pandas从入门到进阶
Posted 辰chen
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了pandas从入门到进阶相关的知识,希望对你有一定的参考价值。
目录
- 一、pandas入门
- 1.pandas的安装
- 2.数据结构
- 3.数据查看
- 4.数据输入和输出
- 5.数据选择
- 6.训练场
- 二、pandas高级
- 三、pandas进阶
- 总结:pandas库的亮点
一、pandas入门

- Python在数据处理和准备方面一直做得很好,但在数据分析和建模方面就差一些。pandas帮助填补了这一空白,使您能够在Python中执行整个数据分析工作流程,而不必切换到更特定于领域的语言,如R。
- 与出色的 jupyter工具包和其他库相结合,Python中用于进行数据分析的环境在性能、生产率和协作能力方面都是卓越的。
- pandas是 Python 的核心数据分析支持库,提供了快速、灵活、明确的数据结构,旨在简单、直观地处理关系型、标记型数据。pandas是Python进行数据分析的必备高级工具。
- pandas的主要数据结构是 Series(一维数据)与 DataFrame(二维数据),这两种数据结构足以处理金融、统计、社会科学、工程等领域里的大多数案例
- 处理数据一般分为几个阶段:数据整理与清洗、数据分析与建模、数据可视化与制表,Pandas 是处理数据的理想工具。
🌟 学习本文之前,需要先自修:NumPy从入门到进阶,本文中很多的操作在 NumPy从入门到进阶 一文中有详细的介绍,包含一些软件以及扩展库,图片的安装和下载流程,本文会直接进行使用。
1.pandas的安装
🚩Windows + R,输入 cmd,输入 pip install pandas -i https://pypi.tuna.tsinghua.edu.cn/simple 下载 pandas,如果你曾跟着NumPy从入门到进阶进行学习,这一步可以省略【已经安装好了 pandas】

安装好后,进入 jupyter,运行如下代码,没有报错证明安装成功:

2.数据结构
2.1 一维结构(Series)
import pandas as pd
s = pd.Series(data = [9, 8, 7, 6], index = ['a', 'b', 'c', 'd'])
display(s)

可以看到,我们创建了索引(index)为 'a' 'b' 'c' 'd',data 为9 8 7 6的一维结构,我们还可以不指定索引(index),那么就会默认为 0 1 2 ...

一维Series和之前NumPy有何不同呢?
区别在于索引,是一一对应的,即索引也可以拥有自己的“名字”,而NumPy则是:自然索引(0 ~ n)
2.2 二维结构(DataFrame)
import pandas as pd
import numpy as np
pd.DataFrame(data = np.random.randint(0, 150, size = (5, 3)))
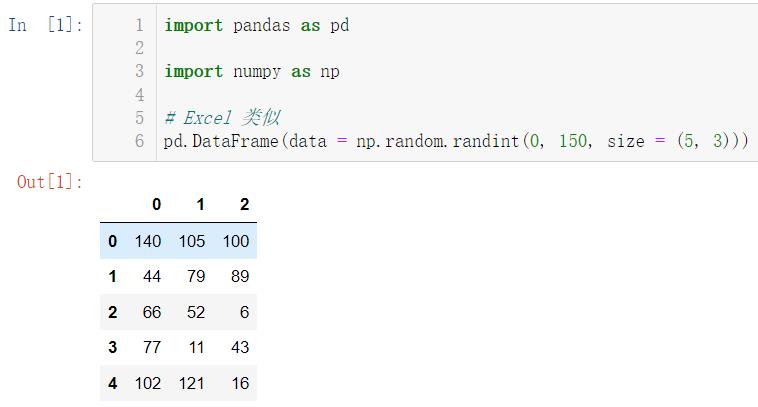
默认的行索引和列索引也都是从0开始的,我们说过,pandas可以自己定义我们的索引:
import pandas as pd
import numpy as np
# columns 用来设置列索引,index 用来设置行索引
pd.DataFrame(data = np.random.randint(0, 150, size = (5, 3)),
columns = ['Python', 'English', 'Math'], index = list('ABCDE'))
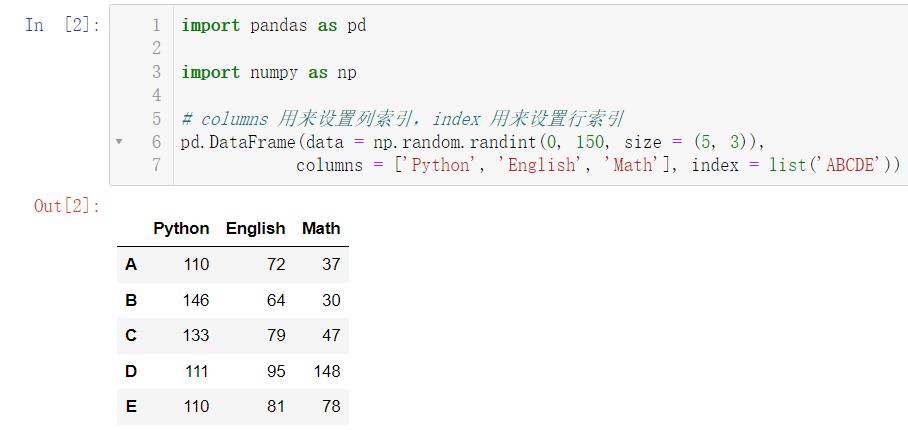
我们发现,表格中的数都是正数,我们可以用 dtype 属性设置为小数或者其他:
import pandas as pd
import numpy as np
# dtype 用来设置数的类型
pd.DataFrame(data = np.random.randint(0, 150, size = (5, 3)),
columns = ['Python', 'English', 'Math'], index = list('ABCDE'),
dtype = np.float32)
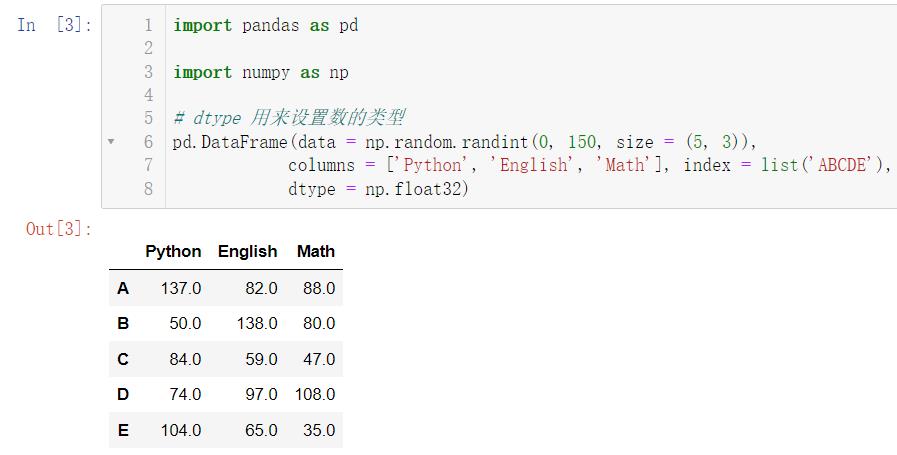
下面介绍另一种创建的方法:我们学过 Python 后,你可能会发现,在 Python 中的字典这种数据类型好像和这个特别像,故我们可以使用字典去进行创建:
import pandas as pd
import numpy as np
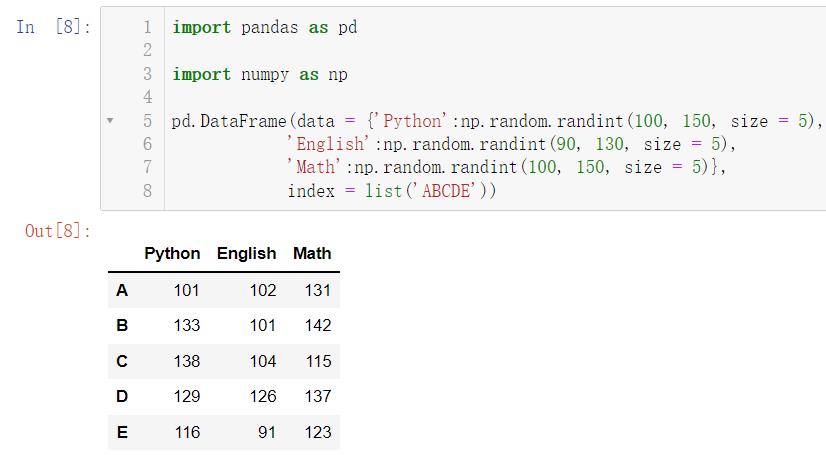
pd.DataFrame(data = 'Python':np.random.randint(100, 150, size = 5),
'English':np.random.randint(90, 130, size = 5),
'Math':np.random.randint(100, 150, size = 5))

我们设置了列索引,接下来我们来设置行索引:
import pandas as pd
import numpy as np
pd.DataFrame(data = 'Python':np.random.randint(100, 150, size = 5),
'English':np.random.randint(90, 130, size = 5),
'Math':np.random.randint(100, 150, size = 5),
index = list('ABCDE'))
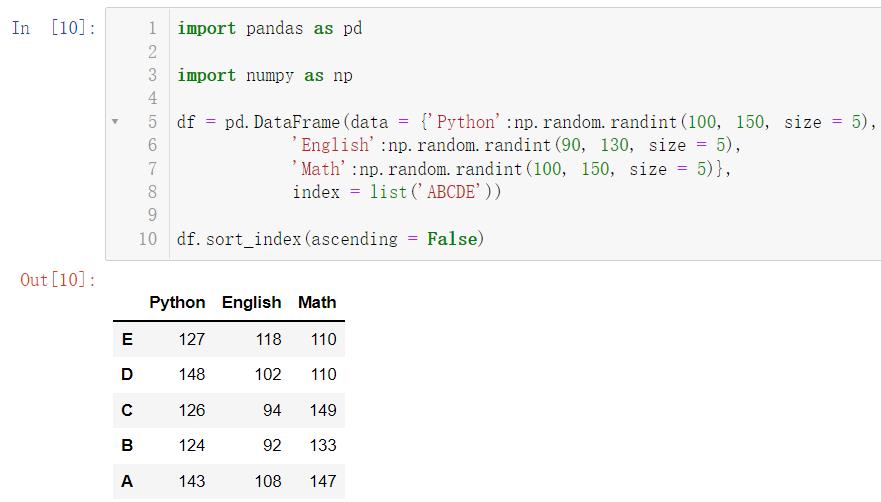
我们当然可以对其进行排序,比如我们按照行索引的大小进行降序:
import pandas as pd
import numpy as np
df = pd.DataFrame(data = 'Python':np.random.randint(100, 150, size = 5),
'English':np.random.randint(90, 130, size = 5),
'Math':np.random.randint(100, 150, size = 5),
index = list('ABCDE'))
df.sort_index(ascending = False)
3.数据查看
🚩接下来来介绍一些查看数据的方法:
import numpy as np
import pandas as pd
# 创建 shape(150, 3)的二维标签数组结构DataFrame
df = pd.DataFrame(data = np.random.randint(0, 151, size = (150, 3)),
columns = ['Python', 'English', 'Math'])
# 查看其属性、概览和统计信息
display(df.head(10)) # 显示头部10个,默认5个
display(df.tail(10)) # 查看末尾10个,默认5个
display(df.shape) # 查看形状,行数和列数
display(df.dtypes) # 查看数据类型
# 改变数据类型:
# 把 'Python' 一列的数据类型由 int32 改为 int64
df['Python'] = df['Python'].astype(np.int64)
display(df.dtypes) # 查看数据类型
display(df.index) # 查看行索引
display(df.columns) # 查看列索引

import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 151, size = (150, 3)),
columns = ['Python', 'English', 'Math'])
display(df.values) # 查看对象值(即这个二维ndarray数组)

import numpy as np
import pandas as pd
df = pd.DataFrame(data = np.random.randint(0, 151, size = (150, 3)),
columns = ['Python', 'English', 'Math'])
# 查看数值类型列的汇总统计,计数、平均值、标准差、最小值、四分位数、最大值
display(df.describe())
# 查看列索引、数据类型、非空计数和内存信息
display(df.info())

4.数据输入和输出
4.1 csv
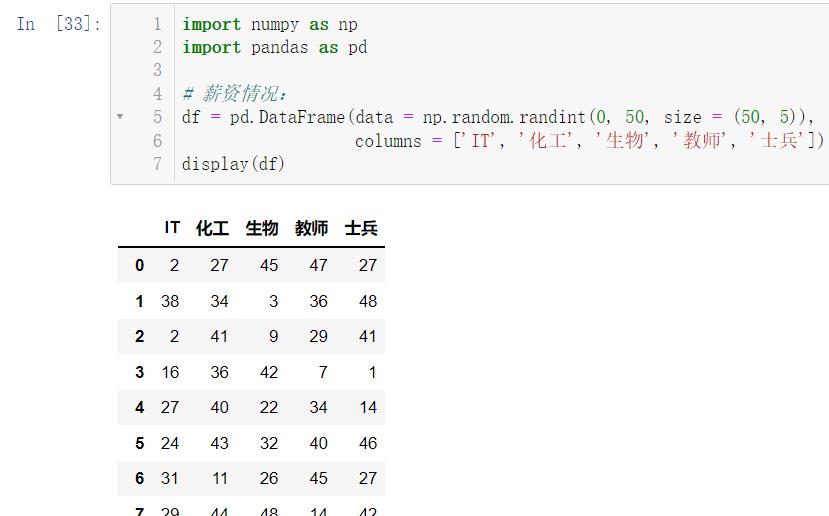
🚩我们想要存储数据,首先要创建数据:
import numpy as np
import pandas as pd
# 薪资情况:
df = pd.DataFrame(data = np.random.randint(0, 50, size = (50, 5)),
columns = ['IT', '化工', '生物', '教师', '士兵'])
display(df)
import numpy as np
import pandas as pd
# 薪资情况:
df = pd.DataFrame(data = np.random.randint(0, 50, size = (50, 5)),
columns = ['IT', '化工', '生物', '教师', '士兵'])
display(df)
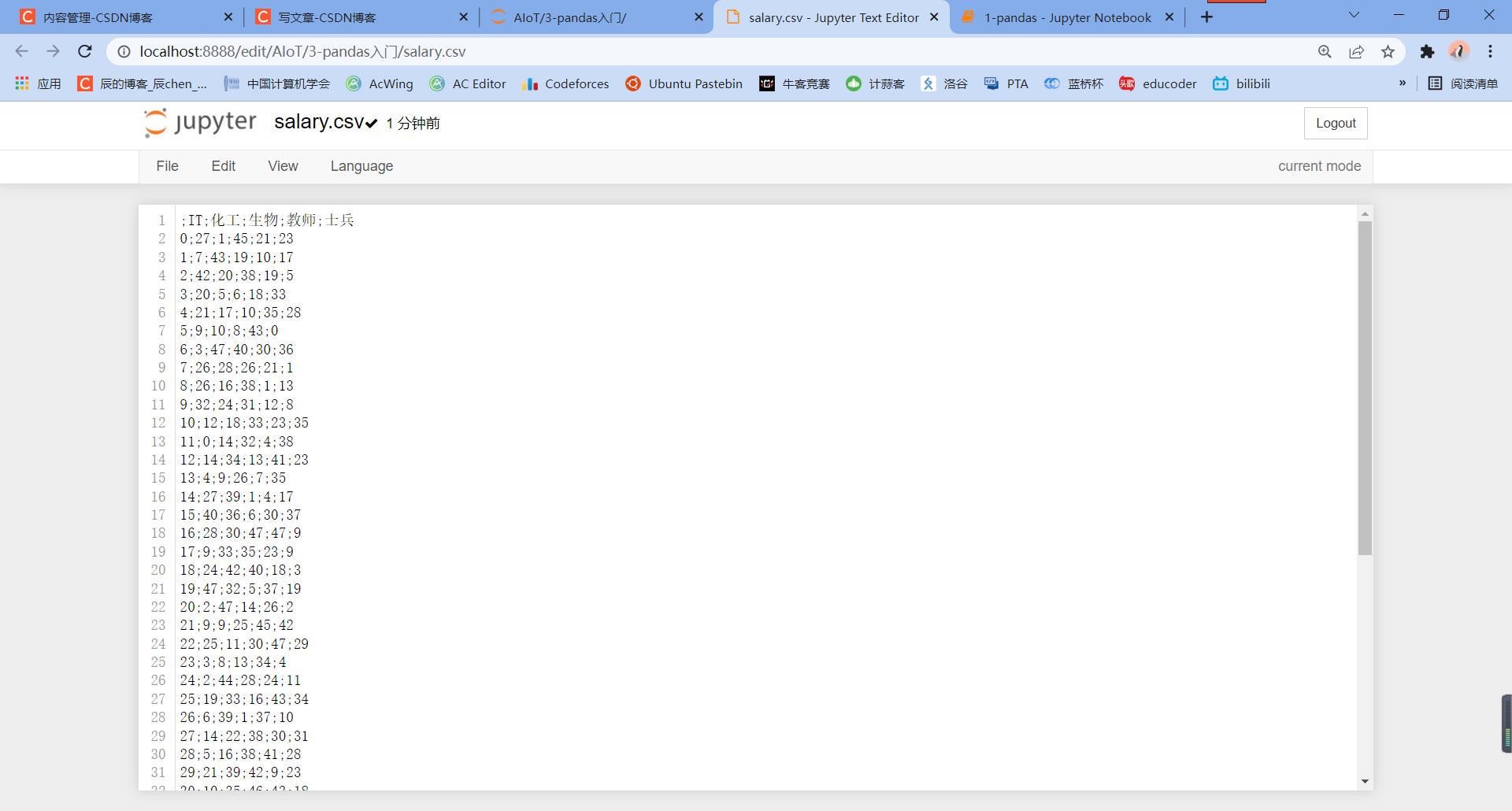
# 保存到当前路径下,文件名是:salary.csv
df.to_csv('./salary.csv',
sep = ';', # 文本分隔符,默认是逗号
header = True, # 是否保存列索引
index = True) # 是否保存行索引
# 保存行索引,文件被加载时,默认行索引会作为一列

点击该文件就可以查看保存的数据信息:
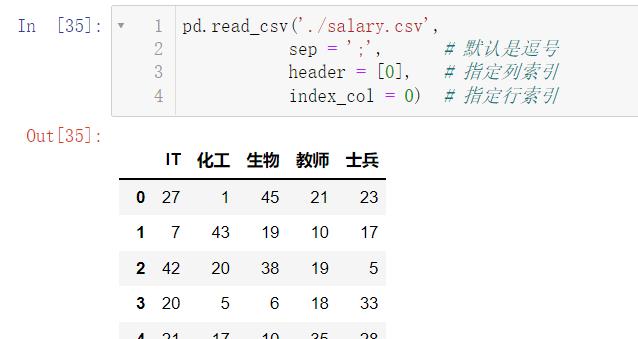
能保存数据自然就有加载数据的操作:
pd.read_csv('./salary.csv',
sep = ';', # 默认是逗号
header = [0], # 指定列索引
index_col = 0) # 指定行索引
4.2 Excel
🚩如果要保存为 Excel 文件,我们需要装两个库:
pip install xlrd -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install xlwt -i https://pypi.tuna.tsinghua.edu.cn/simple
按下 Windows + R,输入 cmd,然后输入上述两行,如果你曾跟着NumPy从入门到进阶进行学习,这一步可以省略
import numpy as np
import pandas as pd
df1 = pd.DataFrame(data = np.random.randint(0, 50, size = [50,5]), # 薪资情况
columns = ['IT', '化工', '生物', '教师', '士兵'])
# 保存到当前路径下,文件命名是:salary.xlsx
df1.to_excel('./salary.xlsx',
sheet_name = 'salary',# Excel中工作表的名字
header = True, # 是否保存列索引
index = False) # 是否保存行索引
这样我们就保存了 df1 的数据,并把文件存到了当前目录下:

注意这个文件我们在 jupyter 上是无法打开的,但是我们可以在文件管理中找到并打开:
接下来我们来读取这个文件:
pd.read_excel('./salary.xlsx',
sheet_name = 0, # 读取哪一个Excel中工作表,默认第一个
header = 0) # 使用第一行数据作为列索引

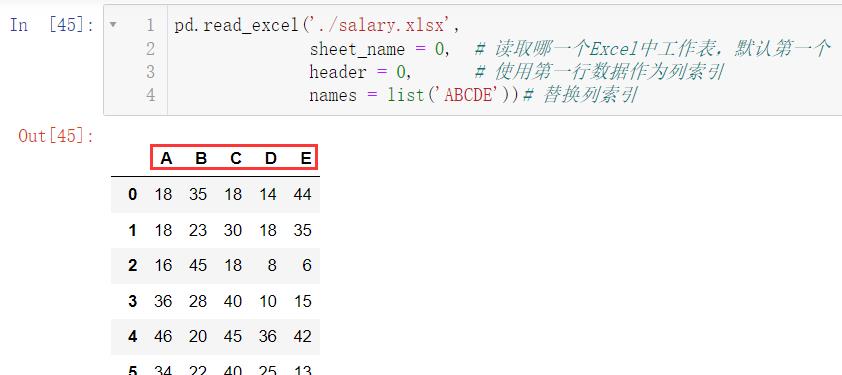
我们还可以替换列索引,比如我们把列索引替换为 ABCDE
pd.read_excel('./salary.xlsx',
sheet_name = 0, # 读取哪一个Excel中工作表,默认第一个
header = 0, # 使用第一行数据作为列索引
names = list('ABCDE'))# 替换列索引
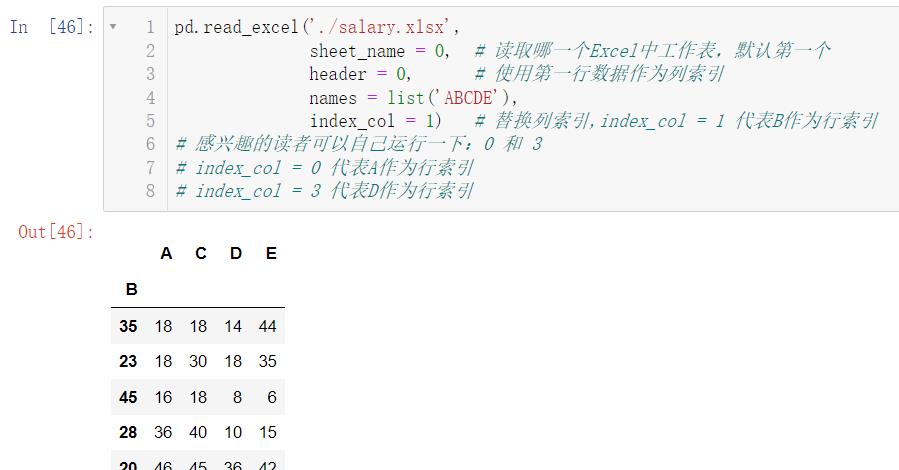
我们还可以指定行索引:
pd.read_excel('./salary.xlsx',
sheet_name = 0, # 读取哪一个Excel中工作表,默认第一个
header = 0, # 使用第一行数据作为列索引
names = list('ABCDE'),
index_col = 1) # 替换列索引,index_col = 1 代表B作为行索引
# 感兴趣的读者可以自己运行一下:0 和 3
# index_col = 0 代表A作为行索引
# index_col = 3 代表D作为行索引
我们打开我们的 Excel 表格:
可以看到只有一个工作表,我们如果现在想再创建一个工作表用来存储其他数据,可以按下述操作:
# 创建一组新的数据:
# 计算机科目的考试成绩
df2 = pd.DataFrame(data = np.random.randint(0, 50, size = [150, 3]),
columns=['Python', 'Tensorflow', 'Keras'])
df2.to_excel('./salary.xlsx',
sheet_name = 'test',# Excel中工作表的名字
header = True,# 是否保存列索引
index = False) # 是否保存行索引,保存行索引
我们再来查看一下我们的文件:
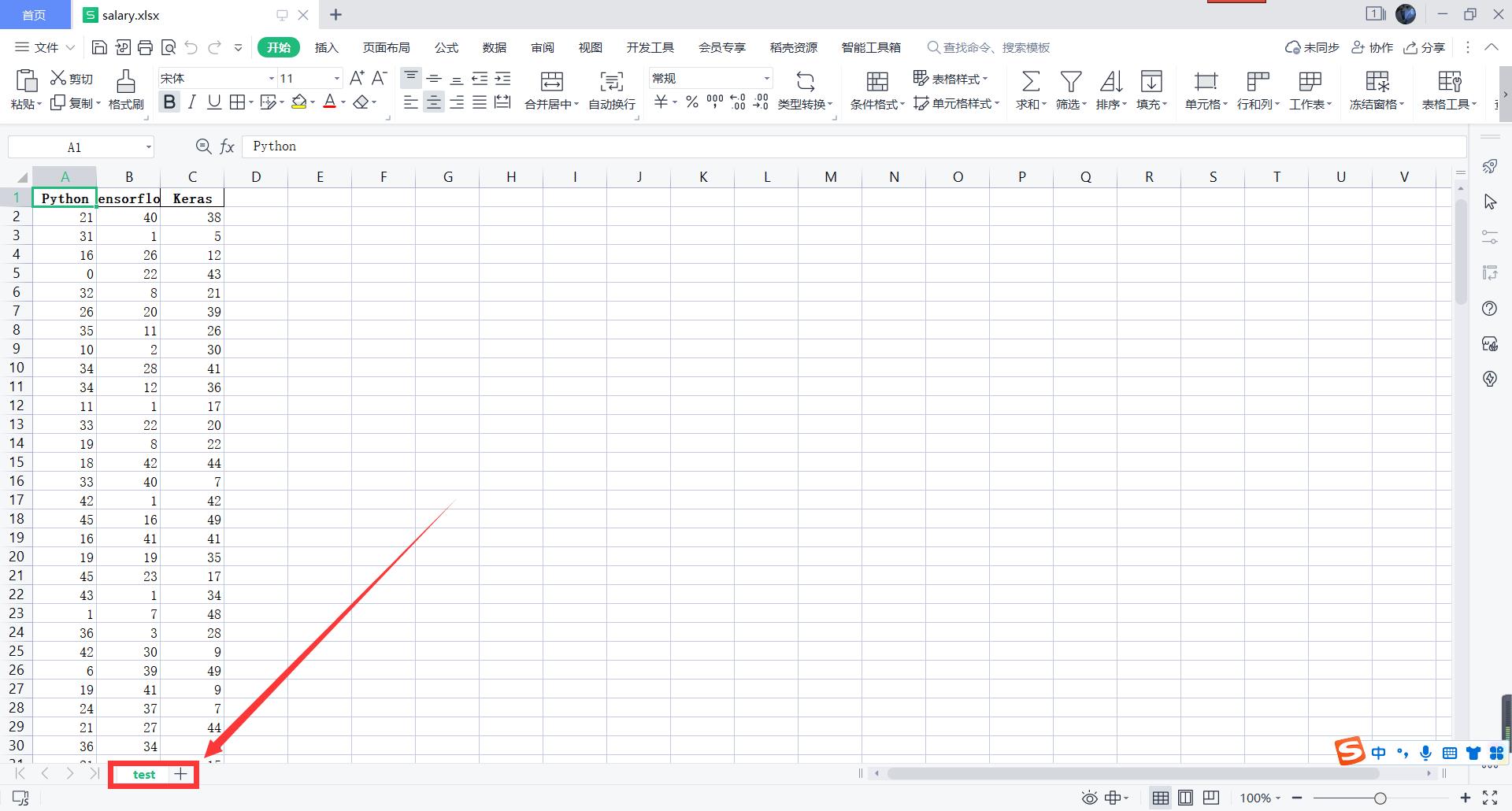
发现并没有实现我们预期的结果,下面来正式介绍一下如何操作:
# 一个Excel文件中保存多个工作表
with pd.ExcelWriter('./data.xlsx') as writer:
df1.to_excel(writer,sheet_name = 'salary', index = False)
df2.to_excel(writer,sheet_name = 'score', index = False)

这样就实现了我们的存入操作,接下来还是读取的操作:
读取 salary:
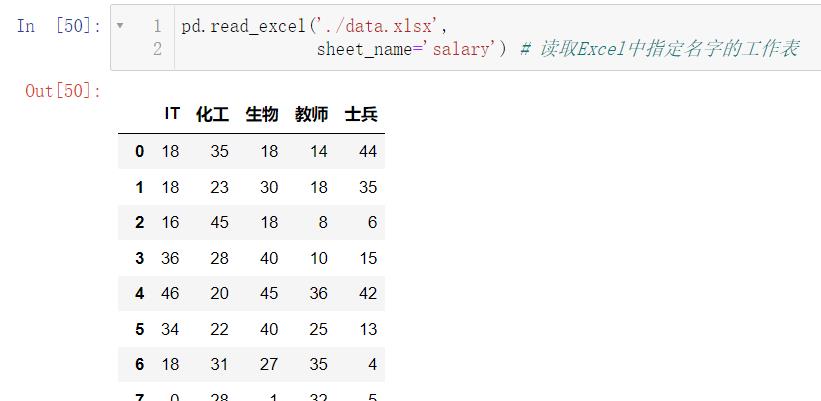
pd.read_excel('./data.xlsx',
sheet_name='salary') # 读取Excel中指定名字的工作表
读取 score:
pd.read_excel('./data.xlsx',
sheet_name='score') # 读取Excel中指定名字的工作表

5.数据选择
5.1 字段数据
5.1.1 列的获取
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0, 150, size = (1000, 3)),
columns = ['Python', 'English', 'Math'])
display(df)
# 获取 Python 一列的数据
# 方法一
display(df['Python'])
# 方法二
display(df.Python)
# 获取两列数据
display(df[['Python', 'Math']])

再来对比两个写法:同样是获得一列的数据,不同的写法对应的运行表现不同:
display(df['Python'])
display(df[['Python']])

5.1.2 行的获取
import numpy as np
import pandas as pd
df = pd.DataFrame(np.random.randint(0, 150, size = (5, 3)),
index = list('ABCDE'),
columns = ['Python', 'English', 'Math'])
# 获取 Python 一行的数据
display(df.loc['A'])
# 获取 两行的数据
display(df.loc[['A', 'C']])

还有一种获取方法:
display(df.iloc[0]) # 按数字去获取,0就是对应'A'
display(df.iloc[[0, 2]]) # 获取的是 'A' 和 'C'

5.1.3 数值的获取
我们介绍了获取行和获取列,现在我们来介绍获取固定行固定列的元素:
# 获取第 B 行,第 Math 列的值<以上是关于pandas从入门到进阶的主要内容,如果未能解决你的问题,请参考以下文章