d2l自动微分练习
Posted 量子智能龙哥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了d2l自动微分练习相关的知识,希望对你有一定的参考价值。
课后题
- 1. 为什么计算二阶导数比一阶导数的开销要更大?
- 2. 在运行反向传播函数之后,立即再次运行它,看看会发生什么。
- 3. 在控制流的例子中,我们计算`d`关于`a`的导数,如果我们将变量`a`更改为随机向量或矩阵,会发生什么?
- 4. 重新设计一个求控制流梯度的例子,运行并分析结果。
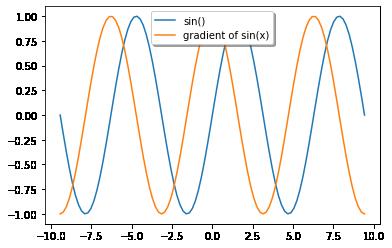
- 5. 使 f ( x ) = sin ( x ) f(x)=\\sin(x) f(x)=sin(x),绘制 f ( x ) f(x) f(x)和 d f ( x ) d x \\fracdf(x)dx dxdf(x)的图像,其中后者不使用 f ′ ( x ) = cos ( x ) f'(x)=\\cos(x) f′(x)=cos(x)。
1. 为什么计算二阶导数比一阶导数的开销要更大?
简单来说就是会造成梯度维数的增大,标量对向量的求导是一个向量,在此基础上再对向量求导就会变成一个矩阵,进一步的会变成张量。
2. 在运行反向传播函数之后,立即再次运行它,看看会发生什么。
运行时异常,之前的结果已经被释放,而且给出了提示,说要使用retain_graph=True就能够保证结果不被释放。
RuntimeError: Trying to backward through the graph a second time, but the saved intermediate results have already been freed. Specify retain_graph=True when calling backward the first time.
3. 在控制流的例子中,我们计算d关于a的导数,如果我们将变量a更改为随机向量或矩阵,会发生什么?
RuntimeError: grad can be implicitly created only for scalar outputs
梯度的计算只针对标量,然后如果是向量则先使用sum()然后再进行计算梯度。
4. 重新设计一个求控制流梯度的例子,运行并分析结果。
待讨论。
5. 使 f ( x ) = sin ( x ) f(x)=\\sin(x) f(x)=sin(x),绘制 f ( x ) f(x) f(x)和 d f ( x ) d x \\fracdf(x)dx dxdf(x)的图像,其中后者不使用 f ′ ( x ) = cos ( x ) f'(x)=\\cos(x) f′(x)=cos(x)。
%matplotlib inline
import matplotlib.pylab as plt
from matplotlib.ticker import FuncFormatter, MultipleLocator
import numpy as np
# 让x打满区间,事实上是创建了-3π到3π的100个点
x = np.linspace(-3 * np.pi,3 * np.pi,100)
# 构建一个tensor,存放梯度,存放中间结果
x1= torch.tensor(x, requires_grad=True)
# 定义函数y
y = torch.sin(x1)
y.sum().backward()
x1.grad
# 在此已经得出了x的对应的点的导数值
# 现在开始画出图像
f,ax=plt.subplots(1)
# 画出sin
ax.plot(x,np.sin(x),label="sin()")
# 画出sin的梯度
ax.plot(x,x1.grad,label="gradient of sin(x)")
# 设置标签
ax.legend(loc='upper center', shadow=True)
plt.show()
以上是关于d2l自动微分练习的主要内容,如果未能解决你的问题,请参考以下文章