ElasticSearch自定义pinyin和ik分词库
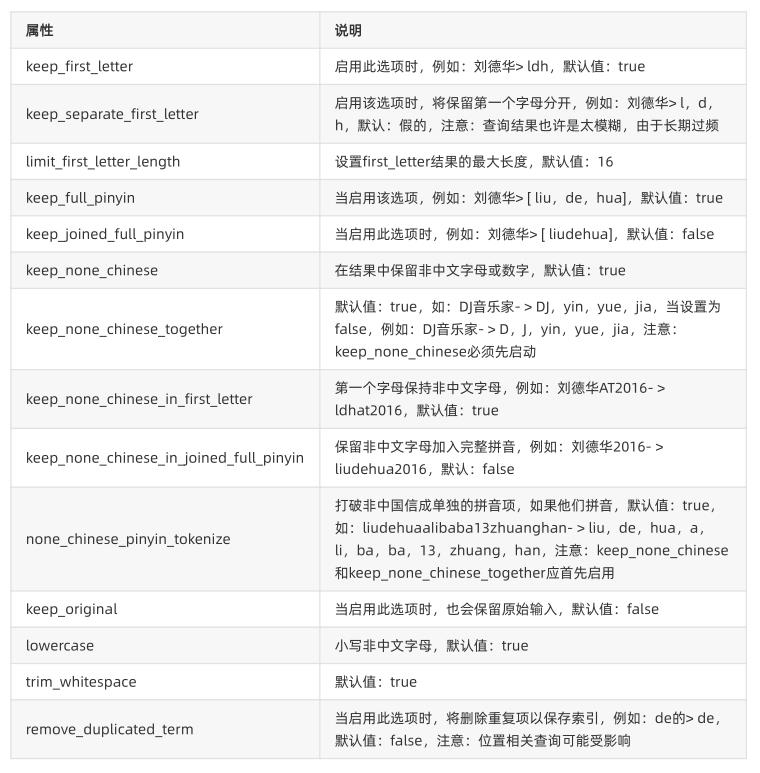
Posted 赵广陆
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了ElasticSearch自定义pinyin和ik分词库相关的知识,希望对你有一定的参考价值。
目录
1 语料库映射OpenAPI
环境准备:
- 先下载ik分词和pinyin分词,并放到esplugins相应目录中
请求kibana:GET /_cat/plugins?v&s=component&h=name,component,version,description
结果
name component version description
WIN-A5KARTU1A65 analysis-ik 7.10.1 IK Analyzer for Elasticsearch
WPhvS8c analysis-pinyin 7.10.1 Pinyin Analysis for Elasticsearch
- 定义ik分词后的pinyin分词器,即定义一个自定义分词器ik_pinyin_analyzer
PUT test_index
"settings":
"number_of_shards":"1",
"index.refresh_interval":"15s",
"index":
"analysis":
"analyzer":
"ik_pinyin_analyzer":
"type":"custom",
"tokenizer":"ik_smart",
"filter":"pinyin_filter"
,
"filter":
"pinyin_filter":
"type":"pinyin",
"keep_first_letter": false
下面的目的就是用API实现这种效果
这里tokenizer使用ik分词,分词之后将分词结果通过pinyin再filter一次,这样就可以了。

测试一下
POST test_index/_analyze
"analyzer": "ik_pinyin_analyzer",
"text":"测试"
结果
"tokens": [
"token": "ce",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 0
,
"token": "shi",
"start_offset": 0,
"end_offset": 2,
"type": "CN_WORD",
"position": 1
]
这样,当我们建立index的mapping的时候,就可以像使用ik_smart分词器一样使用ik_pinyin_analyzer
比如lawbasis字段的mapping可以是这样的
PUT test_index/_mapping/test_type
"properties":
"lawbasis":
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart",
"fields":
"my_pinyin":
"type":"text",
"analyzer": "ik_pinyin_analyzer",
"search_analyzer": "ik_pinyin_analyzer"
其中field满足以不同的目的以不同的方式为相同的字段编制索引,也就是说lawbasis这个field会以中文ik_smart分词以及分词后的pinyin分词来编制索引,并支持中文和拼音搜索。
- 测试一下
加入两条数据
POST test_index/test_type
"lawbasis":"测试一下"
POST test_index/test_type
"lawbasis":"测试东西"
使用拼音搜索
GET test_index/test_type/_search
"query":
"match":
"lawbasis.my_pinyin": "ceshi"
可以看到有两条结果
1.1 定义索引(映射)接口
package com.oldlu.service;
import com.oldlu.commons.pojo.CommonEntity;
import org.elasticsearch.rest.RestStatus;
import java.util.List;
import java.util.Map;
/**
* @Class: ElasticsearchIndexService
* @Package com.oldlu.service
* @Description: 索引操作接口
* @Company: oldlu
*/
public interface ElasticsearchIndexService
//新增索引+映射
boolean addIndexAndMapping(CommonEntity commonEntity) throws Exception;
1.2 定义索引(映射)实现
/**
* @Class: ElasticsearchIndexServiceImpl
* @Package com.oldlu.service.impl
* @Description: 索引操作实现类
* @Company: oldlu
*/
@Service("ElasticsearchIndexServiceImpl")
public class ElasticsearchIndexServiceImpl implements ElasticsearchIndexService
@Resource
private RestHighLevelClient client;
private static final int START_OFFSET = 0;
private static final int MAX_COUNT = 5;
/*
* @Description: 新增索引+setting+映射+自定义分词器pinyin
* setting可以为空(自定义分词器pinyin在setting中)
* 映射可以为空
* @Method: addIndexAndMapping
* @Param: [commonEntity]
* @Update:
* @since: 1.0.0
* @Return: boolean
*
*/
public boolean addIndexAndMapping(CommonEntity commonEntity) throws
Exception
//设置setting的map
Map<String, Object> settingMap = new HashMap<String, Object>();
//创建索引请求
CreateIndexRequest request = new
CreateIndexRequest(commonEntity.getIndexName());
//获取前端参数
Map<String, Object> map = commonEntity.getMap();
//循环外层的settings和mapping
for (Map.Entry<String, Object> entry : map.entrySet())
if ("settings".equals(entry.getKey()))
if (entry.getValue() instanceof Map && ((Map)
entry.getValue()).size() > 0)
request.settings((Map<String, Object>) entry.getValue());
if ("mapping".equals(entry.getKey()))
if (entry.getValue() instanceof Map && ((Map)
entry.getValue()).size() > 0)
request.mapping((Map<String, Object>) entry.getValue());
//创建索引操作客户端
IndicesClient indices = client.indices();
//创建响应对象
CreateIndexResponse response = indices.create(request,
RequestOptions.DEFAULT);
//得到响应结果
return response.isAcknowledged();
1.3 新增控制器
package com.oldlu.controller;
import com.oldlu.commons.enums.ResultEnum;
import com.oldlu.commons.enums.TipsEnum;
import com.oldlu.commons.pojo.CommonEntity;
import com.oldlu.commons.result.ResponseData;
import com.oldlu.service.ElasticsearchIndexService;
import org.apache.commons.lang.StringUtils;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.*;
/**
* @Class: ElasticsearchIndexController
* @Package com.oldlu.controller
* @Description: 索引操作控制器
* @Company: oldlu
*/
@RestController
@RequestMapping("v1/indices")
public class ElasticsearchIndexController
private static final Logger logger = LoggerFactory
.getLogger(ElasticsearchIndexController.class);
@Autowired
ElasticsearchIndexService elasticsearchIndexService;
/*
* @Description: 新增索引、映射
* @Method: addIndex
* @Param: [commonEntity]
* @Update:
* @since: 1.0.0
* @Return: com.oldlu.commons.result.ResponseData
*
*/
@PostMapping(value = "/add")
public ResponseData addIndexAndMapping(@RequestBody CommonEntity
commonEntity)
//构造返回数据
ResponseData rData = new ResponseData();
if (StringUtils.isEmpty(commonEntity.getIndexName()))
rData.setResultEnum(ResultEnum.PARAM_ISNULL);
return rData;
//增加索引是否成功
boolean isSuccess = false;
try
//通过高阶API调用增加索引方法
isSuccess =
elasticsearchIndexService.addIndexAndMapping(commonEntity );
//构建返回信息通过类型推断自动装箱(多个参数取交集)
rData.setResultEnum(isSuccess, ResultEnum.SUCCESS, 1);
//日志记录
logger.info(TipsEnum.CREATE_INDEX_SUCCESS.getMessage());
catch (Exception e)
//日志记录
logger.error(TipsEnum.CREATE_INDEX_FAIL.getMessage(), e);
//构建错误返回信息
rData.setResultEnum(ResultEnum.ERROR);
return rData;
1.4 开始新增映射
http://172.17.0.225:8888/v1/indices/add
或者
http://127.0.0.1:8888/v1/indices/add
参数
自定义分词器ik_pinyin_analyzer(ik和pinyin组合分词器)
tips 在创建映射前,需要安装拼音插件
"indexName": "product_completion_index",
"map":
"settings":
"number_of_shards": 1,
"number_of_replicas": 2,
"analysis":
"analyzer":
"ik_pinyin_analyzer":
"type": "custom",
"tokenizer": "ik_smart",
"filter": "pinyin_filter"
,
"filter":
"pinyin_filter":
"type": "pinyin",
"keep_first_letter": true,
"keep_separate_first_letter": false,
"keep_full_pinyin": true,
"keep_original": true,
"limit_first_letter_length": 16,
"lowercase": true,
"remove_duplicated_term": true
,
"mapping":
"properties":
"name":
"type": "keyword"
,
"searchkey":
"type": "completion",
"analyzer": "ik_pinyin_analyzer"
settings下面的为索引的设置信息,动态设置参数,遵循DSL写法
mapping下为映射的字段信息,动态设置参数,遵循DSL写法
返回
"code": "200",
"desc": "操作成功!",
"data": true
2 语料库文档OpenAPI
2.1 定义批量新增文档接口
package com.oldlu.service;
import com.oldlu.commons.pojo.CommonEntity;
import org.elasticsearch.action.DocWriteResponse;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.rest.RestStatus;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.suggest.completion.CompletionSuggestion;
import java.util.List;
import java.util.Map;
/**
* @Class: ElasticsearchDocumentService
* @Package com.oldlu.service
* @Description: 文档操作接口
* @Company:
*/
public interface ElasticsearchDocumentService
//批量新增文档
public RestStatus bulkAddDoc(CommonEntity commonEntity) throws Exception;
2.2 定义批量新增文档实现
/*
* @Description: 批量新增文档,可自动创建索引、自动创建映射
* @Method: bulkAddDoc
* @Param: [indexName, map]
* @Update:
* @since: 1.0.0
* @Return: org.elasticsearch.rest.RestStatus
*
*/
@Override
public RestStatus bulkAddDoc(CommonEntity commonEntity) throws Exception
//通过索引构建批量请求对象
BulkRequest bulkRequest = new BulkRequest(commonEntity.getIndexName());
//循环前台list文档数据
for (int i = 0; i < commonEntity.getList().size(); i++)
bulkRequest.add(new IndexRequest().source(XContentType.JSON,
SearchTools.mapToObjectGroup(commonEntity.getList().get(i))));
//执行批量新增
BulkResponse bulkResponse = client.bulk(bulkRequest,
RequestOptions.DEFAULT);
return bulkResponse.status();
官方文档介绍https://www.elastic.co/guide/en/elasticsearch/client/java-rest/7.4/java-rest-high-document-bulk.html
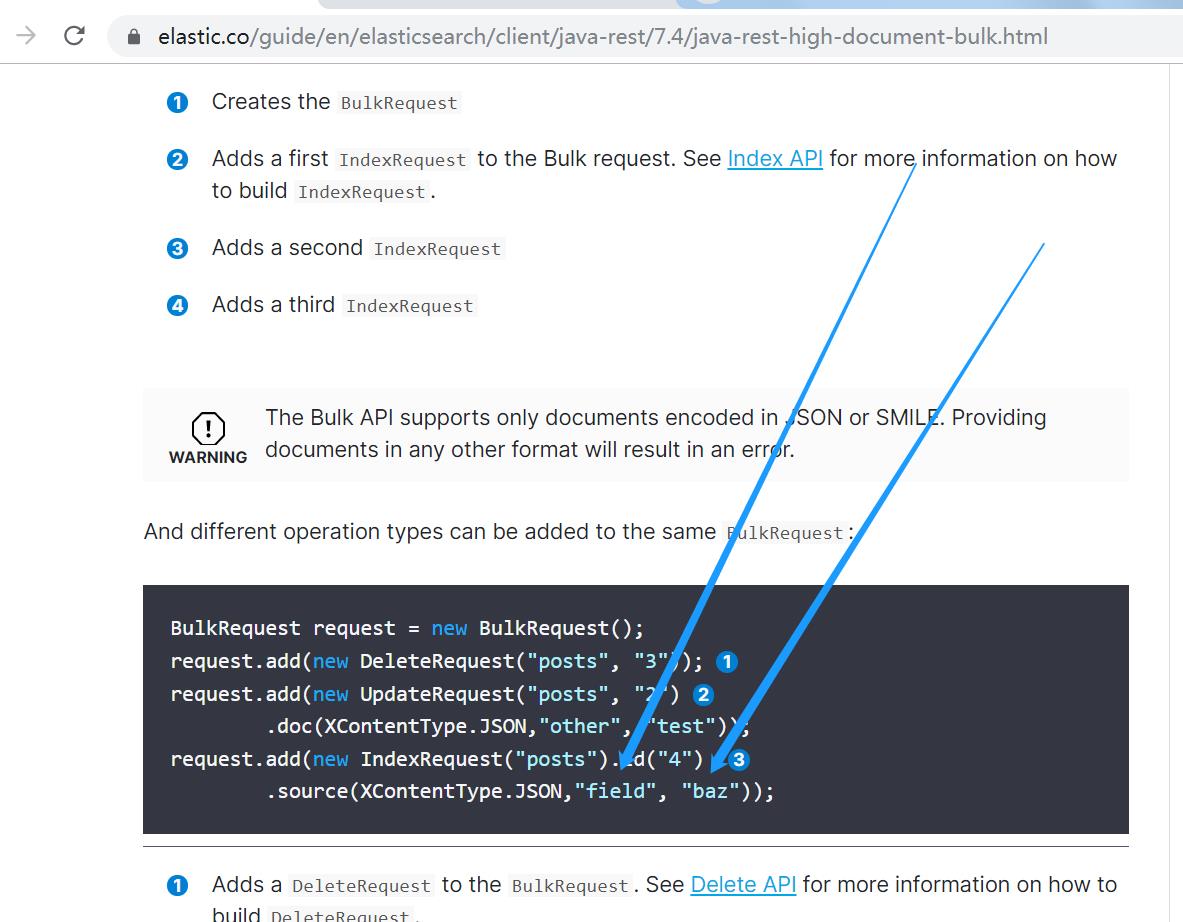
如上图,需要定义成箭头中的形式
所以上面SearchTools.mapToObjectGroup将map转成了数组
2.3 定义批量新增文档控制器
/*
* @Description: 批量新增文档,可自动创建索引、自动创建映射
* @Method: bulkAddDoc
* @Param: [indexName, map]
* @Update:
* @since: 1.0.0
* @Return: org.elasticsearch.rest.RestStatus
*
*/
@PostMapping(value = "/batch")
public ResponseData bulkAddDoc(@RequestBody CommonEntity commonEntity)
//构造返回数据
ResponseData rData = new ResponseData();
if (StringUtils.isEmpty(commonEntity.getIndexName()) ||
CollectionUtils.isEmpty(commonEntity.getList()))
rData.setResultEnum(ResultEnum.PARAM_ISNULL);
return rData;
//批量新增操作返回结果
RestStatus result = null;
try
//通过高阶API调用批量新增操作方法
result = elasticsearchDocumentService.bulkAddDoc(commonEntity);
//通过类型推断自动装箱(多个参数取交集)
rData.setResultEnum(result, ResultEnum.SUCCESS, null);
//日志记录
logger.info(TipsEnum.BATCH_CREATE_DOC_SUCCESS.getMessage());
catch (Exception e)
//日志记录
logger.info(TipsEnum.BATCH_CREATE_DOC_FAIL.getMessage(), e);
//构建错误返回信息
rData.setResultEnum(ResultEnum.ERROR);
return rData;
2.4 开始批量新增调用
http://172.17.0.225:8888/v1/docs/batch
或者
http://127.0.0.1:8888/v1/docs/batch
参数
定义23个suggest词库(定义了两个小米手机,验证是否去重)
"indexName": "product_completion_index",
"list": [
"searchkey": "小米手机",
"name": "小米(MI)"
,
"searchkey": "小米10",
"name": "小米(MI)"
,
"searchkey": "小米电视",
"name": "小米(MI)"
,
"searchkey": "小米路由器",
"name": "小米(MI)"
,
"searchkey": "小米9",
"name": "小米(MI)"
,
"searchkey": "小米手机",
"name": "小米(MI)"
,
"searchkey": "小米耳环",
"name": "小米(MI)"
,
"searchkey": "小米8",
"name": "小米(MI)"
,
"searchkey": "小米10Pro",
"name": "小米(MI)"
,
"searchkey": "小米笔记本",
"name": "小米(MI)"
,
"searchkey": "小米摄像头",
"name": "小米(MI)"
,
"searchkey": "小米电饭煲",
"name": "小米(MI)"
,
"searchkey": "小米充电宝",
"name": "小米(MI)"
,
"searchkey": "adidas男鞋",
"name": "adidas男鞋"
,
"searchkey": "adidas以上是关于ElasticSearch自定义pinyin和ik分词库的主要内容,如果未能解决你的问题,请参考以下文章