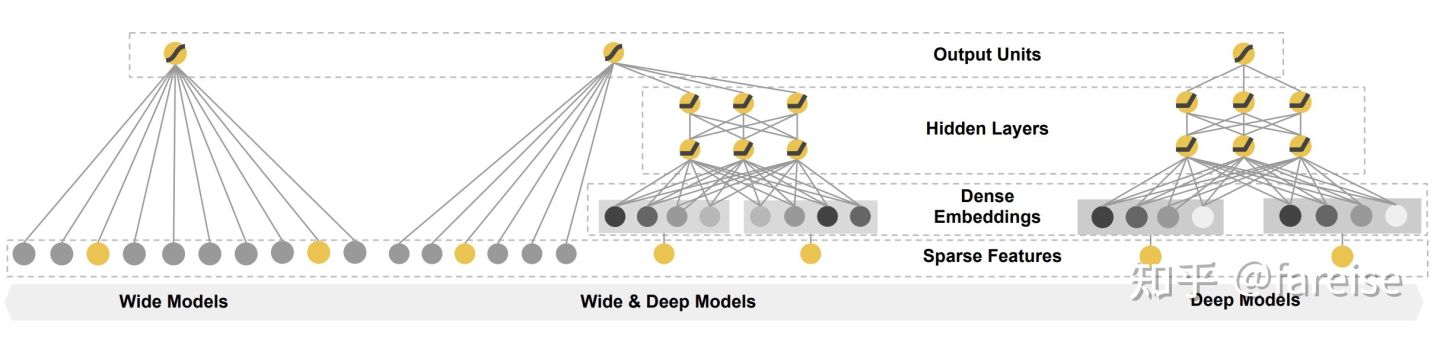
Wide&Deep的缺点在于,左侧部分依赖人工设计特征,Deep & Cross Network for Ad Click Predictions(2017,DCN)将左侧的wide部分替换成了cross layer。Cross layer的核心是下面这个计算公式:
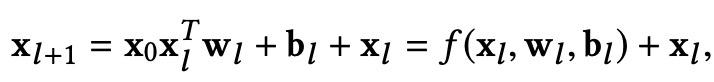
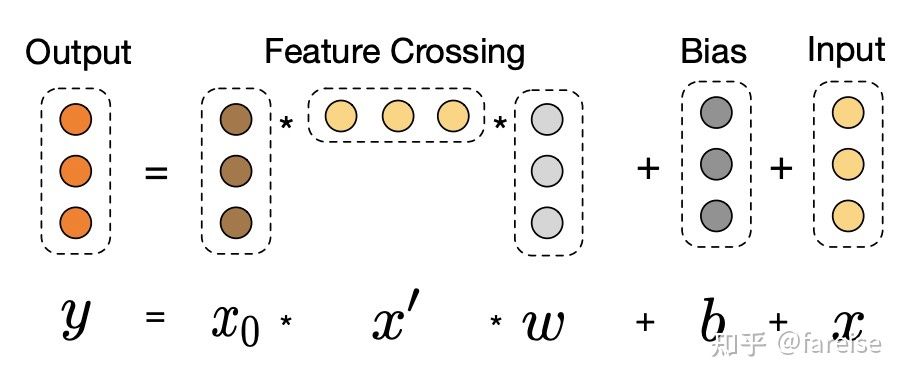
每一层的特征x都是上一层特征和第一层特征的一个组合。为什么采用这个公式,我们来看一个只有2个特征的两层cross layer的展开运算:
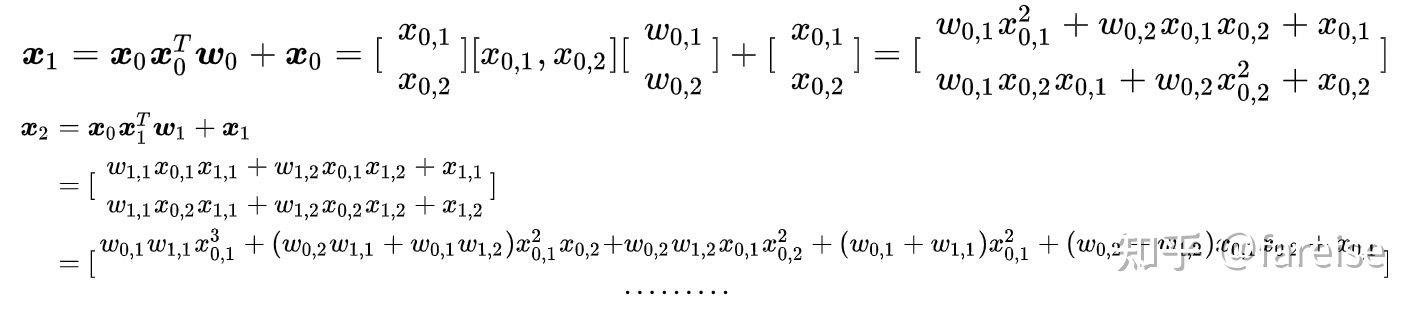
随着层数的增加,最终cross部分的输出是所有特征的多阶交叉,且交叉的阶数和cross layer的层数线性相关。通过这种方式,实现了对所有特征交叉的自动化学习,而不再需要手动提取高阶交叉特征了。
xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems(KDD 2018)进一步对cross layer进行了升级。这篇文章指出,DCN中的cross layer得到的特征交叉只是一个固定形式的(为乘一个标量),这限制了其他形式特征交叉的学习。同时,DCN的公式推导的最终结果是bit-wise的交叉,而非FM中采用的vector-wise的。因此,本文提出了CIN结构替代原来的cross layer。CIN主要目标是实现vector-wise的特征交叉,即将FM的思想引入到cross layer部分,其每层的特征计算方式和示意图如下:
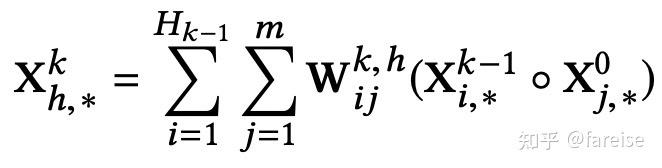
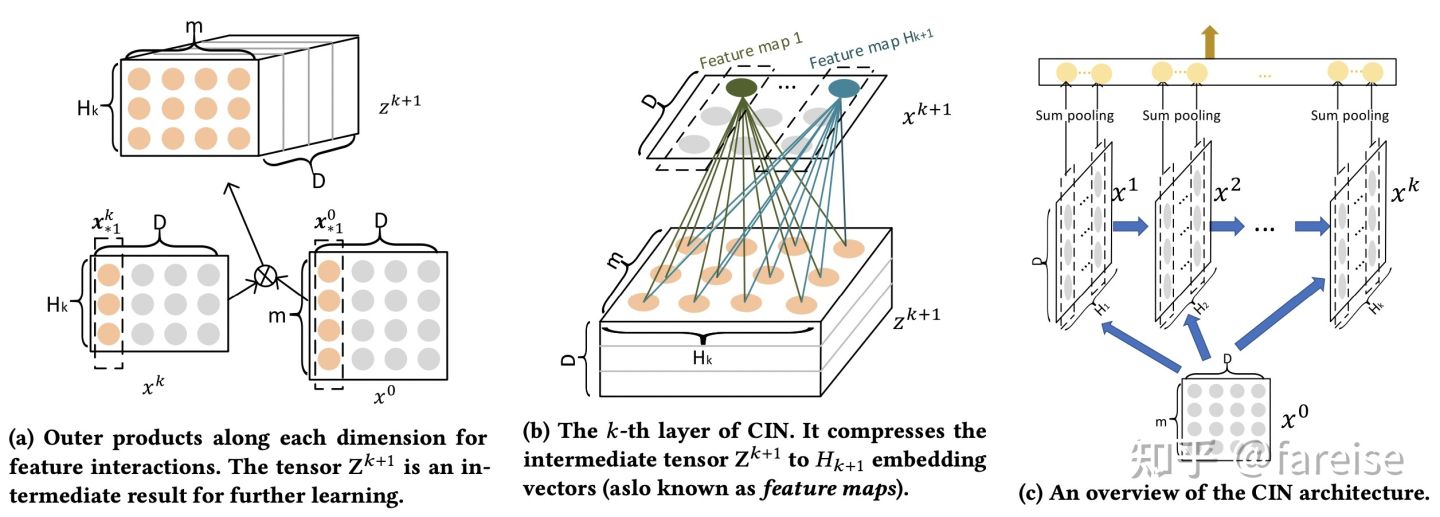
上图中的a和b将这个公式拆成两个部分。图a描述了l-1层的X和0层的X外积的过程,这个过程生成了一个“图像”。图b描述了用W加权的过程,这个过程类似于在图像上做卷积。
4. 总结
本文介绍了点击率预估模型的发展历程,从DNN模型和FM模型出发,介绍了FM和DNN相结合,以及针对DNN/FM问题进行的改进,梳理了近年来点击率预估模型的整体发展历程。
如果觉得我的算法分享对你有帮助,欢迎关注我的微信公众号“圆圆的算法笔记”,更多算法笔记和世间万物的学习记录~
以上是关于一文读懂CTR预估模型的发展历程的主要内容,如果未能解决你的问题,请参考以下文章