k8s3 Service详解 Ingress服务 数据存储 安全认证
Posted lin-fighting
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了k8s3 Service详解 Ingress服务 数据存储 安全认证相关的知识,希望对你有一定的参考价值。
Service详解
在kubernetes中,pod是应用程序的载体,我们可以通过pod的ip来访问应用程序,但是pod的ip地址不是固定的,这也就意味着不方便直接采用pod的ip对服务进行访问。
为了解决这个问题,kubernetes提供了Service资源,Service会对提供同一个服务的多个pod进行聚合,并且提供一个统一的入口地址。通过访问Service的入口地址就能访问到后面的pod服务。
通过service就可以访问特定的pod。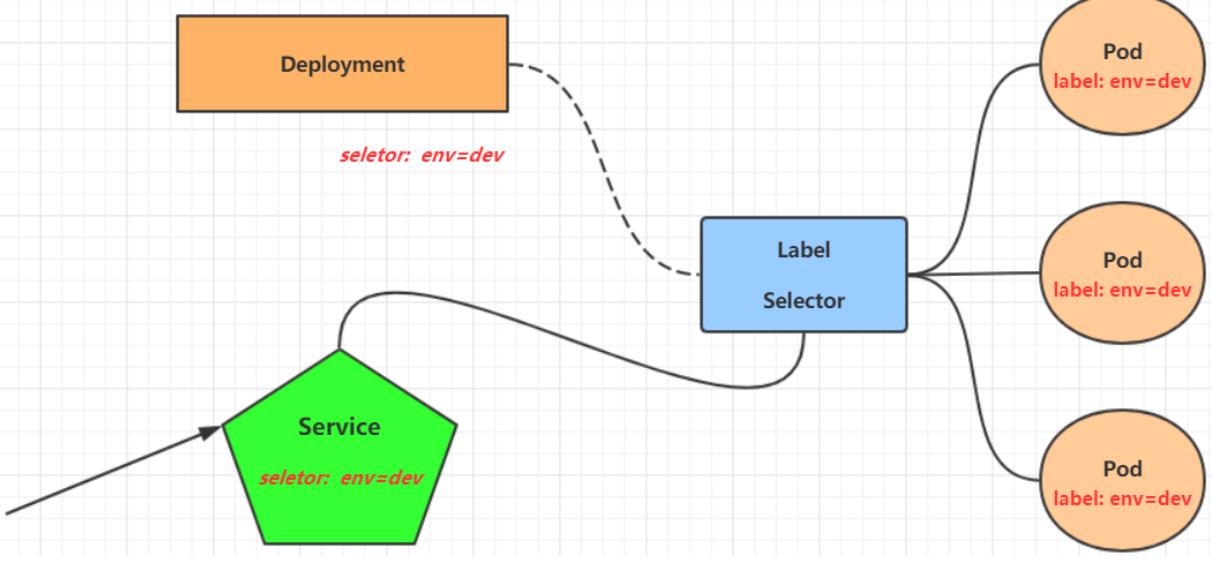
像之前的kubectl expose service xxxx等等,就是用来创建service来访问特定的pod,因为pod ID会随着每次重新创建而变化。
Kube-proxy
Service在很多情况下只是一个概念,真正起作用的其实是kube-proxy服务进程。
每个node节点上都跑着一个kube-proxy服务
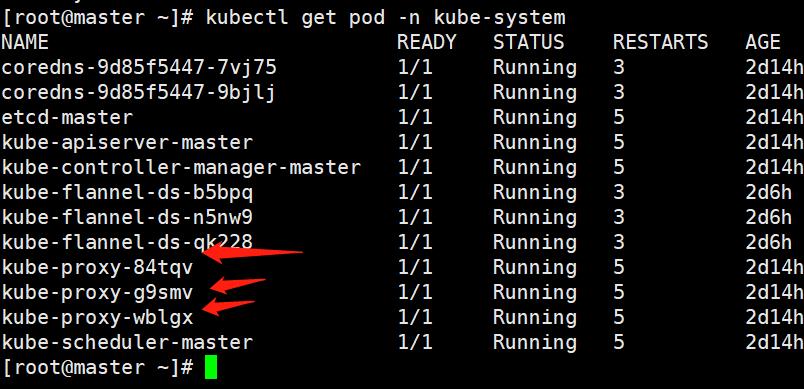
当我们创建service的时候,api-server会向etcd写入创建的service信息,而kube-proxy会给予watch的监听机制发现service的变动,然后将最新的service信息转换成对应的访问规则。
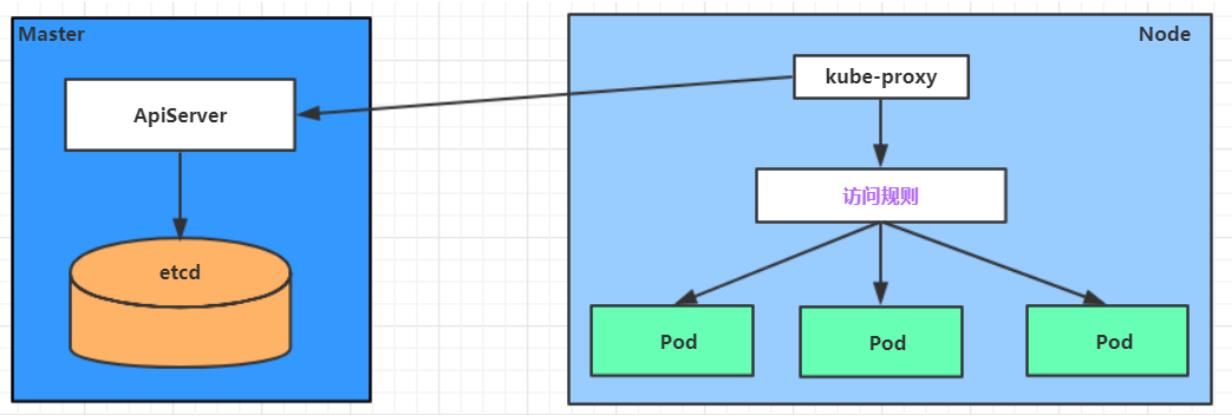
如:
# 10.97.97.97:80 是service提供的访问入口
# 当访问这个入口的时候,可以发现后面有三个pod的服务在等待调用,
# kube-proxy会基于rr(轮询)的策略,将请求分发到其中一个pod上去
# 这个规则会同时在集群内的所有节点上都生成,所以在任何一个节点上访问都可以。
kube-proxy目前支持三种工作模式:
- userspace 模式
- iptables 模式
- ipvs 模式
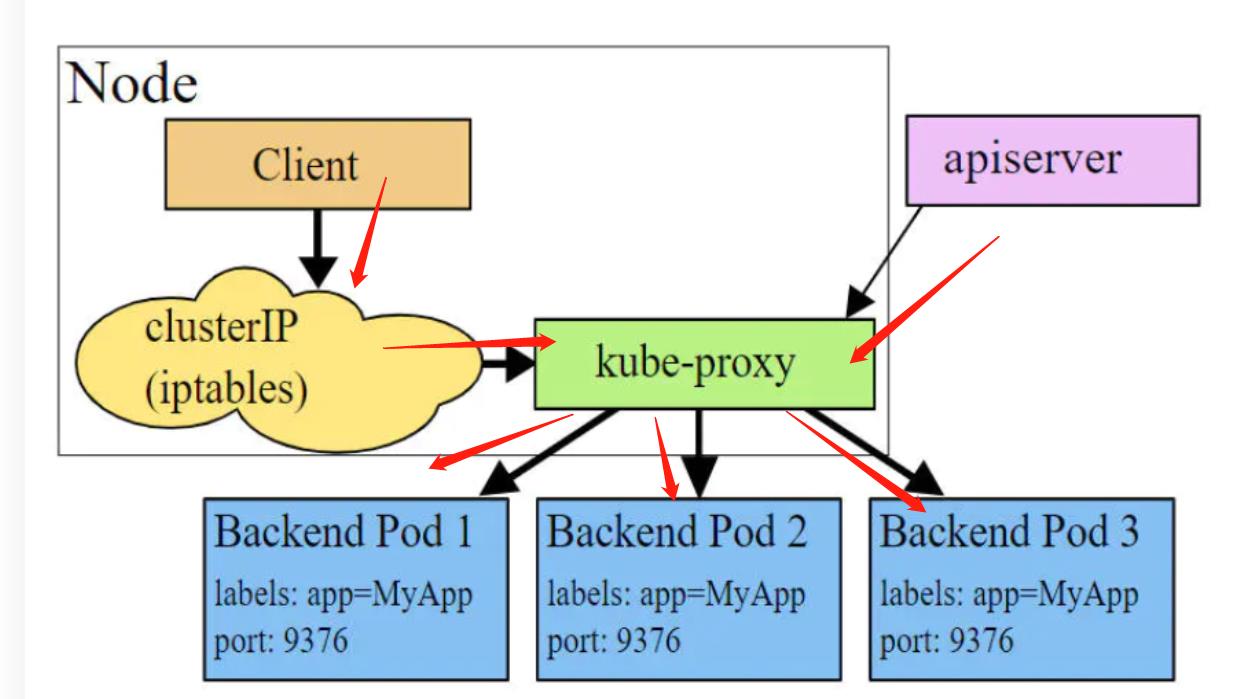
userspace 模式
userspace模式下,kube-proxy会为每一个Service创建一个监听端口,发向Cluster IP的请求被Iptables规则重定向到kube-proxy监听的端口上
kube-proxy根据LB算法选择一个提供服务的Pod并和其建立链接,以将请求转发到Pod上.
kube-proxy充当了一个四层负责均衡器的角色,相当于一个管家,接受到请求之后还要计算哪个pod比较好,再给他转发。
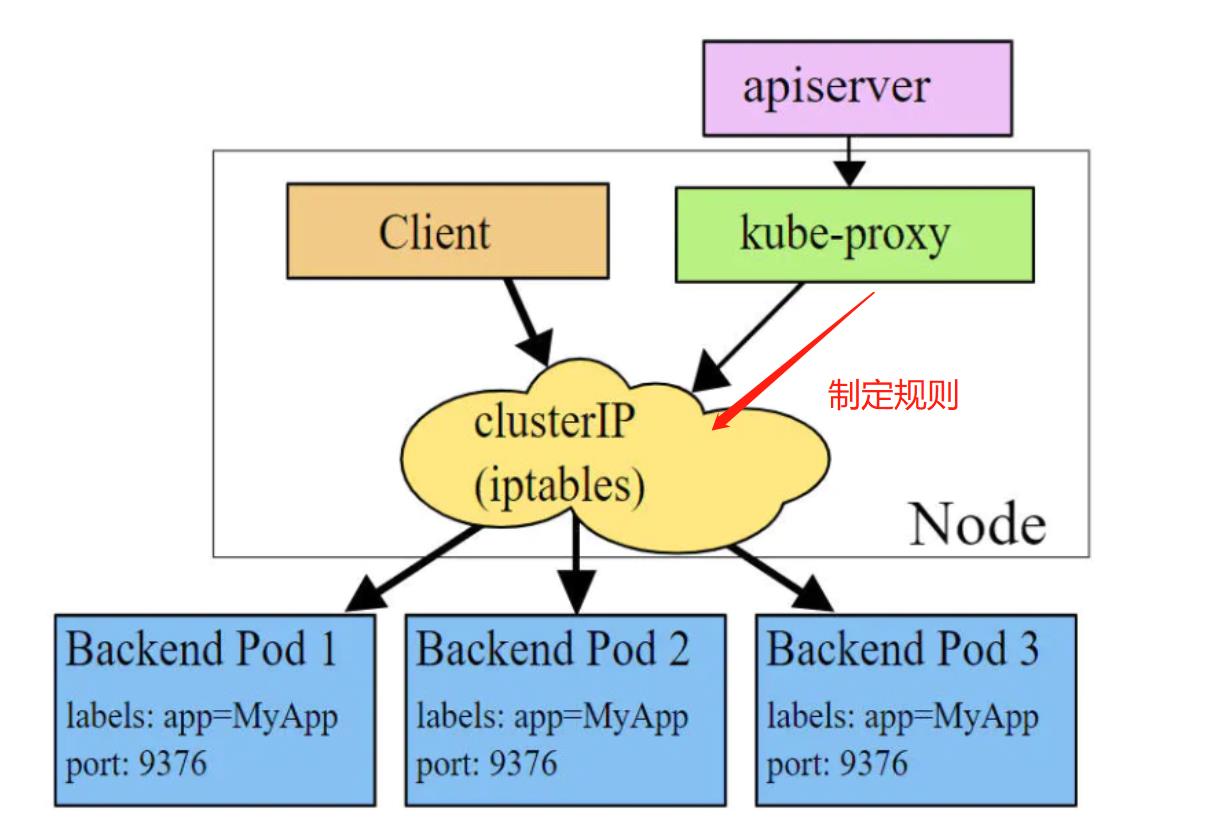
iptables 模式
iptables模式下,kube-proxy为service后端的每个Pod创建对应的iptables规则,直接将发向Cluster IP的请求重定向到一个Pod IP
该模式下kube-proxy不承担四层负责均衡器的角色,只负责创建iptables规则。相当于一个规则创建员,制定好每个Pod的规则,你们该去哪里去哪里。
该模式的优点是较userspace模式效率更高,但不能提供灵活的LB策略,当后端Pod不可用时也无法进行重试。
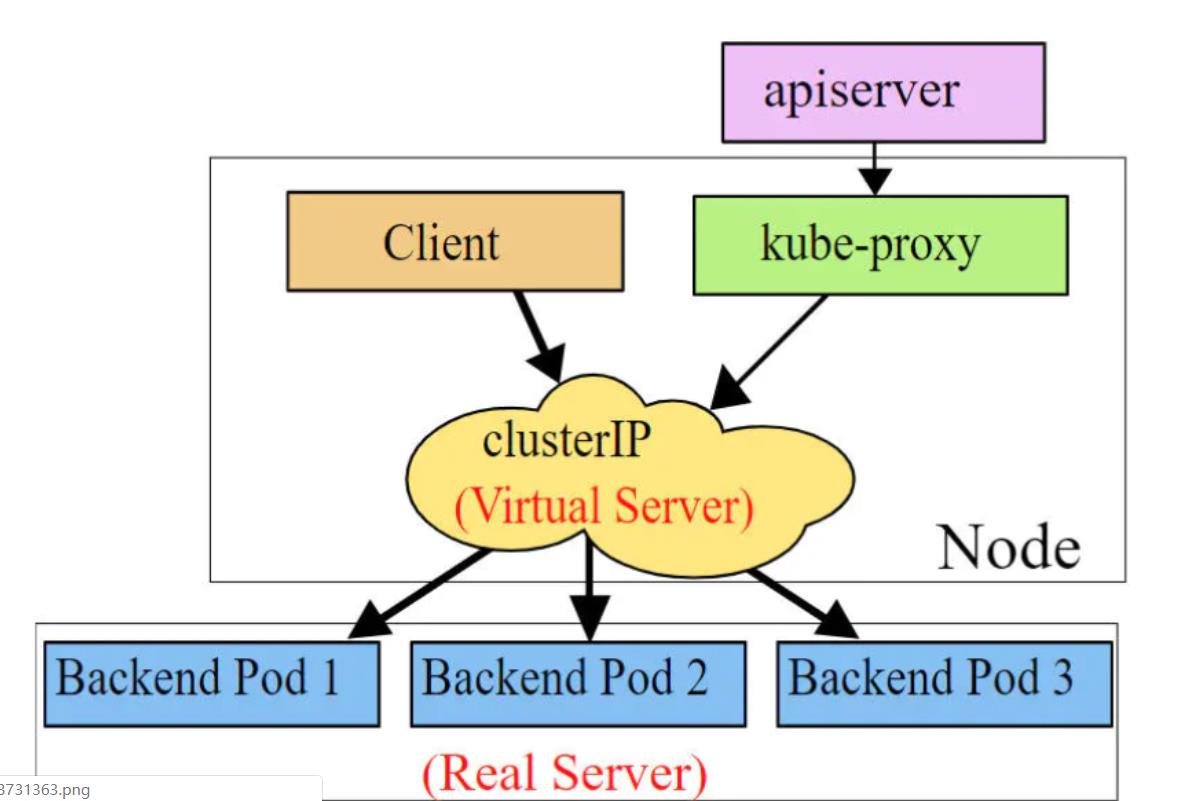
ipvs 模式
ipvs模式和iptables类似,kube-proxy监控Pod的变化并创建相应的ipvs规则。ipvs相对iptables转发效率更高。除此以外,ipvs支持更多的LB算法。
Kube-proxy三种模式,管家类,啥都操心。规则类,只制定规则,其他不管,升级的规则类,可以i通过pod变化实时改变Pod规则,效率更高。
Service类型
- ClusterIP:默认值,它是Kubernetes系统自动分配的虚拟IP,只能在集群内部访问
- NodePort:将Service通过指定的Node上的端口暴露给外部,通过此方法,就可以在集群外部访问服务
- LoadBalancer:使用外接负载均衡器完成到服务的负载分发,注意此模式需要外部云环境支持
- ExternalName: 把集群外部的服务引入集群内部,直接使用
Endpoint
Endpoint是kubernetes中的一个资源对象,存储在etcd中,用来记录一个service对应的所有pod的访问地址,它是根据service配置文件中selector描述产生的。
一个Service由一组Pod组成,这些Pod通过Endpoints暴露出来,Endpoints是实现实际服务的端点集合。换句话说,service和pod之间的联系是通过endpoints实现的。
负载分发策略
对Service的访问被分发到了后端的Pod上去,目前kubernetes提供了两种负载分发策略:
- 1 如果不定义,默认使用kube-proxy的策略,比如随机、轮询
- 2 基于客户端地址的会话保持模式,即来自同一个客户端发起的所有请求都会转发到固定的一个Pod上
HeadLiness类型的Service
在某些场景中,开发人员可能不想使用Service提供的负载均衡功能,而希望自己来控制负载均衡策略,针对这种情况,kubernetes提供了HeadLiness Service,这类Service不会分配Cluster IP,如果想要访问service,只能通过service的域名进行查询。
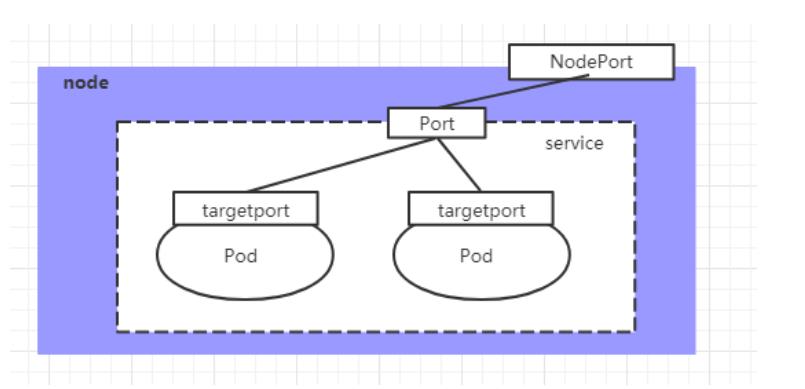
NodePort类型的Service
在之前的样例中,创建的Service的ip地址只有集群内部才可以访问,如果希望将Service暴露给集群外部使用,那么就要使用到另外一种类型的Service,称为NodePort类型。NodePort的工作原理其实就是将service的端口映射到Node的一个端口上,然后就可以通过NodeIp:NodePort来访问service了。
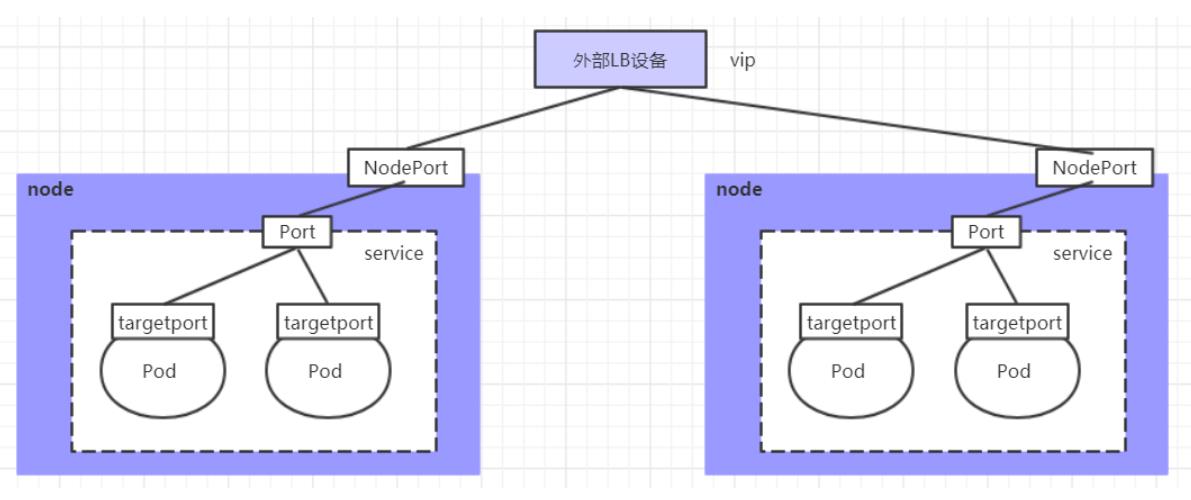
LoadBalancer类型的Service
LoadBalancer和NodePort很相似,目的都是向外部暴露一个端口,区别在于LoadBalancer会在集群的外部再来做一个负载均衡设备,而这个设备需要外部环境支持的,外部服务发送到这个设备上的请求,会被设备负载之后转发到集群中
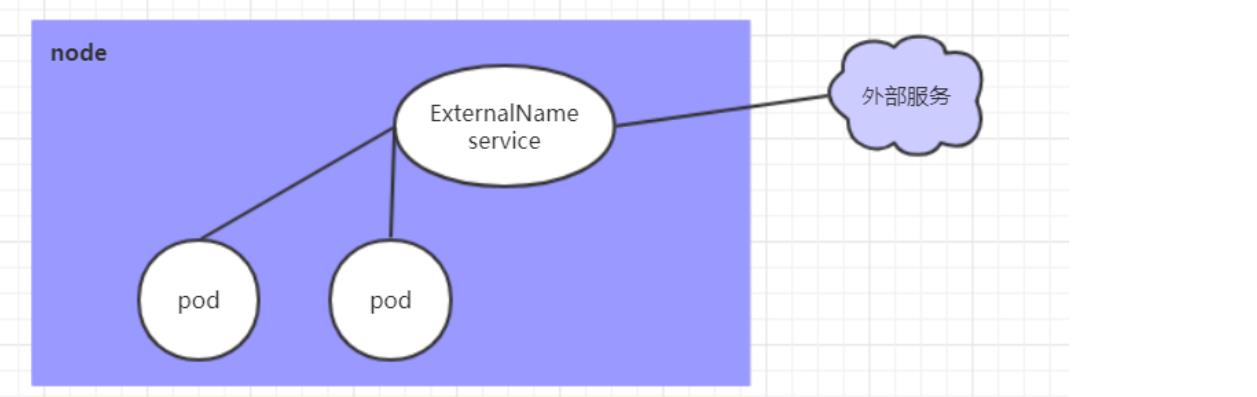
ExternalName类型的Service
ExternalName类型的Service用于引入集群外部的服务,它通过externalName属性指定外部一个服务的地址,然后在集群内部访问此service就可以访问到外部的服务了。
Ingress
Service对集群之外暴露服务的主要方式有两种:NotePort和LoadBalancer
- NodePort方式的缺点是会占用很多集群机器的端口,那么当集群服务变多的时候,这个缺点就愈发明显
- LB方式的缺点是每个service需要一个LB,浪费、麻烦,并且需要kubernetes之外设备的支持
基于这种现状,kubernetes提供了Ingress资源对象,Ingress只需要一个NodePort或者一个LB就可以满足暴露多个Service的需求。工作机制大致如下图表示:
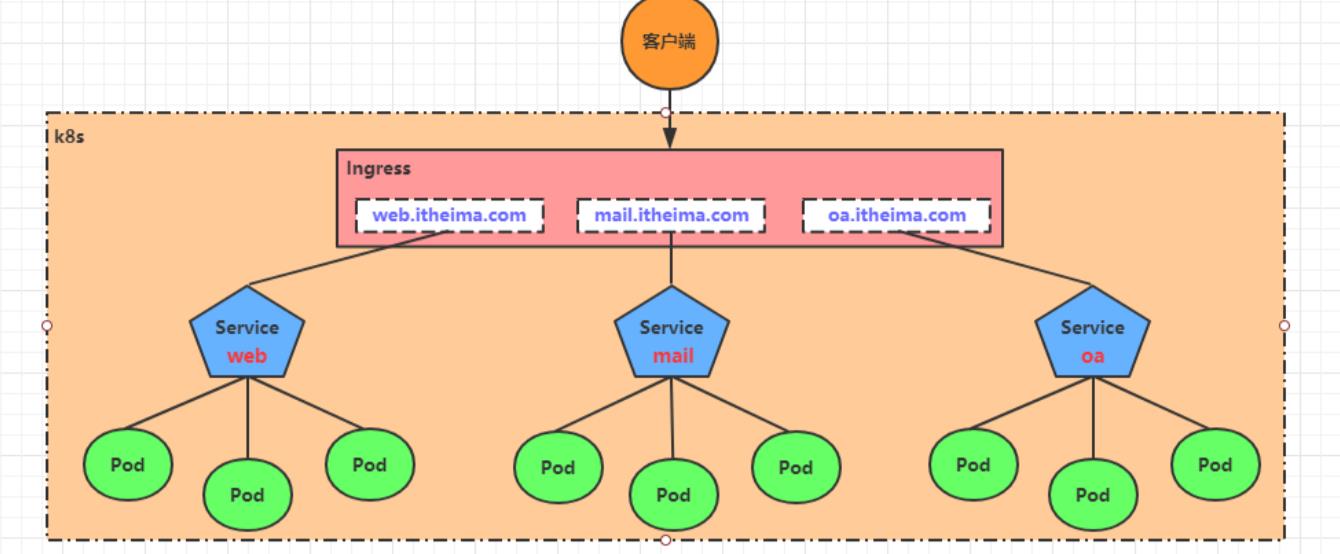
Ingress类似于nginx,可以做负载均衡,反向映射等等。
Ingress相当于一个7层的负载均衡器,是kubernetes对反向代理的一个抽象。在Ingress里建立诸多映射规则
Ingress Controller通过监听这些配置规则并转化成Nginx的反向代理配置 , 然后对外部提供服务
- ingress:kubernetes中的一个对象,作用是定义请求如何转发到service的规则
- ingress controller:具体实现反向代理及负载均衡的程序,对ingress定义的规则进行解析,根据配置的规则来实现请求转发,实现方式有很多,比如Nginx, Contour, Haproxy等等
一个是定义规则,一个是实现规则
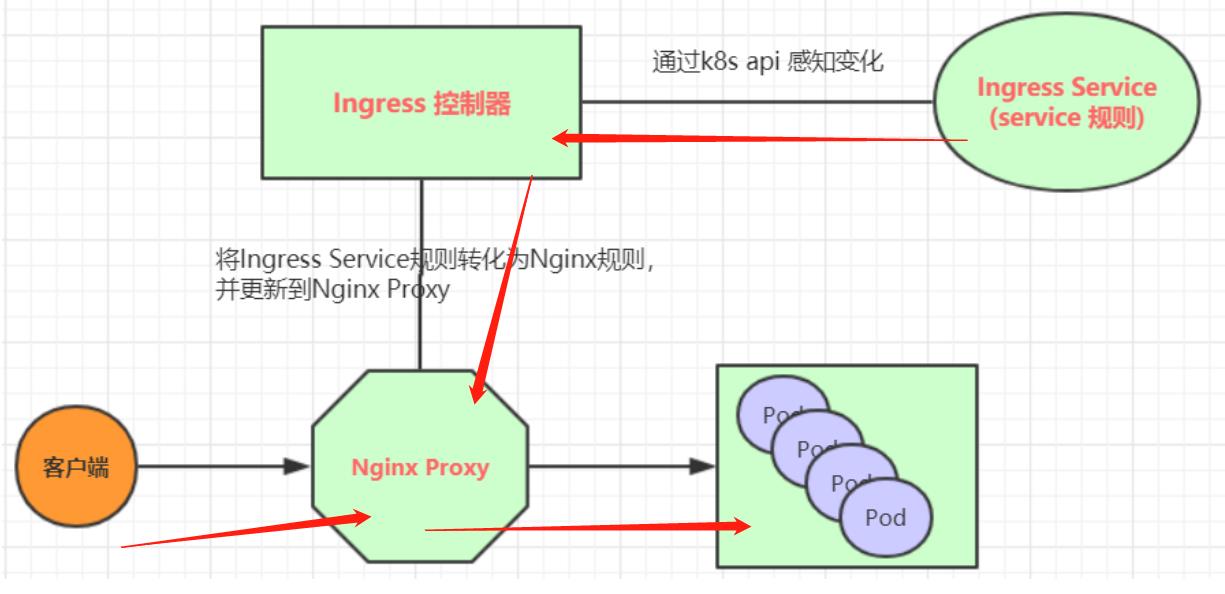
工作原理(nginx为例子):
- 1 用户编写Ingress规则,说明哪个域名对应kubernetes集群中的哪个Service
- 2 Ingress控制器动态感知Ingress服务规则的变化,然后生成一段对应的Nginx反向代理配置
- 3 ngress控制器会将生成的Nginx配置写入到一个运行着的Nginx服务中,并动态更新
- 4 到此为止,其实真正在工作的就是一个Nginx了,内部配置了用户定义的请求转发规则
数据存储(Volumn)
容器的生命周期可能很短,会被频繁地创建和销毁。那么容器在销毁时,保存在容器中的数据也会被清除。
为了持久化保存容器的数据,kubernetes引入了Volume的概念。
Volume是Pod中能够被多个容器访问的共享目录,它被定义在Pod上,然后被一个Pod里的多个容器挂载到具体的文件目录下。
kubernetes通过Volume实现同一个Pod中不同容器之间的数据共享以及数据的持久化存储。Volume的生命容器不与Pod中单个容器的生命周期相关,当容器终止或者重启时,Volume中的数据也不会丢失。
kubernetes的Volume支持多种类型,比较常见的有下面几个:
- 简单存储:EmptyDir、HostPath、NFS
- 高级存储:PV、PVC
- 配置存储:ConfigMap、Secret
基础存储
EmptyDir
EmptyDir是最基础的Volume类型,一个EmptyDir就是Host上的一个空目录
EmptyDir是在Pod被分配到Node时创建的,它的初始内容为空,并且无须指定宿主机上对应的目录文件,因为kubernetes会自动分配一个目录,当Pod销毁时, EmptyDir中的数据也会被永久删除。
一般用于:
- 临时空间,例如用于某些应用程序运行时所需的临时目录,且无须永久保留
- 一个容器需要从另一个容器中获取数据的目录(多容器共享目录)
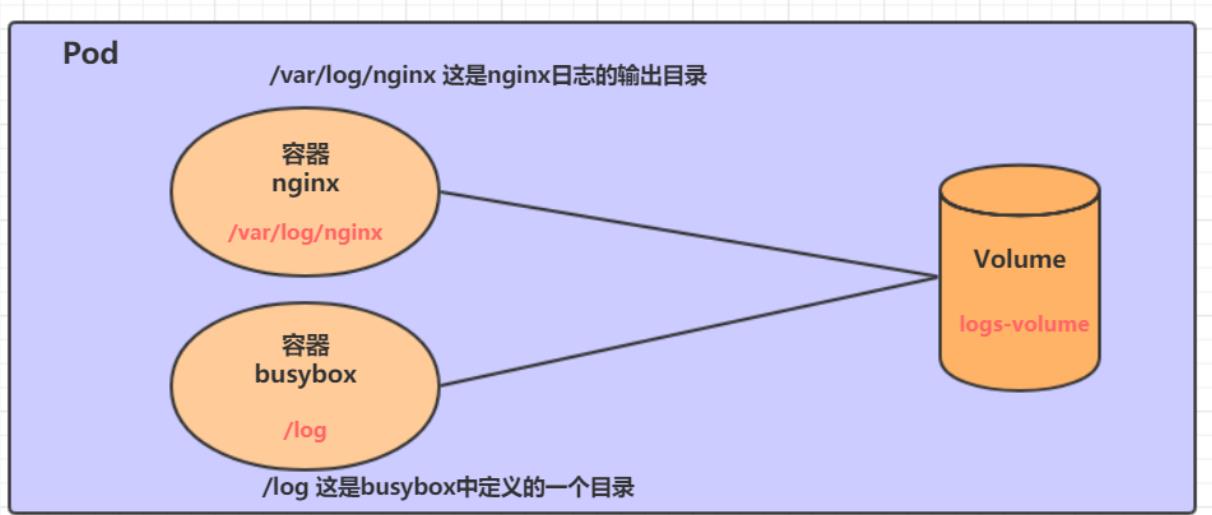
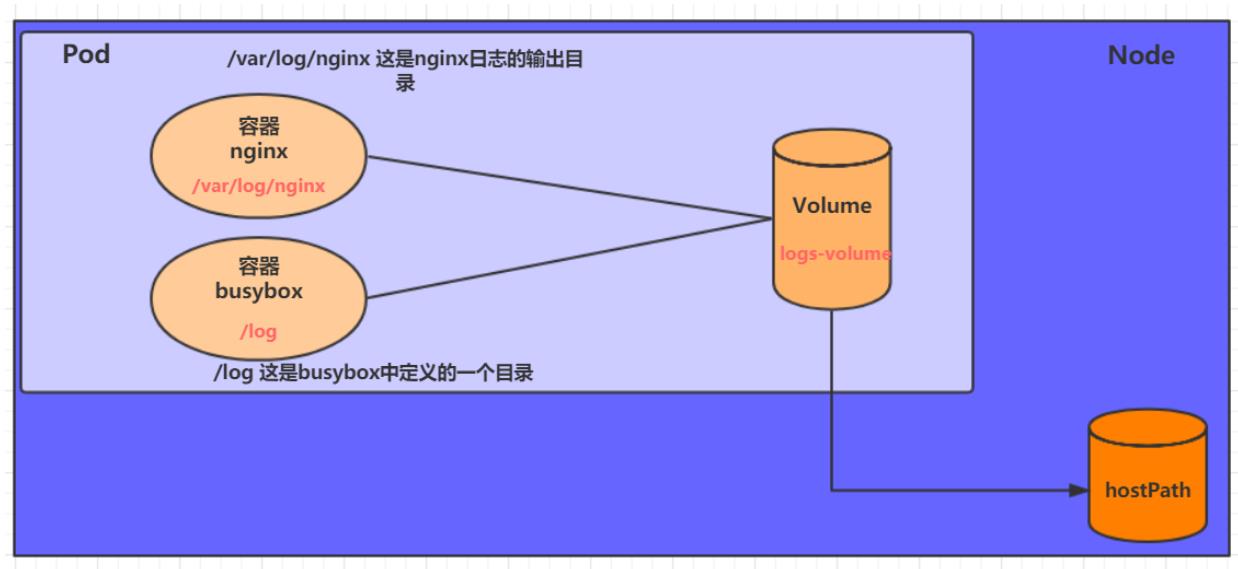
比如:
在一个Pod中准备两个容器nginx和busybox,然后声明一个Volume分别挂在到两个容器的目录中,然后nginx容器负责向Volume中写日志,busybox中通过命令将日志内容读到控制台。
HostPath
EmptyDir中数据不会被持久化,它会随着Pod的结束而销毁,如果想简单的将数据持久化到主机中,可以选择HostPath。
HostPath就是将Node主机中一个实际目录挂在到Pod中,以供容器使用,这样的设计就可以保证Pod销毁了,但是数据依据可以存在于Node主机上
跟docker的存储有点像。
NFS
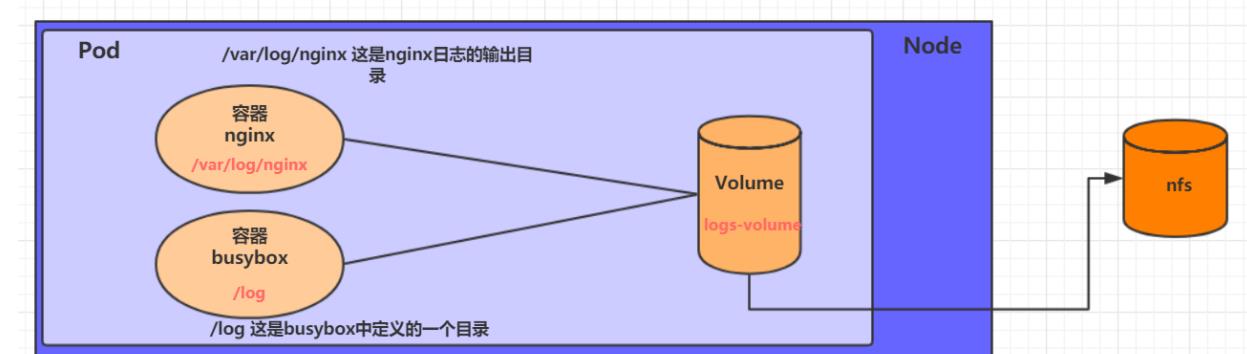
HostPath可以解决数据化持久问题,但是如果node节点故障了,pod如果转移到了别的节点,就会出现问题了。此时就需要单独的网络存储系统,比较常用的有NFS,CIFS.
NFS是一个网络文件存储系统,可以搭建一台NFS服务器,然后将Pod中的存储直接连接到NFS系统上,这样的话,无论Pod在节点上怎么转移,只要Node跟NFS的对接没问题,数据就可以成功访问。
高级存储
-
PV(Persistent Volume)是持久化卷的意思,是对底层的共享存储的一种抽象。一般情况下PV由kubernetes管理员进行创建和配置,它与底层具体的共享存储技术有关,并通过插件完成与共享存储的对接。
-
PVC(Persistent Volume Claim)是持久卷声明的意思,是用户对于存储需求的一种声明。换句话说,PVC其实就是用户向kubernetes系统发出的一种资源需求申请。
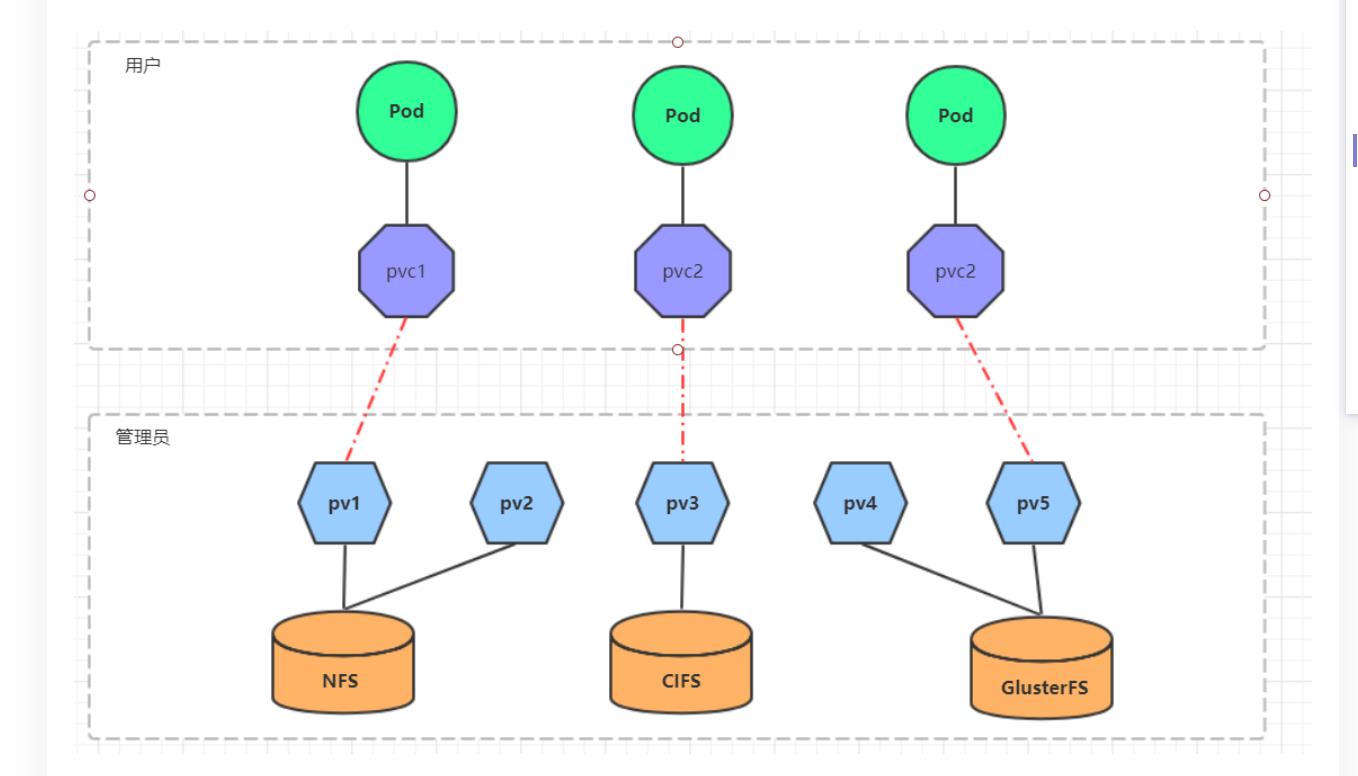
pv就是持久化卷,pvc就是命令。
使用了PV和PVC之后,工作可以得到进一步的细分:
存储:存储工程师维护
PV: kubernetes管理员维护
PVC:kubernetes用户维护
比如可以直接在一些pass上指定数据卷的大小路径等等,就是pvc,向k8s系统发起的一种资源申请。
PV
PV是存储资源的抽象
apiVersion: v1
kind: PersistentVolume
metadata:
name: pv2
spec:
nfs: # 存储类型,与底层真正存储对应
capacity: # 存储能力,目前只支持存储空间的设置
storage: 2Gi
accessModes: # 访问模式
storageClassName: # 存储类别
persistentVolumeReclaimPolicy: # 回收策略
PV 的关键配置参数说明:
- 存储类型: 底层实际存储的类型,kubernetes支持多种存储类型,每种存储类型的配置都有所差异
- 存储能力(capacity):目前只支持存储空间的设置( storage=1Gi ),不过未来可能会加入IOPS、吞吐量等指标的配置
- 访问模式(accessModes)用于描述用户应用对存储资源的访问权限
- ReadWriteOnce(RWO):读写权限,但是只能被单个节点挂载
- ReadOnlyMany(ROX): 只读权限,可以被多个节点挂载
- ReadWriteMany(RWX):读写权限,可以被多个节点挂载
- 底层不同的存储类型可能支持的访问模式不同
- 回收策略(persistentVolumeReclaimPolicy): 当PV不再被使用了之后,对其的处理方式。目前支持三种策略:
- Retain (保留) 保留数据,需要管理员手工清理数据
- Recycle(回收) 清除 PV 中的数据,效果相当于执行 rm -rf /thevolume/*
- Delete (删除) 与 PV 相连的后端存储完成 volume 的删除操作,当然这常见于云服务商的存储服务
- 底层不同的存储类型可能支持的回收策略不同
- 存储类别: PV可以通过storageClassName参数指定一个存储类别
- 状态(status)一个 PV 的生命周期中,可能会处于4中不同的阶段:
- Available(可用): 表示可用状态,还未被任何 PVC 绑定
- Bound(已绑定): 表示 PV 已经被 PVC 绑定
- Released(已释放): 表示 PVC 被删除,但是资源还未被集群重新声明
- Failed(失败): 表示该 PV 的自动回收失败
PVC
PVC是资源的申请,用来声明对存储空间、访问模式、存储类别需求信息
PVC 的关键配置参数说明:
-
访问模式(accessModes) 用于描述用户应用对存储资源的访问权限
-
选择条件(selector)通过Label Selector的设置,可使PVC对于系统中己存在的PV进行筛选
-
存储类别(storageClassName)PVC在定义时可以设定需要的后端存储的类别,只有设置了该class的pv才能被系统选出
-
资源请求(Resources )描述对存储资源的请求
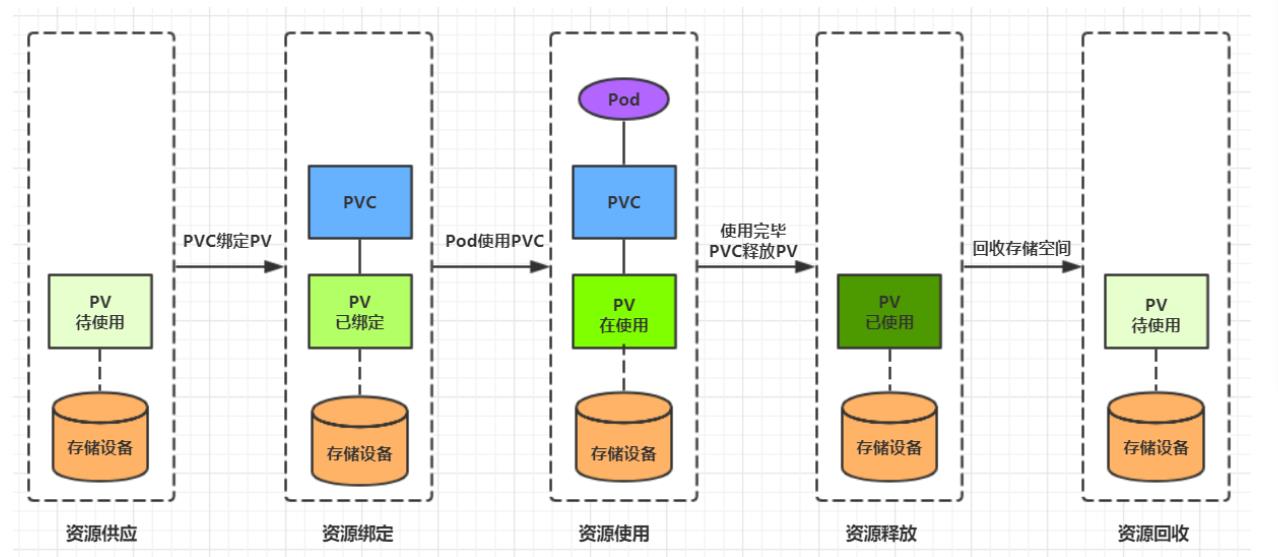
生命周期
PVC和PV是一一对应的,PV和PVC之间的相互作用遵循以下生命周期:

配置存储
ConfigMap
ConfigMap是一种比较特殊的存储卷,它的主要作用是用来存储配置信息的。
Secret
在kubernetes中,还存在一种和ConfigMap非常类似的对象,称为Secret对象。它主要用于存储敏感信息,例如密码、秘钥、证书等等。
安全认证
访问控制
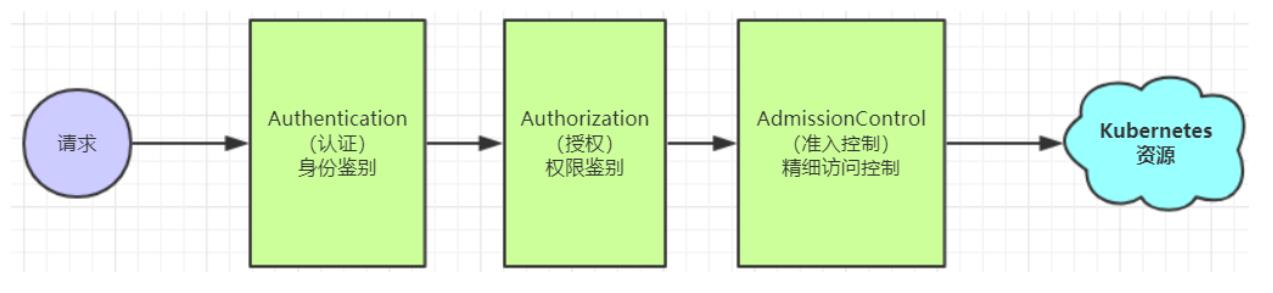
Kubernetes作为一个分布式集群的管理工具,保证集群的安全性是其一个重要的任务。所谓的安全性其实就是保证对Kubernetes的各种客户端进行认证和鉴权操作
客户端
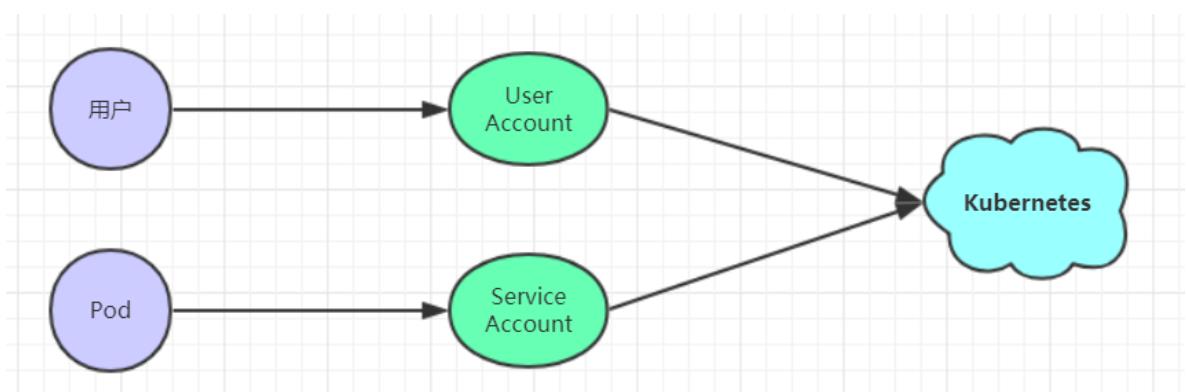
k8s集群中,客户端一般有两种:
- User Account:一般是独立于kubernetes之外的其他服务管理的用户账号。
- Service Account:kubernetes管理的账号,用于为Pod中的服务进程在访问Kubernetes时提供身份标识。
认证、授权与准入控制

认证管理
Kubernetes集群安全的最关键点在于如何识别并认证客户端身份,它提供了3种客户端身份认证方式
- HTTP Base认证:通过用户名+密码的方式认证, 这种认证方式是把“用户名:密码”用BASE64算法进行编码后的字符串放在HTTP请求中的Header Authorization域里发送给服务端。服务端收到后进行解码,获取用户名及密码,然后进行用户身份认证的过程。
- HTTP Token认证:通过一个Token来识别合法用户。 这种认证方式是用一个很长的难以被模仿的字符串–Token来表明客户身份的一种方式。每个Token对应一个用户名,当客户端发起API调用请求时,需要在HTTP Header里放入Token,API Server接到Token后会跟服务器中保存的token进行比对,然后进行用户身份认证的过程。
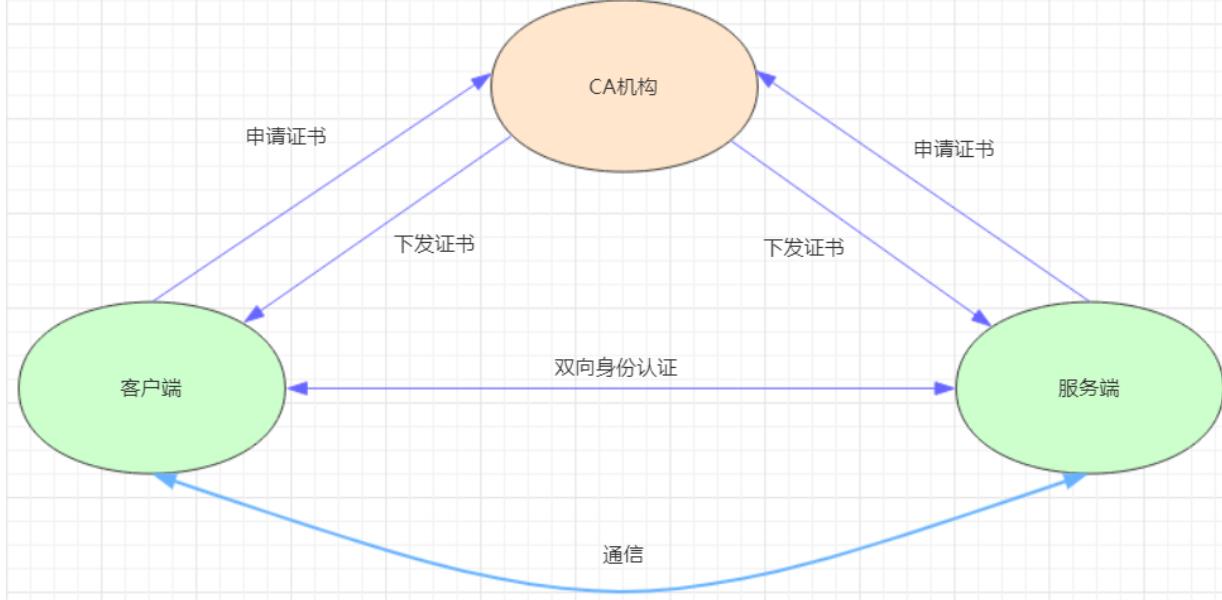
- HTTPS证书认证:基于CA根证书签名的双向数字证书认证方式,这种认证方式是安全性最高的一种方式,但是同时也是操作起来最麻烦的一种方式。
授权管理
授权发生在认证成功之后,认证只能让K8s知道你是谁,但是权限需要继续验证, Kubernetes会根据事先定义的授权策略来决定用户是否有权限访问,这个过程就称为授权。
每个发送到ApiServer的请求都带上了用户和资源的信息:比如发送请求的用户、请求的路径、请求的动作等,授权就是根据这些信息和授权策略进行比较,如果符合策略,则认为授权通过,否则会返回错误。
API Server目前支持以下几种授权策略:
- AlwaysDeny:表示拒绝所有请求,一般用于测试
- AlwaysAllow:允许接收所有请求,相当于集群不需要授权流程(Kubernetes默认的策略)
- ABAC:基于属性的访问控制,表示使用用户配置的授权规则对用户请求进行匹配和控制
- Webhook:通过调用外部REST服务对用户进行授权
- Node:是一种专用模式,用于对kubelet发出的请求进行访问控制
- RBAC:基于角色的访问控制(kubeadm安装方式下的默认选项)
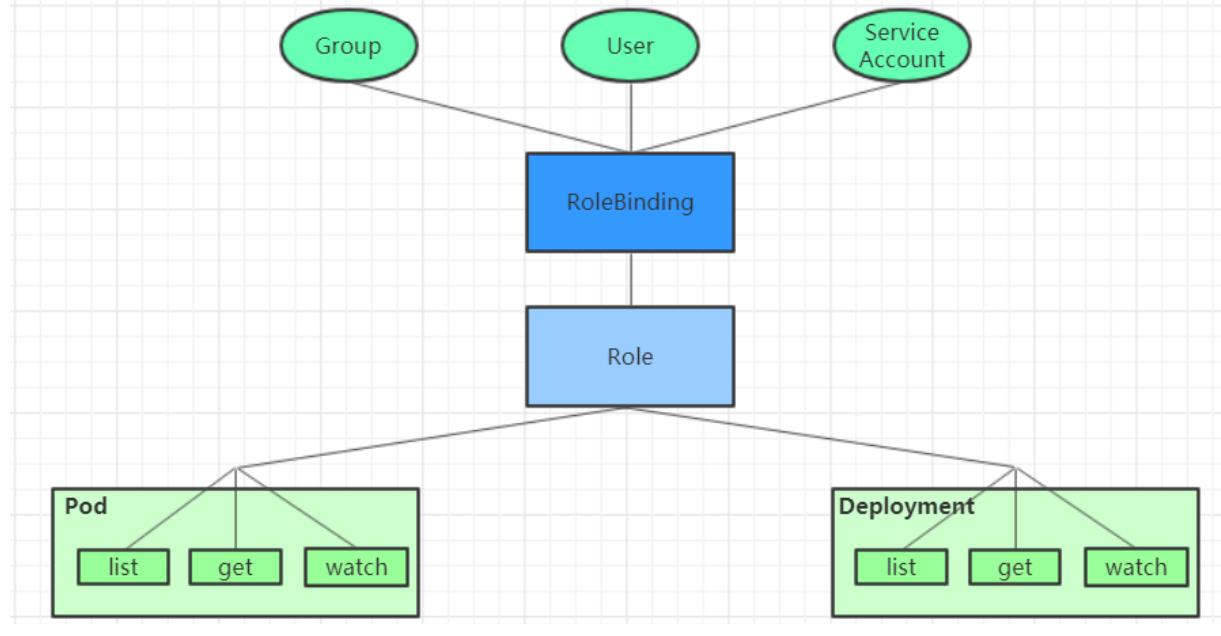
RBAC(Role-Based Access Control) 基于角色的访问控制,主要是在描述一件事情:给哪些对象授予了哪些权限
其中涉及到了下面几个概念: - 对象:User、Groups、ServiceAccount
- 角色:代表着一组定义在资源上的可操作动作(权限)的集合
- 绑定:将定义好的角色跟用户绑定在一起
9.4 准入控制
通过了前面的认证和授权之后,还需要经过准入控制处理通过之后,apiserver才会处理这个请求。
准入控制是一个可配置的控制器列表,可以通过在Api-Server上通过命令行设置选择执行哪些准入控制器
只有当所有的准入控制器都检查通过之后,apiserver才执行该请求,否则返回拒绝。
简而言之,就是k8s知道你是谁后,也知道你有权限,但还是要检查一下,才能执行请求。
DashBoard
之前在kubernetes中完成的所有操作都是通过命令行工具kubectl完成的。其实,为了提供更丰富的用户体验,kubernetes还开发了一个基于web的用户界面(Dashboard)。用户可以使用Dashboard部署容器化的应用,还可以监控应用的状态,执行故障排查以及管理kubernetes中各种资源。
部门内容转自https://www.cnblogs.com/weicunqi/p/14943115.html
笔记仅供学习使用
以上是关于k8s3 Service详解 Ingress服务 数据存储 安全认证的主要内容,如果未能解决你的问题,请参考以下文章