2022 年10 大 Python 库,数据科学家必备神器
Posted simplilearn圣普伦
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2022 年10 大 Python 库,数据科学家必备神器相关的知识,希望对你有一定的参考价值。
Python 是当今使用最广泛的编程语言之一,大多数数据科学家每天都在用Python进行数据分析,这10个Python库是数据科学家几乎每天都用到的,在线认证培训课程专家|圣普伦和大家分享一下。
数据科学常用的10大Python库
1. TensorFlow
TensorFlow是一个端到端开源机器学习平台,活跃贡献者1500多名。它拥有一个全面而灵活的生态系统,其中包含各种工具、库和社区资源,可助力研究人员推动先进机器学习技术。

特征:
- 更好的计算图可视化
- 将神经机器学习中的错误减少 50% 到 60%
- 并行计算以执行复杂模型
- 由 Google 支持的无缝图书馆管理
- 迭代更快频繁,常常更新最新功能
TensorFlow 对于以下应用程序特别有用:
- 语音和图像识别
- 基于文本的应用程序
- 时间序列分析
- 视频检测
2. SciPy
SciPy (Scientific Python) 是另一个用于数据科学的免费和开源的 Python 库,广泛用于高级计算。SciPy 在 GitHub 上有大约 19,000 条评论,并拥有一个由大约 600 名贡献者组成的活跃社区。

特征:
- 基于 Python 的 NumPy 扩展构建的算法和函数的集合
- 用于数据操作和可视化的高级命令
- 使用 SciPy ndimage 子模块进行多维图像处理
- 包括用于求解微分方程的函数
应用:
- 多维图像操作
- 求解微分方程和傅里叶变换
- 优化算法
- 线性代数
3. NumPy
NumPy (Numerical Python) 是 Python 中数值计算的基础包;它包含一个强大的 N 维数组对象。它在 GitHub 上有大约 18,000 条评论和一个由 700 名贡献者组成的活跃社区。

NumPy可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效得多(该结构也可以用来表示矩阵(matrix)),支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库。
特征:
- 为数值例程提供快速的预编译函数
- 提高面向阵列的计算效率
- 支持面向对象的方法
- 使用矢量化进行更快速的计算
应用:
- 广泛用于数据分析
- 创建强大的 N 维数组
- 构成其他库的基础,例如 SciPy 和 scikit-learn
4. Pandas
Pandas(Python 数据分析)是数据科学生命周期中的必备工具,它是数据科学中最流行和使用最广泛的 Python 库之一。在 GitHub 上有大约 17,00 条评论和一个由 1,200 名贡献者组成的活跃社区,它被大量用于数据分析和数据清理。Pandas 提供快速、灵活的数据结构,旨在帮助用户轻松直观地处理结构化数据。

特征:
- 丰富的语法和功能,让用户可以自由地处理丢失的数据
- 能够帮助创建自己的函数并在一系列数据中运行它
- 包含高级数据结构和操作工具
- 可以从各种文件格式比如 CSV、JSON、SQL、Microsoft Excel 导入数据
- 可以对各种数据进行运算操作,比如归并、再成形、选择,还有数据清洗和数据加工特征
应用:
- 通用数据整理和数据清洗
- 用于数据转换和数据存储的 ETL(提取、转换、加载)作业,因为它非常支持将 CSV 文件加载到其数据帧格式中
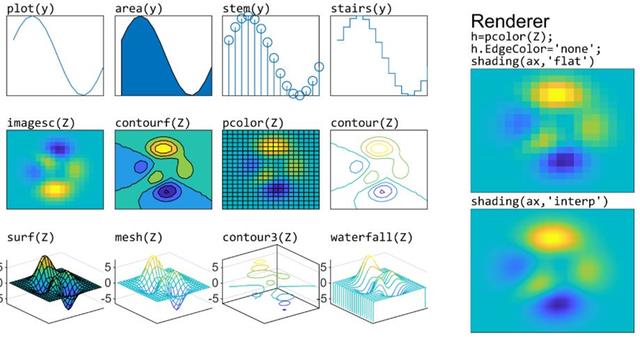
5. Matplotlib
Matplotlib 是 Python 中最受欢迎的数据可视化软件包之一,支持跨平台运行,它是 Python 常用的 2D 绘图库,同时它也提供了一部分 3D 绘图接口。Matplotlib 通常与 NumPy、Pandas 一起使用,是数据分析中不可或缺的重要工具之一,可视化效果绝佳,它还提供了一个面向对象的 API,可用于将这些绘图嵌入到应用程序中。
特征:
- 具有免费和开源的优势
- 支持数十种后端和输出格式类型
- Pandas本身可以用作 MATLAB API 的包装器
- 更低内存能
应用:
- 数据可视化,帮助用户获得数据洞察力
- 变量的相关性分析
- 使用散点图进行异常值检测
6. Keras
Keras是一个由Python编写的开源人工神经网络库,可以作为Tensorflow、Microsoft-CNTK和Theano的高阶应用程序接口,进行深度学习模型的设计、调试、评估、应用和可视化。
它与 TensorFlow 类似,是另一个广泛用于深度学习和神经网络模块的流行库,同时支持 TensorFlow 和 Theano 后端,因此如果你觉得了解TensorFlow的细节好麻烦,Keras会是一个不错的选择。

特征:
Keras 提供了大量的预标记数据集,可直接导入和加载
它包含各种层和参数,可用于神经网络的构建、配置、训练和评估
应用:
Keras最重要的应用之一是具有预训练权重的深度学习模型。你可以直接使用这些模型进行预测或提取其特征,无需创建或训练自己的新模型。
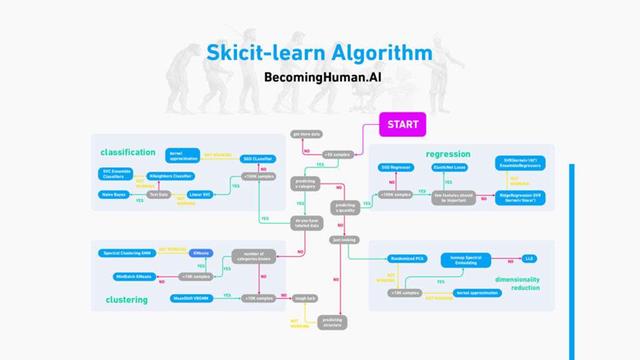
7. Scikit-learn
它是一个机器学习库,提供了几乎所有的机器学习算法,它具有各种分类,回归和聚类算法,包括支持向量机,随机森林,梯度提升,k均值和DBSCAN,并且旨在与Python数值科学库NumPy和SciPy联合使用。
应用:
- 聚类
- 分类
- 回归
- 型号选择
- 降维
8. PyTorch
它是一个基于Python的可续计算包,提供两个高级功能:1、具有强大的GPU加速的张量计算(如NumPy)。2、包含自动求导系统的深度神经网络。PyTorch 是最常用的深度学习研究平台之一,提供最大的灵活性和速度。

应用:
- PyTorch 以提供两个最高级别的功能而闻名
- 具有强大 GPU 加速支持的张量计算
- 在基于磁带的 autograd 系统上构建深度神经网络
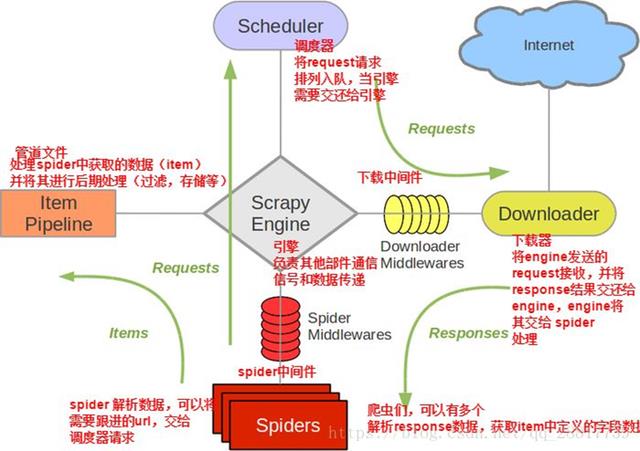
9. Scrapy
Scrapy 是用 Python 编写的最流行的、快速的、开源的网络爬虫框架之一。它通常用于借助基于 XPath 的选择器从网页中提取数据。
应用:
- Scrapy 有助于构建可以从网络检索结构化数据的爬虫程序(蜘蛛机器人)
- Scrappy 还用于从 API 收集数据,并在其界面设计中遵循“不要重复自己”的原则,帮助用户编写可用于构建和扩展大型爬虫的通用代码。
10. BeautifulSoup
BeautifulSoup是一个可以从html或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.BeautifulSoup会帮你节省数小时甚至数天的工作时间。BeautifulSoup以网络爬取和数据抓取而闻名。
用户可以在没有适当的 CSV 或 API 的情况下收集某些网站上可用的数据,BeautifulSoup 可以帮助他们抓取这些数据并将其排列成所需的格式。
以上是关于2022 年10 大 Python 库,数据科学家必备神器的主要内容,如果未能解决你的问题,请参考以下文章
2022年Python+大数据学习路线图 内附「路线+视频」